一次真实的线上 OOM 问题定位(二)

上文提到,此次线上OOM问题的原因是“研发人员疏漏,查询字典表数据未带查询条件,导致查出表中所有记录进行ORM处理从而引发内存溢出 ” ,经过通宵修复发版后,此问题未再重现,然而,新的问题仍在继续:"频繁GC","打开文件数太多","探测报404","频繁宕机",“jboss连接数骤增”……几乎囊括了这些年我能遇到的所有生产常见问题!组织专家会诊后,尝试了几种解决方案,但收效甚微,此问题已导致停止相关业务推广,影响很大。领导安排架构组定位解决此问题,而我自然责无旁贷,面临的压力很大,需要接着处理。
经反复分析及排查,发现业务关键处理调用是供应商提供的jar包,该包中封装了与终端设备使用netty交互的一些细节,之前一直是从我们自身的代码及逻辑入手,寻求突破点,对厂商提供的三方包过于信任,但现在想想,厂商提供的包一定好吗?
顺着这个思路,我对第三方包源码进行了手撕处理,还真发现了一些端倪,而且个人感觉这些问题可能非常关键,现将分析过程及结果梳理成文,以便于指导后续工作有效开展,同时也算是是一点经验,做下分享,具体内容详见下文。
流程图
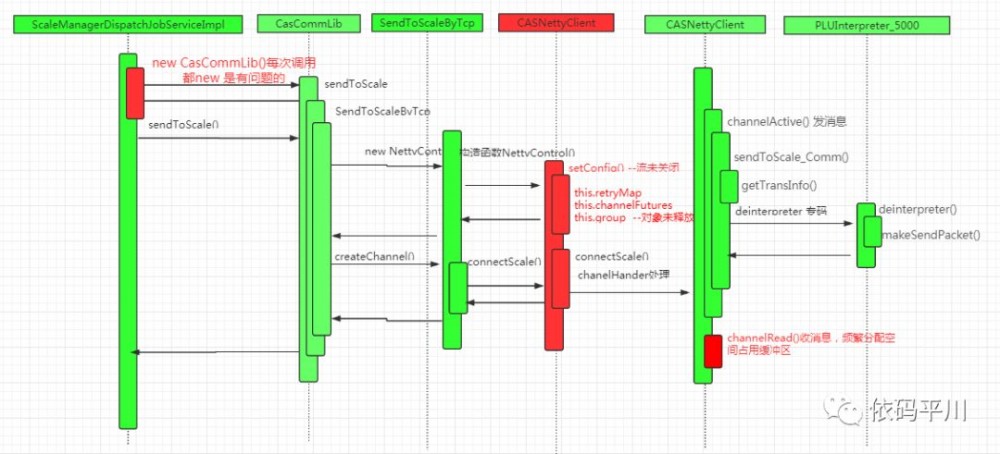
注:图中标红的部分是重大风险点,需要重点关注。
核心处理点
包含调用对象(CasCommLib)的创建,Netty客户端的初始化,建立连接、连接失败重试、发送数据处理,接收数据处理流程,下面详细解读下各环节可能存在的问题。
调用方

来看下new CasCommLib(propFile) 及casCommLib.sendToScale()方法中做了啥
CasCommLib(客户端门面)
CasCommLib()构造方法
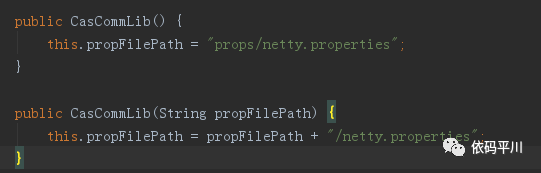
主要是给变量赋值,没问题
sendToScale()调用入口
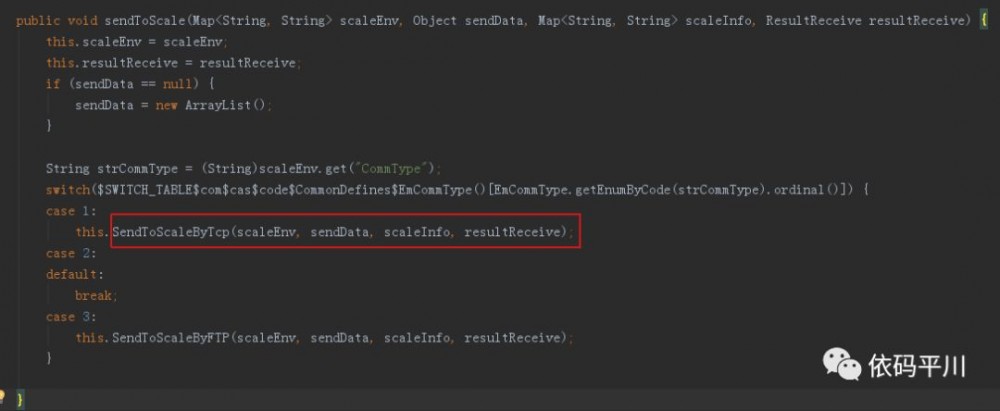
重点关注下SendToScaleByTcp()这个方法 (方法名首字母大写,不规范,很不专业,吐槽下)
SendToScaleByTcp() 业务处理方法

该方法重要分两步
new NettyControl(propFile)

createChannel()

这两步的处理最终都指向CASNettyClient类,这里做的只是透传,由此可见,CASNettyClient类是传操作的最核心处理,接下来我们就重点看下NettyClient的核心逻辑。
CASNettyClient(netty客户端)
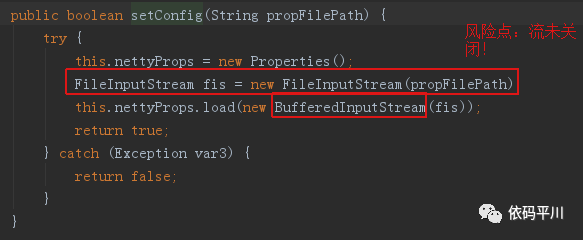
CASNettyClient() 构造方法初始化
public CASNettyClient(String propFilePath) {
if (!this.setConfig(propFilePath)) {
System.out.println("** Property Setting Error");
}
this.retryMap = new HashMap();
this.channelFutures = new HashMap();
this.group = new NioEventLoopGroup(Integer.parseInt(this.nettyProps.getProperty("MAX_THREAD_NUM")));
}
进一步跟踪及分析发现:
-
setConfig() - 每次IO流都未关闭,问题严重
-
创建了 NioEventLoopGroup,HashMap
这些都是内存杀手,意味着每次连接都会创建这个对象,重点关注下这些对象是否有地方释放并正确释放
-
纵观源码,发现NioEventLoopGroup无法释放, 问题严重
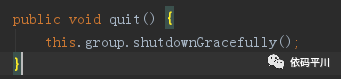
注:虽然代码中有quit()方法,并且方法内进行了优雅关闭,但此方法无地方调用,等于无用。HashMap也一样。
小结
看到这里,结合前几日对堆栈的分析,似乎可以大胆推测,产生此问题的根因如下:
-
setConfig方法中流未关闭,会导致打开文件数过多的问题
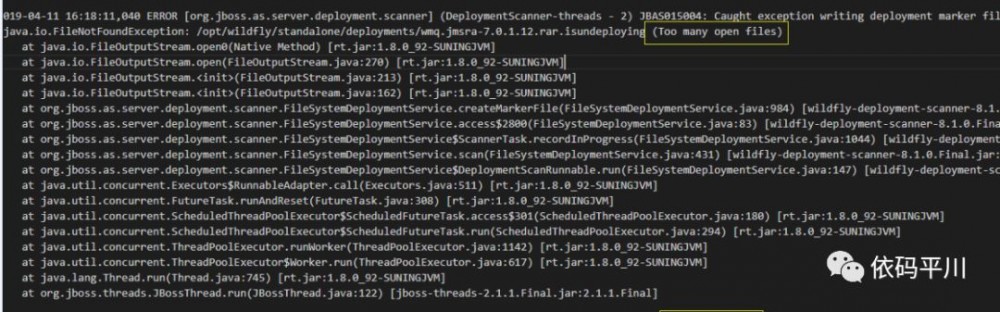
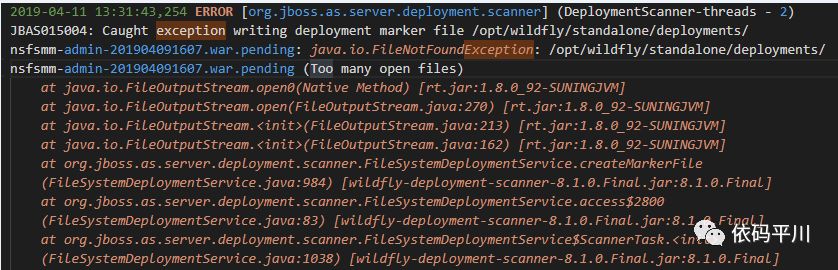
-
NioEventLoopGroup未释放,将导致内存占用高的问题
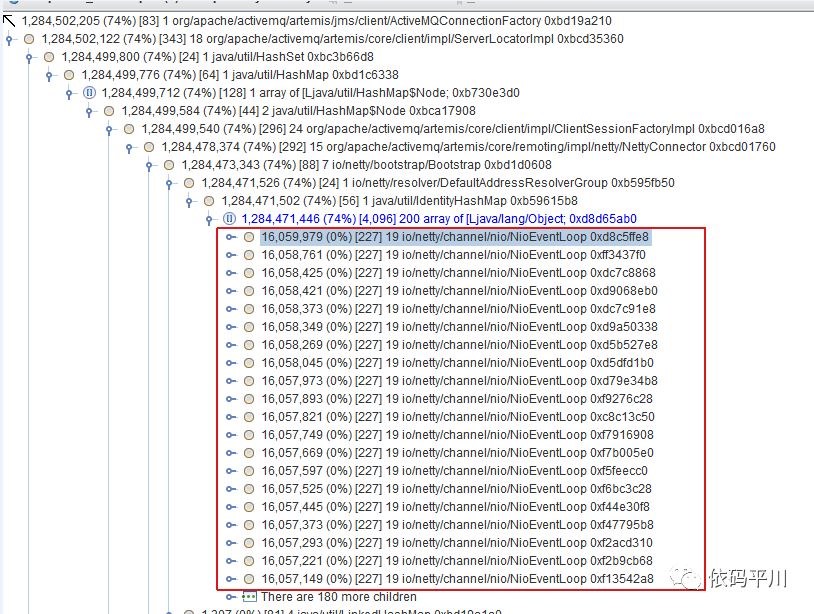
为严谨起见,我们把接下来的全流程代码走读并分析完,初始化完成后,接下来执行的是connectScale()
connectScale()连接
此处为业务处理的核心入口,是netty客户端的常规写法,主要作用如下:
-
创建BootStrapt对象
-
设置BootStrapt的EventLoopGroup
-
设置Channel
-
设置客户端连接属性
-
设置处理Handler
-
ReadTimeoutHandler --Netty自带类(风险低)
-
LoggingHandler --Netty自带类(风险低)
-
CASNettyClientHandler --自定义处理类,需要重点关注,包含消息的发送及接收处理
-
连接connect()
-
ChannelFuture
下面详细分析下具体细节
建立连接
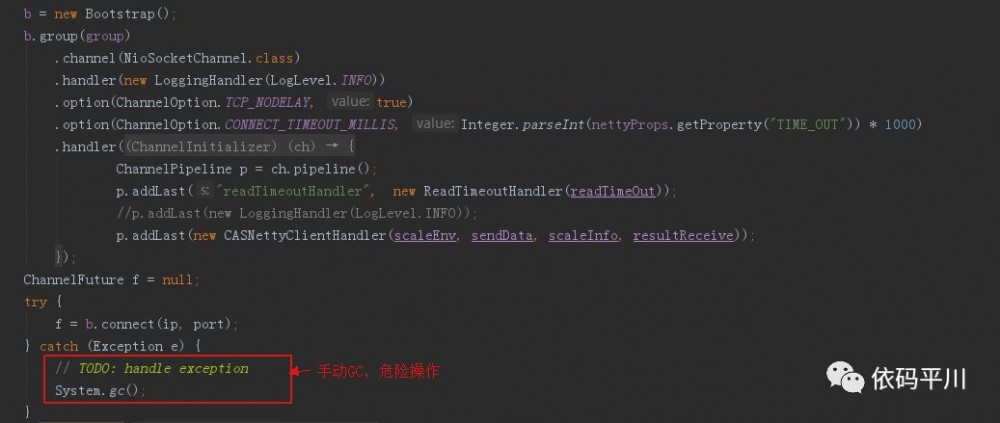
问题:连接异常时,手动GC,此块源码中有大量这样的处理,可去掉。
注:从源码中看,此工程更像是测试代码,不像商业版本(命名随意,代码洒脱)
连接失败重传机制

问题:频繁手动GC
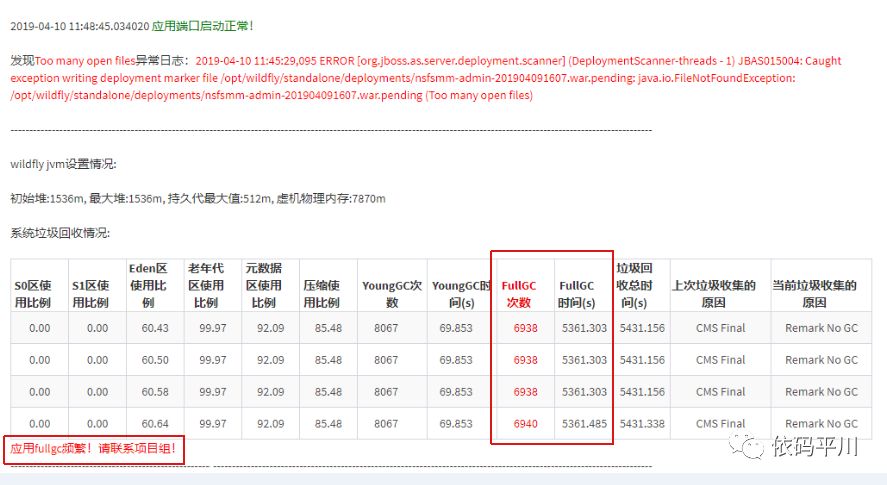
小结
至此,发现代码频繁进行手动GC,结合前几日的日志分析,大胆猜测下,可能与这种代码编写习惯关系较大
关于消息的发送及接收处理,就需要看pipeLine中的事件了,模型很简单,业务逻辑都在CASNettyClientHandler 类中,接下来,就重点看下这个类。
CASNettyClientHandler(netty消息处理)
该类主要处理消息的发送和接收,分开看下
消息发送
发送处理逻辑在channelActive()方法中
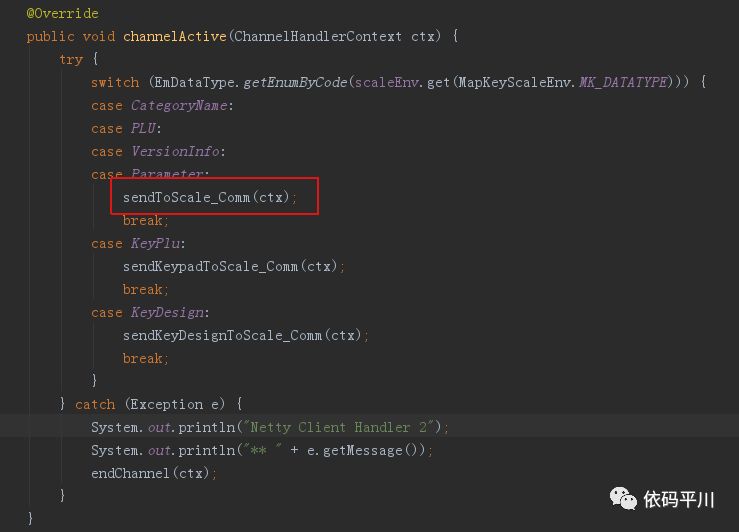
重点处理在 sendToScale_Comm() 方法中,看下这个方法:
private void sendKeypadToScale_Comm(ChannelHandlerContext ctx){
……
ByteBuffer assemblyData = null;
……
//转码
assemblyData = casTrans.deinterpreter(scaleEnv, curKeypad,scaleInfo);
……
ByteBuf sendToScaleData = Unpooled.wrappedBuffer(assemblyData);
ctx.writeAndFlush(sendToScaleData);
assemblyData.clear();
}
未发现明显问题,接下来看下接收处理。
消息接收
消息接收处理逻辑在channelRead()方法中

上图中标红的代码有问题,每次接收到服务端返回的消息时都分配一次缓存空间, 这是NIO处理的大忌 ,会导致占用大量的内存空间。结合前日压测出现缓存空间被占满的情况,在此可以大胆猜测下,可能与此相关。 发送及接收消息的编码及解码,未使用netty中的pipeline进行分发,而是自行直接调用自定义代码实现,未发现明显问题。 至此,核心代码流程跟踪及分析完毕。
修改方案
通过以上代码的走读及分析,已初步可以推测,厂商提供的jar包处理是有问题的,主要有5个问题,问题描述及对应的解决方案如下:
-
每次传数据都new对象,导致重复创建大量对象,并且无法释放资源
修改方案:调用方在调用时通过单例方式调用,代码已修改。
-
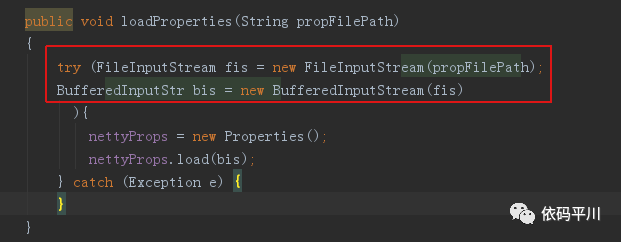
存在文件流未关闭问题
修改方案:修改源码,使用jdk1.7特性进行自动关闭处理,代码已修改。
-
存在NioEventLoopGroup未关闭问题
修改方案:调用方修改为单例方式时,保证全局只会有一个EventLoopGroup对象进行共用,在这种情况可以暂不做处理。
-
存在较多手动触发gc问题
修改方案:去掉相关显式调用System.gc()的代码,代码已修改。
-
存在ByteBuffer缓存分配不合理问题
修改方案:将内存分配变量放到方法外面,作为全局对象使用,避免频繁开辟空间,导致缓冲区被占满,代码已修改。
总结
通过以上几种方式处理,初步预计可以解决目前现网暴露出的大量问题,具体情况还是需要上线后重点观察,现网环境复杂多变,不能保证一定完全解决。 此外,我们还应引起重视:不要过分相信厂商提供的三方包,他们可能隐藏着巨大的陷阱,稍不留意,我们就可能被坑的很惨,后续评估厂家提供的.jar包时,保证在“能用”的基础上,一定要考虑现网大数据高并发场景下的性能问题,上线前必须要经过压测;必要时需要走读其源码,以便于在第一时间发现可能存在的问题。
最后,聊点心得,定位解决生产问题,对人的综合能力要求很高,需要对技术有较为全面的认知和了解,否则步履维艰,需要用到技术点诸如:JVM及故障分析工具,网络,并发编程,高性能设计,netty,数据库原理及性能优化,分布式集群中的注意事项,高并发场景分析……非常考验人,同时,这种经历对人提升也很大,我还需要不断去学习,积累经验。 待发布后观察验证,若问题仍未解决,还需逆风而上,砥砺前行,任重道远,我将持续跟进。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

