从一个真实的分布式 ID 案例看如何做架构

1.1 前言
在软件开发过程中,经常会遇到 "架构设计","方案评估","技术选型"等工作,这些内容处理起来相对比较棘手,一般会交由架构师及技术总监进行决策与把控,笔者从事的是架构师岗位,在处理此类问题的过程中积累了一些小经验,有些心得体会,现将平时工作中实际遇到的架构问题及解决方案进行梳理和总结,一方面便于自我提升,不断学习,另一方面,也可对从事架构工作的同事(不一定是架构师)提供一些借鉴和参考。
关于“什么是架构设计”,“什么是架构师”,“怎么做好架构设计”,“架构思维”、“架构方法论”等话题,网上材料一抓一大把,但多数可能显得形而上,夸夸其谈者居多,对于多数读者来说,看着热闹,但收获甚微,真正弄懂什么是架构,还是需要在实践中磨练,正如陆游所说“纸上谈来终觉浅,绝知此事要躬行”。
本文将通过一个真实的案例,来看下该怎么开展架构设计工作。
1.2 背景介绍
互联网项目,特别是电商系统,经常面临的一个场景是:如何保证在分布式、高并发环境下数据的一致性?
笔者最近支持的项目就遇到了这个问题,业务场景很简单:大家去超市或商场购物时,经常会发现有些商品的价格是有折扣的,折扣的原因可能是节假日促销或临期打折处理,通过折扣可以激发消费者购买欲,增加销售额,同时减少因商品过期导致下架丢弃带来的损失,这是一个生活中常见的场景,也很容易理解。
为了支持这一业务,我们应该怎样一步步分析、设计并实现呢?本文将尝试从架构师视角,详细介绍下相关工作及处理流程,详见下文。
1.3 处理流程
说到架构,业界有个经典的cube(立方图),如下图所示:
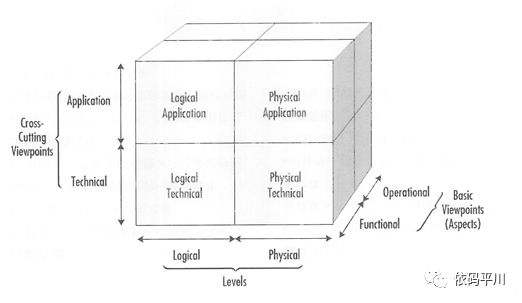
架构的维度一般包含:业务架构,应用架构,技术架构,逻辑架构,物理架构,数据架构,运维架构,集成架构,系统架构等内容, ”软件架构设计的目的是为了解决软件复杂度带来的问题“,在分析具体问题时,不必每个架构维度面面俱到,可以针对业务的复杂度,根据实际情况进行选择。
对于今天聊到这一业务场景,我将其归纳为模块的架构设计,针对这块内容,我感觉只要梳理清楚业务架构和技术架构就可以了。
接下来,我们就先看下业务架构。
注:这里需要区分几个概念:系统与子系统,模块与组件,框架与架构,设计与架构等,因涉及内容较多,就不在本文展开,有兴趣的同学请自行查阅下相关资料。
1.3.1 业务架构
从产品需求中了解到:商品搞促销活动时,需要对将待促销的商品放入促销商品池,并且要对促销的商品重新生成折扣码并打印作为价签,一个折扣码唯一对应一个商品,消费者从价签看到折后价格,将商品放入自己的购物车,再到收银台结算,需要保证价签上的价格与结算价格一致。
这就要思考一个问题:在分布式,大数据高并发的场景下,如何保证生成的折扣码唯一性?如果处理不好,则会出现同一折扣码对应出不同商品,导致消费者购买商品时看到一个价,实际结算是另一个价,非常影响用户体验,容易引发纠纷。
从需求描述可抽象出如下业务架构图:

识别复杂度
上文提到, ”软件架构设计的目的是为了解决软件复杂度带来的问题“,那么接下来我们就来尝试识别出这块业务的复杂度在哪。
从上图中可以发现,促销活动业务包含折扣码的生成、打印、扫码支付,经分析,其中,打印、扫码支付都是现有的成熟业务,无需修改,而促销码的生成需要新开发,规则较多,处理较为复杂,可以将其列为系统的复杂度来源。
业务复杂度分析
识别出业务复杂度之后,接下来分析下,业务的复杂点在哪,对于分布式下的全局ID需要具备如下特点:
-
全局唯一,区别于单机唯一,需要保证集群中的每台机器生成的ID都是不一样的,不能存在重复
-
顺序性,生成的全局ID,需要能够有序递增
-
区间约束:生成的全局ID需要满足业务规则,如:每家店每天生成的ID区间在1-999
-
性能要求:需要考虑门店数量较大情况下(如超过1万家)并发访问带来的性能问题
以上,完成业务架构梳理后,接下来需要看下如何实现,这就涉及到了技术架构。
1.3.2 技术架构
透过业务架构的复杂度来源分析,抽象出其背后的技术模型,不难发现,这其实就是一个分布式环境下全局ID生成的问题,识别出这一点之后,接下来的工作就是技术选型。
技术选型
有哪些技术可以用来来生成全局ID,我们应该如何抉择?在make decidion之前,需要准备下可选方案,我们能够想到的常规解决方案如下:
-
使用数据库:自增主键
-
使用Redis实现:incr命令
-
使用zookeeper实现:有序节点
-
使用mongoDB实现:ObjectId
-
使用业界流行的开源框架实现
-
Twitter开源的Snowflake方案
-
微信的seqsvr
-
百度的UidGenerator
-
美团的Leaf
方案确认
针对可选方案,结合公司的环境,团队的技术栈,研发人员能力等因素,逐一进行分析对比,梳理出方案的对比分析,如下图所示:
| 备选方案 | 优势 | 劣势 |
|---|---|---|
| 使用数据库的自增主键 | 简单方便 | 1. 不支持按指定维度递增(按门店,按天) 2. 分库分表会有麻烦 3.性能一般,难扩展 |
| 使用Redis实现 | 1. 灵活方便,性能高于数据库 2.适合按照门店-天分组 3.公司标准环境 | 实现方式需要自行开发,需要考虑并发及异常场景,有一定的复杂度 |
| 使用zookeeper实现 | 简单方便 | zookeeper在公司内为非标操作,需要自运维且性能在高并发场景下不太理想 |
| mongodb | 轻量级,支持分布式 | mongodb在公司内部为非标操作,需要自运维 |
| 使用业界流行的开源框架实现 | 大厂背书,不依赖数据库,灵活方便且性能优于数据库 | 有一定学习成本,且不一定能完全支持当前业务场景,如snowflake方案在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。 |
综上,根据公司内部规范及团队技术栈现状,最终选定使用redis+db的方式来实现。
技术架构图
针对确认好的方案,抽象技术架构图,如下图所示:
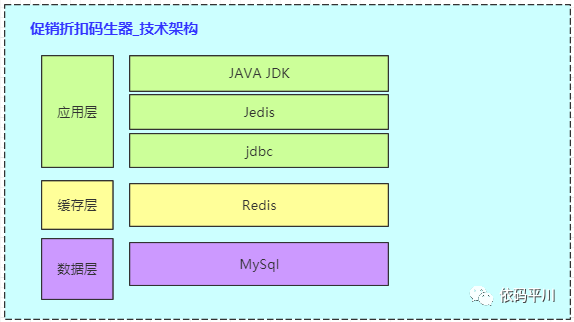
注: 这个图比较简单,能说明问题即可。 技术架构图描述层次结构及其对应的技术栈信息,需具体项目具体分析。
1.3.3 架构落地
架构落地,主要根据架构设计确定的解决方案进行代码实现,此环节主要涉及详设编码实现、代码走读、自测、联调、转测、发布等环节。
流程设计
技术处理流程图设计如下:
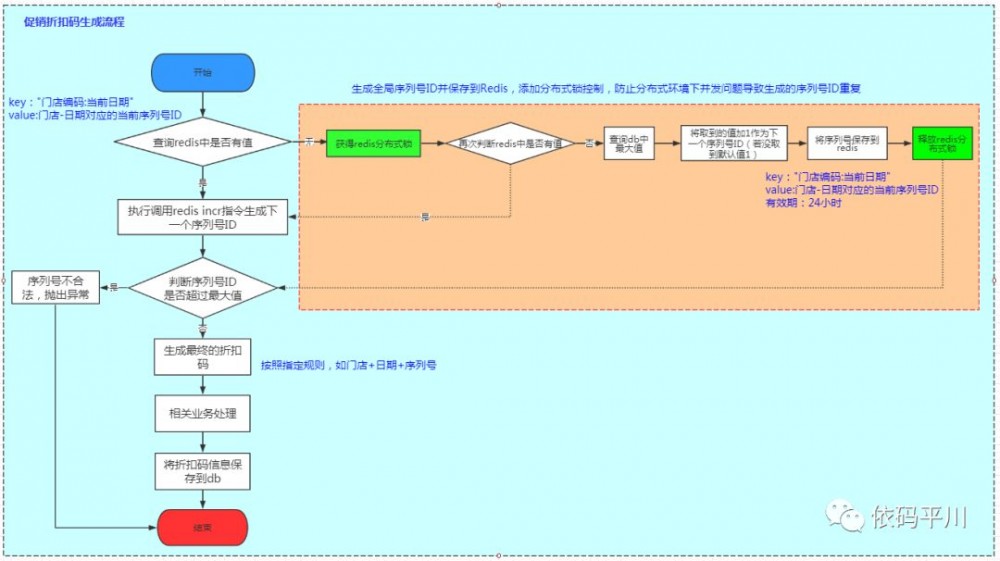
核心设计要点:
-
利用数据库的分组特性取出当前db中的最大序列号,并将其初始化redis中
-
后续处理利用redis的incr指令完成序列号ID的递增处理,由redis保证原子性与高性能
-
考虑分布式高并发场景下数据一致性问题,在做数据初始化过程中需要引入分布式锁,以控制集群下序列号ID的全局唯一性
代码实现
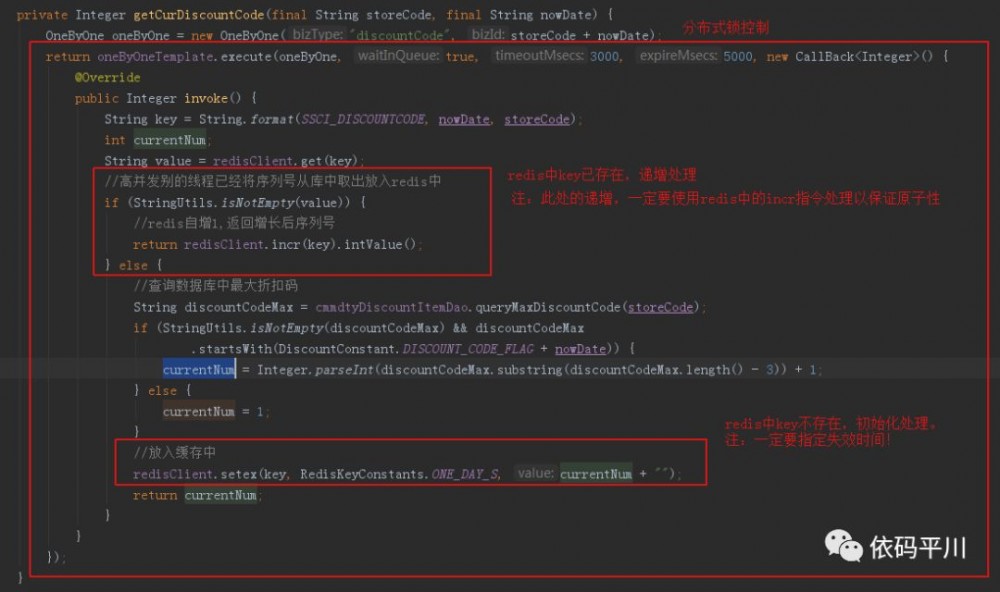
关键设计流程说明:
-
加入分布式锁,会对高并发下的性能产生影响,应该将锁的粒度控制的尽量小
-
本例中,一致性问题可能出现在从数据库去中取值做初始化的步骤,将分布式锁控制到这层即可
-
在分布式锁锁定的代码块中,一定要先判断redis中是否已经有值,否则在并发情况下可能会重复初始化,导致数据不一致问题。
-
其他情况下的高并发一致性保证由Redis天然支持
代码评审过程中发现的问题
-
由于开发人员缺乏对分布式的认知,初始代码使用在方法上添加synchronized关键字处理
-
问题:synchronized为jvm层面的锁,在分布式集群环境下无效,需要改为分布式锁
-
分布式锁控制在整个折扣码生成、业务处理、入库流程
-
问题:高并发场景下将严重影响性能,且无法通过扩容方式解决,需要将分布式锁的粒度减小,避免不必要的同步降低性能,在此案例中,只有从数据库中读取数据做redis初始化的处理会出现一致性问题,在这块加锁即可。
-
自增处理代码实现时使用内存操作,先查询redis中的值,然后在内存中加1后写回redis
-
问题:非原子性操作导致缓存一致性问题,修改为所有redis自增操作都有incr命令完成
-
在判断redis缓存中已有值的情况下,直接在内存中加1后返回

-
内从中加1后返回,导致redis中的并没有更新,下次判断时将取到旧值,导致一致性问题,从而引发大bug
注:这个问题非常隐蔽,测试环境无那么大的并发量,很难发现,在发版前,我走读其代码时发现此问题,并立即安排对应研发人员整改,还好处理及时,规避了一个可能产生的严重生产问题。
至此,从业务背景到需求分析到业务架构、技术选型、方案确定、技术架构、编码实现等环节已处理完毕,接下来就是投产使用,接受市场的考验了。
1.4 结语
本文通过分布式高并发场景下的全局序列ID生成的案例,演示了在真实的项目开发过程中如何做架构设计并将其跟踪落地的整个过程,希望对你有所帮助。
另外,补充说明下, 实际项目开发中一般工期都比较赶,完成技术选型、方案确定、技术架构设计的时间可能非常短,有时只是通过一次简短的会议,一次沟通就已完成,形式不拘泥于文档,有时一块白板、一只水笔、一个草图,足矣。关键是思路,重在日常积累。
最后,分享点在此过程中的个人体会:一个看似简单的方案,其实涉及的细节考量非常多,本以为架构设计、流程处理已足够详细,开发人员也已明确理解方案,实现起来应该问题不大,然而落实到代码时,还是会发现诸多严重bug,这就说明我们在工作过程中,一定要要重视以下几个问题:
-
做架构不能与开发脱节,架构设计不是空中楼阁,一定要能指导开发,能落地,接地气
-
一定要对代码实现进行复查及走读,及时发现实现与设计有出入的地方,并及时修正
-
需要对分布式大数据高并发场景下的一致性及性能问题重点考虑
-
异常场景不容忽视,需要做好容错及必要的降级处理,保证高可用
对于本文提到的分布式锁,也是分布式架构中经常遇到的问题,业界也有较多的解决方案,待后续有时间再单独进行总结梳理。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

