Java反序列化漏洞辅助工具之 gadgetinspector
银河实验室 前沿安全组 刘瑞恺
Java反序列化漏洞可谓是近年来人气颇高的一种漏洞。由于其影响范围广,造成危害大,每次新曝光的反序列化漏洞,往往都要掀起一片血雨腥风。而针对这类漏洞的自动化扫描,大都集中于反序列化的入口(source),但对于如何构造调用链(gadget chain),最终到达目标方法(sink),则仍然需要研究者花费大量人工工作。虽然有诸如 ysoserial 和 marshalsec 这类可以生成完整payload的工具,但它们也只是基于常见的库,预置了一些gadget chain;而对于大量第三方库中可能存在的其他调用链,则无法识别和利用,因此具有一定的局限性。
鉴于此,来自 Nexflix 的安全研究员 Ian Haken 开发并公布了一款自动化扫描生成gadget chain的工具: gadgetinspector 。这个工具的最大特点,就是可以扫描全部可以利用的Jar包,并自动化生成从 source 到 sink 的调用链。在本文中,我们将介绍 gadgetinspector 的工作原理,并基于我们的学习研究,提出一些相应的改进和完善。
1. Java反序列化漏洞重温
其实,关于Java反序列化漏洞,网上已经有很多非常详尽的文章了。这里我们也不会再赘述,只是从整体的角度来简要回顾这些漏洞的原理。
正如上文所说,反序列化漏洞的挖掘,本质上就是一个已知 source 和 sink,如何走通整个调用流程的问题。在这里的 source,可以包括:
- Java原生的反序列化,即通过 ObjectInputStream.readObject(),处理二进制格式内容,得到Java对象
- 专有格式的反序列化,例如通过 Fastjson, Xstream 等第三方库,处理 json, xml 等格式内容,得到Java对象
而要执行的目标sink,可以包括:
- Runtime.exec(),这种最为简单直接,即直接在目标环境中执行命令
- Method.invoke(),这种需要适当地选择方法和参数,通过反射执行Java方法
- RMI/JNDI/JRMP等,通过引用远程对象,间接实现任意代码执行的效果
按理来说,只要我们从source出发,递归检查其所有方法调用,如果能够执行到sink,不就构成了一条调用链么?但问题远比这复杂的多。举个例子,下面这个类在反序列化时会执行Runtim.exec(): 
然而,它执行的命令是已经预设好的计算器,我们无法控制exec()的参数,这样的sink就是无法被利用的。因此,我们需要通过类似污点分析的方式,跟踪判断最终的sink是否是实际可利用的。
再例如,Java面向对象的语言特性,让实际方法调用的记录变得异常复杂。假设我们有两个类,Apple 和 Banana,都继承类 Fruit:

那么,下面这个方法中,调用的究竟是 Apple.eat(),还是 Banana.eat() 呢?

因此,当我们遇到调用虚方法或者接口方法时,还需要考虑其全部的实现。而许多实际中的反序列化漏洞,就是利用这种非预期的子类方法调用,打通整个调用链的。
2. gadgetinspector 基本介绍
为了解决以上问题,gadgetinspector应运而生。它对classpath中全部可用的jar包进行分析,从而生成方法调用的污点传递关系,并最终从source出发,通过广度优先搜索(BFS),生成通往sink的调用链。由于扫描分析是在Java字节码这一层进行,因此gadgetinspector可以直接对编译完成的jar包或者war包进行检查,而无需项目的源码。
gadgetinspector的具体工作原理,可以参见作者本人的文章https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains-wp.pdf,这里我们只对其工作流程做一个基本的介绍。
2.1 穷举全部类和方法
这是最基本的准备工作。gadgetinspector会检查用户提供的jar包、war包,以及Java自身的classpath,获取在运行时全部可用的类。类之间的继承关系会被保存,类中包含的方法及其继承关系同样也被记录下来,用于之后的分析。
这一步完成后,相关的数据会保存在文件 methods.dat, classes.dat, methodimpl.dat 中。
2.2 生成passthrough数据流(dataflow)
这一步会检查所有方法,并判断每个方法的返回结果是否可以被其参数所影响。例如,下面有两个方法,都是接收一个String类型的参数,并返回一个String类型的结果:

但是,对于方法foo来说,结果是可以被参数控制的,而方法bar的结果与其参数毫无关系。因此,如果攻击者的输入内容被传递到方法foo,还有可能继续进行下去;如果被传递到方法bar,那就走入死胡同了。
在这一步中,gadgetinspector是利用ObjectWeb ASM来进行方法字节码的分析,其主要逻辑是在类PassthroughDiscovery和TaintTrackingMethodVisitor中。特别是TaintTrackingMethodVisitor,它通过标记追踪JVM虚拟机在执行方法时的stack和localvar,并最终得到返回结果是否可以被参数标记污染。
待全部方法都这样分析完成后,结果会保存在文件passthrough.dat中。
2.2.1 题外话:Java方法执行机制
要了解Java方法是如何在JVM中执行的,首先就必须要了解Java字节码(bytecode)。字节码是JVM所执行的基本指令,可以与x86的指令来类比理解。
工具javap用于反编译得到字节码。例如,将以下Java代码编译为jar包Test.jar:
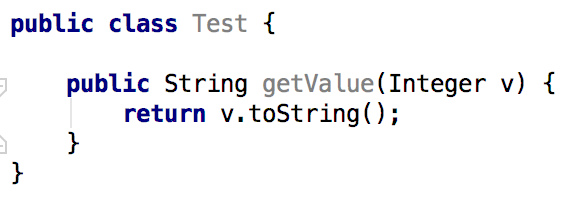
再使用javap反编译,即可得到其字节码:

每条Java字节码的含义,可参阅https://en.wikipedia.org/wiki/Java_bytecode_instruction_listings。
回到Java方法的执行机制上来。JVM为每个Java方法维护了一个栈(stack),用于callee调用的参数传递和返回结果获取。类似于x86,参数从右向左依次被圧入栈,并通过invokespecial, invokestatic, invokevirtual, invokeinterface分别调用构造方法、静态方法、虚方法、接口方法。当callee调用完毕后,栈上的全部参数会全部被弹出,并把返回结果圧入栈。
与x86所不同的是,方法的局部变量(localvar)不再通过栈来保存,而是另外开辟一个局部变量池,专门保存方法执行过程中需要用到的这些变量。另外,方法本身所需的参数,也是作为局部变量,在v0, v1, ..., vn中保存。
以上文中的Test.getValue()方法为例。可以看到第一条指令是aload_1,这是取局部变量v1圧入栈。因为getValue()是一个虚方法,所以this对象是方法的第0个参数,number正好是第1个参数,即局部变量v1。
接下来,通过invokevirtual来调用方法toSting(),此时toString()的参数v1已入栈,调用完成后,栈上保留的就是toString()的返回结果。
最终,通过areturn,将栈顶元素弹出作为返回结果。至此,方法getValue()就调用完成了。
2.3 生成passthrough调用图(callgraph)
这一步的主要逻辑在CallGraphDiscovery和TaintTrackingMethodVisitor中。与上一步非常类似,gadgetinspector 会再次扫描全部的Java方法,但检查的不再是参数与返回结果的关系,而是方法的参数与其所调用的子方法的关系,即子方法的参数是否可以被父方法的参数所影响。例如:
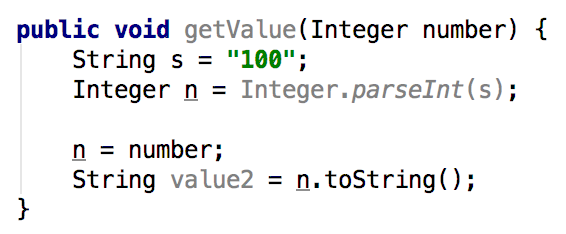
在方法getValue()中,调用了parseInt()和toString()这两个子方法。然而,getValue()的参数number只会影响toString()的参数,对parstInt()的参数无法控制。因此,如果调用链走到了getValue()方法,而且参数number是可控的,那么接下来就只需要进一步检查toString()方法,而parseInt()方法则无需再跟进了。
这一步的分析结果,会保存在文件callgraph.dat中。
2.4 搜索可用的source
这一步会根据以往反序列化漏洞的入口,检查所有可以被触发的方法。例如,当向HashMap添加元素时,会通过Object.hashCode()方法判断是否重复,因此所有继承重写的hashCode()方法都可以视为潜在的入口方法。当然,这里还需要判断方法所属的类是否可被反序列化,而这又依赖于具体的反序列化库了。
这一步的结果会保存在文件sources.dat中。
2.5 搜索生成调用链
有了passthrough.dat和callgraph.dat,gadgetinspector就进入到了最终的调用链搜索阶段。这一步会遍历全部的source,并在callgraph.dat中递归查找所有可以继续传递污点参数的子方法调用,直至遇到sink中的方法。
例如,类org/apache/commons/collections/map/Flat3Map的方法equals是入口点之一,通过callgraph.dat可知其调用了以下三个方法:  那么对这三个方法,会继续在callgraph.dat中递归搜索调用的子方法。而由于这三个方法都有大量的子类实现,因此这些实现也会被纳入搜索的范围,以进一步拓宽可能的调用范围。例如,类org/apache/commons/collections/map/LazyMap实现了java/util/Map,而检查方法LazyMap.get()的调用可以发现:
那么对这三个方法,会继续在callgraph.dat中递归搜索调用的子方法。而由于这三个方法都有大量的子类实现,因此这些实现也会被纳入搜索的范围,以进一步拓宽可能的调用范围。例如,类org/apache/commons/collections/map/LazyMap实现了java/util/Map,而检查方法LazyMap.get()的调用可以发现:

接口org/apache/commons/collections/Transformer的方法transform()被调用了。再接下来,当检查到实现了Transformer接口的类org/apache/commons/collections/functors/InvokerTransformer时,发现其transform()方法正好调用了Method.invoke():

至此便完成了一条调用链的搜索。
事实上,对于每个入口节点来说,其全部子方法调用、孙子方法调用等等递归下去,就构成了一棵树。之前的步骤所做的,就相当于生成了这颗树,而这一步所做的,就是从根节点出发,找到一条通往叶子节点的道路,使得这个叶子节点正好是我们所期望的sink方法。gadgetinspector对树的遍历采用的是广度优先(BFS),而且对于已经已经检查过的节点会直接跳过,从而极大地减少了运行开销。
3. gadgetinspector的缺点和改进
以上便是gadgetinspector的基本工作原理,整个流程还是很清晰的。不过,在实际使用时,我们还是发现了一些问题,主要表现是搜索生成的调用链较少。以Xstream反序列化漏洞为例,工具marshallsec中包含了大量的已知调用链,其中有一些如ImageIO这类只依赖JDK本身的调用链,gadgetinspector却没有发现。而这个经典的调用链正好是Struts2 S2-052漏洞的payload,未能发现还是挺令人遗憾的,这也激发了我们进一步研究问题的成因。
通过对gadgetinspector代码的分析调试,我们发现了其主要存在以下两处缺点:
3.1 callgraph生成不完整
还是以Xstream的ImageIO调用链为例。当检查到类com.sun.xml.internal.bind.v2.runtime.unmarshaller.Base64Data的方法get()时:

原本,这里的利用方式是通过反序列化控制InputStream的实现为CipherInputStream,并触发其close()方法。也就是说,Base64Data.get()方法的参数0(类型为Base64Data的this对象),可以影响InputStream.close()方法的参数0(类型为InputStream的this对象)。然而,CallgraphDiscovery却没有发现这一层关系,从而造成gadget chain搜索到此处就中断。
我们对Base64Data.get()方法中的具体调用逻辑进行进一步分析。再次回到上图,首先看到的,是对this.dataHandler对象调用方法getDataSource()。由于this.dataHandler作为this对象(类型为Base64Data)的field,其值是可以在反序列化Base64Data时控制的。因此,Base64Data.get()方法的参数0是可以影响this.dataHandler,即DataHandler.getDataSource()方法的参数0。
而DataHandler.getDataSource()方法的源码如下:
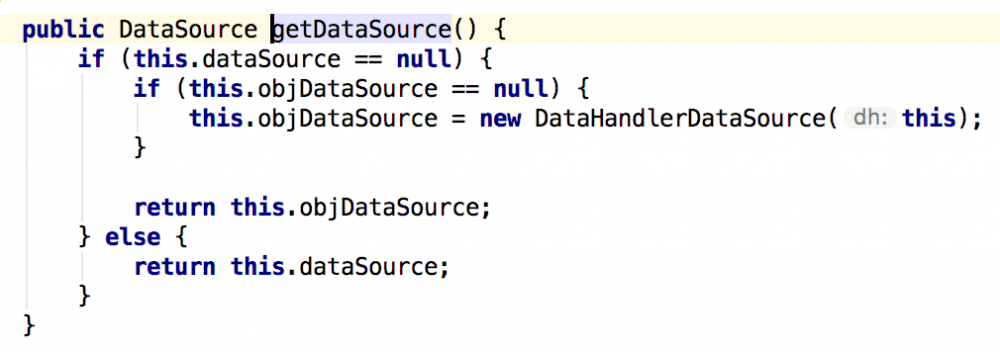
可以看到,DataHandler.getDataSource()方法的返回结果是DataHandler的一个field,因此是可以被参数0(类型为DataHandler)影响的。组合以上信息可知,DataHandler.getDataSource()的结果,是可以被Base64Data.get()方法的参数0影响的。
接下来,是对DataHandler.getDataSource()方法的结果,调用DataSource.getInputStream()方法。而问题恰好就出在这里:

可以看到,DataSource是一个interface,其运行时的具体实现在静态扫描时是不可知的。而一旦遇到这种不确定方法实现的情况,工具gadgetinspector就无可奈何了。所以,DataSource.getInputStream()的结果(类型为InputStream),会被直接判定为不受参数0(类型为DataSource)影响。这一环的缺失,就最终使得无法将Base64Data.get()与InputStream.close()连接起来。
既然知道了问题在于调用interface方法时不确定其具体实现,那么最直接的改进思路,就是对全部的实现方法进行检查。还是以DataSource.getInputStream()为例,com.sun.xml.internal.ws.encoding.xml.XMLMessage$XmlDataSource是DataSource的一个实现,而XMLMessage$XmlDataSource.getInputStream()方法的结果是受到参数0影响的:
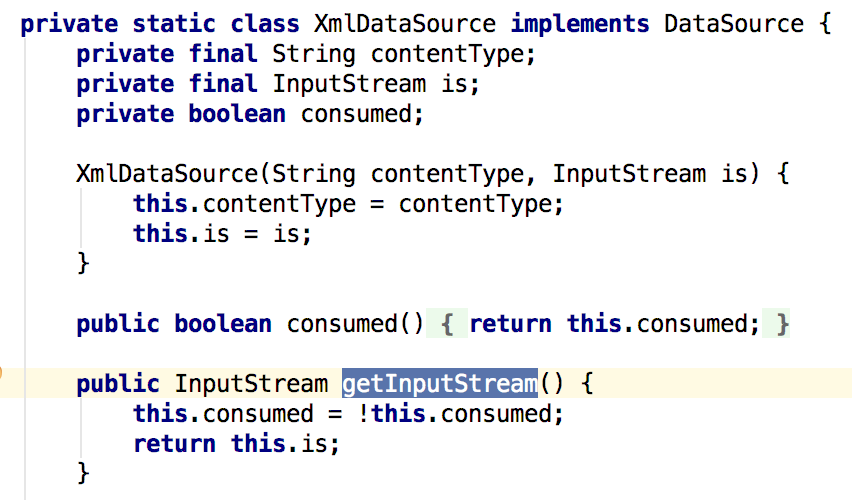
那么经过改进,CallgraphDiscovery在检查到这一步时,会将DataSource.getInputStream()的结果标记为受到Base64Data.get()的参数0影响,从而可以影响InputStream.close()的参数0。但是,单纯检查全部实现方法,会引入许多误报,特别是在interface的实现并不是完全未知的情况下。倘若DataHandler.getDataSource()的实现如下:
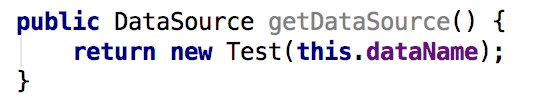
其中Test类是DataSource的一个实现,但Test.getInputStream()的结果并不受其参数0影响:
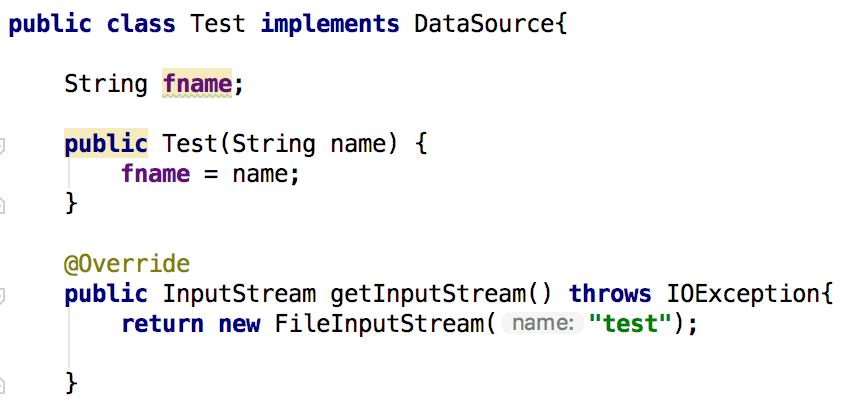
那么DataSource.getInputStream()的实际结果就是FileInputStream("test"),完全不受Base64Data.get()的参数0影响。这种情况下,再检查DataSource.getInputStream()的全部实现,就会造成误报。
为此,我们的改进还需要判断方法的实现是否可知,如果可以推断出来实际运行时是哪一种实现,就不能再一股脑地将所有实现都检查一番。为了达到这一目的,我们在TaintTrackingMethodDiscovery的基础上,对Java方法执行过程中的栈和局部变量的类型进行了记录。之后,在CallDiscovery检查子方法调用时,会首先判断其参数0是否是已知类型,只有在参数0未知,即方法具体实现是未知的情况下,才会对所有的实现方法进行检查,并判断是否会影响到这一方法的返回结果。
3.2 调用链搜索结果不完整
出于效率考虑,gadgetinspector的调用链生成搜索采用的是广度优先,而且在树的遍历中遇到已经出现过的节点会跳过。例如:
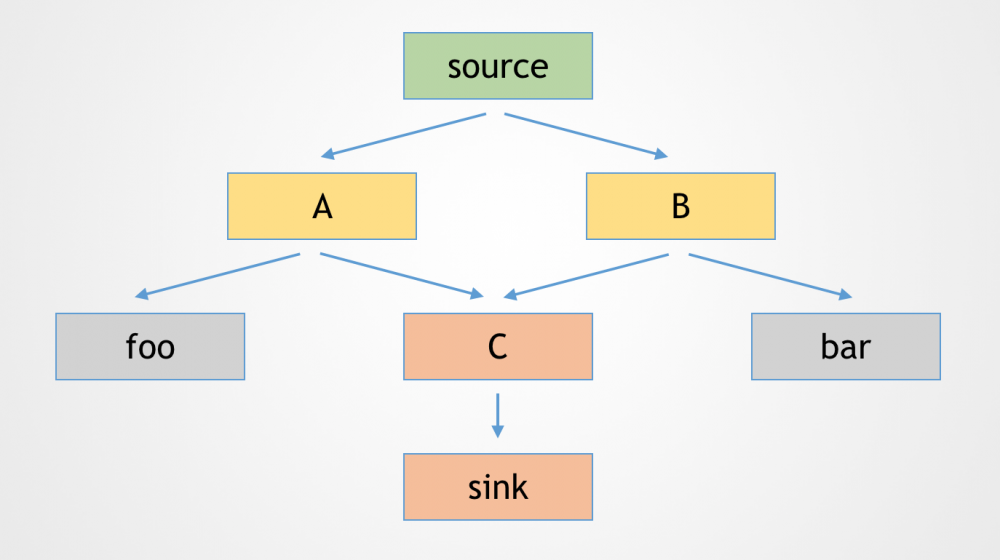
在上图所示的搜索中,如果先走通了source->A->C->sink这条调用链,那么当再遍历到source->B->C时,由于节点C之前已经访问过,就会直接跳过。因此,最终输出的调用链就只有source->A->C->sink这一条。如果source->A->C->sink是实际可用的,那影响还不大;但如果因为某些原因,例如方法A中有条件判断等限制,使得A->C实际是无法触发的,只有source->B->C->sink是真正可用的调用链,那么如此这般跳过已访问节点,就会造成漏报。
为了解决这一问题,我们更改了树的遍历方式为深度优先(DFS),并记录了全部可能的调用链。当然,这里面也有一些坑,例如需要检查节点是否重复出现以防止死循环,设置最大深度以控制运行时间,记录已访问节点的下方通路情况以减少重复工作,等等。通过这种方式再次对Xstream进行测试,并以Base64Data.get()方法作为source,以Method.invoke()作为sink,ImageIO的调用链
便出现在结果中。另外,还发现了如下类型的的调用链:

不过,改成DFS并记录全部可能的调用链后,由于路径爆炸的原因,即使设置了最大遍历深度,搜索所消耗资源还是会大幅上升,这一点还需要后续的优化。另一种思路是,仍然采取之前的BFS,并人工检查生成的调用链,把无效的调用从callgraph中删除,随后再次运行BFS,如此重复直至找到可用的调用链。
4. 小结
gadgetinspector 的出现,将之前大量的人工查找工作交由不知疲倦的机器完成,从而提高了工作效率。当然,目前的 gadgetinspector 和我们改进的版本,仍然存在一些问题,也希望作者或者其他感兴趣的研究人员能够更好地解决这些问题。
本文由 Galaxy Lab 作者:GalaxyLab 发表,其版权均为 Galaxy Lab 所有,文章内容系作者个人观点,不代表 Galaxy Lab 对观点赞同或支持。如需转载,请注明文章来源。
正文到此结束
- 本文标签: 构造方法 测试 时间 XML 删除 工作原理 静态方法 编译 js 代码 Collections http Struts2 字节码 web https 漏洞 json src Collection JVM apache struct 数据 parse dataSource IO equals java ip 调试 遍历 开发 ORM HashMap rmi 自动化 UI App 参数 message 本质 递归 源码 map CTO list 文章 stream classpath 安全 Apple value ACE 希望
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

