浅谈动态追踪技术
本文主要介绍了动态追踪技术,并举例说明动态追踪技术的应用。

身为一个SRE,工作中经常会遇到各种奇奇怪怪的服务异常问题。这些问题在staging(测试环境)没有发现,但放到真实的生产环境就会碰到,最关键的是难以复现,某些问题可能是几个月才会复现。
初次碰到可能会手忙脚乱,暴力的解决手段是将机器拉下线,然后开始专家会诊,但是脱离了线上真实环境,没有线上真实流量,某些问题可能不好复现了,这种方式还不是特别适合。
如何找到病因
大部分情况,其实我们已经可以通过top,pidstat等命令定位到具体是哪一个服务出的问题。当然重启服务可以解决60%以上的服务异常问题,但是重启后会丢失现场。
重启一时爽,一直重启就不爽了。还是需要定位到具体的问题。我还是希望知道底病根在哪,最好直接告诉我哪个具体函数,哪条语句导致的问题或者bug。最差也得知道是大致什么节点的什么类型故障
很多人可能会想到GDB。虽然这些工具很伟大,但是这应该不适合我们sre在已经服务已经发病的情况下使用,因为线上的服务不能被中止。GDB在调试过程中设置断点会发出SIGSTOP信号,这会让被调试进程进入T (TASK_STOPPED or TASK_TRACED)暂停状态或跟踪状态。同时 GDB 所基于的 ptrace 这种很古老的系统调用,其中的坑和问题也非常多。
比如 ptrace 需要改变目标调试进程的父亲,还不允许多个调试者同时分析同一个进程,而且不太熟悉GDB的人可能会把程序调试挂了,这种交互式的追踪过程通常不考虑生产安全性,也不在乎性能损耗。另外提一下,strace也是基于ptrace的,所以strace也是对性能不友好的。
那么就要提到动态追踪技术了,动态追踪技术通常通过探针这样的机制发起查询。动态追踪一般来说是不需要应用目标来配合的,随时随地,按需采集,而且它非常大的优势为性能消耗极小(通常5%或者更低的水平)。
动态追踪
动态追踪的工具很多,systemtap,perf,ftrace,sysdig,dtrace,eBPF等,由于我们的线上服务器是Linux系统,且内核版本没有那么激进的使用最新的版本,所以我还是比较倾向于使用perf或者systemtap。就我个人而言,perf无疑是我的最爱了。
动态追踪的事件源根据事件类型不同,主要分为三类。静态探针, 动态探针以及硬件事件。
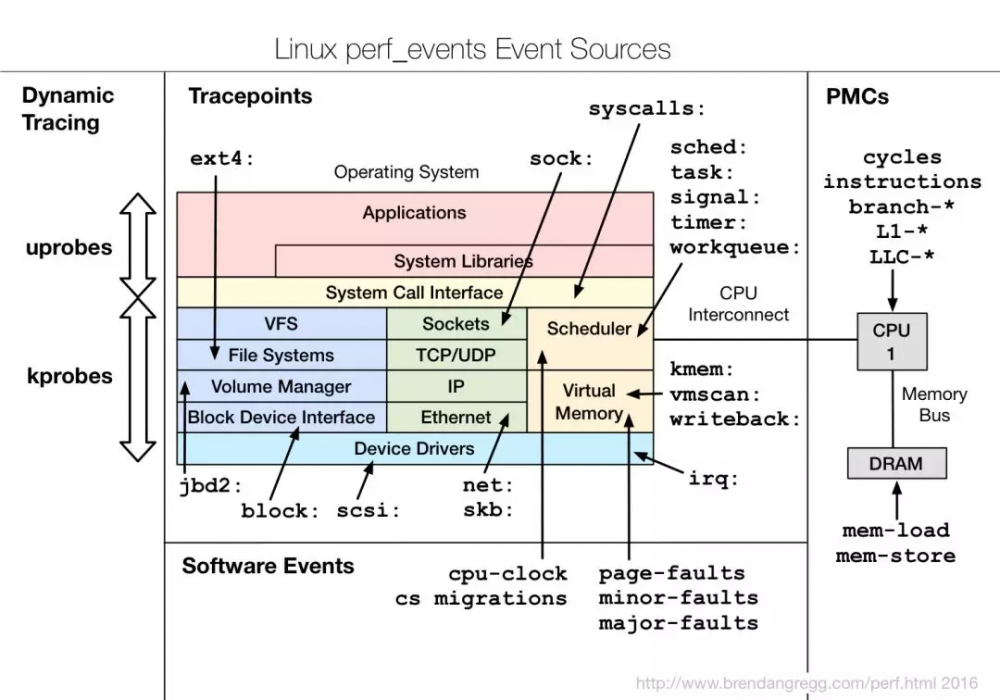
静态探针: 事先在代码中定义好的一类,已经编译进应用程序或内核中的探针。常见的有 tracepoints(这是散落在内核源代码中的一些hook,使能后一旦特定的代码被运行到时就会被触发)还有USDT探针。
动态探针: 事先没有在代码中定义,但是可以在运行时动态加载,比如函数返回值等。常见的有uprobes(跟踪用户态函数)和kprobes(跟踪内核态函数)。
硬件事件: 一般由PMC产生,比如intel的CPU,一般会内置统计性能的寄存器(Hardware Prefirmance Counter)。
想要查看可触发的采样事件可以通过 perf list 去展示
复制代码
$ perf listList of pre-defined events (to be used in -e):branch-instructions OR cpu/branch-instructions/ [Kernel PMU event]branch-misses OR cpu/branch-misses/ [Kernel PMU event]... ...复制代码
可以看下perf是支持很多事件的(注:由于线上服务器内核版本不是最新的,所以这里看到的有些少)
复制代码
$ perf list | wc -l1196复制代码
其主要分这几大类(不同的版本可能看到的不一样),HardWare Event,SoftWare Event,Kernel Tracepoint Event,User Statically-Defined Tracing (USDT),Dynamic Tracing。
HardWare Event
就是上面提到的PMC,通过这些内容可以获取到cpu周期,2级缓存命中等事件,其实这些有些太过底层,在实际业务中并用不到这些的。
SoftWare Event
软件事件是区别硬件事件的,比如缺页,上下文切换等。
Kernel Tracepoint Event
内核追踪点事件一般就是我们能想到的一些内核事件。Linux内核中定义了大量的跟踪点,在代码层面就被编译进内核,如TCP,文件系统,磁盘I/O,系统调用,随机数产生等等了。
User Statically-Defined Tracing (USDT)
与内核追踪点事件类似,只不过是用户级的,需要在源代码中插入DTRACE_PROBE()代码,其实不少软件都已经实现了,如Oracle。且一般在编译的时候使用 ./configure --with-dtrace。如下所示是加上探测器的一段代码,在<sys/sdt.h>中加入的了DTRACE_PROBE() 宏的引用
复制代码
#include <sys/sdt.h>...voidmain_look(void){ ... query = wait_for_new_query(); DTRACE_PROBE2(myserv, query__receive, query->clientname, query->msg); process_query(query) ...}复制代码
Dynamic Tracing
动态追踪。当内核编译时开启CONFIG_KPROBES和CONFIG_UPROBES就可以使用动态的跟踪。有了这些,我们就可以通过添加探针,来追踪一个应用程序的内核调用,如打开文件,发送tcp报文。
复制代码
$ perf probe --add 'do_sys_open filename:string'$ perf record -e probe:do_sys_open -aR -p ${Service PID}$ perf script -i perf.data复制代码
当然了,perf有很多的用法,下面大致介绍一下。
有了perf,我还可以对应用程序发生的系统调用做一次详细的剖析。有了这些可以深层次的分析一个代码的调用关系。就像下面一样,压缩文件发生的是大量的read和write
复制代码
复制代码
# perf stat -e 'syscalls:sys_enter_*' gzip file 2>&1 | awk '$1 != 0' Performance counter stats for 'gzip file': 1 syscalls:sys_enter_utimensat 1 syscalls:sys_enter_unlink 3 syscalls:sys_enter_newfstat 1 syscalls:sys_enter_lseek 2,180 syscalls:sys_enter_read 4,337 syscalls:sys_enter_write 3 syscalls:sys_enter_access 1 syscalls:sys_enter_fchmod 1 syscalls:sys_enter_fchown ... 2.309268546 seconds time elapsed复制代码
亦或者通过perf trace 去跟踪某个进程的系统调用。比starce好用多了。事实上前面也提到过strace是对性能很不友好的。这里可以看下,gzip同样的文件,相同的操作,被strace后,执行总是慢一些。我试了很多次,perf的追踪总是在2.3s左右,而strace就是2.9s左右。
复制代码
# time strace -c gzip file% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- ---------------- 67.69 0.125751 29 4337 write 27.36 0.050826 23 2180 read 4.12 0.007661 7661 1 unlink 0.20 0.000377 94 4 openat 0.12 0.000231 77 3 3 access 0.08 0.000157 22 7 close ...------ ----------- ----------- --------- --------- ----------------100.00 0.185767 6568 4 totalreal 0m2.919suser 0m0.669ssys 0m2.263s复制代码
perf最强大的还是 perf record,它支持先记录,后查看,记录完成后通过perf report查看。比如我想记录某个应用程序的IO情况。以SimpleHTTPServer为例,可以看到当从SimpleHTTPServer下载文件时的读磁盘的调用。
复制代码
复制代码
$ perf record -e block:block_rq_issue -ag -p ${Service PID}$ perf report -i perf.dataSamples: 105 of event 'block:block_rq_issue', Event count (approx.): 105 Children Self Trace output- 0.95% 0.95% 8,0 R 0 () 24895224 + 1024 [python] 0 __GI___libc_read tracesys sys_read vfs_read do_sync_read xfs_file_aio_read xfs_file_buffered_aio_read generic_file_aio_read page_cache_async_readahead ondemand_readahead __do_page_cache_readahead ... ...复制代码
或者是对一个应用服务程序进行全方位的追踪
复制代码
perf record -F 99 -ag -p ${Service PID} -- sleep 10复制代码
然后通过perf report -i perf.data 来进行分析
复制代码
Samples: 21 of event 'cpu-clock', Event count (approx.): 5250000 Children Self Command Shared Object Symbol- 76.19% 0.00% python [kernel.vmlinux] [k] system_call - system_call - 28.57% sys_recvfrom SYSC_recvfrom - sock_recvmsg + 23.81% inet_recvmsg - 4.76% security_socket_recvmsg selinux_socket_recvmsg sock_has_perm avc_has_perm_flags + 23.81% sys_sendto + 19.05% sys_shutdown + 4.76% sys_newstat复制代码
这里的分析结果显示分为四列其中 Overhead 是我们需要关注的,因为这个比例占用的多的话,证明该程序的大部分时间都在处理这个事件。其次是Symbol,也就是函数名,未知的话会用16进制表示的。
perf stat 也是一个不错的程序性能分析工具 ,在上面的例子中,我通过perf stat记录了某个程序的系统调用。它可以提供一个整体情况和汇总数据。
下面这个是一个疯狂的C代码。可以看出,这是一个疯狂的循环。
复制代码
复制代码
复制代码
复制代码
复制代码
复制代码
复制代码
void longa(){ int i,j; for(i = 0; i < 10000000000000000; i++) j=i;}void foo1(){ int i; for(i = 0; i< 1000; i++) longa();}int main(void){ foo1();}复制代码
编译后使用一下 perf stat
复制代码
$ perf stat ./a.out Performance counter stats for './a.out': 30249.723058 task-clock (msec) # 1.000 CPUs utilized 150 context-switches # 0.005 K/sec 2 cpu-migrations # 0.000 K/sec 113 page-faults # 0.004 K/sec <not supported> cycles <not supported> instructions <not supported> branches <not supported> branch-misses 30.260523538 seconds time elapsed复制代码
可以看出,这是一个cpu密集型程序,会大量耗费cpu的计算资源。
更多的例子可以到 大神brendan gregg的博客上看到,不仅仅是磁盘情况,还有更多奇妙的例子。
博客地址:http://www.brendangregg.com/perf.html
虽然可以通过 $ perf record -ag -p ${Service PID} 来记录追踪一个进程的所有事件,但是需要注意的是,动态追踪需要调试符号,这些调试符号诸如函数和变量的地址,数据结构和内存布局,映射回源代码的抽象实体的名称等等,如果没有的话,将看到一堆16进制地址。这是很痛苦的。
而我们这里大部分应用都是java服务,java服务是跑在jvm里的。如果直接使用record看到的全是vm引擎符号,这些只能让我们看到诸如gc一类的信息,看不到具体某个java的类和方法,不过可以通过 开源的 perf-map-agent,它通过虚拟机维护的 /tmp/perf-PID.map来进行符号的转换。但是由于x86上的hotspot省略了frame pointer,所以就算转换了符号,可能还是不能显示完整的堆栈。不过在JDK 8u60+可以通过添加-XX:+PreserveFramePointer。同样java的动态追踪可以参考大神brendan gregg的博客。
博客地址:
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html#Java
当所需要的工具安装好且都配置完成后,可以使用如下命令对java服务进行动态追踪其调用过程。
复制代码
复制代码
复制代码
git clone --depth=1 https://github.com/brendangregg/FlameGraphperf record -F 99 -a -g -- sleep 30; ./FlameGraph/jmapsperf script > out.stacks01cat out.stacks01 | ./FlameGraph/stackcollapse-perf.pl | grep -v cpu_idle | / ./FlameGraph/flamegraph.pl --color=java --hash > out.stacks01.svg复制代码
同样,systemtap也十分厉害的动态追踪框架,它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核行为。
systemtap就不在这里多做介绍了,有兴趣的朋友可以去systemtap官网看看,这里有许多现成的脚本,如网络监控(监控tcp的连接,监控内核丢包的源头等),磁盘监控(io监控,每个应用的读写时间等)等等。
相较于perf,systemtap的一个巨大的优势是systemtap是可编程的,想追踪什么写个脚本就ok了,目前perf也在支持可编程计划,eBPF的补丁计划加上后,perf会变得更加强大。
systemtap官网教程:
https://sourceware.org/systemtap/SystemTap_Beginners_Guide/useful-systemtap-scripts.html
一次故障的动态追踪过程
就在前不久,一阵急促的短信报警涌来,是线上服务器的load告警了,我开始扫码登陆服务器,熟练的使用 top -c 观察着线上服务器的指标。
大致现象我没有截图,口述一下吧,有2个服务的cpu使用率达到300%,wa有些高,我怀疑到是程序bug了疯狂读磁盘。于是使用iotop,查看io情况,可以看到总体的写磁盘速度是 135M/s 。而读请求几乎是0 ,这是怎么回事,这几个服务在疯狂写数据?不应该吧,这几个服务似乎没有这么大的写磁盘需求啊,如果有,应该就是日志了。在看日志前,先 perf record -ag -p ${Service Pid} 记录服务的状态。查看了应用服务的日志,消息队列似乎处理出错了,日志量巨大且繁杂,各种日志都有。到底哪里有问题呢?虽然已经定位到故障可能和消息队列有关,但是还不能确定是哪里的问题。
中断 perf record 后,我利用上面提到的方法,导出火焰图。
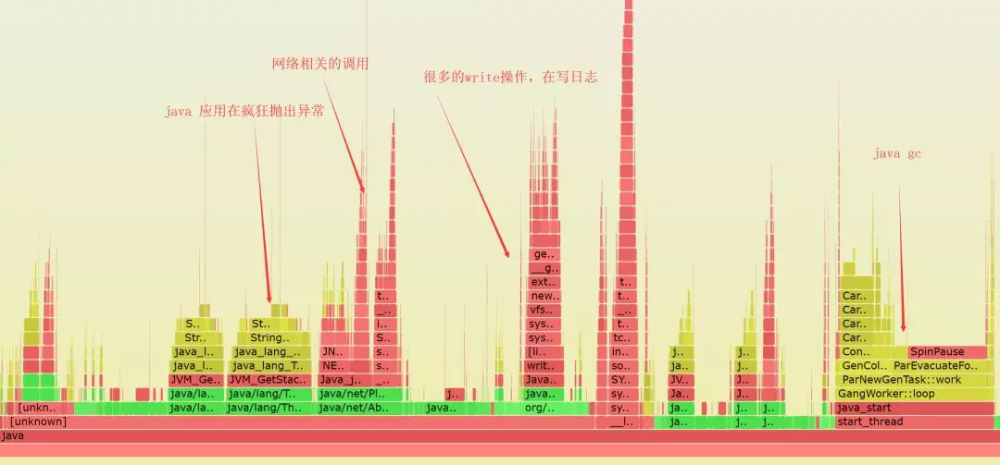
可以看到应用程序主要在做抛异常、网络相关调用、gc、写磁盘的操作。除了已知的操作外,问题服务的其余大量操作都集中在网络的数据包收发上,再结合之前看到消息队列的相关报错,应该定位是网络连接消息队列出的问题,应该消息队列连不上了,而代码有重试机制。
根据猜测,再到日志中找线索,果然是这个问题。如果是在大海般的日志中捞出有用的日志信息可能还需要些时间吧,这里需要提一下,传统的埋点多了不好,少了也不好,总归是比较难以权衡的。(因为该java服务没有开启PreserveFramePointer,所以看不到java代码级的调用)于是很快的完成了故障的定位,接下来就好办了,哪里有问题治哪里。
PS:perf 和 systemtap 的使用我这里只是很粗浅的介绍了一下,大神brendan gregg有详细博客去介绍动态追踪的每一个细节。开源社区也有很多动态追踪的扩展,如春哥在OpenResty的性能追踪上有很多十分赞的工具,同时我表示十分赞叹OpenResty的强大。我在动态追踪的路上还是一个初级学习者,远远比不上春哥等大神级别的人物,如果有什么错误也请指正。
参考文献:
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html#Java
http://openresty.org/posts/dynamic-tracing/#rd?utm_source=tuicool&utm_medium=referral
http://www.brendangregg.com/perf.html
https://zhuanlan.zhihu.com/p/34511018
https://www.ibm.com/developerworks/cn/linux/l-cn-perf1/
文章首发于小米运维公众号,原文请戳:《浅谈动态追踪技术》
正文到此结束
- 本文标签: 博客 Service JVM 服务器 git 安全 NSA 消息队列 Developer http 人物 bug 探针 awk cat IDE HTML OpenResty ECS Security id tag PHP struct 进程 数据 App 开源 ask 下载 希望 重试机制 zip ip Oracle 调试 TCP 快的 统计 文章 文件系统 测试环境 java db grep UI 时间 小米 src python IO Agent linux IBM tar 配置 需求 REST lib ACE cache 缓存 测试 安装 代码 软件 strace ORM AIO 编译 https map GitHub list client
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

