当我们谈微服务,我们在谈什么 (3) — 如何保障微服务的稳定性
当一个单体应用改造成多个微服务之后,在请求调用过程中往往会出现更多的问题,通信过程中的每一个环节都可能出现问题。而在出现问题之后,如果不加处理,还会出现链式反应导致服务雪崩。服务治理功能就是用来处理此类问题的。我们将从微服务的三个角色:注册中心、服务消费者以及服务提供者一一说起。
注册中心如何保障稳定性
注册中心主要是负责节点状态的维护,以及相应的变更探测与通知操作。一方面,注册中心自身的稳定性是十分重要的。另一方面,我们也不能完全依赖注册中心,需要时常进行类似注册中心完全宕机后微服务如何正常运行的故障演练。
这一节,我们着重讲的并不是注册中心自身可用性保证,而更多的是与节点状态相关的部分。
节点信息的保障
我们说过,当注册中心完全宕机后,微服务框架仍然需要有正常工作的能力。这得益于框架内处理节点状态的一些机制。
本机内存
首先服务消费者会将节点状态保持在本机内存中。一方面由于节点状态不会变更得那么频繁,放在内存中可以减少网络开销。另一方面,当注册中心宕机后,服务消费者仍能从本机内存中找到服务节点列表从而发起调用。
本地快照
我们说,注册中心宕机后,服务消费者仍能从本机内存中找到服务节点列表。那么如果服务消费者重启了呢?这时候我们就需要一份本地快照了,即我们保存一份节点状态到本地文件,每次重启之后会恢复到本机内存中。
服务节点的摘除
现在无论注册中心工作与否,我们都能顺利拿到服务节点了。但是不是所有的服务节点都是正确可用的呢?在实际应用中,这是需要打问号的。如果我们不校验服务节点的正确性,很有可能就调用到了一个不正常的节点上。所以我们需要进行必要的节点管理。
对于节点管理来说,我们有两种手段,主要是去摘除不正确的服务节点。
注册中心摘除机制
一是通过注册中心来进行摘除节点。服务提供者会与注册中心保持心跳,而一旦超出一定时间收不到心跳包,注册中心就认为该节点出现了问题,会把节点从服务列表中摘除,并通知到服务消费者,这样服务消费者就不会调用到有问题的节点上。
服务消费者摘除机制
二是在服务消费者这边拆除节点。因为服务消费者自身是最知道节点是否可用的角色,所以在服务消费者这边做判断更合理,如果服务消费者调用出现网络异常,就将该节点从内存缓存列表中摘除。当然调用失败多少次之后才进行摘除,以及摘除恢复的时间等等细节,其实都和客户端熔断类似,可以结合起来做。
一般来说,对于大流量应用,服务消费者摘除的敏感度会高于注册中心摘除,两者之间也不用刻意做同步判断,因为过一段时间后注册中心摘除会自动覆盖服务消费者摘除。
服务节点是可以随便摘除/变更的么
上一节我们讲可以摘除问题节点,从而避免流量调用到该节点上。但节点是可以随便摘除的么?同时,这也包含"节点是可以随便更新的么?"疑问。
频繁变动
当网络抖动的时候,注册中心的节点就会不断变动。这导致的后果就是变更消息会不断通知到服务消费者,服务消费者不断刷新本地缓存。如果一个服务提供者有100个节点,同时有100个服务消费者,那么频繁变动的效果可能就是100*100,引起带宽打满。
这时候,我们可以在注册中心这边做一些控制,例如经过一段时间间隔后才能进行变更消息通知,或者打开开关后直接屏蔽不进行通知,或者通过一个概率计算来判断需要向哪些服务消费者通知。
增量更新
同样是由于频繁变动可能引起的网络风暴问题,一个可行的方案是进行增量更新,注册中心只会推送那些变化的节点信息而不是全部,从而在频繁变动的时候避免网络风暴。
可用节点过少
当网络抖动,并进行节点摘除过后,很可能出现可用节点过少的情况。这时候过大的流量分配给过少的节点,导致剩下的节点难堪重负,罢工不干,引起恶化。而实际上,可能节点大多数是可用的,只不过由于网络问题与注册中心未能及时保持心跳而已。
这时候,就需要在服务消费者这边设置一个开关比例阈值,当注册中心通知节点摘除,但缓存列表中剩下的节点数低于一定比例后(与之前一段时间相比),不再进行摘除,从而保证有足够的节点提供正常服务。
这个值其实可以设置的高一些,例如百分之70,因为正常情况下不会有频繁的网络抖动。当然,如果开发者确实需要下线多数节点,可以关闭该开关。
服务消费者如何保障稳定性
一个请求失败了,最直接影响到的是服务消费者,那么在服务消费者这边,有什么可以做的呢?
超时
如果调用一个接口,但迟迟没有返回响应的时候,我们往往需要设置一个超时时间,以防自己被远程调用拖死。超时时间的设置也是有讲究的,设置的太长起的作用就小,自己被拖垮的风险就大,设置的太短又有可能误判一些正常请求,大幅提升错误率。
在实际使用中,我们可以取该应用一段时间内的P999的值,或者取p95的值*2。具体情况需要自行定夺。
在超时设置的时候,对于同步与异步的接口也是有区分的。对于同步接口,超时设置的值不仅需要考虑到下游接口,还需要考虑上游接口。而对于异步来说,由于接口已经快速返回,可以不用考虑上游接口,只需考虑自身在异步线程里的阻塞时长,所以超时时间也放得更宽一些。
容错机制
请求调用永远不能保证成功,那么当请求失败时候,服务消费者可以如何进行容错呢?通常容错机制分为以下这些:
- FailTry:失败重试。就是指最常见的重试机制,当请求失败后视图再次发起请求进行重试。这样从概率上讲,失败率会呈指数下降。对于重试次数来说,也需要选择一个恰当的值,如果重试次数太多,就有可能引起服务恶化。另外,结合超时时间来说,对于性能有要求的服务,可以在超时时间到达前的一段提前量就发起重试,从而在概率上优化请求调用。当然,重试的前提是幂等操作。
- FailOver:失败切换。和上面的策略类似,只不过FailTry会在当前实例上重试。而FailOver会重新在可用节点列表中根据负载均衡算法选择一个节点进行重试。
- FailFast:快速失败。请求失败了就直接报一个错,或者记录在错误日志中,这没什么好说的。
另外,还有很多形形色色的容错机制,大多是基于自己的业务特性定制的,主要是在重试上做文章,例如每次重试等待时间都呈指数增长等。
第三方框架也都会内置默认的容错机制,例如Ribbon的容错机制就是由retry以及retry next组成,即重试当前实例与重试下一个实例。这里要多说一句,ribbon的重试次数与重试下一个实例次数是以笛卡尔乘积的方式提供的噢!
熔断
上一节将的容错机制,主要是一些重试机制,对于偶然因素导致的错误比较有效,例如网络原因。但如果错误的原因是服务提供者自身的故障,那么重试机制反而会引起服务恶化。这时候我们需要引入一种熔断的机制,即在一定时间内不再发起调用,给予服务提供者一定的恢复时间,等服务提供者恢复正常后再发起调用。这种保护机制大大降低了链式异常引起的服务雪崩的可能性。
在实际应用中,熔断器往往分为三种状态,打开、半开以及关闭。引用一张martinfowler画的原理图:
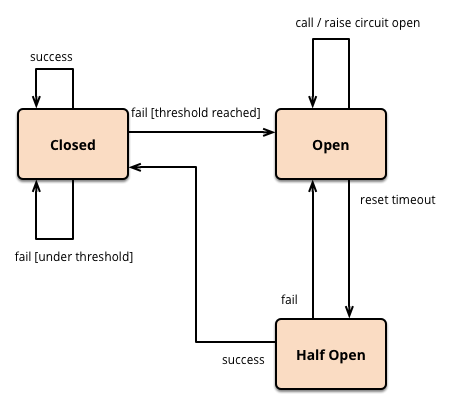
在普通情况下,断路器处于关闭状态,请求可以正常调用。当请求失败达到一定阈值条件时,则打开断路器,禁止向服务提供者发起调用。当断路器打开后一段时间,会进入一个半开的状态,此状态下的请求如果调用成功了则关闭断路器,如果没有成功则重新打开断路器,等待下一次半开状态周期。
断路器的实现中比较重要的一点是失败阈值的设置。可以根据业务需求设置失败的条件为连续失败的调用次数,也可以是时间窗口内的失败比率,失败比率通过一定的滑动窗口算法进行计算。另外,针对断路器的半开状态周期也可以做一些花样,一种常见的计算方法是周期长度随着失败次数呈指数增长。
具体的实现方式可以根据具体业务指定,也可以选择第三方框架例如Hystrix。
隔离
隔离往往和熔断结合在一起使用,还是以Hystrix为例,它提供了两种隔离方式:
- 信号量隔离:使用信号量来控制隔离线程,你可以为不同的资源设置不同的信号量以控制并发,并相互隔离。当然实际上,使用原子计数器也没什么不一样。
- 线程池隔离:通过提供相互隔离的线程池的方式来隔离资源,相对来说消耗资源更多,但可以更好地应对突发流量。
降级
降级同样大多和熔断结合在一起使用,当服务调用者这方断路器打开后,无法再对服务提供者发起调用了,这时候可以通过返回降级数据来避免熔断造成的影响。
降级往往用于那些错误容忍度较高的业务。同时降级的数据如何设置也是一门学问。一种方法是为每个接口预先设置好可接受的降级数据,但这种静态降级的方法适用性较窄。还有一种方法,是去线上日志系统/流量录制系统中捞取上一次正确的返回数据作为本次降级数据,但这种方法的关键是提供可供稳定抓取请求的日志系统或者流量采样录制系统。
另外,针对降级我们往往还会设置操作开关,对于一些影响不大的采取自动降级,而对于一些影响较大的则需进行人为干预降级。
服务提供者如何保障稳定性
限流
限流就是限制服务请求流量,服务提供者可以根据自身情况(容量)给请求设置一个阈值,当超过这个阈值后就丢弃请求,这样就保证了自身服务的正常运行。
阈值的设置可以针对两个方面考虑,一是QPS即每秒请求数,二是并发线程数。从实践来看,我们往往会选择后者,因为QPS高往往是由于处理能力高,并不能反映出系统"不堪重负"。
除此之外,我们还有许多针对限流的算法。例如令牌桶算法以及漏桶算法,主要针对突发流量的状况做了优化。第三方的实现中例如guava rateLimiter就实现了令牌桶算法。在此就不就细节展开了。
重启与回滚
限流更多的起到一种保障的作用,但如果服务提供者已经出现问题了,这时候该怎么办呢?
这时候就会出现两种状况。一是本身代码有bug,这时候一方面需要服务消费者做好熔断降级等操作,一方面服务提供者这边结合DevOps需要有快速回滚到上一个正确版本的能力。
更多的时候,我们可能仅仅碰到了与代码无强关联的单机故障,一个简单粗暴的办法就是自动重启。例如观察到某个接口的平均耗时超出了正常范围一定程度,就将该实例进行自动重启。当然自动重启需要有很多注意事项,例如重启时间是否放在晚上,以及自动重启引起的与上述节点摘除一样的问题,都需要考虑和处理。
在事后复盘的时候,如果当时没有保护现场,就很难定位到问题原因。所以往往在一键回滚或者自动重启之前,我们往往需要进行现场保护。现场保护可以是自动的,例如一开始就给jvm加上打印gc日志的参数 -XX:+PrintGCDetails ,或者输出oom文件 -XX:+HeapDumpOnOutOfMemoryError ,也可以配合DevOps自动脚本完成,当然手动也可以。一般来说我们会如下操作:
- 打印堆栈信息,
jstak -l 'java进程PID' - 打印内存镜像,
jmap -dump:format=b,file=hprof 'java进程PID' - 保留gc日志,保留业务日志
调度流量
除了以上这些措施,通过调度流量来避免调用到问题节点上也是非常常用的手段。
当服务提供者中的一台机器出现问题,而其他机器正常时,我们可以结合负载均衡算法迅速调整该机器的权重至0,避免流量流入,再去机器上进行慢慢排查,而不用着急第一时间重启。
如果服务提供者分了不同集群/分组,当其中一个集群出现问题时,我们也可以通过路由算法将流量路由到正常的集群中。这时候一个集群就是一个微服务分组。
而当机房炸了、光缆被偷了等IDC故障时,我们又部署了多IDC,也可以通过一些方式将流量切换到正常的IDC,以供服务继续正常运行。切换流量同样可以通过微服务的路由实现,但这时候一个IDC对应一个微服务分组了。除此之外,使用DNS解析进行流量切换也是可以的,将对外域名的VIP从一个IDC切换到另一个IDC。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

