Android技术栈(五)HashMap和ArrayMap源码解析

1 总览
WARNING!!:本文字数 较多 , 内容 较为 完整 并且部分内容难度 较大 ,阅读本文需要 较长 时间,建议读者 分段 并 耐心 阅读.
本文会对 Android 中常用的数据结构进行源码解析,包括 HashMap(有红黑树) + ArrayMap
本文ArrayMap的源码来自 Android Framework API 28 和 AndroidX
//AndroidX implementation 'androidx.collection:collection:1.1.0-alpha03' 复制代码
2 HashMap<K,V>
本着 全世界 都知道面试一定会问 HashMap 的前提下,我们第一个分析 HashMap .
首先说明,并发时 只读不写 是没有问题的,但是并发时 有读有写 时会出现问题, HashMap 不是 线程安全的,并且在 JDK<=1.7 多线程情况下调用 put 引起扩容时还有可能导致循环链表问题,从而死循环使 CPU 占用率变成 100% .本文分析的是 JDK=1.8 这里只是简单提一下,不做展开讨论,有兴趣的同学可以自行查阅资料.
HashMap 是一种散列表,是一种典型的用空间换时间的数据结构,在内部使用拉链法处理 Hash 碰撞,也就是说在 Hash 后自己要放到表里时,发现自己的坑已经被别人占了,那就把之前的占坑者作为链表的头结点,自己作为下一个结点连到后面去.
//就像这样
[ Node<K,V> , null , Node<K,V> , null , Node<K,V> , null , Node<K,V> , null , null ......]
↓ ↓ ↓
Node<K,V> Node<K,V> Node<K,V>
↓ ↓
Node<K,V> Node<K,V>
↓
Node<K,V>
复制代码
在 JDK 1.8 中,链表长度是有一个临界值的,因为过长的链表会增大平均搜索时间,所以当链表长度大于 8 时,将链表转换为 红黑树 ( 本文不会规避这个话题,会讲红黑树,所以中间有一段会非常高能,请读者做好准备 ),以提高搜索效率.
在理想情况下 HashMap 查找元素的的时间复杂度为 O(1) ,这个复杂度会随负载因子的变大而变大,当负载因子变大时,同样容量的 HashMap 中能够存储更多的元素,但是同时也会导致 Hash 碰撞变得更加频繁,从而降低 HashMap 的搜索效率.
2.1 构造器
首先当然要从构造器开始说起:
这里我们要区分容量 (Capacity) 和大小 (Size) 这两个概念,容量是指 HashMap 中桶的数量,也就是存放同一个 Hash 的位置的数量,而大小则是该 HashMap 中总共存了多少个键值对.
initialCapacity 为初始容量,这个值并不是 HashMap 实际的容量,因为 HashMap 的容量必须是 2 的幂,所以这个值在后面会被处理,变成 2 的幂, loadFactor 负载因子, MAXIMUM_CAPACITY 是 HashMap 的最大容量在代码中是一个int,值为 1<<30 ,因为最高位是符号位所以不能 <<31 ,这样一来就能表示出用 int 存储的 2 的幂的最大正整数
//构造函数内主要是做一些检查参数的工作
//重点看tableSizeFor这个方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//初始化临界值
this.threshold = tableSizeFor(initialCapacity);
}
复制代码
构造器的末尾走到了 tableSizeFor 这个方法里.我们进一步追踪到 tableSizeFor :
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
复制代码
这么多位移运算符这是要干啥呢?
前面说过 HashMap 的容量必须是 2 的幂, tableSizeFor 所做的工作其实就是找到最接近于你所给 initialCapacity 的 2 的幂.
要解析这里的代码,我们要先知道参数 cap 的范围是怎样的,通过看之前的构造函数,我们知道参数 cap 肯定是 大于 0 的,所以接下来就要分两种情况了.
- 如果是 cap 为 1 的情况.那么
n |= n >>> 1和下面的 4 行代码都可以跳过,因为>>>是 无符号 右移运算符,当 cap 为 1 时,n 为 0,对其进行>>>和|=后其值还是0,最后经过下面的两个三元运算符,获得的返回值是 1 ,也就是 2 的 0 次幂. - 如果 cap 不是 1 ,那我们先假定它是 9 , 9 不是 2 的幂,它的二进制表达为
...0001001,那么 n 的二进制表示就是...0001000
执行>>> 1 得到 ...0000100 执行|= 得到n为 ...0001100 执行>>> 2 得到 ...0000011 执行|= 得到n为 ...0001111 执行>>> 4 得到 ...0000000 执行|= 得到n为 ...0001111 ... 复制代码
最终我们会得到 ...0001111 也就是1 + 2 + 4 + 8 = 15,诶不是说好的 2 的幂吗?这不是 15 吗,看到 return 语句的最后一句了没有,还要 +1 ,所以返回的值是 16 还是 2 的幂,并且是最接近于 9 的二的幂.
那如果我们拿 8 作为 cap 会怎样呢? 8 是 2 幂,二进制表示为 ...0001000 ,进行 -1 后就是 ...0000111
执行>>> 1 得到 ...0000011 执行|= 得到n为 ...0000111 ... 复制代码
你会发现他变回去了,这就是这个算法的神奇之处...所以下面的就不用分析了.
这是 HashMap 的另一个构造器,就是调用了上面的那个构造器而已. DEFAULT_LOAD_FACTOR 的值为 0.75 听说是经过测试过的比较理想的值,自己没有测试过.
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
复制代码
这个构造器也差不多,不过没有设置 initialCapacity ,其实是它在扩容函数 reszie 中设置了,这样构造的 HashMap 拥有默认容量 16.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
复制代码
下面继续看下一个构造器
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
复制代码
putMapEntries 方法除了构造器会调用,其实在其他时候也会被调用但是构造器调用时参数 evict 为 false ,其他时候是 true .
这里涉及到几个字段,要先说一下,分别是 table , threshold , loadFactor
//HashMap管理的节点表,在第一次使用时初始化,并根据需要调整大小 //分配时,长度总是2的幂 //用数组保存,也可以叫它桶 transient Node<K,V>[] table; //扩容的临界值,由负载因子*当前容量得到 int threshold; //负载因子 //是当前最多能使用的桶于总桶数的一个比例 final float loadFactor; 复制代码
我们跟着来到 putMapEntries
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
//s等于0就什么都不做
if (s > 0) {
//table==null,也就是第一次初始化
if (table == null) { // pre-size
//加进来的Map的大小除以负载因子得出新的临界值
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//如果新的临界值比当前的大,则将它转换为2的幂
if (t > threshold)
threshold = tableSizeFor(t);
}
//当前表非空,加进来的Map大小已经大于旧的临界值,直接扩容
else if (s > threshold)
resize();
//将值依次插入表中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
复制代码
2.2 扩容
因为上面涉及到了 resize 这个方法,而且这个方法非常重要,是 HashMap 的扩容方法,不接着讲它就讲不下去了.
final Node<K,V>[] resize() {
//旧表
Node<K,V>[] oldTab = table;
//旧表大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//之前的临界值
int oldThr = threshold;
int newCap, newThr = 0;
//如果当前表非空
if (oldCap > 0) {
//并且如果容量到达上限,不进行扩容,直接返回旧表
//并将临界值设置为不可能到达的Integer.MAX_VALUE
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//否则旧容量左移一位得到新容量,也就是翻倍
//如果翻倍后新的容量仍然小于最大容量
//并且旧容量是大于默认初始容量DEFAULT_INITIAL_CAPACITY(值为16)的
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//那么临界值也左移一位翻倍
newThr = oldThr << 1;
}
//如果当前表不是空表,并且已有临界值
//这种情况对应前面在构造函数中
//使用tableSizeFor(initialCapacity)对threshold的赋值
//表本身是空的,没有元素,所以要进行一次扩容
else if (oldThr > 0)
newCap = oldThr;
//在没有初始化临界值时
//先给他设置新的容量为DEFAULT_INITIAL_CAPACITY(值为16)
//然后使用默认负载计算出临界值
//这种情况对应上文中的第三个构造函数
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//防止新表的临界值为0,重新计算临界值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//new 新表
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果旧表不为空
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//取出相应位置的节点
if ((e = oldTab[j]) != null) {
//并将原位置置空,减少GC压力
oldTab[j] = null;
//如果这个节点(桶)只有一个元素
//也就是没有发生过Hash碰撞,没有别的节点连在后面
if (e.next == null)
//那么直接将其Hash到新表里
//我们之前一直说HashMap的容量是2的幂,这时它派上了用场
//这里也用了一种神奇的算法
//下面这行代码相当于hash对newCap取模
//只不过使用位运算效率更高
//不相信的话我们可以试试
//hash=7 ...0111
//newCap=4 ...0100
//newCap-1 ...0011
//hash&(newCap - 1) ...0011
//0011等于3,没错就是这么神奇,而且这并不是偶然
//但在这里有一点需要注意
//不同的Hash值经过上面的计算后可能会得到相同的结果
//这也就是说
//在一个桶中连成的链表上的不同的节点的Hash值有可能是不同的
//所以在同一个桶中并不代表他们的Hash值就一定相等了
newTab[e.hash & (newCap - 1)] = e;
//这里是对红黑树的处理,这里先暂时跳过,下面专门讲
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
//下面开始处理有Hash碰撞发生的桶
//也就是那些连成链表的
//要放在原本位置的链表
Node<K,V> loHead = null, loTail = null;
//要放在新位置的链表
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//开始处理
do {
next = e.next;
//用节点的Hash与旧表容量进行与运算
//其实也就是跟取模差不多
//只是现在用来判断Hash值是否大于等于旧表容量
//若计算结果为0,则表示小于旧表容量
//则放在原来的位置
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//否则就是大于旧表容量
//放到新位置
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//旧位置
if (loTail != null) {
//清除原来的尾巴
loTail.next = null;
newTab[j] = loHead;
}
//新位置
//新位置等于原位置+旧表容量
if (hiTail != null) {
//清除原来的尾巴
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
//这里举个例子说清楚一点
//由于扩容后的HashMap的容量是原来的两倍
//如果之前的容量是32,那么扩容后就是64
//Hash值为16的会被放到原来的位置16
//Hash值为48的原本是和16放一起的
//但是扩容后就被放到48这个位置了
}
}
}
}
return newTab;
}
复制代码
2.3 增删查
2.3.1 增加元素
一般我们都是调用 put 对 HashMap 进行添加操作,今天我们对它的源码进行分析
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
复制代码
跟踪到 putVal ,我们发现上面的 putMapEntries 其实也调用了该函数
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//若表空,先进行一次扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//和之前一样,与运算,实际上是取模
//若位置刚好为空则创建新节点放进桶中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//若位置不为空
else {
Node<K,V> e; K k;
//先依次使用Hash,引用,以及equals函数比较相等性
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//若完全相等,直接赋值给下一步需要处理的变量e
e = p;
//若为红黑树,则作特殊处理
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//否则遍历该桶的链表
for (int binCount = 0; ; ++binCount) {
//在桶中没找到Key相等性完全一致的节点
//则创建新节点对该桶的链表进行尾插
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//长度大于TREEIFY_THRESHOLD(值为8)
//转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//找到了就退出循环,下一步要处理的变量是e
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//e不为null,也就是有要处理的节点
if (e != null) {
//保存旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//写入新值
e.value = value;
//空方法,LinkedHashMap实现
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//更新size,并判断是否要扩容
if (++size > threshold)
resize();
//空方法,LinkedHashMap实现
afterNodeInsertion(evict);
return null;
}
复制代码
我们注意到 put 还有一个 hash 方法,它的实现是这样的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
HashMap 作为 JDK 中泛用的集合,必须考虑各种极端情况,所以是不能假设作为 K 泛型参数的类型有良好定义的 hashCode 方法的,所以在内部还要在 hash 一次,这样做能让 hash 碰撞更少的发生从而提升 HashMap 的效率.
2.3.2 删除元素
我们通常使用 remove 来移除 HashMap 中的元素
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
复制代码
跟踪到 removeNode 方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//若表非空,则用Hash计算出应该在表中的所在的桶的下标,并获取该节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//能到这里说明节点非空
//与之前一样,比较key相等性
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//若完全相等,直接赋值给下一步需要处理的变量node
node = p;
//相等性不匹配,且有下一个节点时
else if ((e = p.next) != null) {
//红黑树获取节点要特殊处理,下文展开讨论
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//在桶中遍历链表查找节点
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//有需要处理的节点
//之前传参时matchValue=false,不需要匹配值
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//红黑树特殊处理,下文讨论
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//从链表中将该节点移除
//p为链表头,移除链表头
else if (node == p)
tab[index] = node.next;
//node为链表的中间节点
else
p.next = node.next;
++modCount;
//减小size
--size;
afterNodeRemoval(node);
//返回旧值
return node;
}
}
return null;
}
复制代码
但是当我们调用另一个重载时 matchValue 为 true ,这时就要匹配值了.
@Override
public boolean remove(Object key, Object value) {
//此时matchValue为true
return removeNode(hash(key), key, value, true, true) != null;
}
复制代码
2.3.3 查找元素
我们一般使用 get 来获取 HashMap 中的值
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
复制代码
跟踪到 getNode 方法,相比起前几个方法,这个方法就简单许多
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//判断表是否非空,该Hash位置的桶中是否有节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//查看第头节点是否相等性是否完全匹配
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
//匹配直接返回
return first;
if ((e = first.next) != null) {
//红黑树特殊处理
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//遍历查找节点
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
复制代码
当我们使用某种类型作为 HashMap 泛型参数 K (也是就是键-值对中的键)时,该类型的对象的 hashCode 函数返回的值应该是不变的,否则当 HashMap 进行 Hash 时可能会得到错误的位置,有可能导致 key-value 对实际存储到了 HashMap 中,但就是找不到的情况.
2.4 红黑树
WARNING:前方即将进入高能区,不了解二叉树的建议先去看一点二叉树的有关知识再来看本节.
每次看别人在解析 HashMap 的时候一讲到红黑树就戛然而止,要不然说后面单独开一篇文章来讲,要不然就直接太监了,所以我看别人都不说那索性我就自己研究去了.
需要读者注意的是,看红黑树这一节需要你有一定二叉树的基础知识,并且有一定耐心去理解,笔者会尽可能地讲清楚,但不可能面面俱到,如果在阅读过程中发现有不能理解的名词,还请自行百度.
2.4.1 什么是红黑树?
红黑树是一种自平衡 二叉 查找树,虽然它的实现非常复杂,但即使是在最坏情况下运行也能有很好的效率.比如当红黑树上有 N 个元素时,它可以在 O(log N) 时间内做查找,插入和删除.
当 HashMap 在桶中的链表长度超过 8 时使用它,链表在做查找时的时间复杂度是 O(N) ,使用红黑树会将效率提高不少.
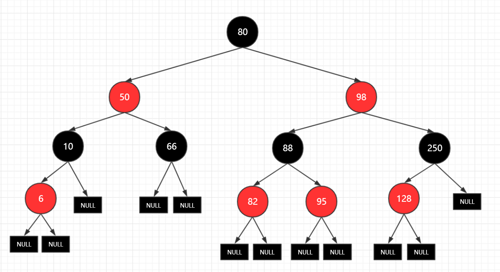
作为一种查找树,它需要符合一些规则:
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 左、右子树也分别为二叉排序树
一颗红黑树的样子,大概就像这样(图是用Process On画的)
2.4.2 红黑树的5个性质
除了二叉查找树所具有的一些性质,所有的红黑树还具有以下的 5 个性质:
null
因为插入,查找,删除操作时, 最坏的情况 下的时间都与二叉树的 树高 有关,根据性质 4 我们知道不会有两个直接相连的红色节点.接着,根据性质 5 我们又可以知道,因为所有最长的路径都有相同数目的黑色节点,这就保证了没有可能会有一条路径的长度能有其他路径的两倍这么长.
上面的性质使红黑树达到了相对平衡,但实际上,红黑树也是最接近平衡的二叉树.
2.4.3 树化
之前我们一讲到 TreeNode 就跳过,现在我们对它进行分析
我们先分析 TreeNode 这个嵌套类是怎么来的
//追根溯源 //HashMap.TreeNode // -继承-> LinkedHashMap.LinkedHashMapEntry // -继承->HashMap.Node // -实现->Map.Entry //这样的好处是TreeNode既可以当做LinkedHashMap.LinkedHashMapEntry来使用 //也可以当做HashMap.Node来使用 //TreeNode包含以下几个字段 //父节点 TreeNode<K,V> parent; //左子节点 TreeNode<K,V> left; //右子节点 TreeNode<K,V> right; //TreeNode也是由之前的链表树化而来的 //prev指向的是原本还是链表时的前一个节点 //删除时需要取消下一个链接 TreeNode<K,V> prev; //是不是红色节点 boolean red; //并从HashMap.Node继承了next //Node是链表节点,next指向链表中的下一个节点 Node<K,V> next; 复制代码
回忆之前的代码,我们知道当链表长度超过 8 时会调用 treeifyBin 这个方法对链表进行树化
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//MIN_TREEIFY_CAPACITY的值为64
//这是会触发树化的容量最小值
//若未达到这个值
//则HashMap选择的策略是使用resize进行扩容以减少Hash冲突,而非树化
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
//先检查一波这个地方是否真的要树化(是否为空)
else if ((e = tab[index = (n - 1) & hash]) != null) {
//其实这里先把它转换成了双链表方便下一步操作
//hd是链表头,tl是链表尾
TreeNode<K,V> hd = null, tl = null;
do {
//HashMap.Node将转换为HashMap.TreeNode
TreeNode<K,V> p = replacementTreeNode(e, null);
//若尾巴为空说明是第一次循环
if (tl == null)
//先设置头结点
hd = p;
else {
//将当前新生成的节点p的前驱设置为原本的尾巴
p.prev = tl;
//然后原本的尾巴的下一个节点指向新生成的节点
tl.next = p;
}
//更新尾巴
tl = p;
} while ((e = e.next) != null);
//给节点表赋值
if ((tab[index] = hd) != null)
//并开始实际的树化
hd.treeify(tab);
}
}
//继续跟踪源码到TreeNode#treeify
final void treeify(Node<K,V>[] tab) {
//树根
TreeNode<K,V> root = null;
//从头开始遍历
for (TreeNode<K,V> x = this, next; x != null; x = next) {
//取下一个节点
next = (TreeNode<K,V>)x.next;
//将左右子树置空
x.left = x.right = null;
//若根节点为空,则把当前节点设置为根节点
if (root == null) {
x.parent = null;
//根节点是黑色的
x.red = false;
root = x;
}
//否则取出该节点的Hash值和Key值,准备进行插入
//变量x是带插入节点
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
//从根节点开始遍历红黑树,查找插入位置
//变量p代表的是当前遍历到的节点
for (TreeNode<K,V> p = root;;) {
//dir代表两个节点比较的结果
//ph是p的Hash值
int dir, ph;
//pk是p的Key值
K pk = p.key;
//如果要插入的节点的Hash值小于当前遍历到的节点
if ((ph = p.hash) > h)
//比较结果为-1,继续往左子树找
dir = -1;
else if (ph < h)
//否则为1,继续往右子树找
dir = 1;
//如果出现两者相等的情况
//则调用comparableClassFor
//瞄一眼作为Key的类是否实现了Comparable
//如果实现了
//就继续调用compareComparables进行比较
//如果比较结果还是相等
//就到tieBreakOrder中去比较
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
//按照每次比较得到的结果
//不是树叶则选择左子节点还是右子节点
//如果该节点不是树叶(不为null),则继续向下找
//否则先将x其插入到那个树叶原有的位置
//上述过程实际上就是将其先变成一颗二叉查找树的过程
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//在插入结束后再做平衡处理
root = balanceInsertion(root, x);
break;
}
}
}
}
//把红黑树的根节点移动成为桶中的第一个元素
moveRootToFront(tab, root);
}
//回到刚才跳过的tieBreakOrder看看
//我们得知是调用了System#identityHashCode
//这个函数是根据对象在JVM中的的实际地址来返回Hash的
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
复制代码
balanceInsertion 这个方法比较复杂并且会在增加元素时用到,所以我们放到下文的 增加元素 中来讲.
2.4.4 左旋与右旋
现在我们补充一些二叉树左旋与右旋的知识,为后面做铺垫.
左旋的步骤:
- 选定一个节点 N 作为左旋操作的支点
- 该节点 N 代替 N 原本的父节点P的位置
- 原本的父节点 P 变成 N 的左子节点
- 如果 N 原本有左子节点,那么这个左子节点现在变成P的右子节点
是不是感觉像绕口令一样?那画个图吧(图是用Process On画的)
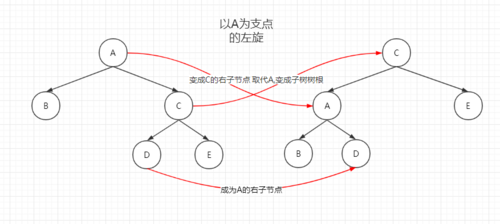
搞清楚左旋之后,右旋就可以类比出来了,下面是右旋的步骤:
- 选定一个节点 N 作为右旋操作的支点
- 该节点 N 代替 N 原本的父节点P的位置
- 原本的父节点 P 变成 N 的右子节点
- 如果 N 原本有右子节点,那么这个右子节点现在变成 P 的左子节点
还是继续画一个图:

Java
中是如何实现的
//左旋
//root是树根
//p代表上图左旋中的A
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> r, pp, rl;
//因为p是A,所以r就是C了
if (p != null && (r = p.right) != null) {
//就像上图一样,C的左子节点若存在
//就变成A的右子节点
if ((rl = p.right = r.left) != null)
rl.parent = p;
//C取代A变成子树树根
if ((pp = r.parent = p.parent) == null)
//如果A之前刚好是二叉树的树根
//则要保证它是黑色的
(root = r).red = false;
else if (pp.left == p)
//替换A
pp.left = r;
else
//替换A
pp.right = r;
//C的左节点变成A
r.left = p;
p.parent = r;
}
return root;
}
//右旋以此类推
//不再赘述
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p)
复制代码
这里最后说个题外话,让大家放松一下,在 rotateLeft 方法的源码上面有这么一句注释
// Red-black tree methods, all adapted from CLR 复制代码
它的意思就是: 红黑树的方法,均改变自CLR
看到这个的我就当场就笑出来了,因为笔者半年前还是一个学 C# 的,现在转 Android 之后,总感觉 Java 之于 C# 有一种莫名的讽刺感,下面这段话可能能够更贴切地表达我的心情:
震惊!从 响应式编程 到 MVVM , Microsoft 研究出来的新技术竟然总是最先在 Java 上大规模使用!Microsoft 竟然在背后源源不断地为 Java 提供技术支持? Oracle 坐享其成恐成最大赢家.
2.4.5 增加元素
在给红黑树增加元素时有两个步骤:
- 把红黑树当做二叉查找树做 插入 操作
- 把插入后的二叉查找树重新 调整 成红黑树
给二叉排序树插入元素的思路很简单,一句话就能讲清楚.因为树是已经排序过的,从根节点开始遍历和比较,如果要插入的节点的Hash 小于 遍历到的节点的Hash,则进入左子树,否则进入右子树,如此递归,直到找到一个空叶子把节点插入即可.
由于插入后红黑树可能会退化成二叉查找树,所以接下来对二叉查找树进行调整使它重新变成红黑树.左旋和右旋不会改变二叉查找树的性质,所以在给原红黑树按照二叉查找树的排序规则插入新的节点后,我们需要使用左旋和右旋来使这颗二叉查找树重新调整成红黑树.
在插向红黑树插入一个元素时,我们把要新插入的设置成红色,至于为什么要这么做,我们结合红黑树的 5 条性质来分析一下就知道了.
null
这样我们在调整红黑树的时候就只需要考虑性质 2 和 4 带来的问题就可以了.
在插入时会出现以下几种情况:
- 若之前是空树,那么插入后将节点纠正为黑色即可
- 插入后父节点是黑色的,这种情况不用处理,因为红色节点不影响平衡
- 插入后父节点是红色的,因为根节点必须是黑色的,所以被插入节点的祖父节点(父节点的父节点)必然存在,此时就要根据叔叔节点(祖父节点的另一个子节点)的情况进行进一步处理.
为了分析第三种情况,下面我们设一些变量方便进一步说明, x 为当前要处理的节点, xp 为父 x 的父节点, xpp 为 x 的祖父节点(父节点的父节点), xu 为叔叔节点(祖父节点的另一个子节点).并且在一开始,我们把插入的节点当做 x.
注意!!:下面的情况只适用于 xp 是 xpp 的 左子节点 的情况, xp 是 xpp 的 右子节点 的情况需要进行 对称(左右交换) 处理,如果你在自己尝试的时候一定要注意这个 大前提 .
- 第一种情况是 红叔 ,也就是自己( x )红,父亲( xp )红,叔叔( xu )也红的情况,此时祖父节点( xpp )必然是 黑色 ,在这种情况下需要变色,将 xp 和 xu 由 红色 => 黑色 ,将 xpp 由 黑色 => 红色 ,在此次调整完毕后, xpp 可能会破坏性质 4 (不允许有两个相连的 红 节点),所以将当前的 xpp 设置为 x 进行进一步调整.
- 第二种情况是 黑叔 并且自己( x )是自己父节点( xpp )的 右子节点 ,此时将当前的 xp 设置为 x,然后以 x 为支点进行 左旋 ,经过此次调整后,问题其实并没有解决,只是把 情况二 变成了 情况三 ,所以还是要为 x 进行进一步调整.
- 第三种情况是 黑叔 并且自己( x )是自己父节点( xpp )的 左子节点 ,此时祖父节点( xpp )必然是 黑色 ,是需要把 xpp 由 黑色 => 红色 ,把 xp 由 红色 => 黑色 ,然后以 xpp 为支点进行 右旋 ,这样就解决了问题.
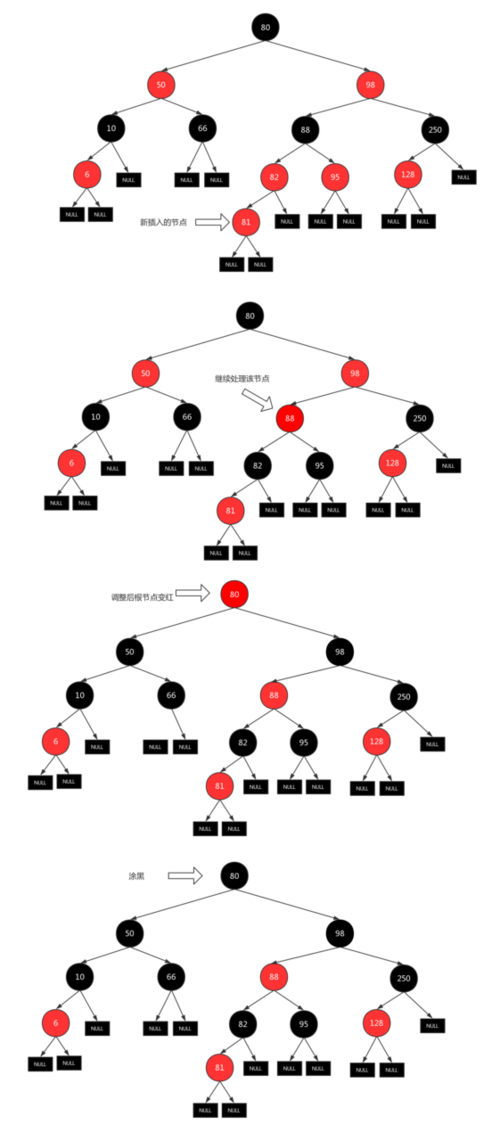
下面我们画两张图来解释一下.下面这棵红黑树调整的步骤:
- 插入 81 (在 82 的左子节点),红黑树退化成二叉查找树
- 符合 三红 的情况,直接变色,然后将 xpp 变成 x
- 还是符合 三红 的情况,变色
- 此时算法已经到达根节点,将根节点涂黑即可
- 插入 150 (在 120 的右子节点),红黑树退化成二叉查找树
- 是 黑叔 并且 x 是右子节点,把 xp 变成 x,然后直接左旋
- 还是 黑叔 并且 x 是现在是左子节点,将 xp 涂黑,然后将 xpp 涂红,右旋
- 已经重新变成红黑树
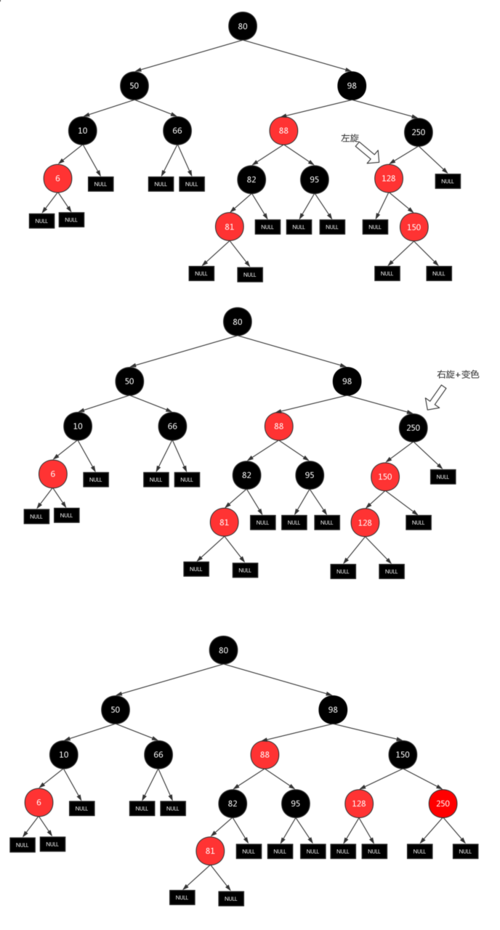
这个算法的核心思想就是:将影响红黑树性质的红色节点向上移动到根节点,并将根节点设置成黑色.
经过上面的一通分析,我们只是仅仅知道了原理,离源码分析实际上还很远,不得不说这数据结构真的太狠了,感觉比 HashMap 本身还要复杂.
之前我们对 HashMap 的源码进行分析时,一分析到 putTreeVal 时就跳过了,现在我们在重点看看它的源码
//获取根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
//直到父节点为null
if ((p = r.parent) == null)
return r;
r = p;
}
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
return new TreeNode<>(hash, key, value, next);
}
//可以看到这里和TreeNode#treeify差不多
//就是尝试这在红黑树里找已近存过指定Key的节点
//如果实在在不到,就给该Key插入一个新的节点
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
//可能会用到的变量,如果Key实现了Comparable
Class<?> kc = null;
//标记是否已经遍历查找过
boolean searched = false;
//拿到跟节点
TreeNode<K,V> root = (parent != null) ? root() : this;
//从根节点开始遍历
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
//如果遍历到的节点的Hash值大于要插入的Key的Hash值
//则继续dir赋值为-1
//会继续往左子树搜索
if ((ph = p.hash) > h)
dir = -1;
//否则往右子树搜索
else if (ph < h)
dir = 1;
//大于和小于的情况已近被排除,现在Hash必然相等
//如果Key也相等,那就直接返回
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
//这里并没有直接修改节点的value
//但你若回去看putVal,就可以知道它实际上在putVal中修改了
return p;
//若是上面那个else if没有匹配
//则说明Hash相等,但是Key不等,这下就要进一步比较
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
//到这里只有两种情况
//1.Key没有实现Comparable
//2.实现了Comparable并且比较还是相等了
//我们知道通过上面的比较,Hash是已经相等了
//但是Key不等,所以就要在该节点的左右子树继续进行搜索
if (!searched) {
TreeNode<K,V> q, ch;
//遍历查找只会进行一次
//待会继续向下找时不会再遍历
//只是找插入位置
searched = true;
//find是一个递归方法,比较简单
//作用是在这个子树里查找与指定的Key完全匹配的节点
//本着抓大放小的原则
//这里我选择跳过,节约大家时间
//感兴趣的话建议自己去看源码
//下面这里短路求值,只要在一边找到了,就直接返回
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
//如果没有找到
//那就使用对象地址进行比较
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
//根据上面得到的dir
//瞄一眼左子树或右子树是否为空
//为空就插入新节点
//如果不为空,即p!=null
//则下一次迭代的节点p被赋值,继循循环
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
//创建新节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//同时还要保持双链表的结构
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
//没完,现在还只是一颗二叉查找树而已
//还要进行平衡处理
moveRootToFront(tab, balanceInsertion(root, x));
//返回null,则外层的putVal啥都不做
return null;
}
}
}
复制代码
下面就是期待已久的 balanceInsertion 了,如果你理解了上面红黑树的理论知识,看这个你会觉得很轻松.
//新插入的元素虽然使整棵树依然保持为二叉查找树
//但是这棵树可能还不够平衡
//所以要进行调整
//该方法的返回值是调整完成后的树根
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//将新插入的节点初始化为红色
x.red = true;
//x->当前节点
//xp->父亲节点
//xpp->祖父节点
//xppl和xppr->分别是祖父节点的左子节点或右子节点
//现在我们开始回忆刚才在理论介绍中罗列的几种情况
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//之前是空树
if ((xp = x.parent) == null) {
//涂黑,然后返回即可
x.red = false;
return x;
}
//这里是方法的第二个出口
//如果父节点是黑的
//又或者是祖父节点已经不存在
else if (!xp.red || (xpp = xp.parent) == null)
//算法结束,直接返回根节点
return root;
//若父节点是祖父节点的左子节点
if (xp == (xppl = xpp.left)) {
//出现三红的情况,变色
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
//否则就要看自己是左子节点还是右子节点
else {
//是右子节点
if (x == xp.right) {
//更新当前节点x,并左旋
root = rotateLeft(root, x = xp);
//更新xp和xpp
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//若是左子节点
if (xp != null) {
//父节点变黑
xp.red = false;
if (xpp != null) {
//祖父变红
xpp.red = true;
//右旋,且当前节点不变
root = rotateRight(root, xpp);
}
}
}
}
//若父节点是祖父节点的右子节点
//与上面类似,只是把左右交换了而已,故不再赘述
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
复制代码
2.4.6 删除元素
PS:望理解,笔者能力有限,待日后补充.....
2.4.7 查找元素
在查找元素时调用的是 getTreeNode 方法,该方法比较简单,调用了我们之前分析过的 find 方法.
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
复制代码
3 ArrayMap<K,V>
其次,在 Android 中除了 HashMap 可能最重要的就是也实现 Map 接口的 ArrayMap 了,它也是 非 线程安全的,但也是允许并发地 只读不写 .
ArrayMap 在内部使用开地址法处理Hash碰撞,也就是说存值时对Key先Hash一波,然后算出自己在数组中应该存放的位置的下标,如果自己拿着下标去存的时候发现自己的坑已经被别人给占了,那自己就往后占一个坑,如果坑还被占,那就继续往下一个坑看,直到有没被占的坑位置把自己放进去.
ArrayMap 中内部的数组是经过排序的,并使用二分查找法搜索元素,所以时间复杂度是 O(log N) ,比 HashMap 慢,而且数据规模越大慢得越多,个人认为在数据规模 <=100 时使用 ArrayMap 是比较理想的,如果超过这个值还是推荐你用 HashMap 吧.
注:系统 ArrayMap 与 AndroidX 的 ArrayMap 实现上有所不同,下文中的 ArrayMap 来自AndroidX
3.1 适用场景
Google 说 ArrayMap 是一种节省内存的 Map 实现,比较适用于 APP 开发这种 Map 中元素较少的情况.
但是然并卵,在看开源项目的源码时,我发现实际上是很多人还是更倾向于使用 HashMap .我个人也比较推崇使用 HashMap ,因为 ArrayMap 不够跨平台,节省的那点内存也实在是杯水车薪,而且 HashMap 速度更快,也能适应未来数据规模变大时的改变.
我的意见是,在自己写的库和内存不吃紧的APP里,最好不要用ArrayMap.
3.2 构造器
ArrayMap 继承自 SimpleArrayMap 并实现了 Map 接口, ArrayMap 这个类里基本上是空的,具体实现都在 SimpleArrayMap 中.
public class ArrayMap<K, V> extends SimpleArrayMap<K, V> implements Map<K, V> 复制代码
从 ArrayMap 追踪源码到 SimpleArrayMap ,查看其构造器
public ArrayMap() {
super();
}
//实际调用
public SimpleArrayMap() {
//EMPTY_INTS为new int[0]
mHashes = ContainerHelpers.EMPTY_INTS;
//EMPTY_OBJECTS为new Object[0]
mArray = ContainerHelpers.EMPTY_OBJECTS;
mSize = 0;
}
//涉及的两个字段
//mHashes用来保存Key值对应的Hash值
//它的大小就是ArrayMap的容量
int[] mHashes;
//与HashMap不一样,没有Node这一说
//只使用一个数组mArray来保存Key和Value
//mArray的长度永远是mHashes的两倍
//Key的Hash在mHashes中所在的位置的下标index
//在没有Hash冲突时index*2的位置就是mArray中存Key的位置
//index*2+1的位置就是mArray中存Value的位置
Object[] mArray;
//在mArray中Key和Value以以下的形式存储
//我们举一个容量为4的例子
//那么mArray的长度就等于8
//在ArrayMap中Key和Value以相邻的形式存在mArray中
//[ Key1 , Value1 , null , null , null , null , Key2 , Value2 ]
// ↑ ↑ ↑ ↑
// 键值对KV 键值对KV
复制代码
可以看到这个构造器基本没做什么事,那我们继续看下一个构造器
public ArrayMap(int capacity) {
super(capacity);
}
//实际调用
public SimpleArrayMap(int capacity) {
//若初始容量为0,就和上面那个构造函数一样
if (capacity == 0) {
//ContainerHelpers是一个工具类
mHashes = ContainerHelpers.EMPTY_INTS;
mArray = ContainerHelpers.EMPTY_OBJECTS;
}
//否则分配新数组
else {
allocArrays(capacity);
}
mSize = 0;
}
复制代码
3.3 缓存与扩容
顺着源码继续跟踪到 allocArrays
下面面涉及到几个字段,这里提前说明一下,分别是 mBaseCache , mBaseCacheSize , mTwiceBaseCache 和 mTwiceBaseCacheSize .
这就不得不说到 ArrayMap 的缓存机制, ArrayMap 的空间策略十分保守,对于用来保存 Hash 的 mHashes 与用来保存 Key 和 Value 的 mArray 有两个缓存,分别用来缓存容量为 4 和 8 ArrayMap 在扩容时被换下的数组,并且连成链表.
//第一个缓存,实际上是一个链表
//用来缓存长度为4的ArrayMap在扩容时换下的数组
static @Nullable Object[] mBaseCache;
//第一个缓存的大小
static int mBaseCacheSize;
//第二个缓存,实际上是一个链表
//用来缓存长度为8的ArrayMap在扩容时换下的数组
static @Nullable Object[] mTwiceBaseCache;
//第二个缓存的大小
static int mTwiceBaseCacheSize;
//以mBaseCache为例子
//连成的链表大概像这样
//mBaseCache=>[ Object[] , int[] , null , null.......]
// ↑ ↑
// ↑ 对应的mHashes
// ↑
// 另一个长度为4的数组=>[ Object[] , int[] , null , null......]
// ↑ ↑
// ↑ next mHashes
// next...
复制代码
上面的链表,不知道你看懂了没有,反正我第一次看的的时候就在想,居然还有这种操作?充分利用了数组空间又实现了链表结构.
当有 ArrayMap 实例进行扩容有换下的 mHash 和 mArray 刚好满足条件(也就是 mHash 的大小为 4 mArray 的大小为 8 以及 mHash 的大小为 8 mArray 的大小为 16 时)时,就由 ArrayMap 上的这些的静态缓存来接收这些数组.
因为这些字段是静态的,所有实例共享,并发的时候就可能会出问题,所以我们看到了下面的代码使用了 synchronized 关键字在同步代码块中执行修改操作.
//该函数也是ArrayMap的扩容函数
private void allocArrays(final int size) {
//BASE_SIZE的值为4,若要分配的大小等于8
if (size == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {
//若为容量为8的缓存非空
if (mTwiceBaseCache != null) {
//取出该缓存赋值到array上
final Object[] array = mTwiceBaseCache;
//因为长度合适,可以直接mArray
mArray = array;
//更换头结点
mTwiceBaseCache = (Object[])array[0];
//取出缓存的int[]
mHashes = (int[])array[1];
//最后清理数组
array[0] = array[1] = null;
//链表长度减1
mTwiceBaseCacheSize--;
if (DEBUG) System.out.println(TAG + " Retrieving 2x cache " + mHashes
+ " now have " + mTwiceBaseCacheSize + " entries");
return;
}
}
}
//长度为4时的情况大同小异,不再赘述
else if (size == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCache != null) {
final Object[] array = mBaseCache;
mArray = array;
mBaseCache = (Object[])array[0];
mHashes = (int[])array[1];
array[0] = array[1] = null;
mBaseCacheSize--;
if (DEBUG) System.out.println(TAG + " Retrieving 1x cache " + mHashes
+ " now have " + mBaseCacheSize + " entries");
return;
}
}
}
//没有合适的缓存,则给它new新的数组
mHashes = new int[size];
//size左移一位相当于乘2
mArray = new Object[size<<1];
}
复制代码
3.4 增删查
3.4.1 增加元素
ArrayMap 并没有实现 put 方法, put 方法由它的父类 SimpleArrayMap 实现.
不过我们现在先不看 put ,而是先看 indexOf ,这个方法,否则接下来看 put 的时候会很难受
//这个函数如果返回正值
//则表示所hash的key在表中被找到
//将返回其在数组mHashes中的下标
//若返回负值
//则表示所hash的key在表中没有被找到
//将返回可以在表中插入的下标用~运算符按未取反后的值
int indexOf(Object key, int hash) {
final int N = mSize;
//如果数组为空那这个表里就没什么东西好找的
if (N == 0) {
//将0按位取反
//告诉调用方若要插入值,在0这个下标进行插入
return ~0;
}
//如果表非空,则使用Hash进入二分搜索
//如果找不到就返回一个负数
//也就是用~按位取反过的插入位置
//找到了就返回该Hash在mHashes中的下标
int index = binarySearchHashes(mHashes, N, hash);
//找不到了就直接返回
if (index < 0) {
return index;
}
//如果在mHash中找到了,那么还要比较Key
//看看自己的坑是不是已经被别人给占了
//如果占坑的刚好是自己,就将下标返回
//index<<1是将index乘2的意思
if (key.equals(mArray[index<<1])) {
return index;
}
//否则在mArray使用线性探索法一直向后找
//直到在下一个节点的Hash与自己的Hash不等
//或者在中mArray找到自己为止
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
//找到了就返回
if (key.equals(mArray[end << 1])) return end;
}
//向后找找不到就向前找
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
//找到了就返回
if (key.equals(mArray[i << 1])) return i;
}
//没找到,返回插入位置
//我们可以看到这个算法非常倾向于减元素插入到尽可能靠后的位置
//这样可以减少插入时需要复制的数组条目的数量
return ~end;
}
复制代码
然后我们继续进到刚才没讲的 binarySearchHashes 方法
//可以看到这个方法啥都没做
//而是把工作转给ContainerHelpers.binarySearch去做了
//同时我们也可以在这里看到ArrayMap是不允许并发编程的
//其中CONCURRENT_MODIFICATION_EXCEPTIONS的值为true
//表示如果发生ArrayIndexOutOfBoundsException那么一定是由于并发引起的
private static int binarySearchHashes(int[] hashes, int N, int hash) {
try {
return ContainerHelpers.binarySearch(hashes, N, hash);
} catch (ArrayIndexOutOfBoundsException e) {
if (CONCURRENT_MODIFICATION_EXCEPTIONS) {
throw new ConcurrentModificationException();
} else {
throw e;
}
}
}
//我们继续看ContainerHelpers.binarySearch
//这是一个非常常规的二分搜索
static int binarySearch(int[] array, int size, int value) {
//区间头
int lo = 0;
//区间尾
int hi = size - 1;
while (lo <= hi) {
//又是位运算,>>>为无符号右移运算符
//(lo + hi) >>> 1代表的就是两数相加后除2,不过效率更高
int mid = (lo + hi) >>> 1;
//取出中值
int midVal = array[mid];
//比较Hash,若传入的Hash更大
//说明该Hash在区间的后半段
//头lo变成中位数的位置+1
if (midVal < value) {
lo = mid + 1;
}
//否则就是在前半段
else if (midVal > value) {
hi = mid - 1;
}
//又或者说找到了
else {
return mid; // value found
}
}
//如果坑是没被占过的
//也就是说该Hash在mHashes中不存在
//那么返回的是该Hash在数组中该插入位置
return ~lo; // value not present
}
复制代码
indexOf 讲完了,但是我们现在还是不能开始讲 put ......因为 ArrayMap 的 Key 可以为 null ,所以要对为 null 的 Key 做特殊处理,那就是 indexOfNull 这个方法
int indexOfNull() {
final int N = mSize;
//这里和indexOf一样
if (N == 0) {
return ~0;
}
//也是二分搜索,只不过现在的Hash=0
//这里要注意的一点是虽然null的Hash=0
//但不代表其他Key值的Hash就不可以为0了
//Hash只是保证在Key相等的情况下Hash一定相等
//但是不保证Hash相等的情况下Key一定相等
//所以其他非null的Key依然可能得到为0的Hash
//所以依然可能会发生Hash碰撞
int index = binarySearchHashes(mHashes, N, 0);
//如果找不到,返回可插入的位置
if (index < 0) {
return index;
}
//如果找到的位置的Key刚好就是null
//那没什么好说了,直接返回
if (null == mArray[index<<1]) {
return index;
}
//依然是线性探索法,向后找
int end;
for (end = index + 1; end < N && mHashes[end] == 0; end++) {
if (null == mArray[end << 1]) return end;
}
//找不到就向前找
for (int i = index - 1; i >= 0 && mHashes[i] == 0; i--) {
if (null == mArray[i << 1]) return i;
}
//找不到就返回插入位置
return ~end;
}
复制代码
有了上面的充足准备后,现在我们可以开始看 put 了
public V put(K key, V value) {
//表的旧大小
final int osize = mSize;
final int hash;
//该Key的Hash在mHash中的下标
int index;
//如果Key为null,则Hash值为0
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
hash = key.hashCode();
index = indexOf(key, hash);
}
//如果index是大于0的,那就说明Key在表中被找到
if (index >= 0) {
index = (index<<1) + 1;
//保存旧值并设置新值
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
//否则index就是新值的插入位置
index = ~index;
//如果表中的元素数量已经大于等于mHashes的大小
//此时就说明ArrayMap需要进行一轮扩容
if (osize >= mHashes.length) {
//若之前的大小>=8,则只扩容50%(>>1等价于除2)
//若之前的大小>=4<=8,则变成8
//若之前的大小<=4,则变成4
//想清楚为什么ArrayMap会省内存了吗?
//因为HashMap扩容是翻倍
//而ArrayMap扩容时在小容量时有两级缓存
//在大容量时也最多扩容50%
final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1))
: (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) System.out.println(TAG + " put: grow from " + mHashes.length + " to " + n);
//先把两个这数组存在临时变量中
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//扩容后mHashes和mArray就被设置成新数组了
allocArrays(n);
//依然是不允许并发,这里有并发检查
//如果在扩容时给ArrayMap添加元素,那就会报错
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (mHashes.length > 0) {
if (DEBUG) System.out.println(TAG + " put: copy 0-" + osize + " to 0");
//将旧数组内的值拷贝到新数组
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
//释放旧数组,如果他们符合条件,就会被回收
freeArrays(ohashes, oarray, osize);
}
//如果这次put进来的Key没有排在数组的最后
if (index < osize) {
if (DEBUG) System.out.println(TAG + " put: move " + index + "-" + (osize-index)
+ " to " + (index+1));
//那么就要移动数组的元素,给当前要插入的值腾出位置
//这个过程实际上就是对数组进行排序
//System.arraycopy这个方法在Android上是一个native方法
//所以它的效率会更高
System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS) {
if (osize != mSize || index >= mHashes.length) {
throw new ConcurrentModificationException();
}
}
//最后才是给数组对应的位置赋值
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
复制代码
3.4.2 删除元素
下面我们开始分析 remove
@Nullable
public V remove(Object key) {
final int index = indexOfKey(key);
//大于0,说明才有Key
if (index >= 0) {
return removeAt(index);
}
return null;
}
//跟踪到indexOfKey,可以发现都是上面我们已经分析过的方法
public int indexOfKey(@Nullable Object key) {
return key == null ? indexOfNull() : indexOf(key, key.hashCode());
}
//那么继续跟踪到removeAt
public V removeAt(int index) {
//先拿出旧值
final Object old = mArray[(index << 1) + 1];
final int osize = mSize;
final int nsize;
//如果当前就只存了一个元素
if (osize <= 1) {
// Now empty.
if (DEBUG) System.out.println(TAG + " remove: shrink from " + mHashes.length + " to 0");
//那么就检查一下能否回收这两个数组
freeArrays(mHashes, mArray, osize);
//并将原数组置空
mHashes = ContainerHelpers.EMPTY_INTS;
mArray = ContainerHelpers.EMPTY_OBJECTS;
nsize = 0;
}
//如果存着的不只一个元素
else {
//大小减1
nsize = osize - 1;
//如果ArrayMap的容量是大于8,并且最多只使用了三分之一
//那么就要重新分配空间,减少内存使用
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
//计算出新的容量
//如果移除该元素之前ArrayMap所存的大小(Szie)大于8
//则容量(Capacity)收缩到原大小(Size)的1.5倍,否则收缩到8
final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);
if (DEBUG) System.out.println(TAG + " remove: shrink from " + mHashes.length + " to " + n);
//暂存旧数组
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//分配新数组
allocArrays(n);
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
//和之前一样,从旧数组拷贝
if (index > 0) {
if (DEBUG) System.out.println(TAG + " remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
//然后移动数组元素
//将要移除的数组下标后的元素往前移覆盖掉要移除的元素
if (index < nsize) {
if (DEBUG) System.out.println(TAG + " remove: copy from " + (index+1) + "-" + nsize
+ " to " + index);
System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
}
//如果没有达成收缩条件
//则直接移动
else {
if (index < nsize) {
if (DEBUG) System.out.println(TAG + " remove: move " + (index+1) + "-" + nsize
+ " to " + index);
System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
mArray[nsize << 1] = null;
mArray[(nsize << 1) + 1] = null;
}
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
//更新大小
mSize = nsize;
//返回旧值
return (V)old;
}
复制代码
最后我们再来看一下用于回收数组的 freeArrays
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
//如果长度是8,则进入同步代码块
if (hashes.length == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {
//最多只会缓存10个数组
//CACHE_SIZE=10
if (mTwiceBaseCacheSize < CACHE_SIZE) {
//为把array作为新的头结点做准备
array[0] = mTwiceBaseCache;
array[1] = hashes;
//除了前两个item其他置空
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
//更新头结点
mTwiceBaseCache = array;
//链表长度加1
mTwiceBaseCacheSize++;
if (DEBUG) System.out.println(TAG + " Storing 2x cache " + array
+ " now have " + mTwiceBaseCacheSize + " entries");
}
}
}
//大小为4时同理,不在赘述
else if (hashes.length == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
array[0] = mBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
if (DEBUG) System.out.println(TAG + " Storing 1x cache " + array
+ " now have " + mBaseCacheSize + " entries");
}
}
}
}
复制代码
3.4.3 查找元素
现在我们来看看 get 的源码
public V get(Object key) {
//我们看到实际上是调用getOrDefault
return getOrDefault(key, null);
}
//跳到getOrDefault,可以发现它非常简单
//indexOfKey之前我们已经分析过,这里只是对负值做判断
//若index为负值则返回null
public V getOrDefault(Object key, V defaultValue) {
final int index = indexOfKey(key);
return index >= 0 ? (V) mArray[(index << 1) + 1] : defaultValue;
}
复制代码
4 结语
在这里特别感谢掘金的运营负责人@优弧大大,这篇文章在写到7000字的时候,因为我的失误,险些造成腰斩,谢谢大大帮我找回.
自己在写这篇文章的时候也遇到很多困难,比如在看 HashMap 中的 红黑树 的时候,由于网上文章质量 良莠不齐 ,很多文章都存在对红黑树的理解 不够透彻 的问题,而且自己算法基础也比较差,看得几近奔溃,但是我不喜欢妥协,通过看书和参考对比大量文章坚持下来了,虽然到最后 红黑树删除 那块还是鸽了,因为我觉得自己都弄不清楚的东西怎么能跟别人讲清楚呢?所以干脆别讲,免得害人害己,等日后我水平达到了再补上了,通过这一趟下来感觉自己也提升了不少.
同时,在此也提醒一下各位读者,对于 复杂 的 数据结构 和 算法 理解必须捧着 权威书本 来做参考,不可以轻易相信网上的博客,因为 红黑树 作为一种 复杂 的 高级数据结构 ,是没有多少人能将它完全讲清楚的,或多或少都会存在一些 谬误 ,这对你的理解是极其有害的.所以对于本篇的态度也是一样,本篇文章仅供您的参考,如有谬误还请指出.
最后,这篇文章真的很来之不易,综上种种才让大家能在今天看到这篇文章.
如果喜欢我的文章别忘了给我点个 赞 ,拜托了这对我来说真的 很重要 (我想当 联合编辑 啊QAQ).
正文到此结束
- 本文标签: tk 源码 线程 开源项目 注释 实例 开源 ACE HashMap 递归 测试 Oracle IDE 响应式 遍历 百度 博客 bug tag root find 数据 时间 解析 final 删除 id 并发 java UI 代码 Android 并发编程 http Collection 缓存 https map Google App 开发 运营 IO synchronized 质量 安全 多线程 CTO 参数 entity cache JVM node cat API CEO value src 文章 tab 压力 管理 空间 key 同步 1111 equals
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

