基于Kubernetes的微服务可观测性和Istio服务网格(二)
在本系列文章中,我们将继续探索可观测性工具集,这些工具集作为最新的Istio服务网格中的一部分,包含了 Prometheus 和 Grafana 用于度量指标收集,监控和警报, Jaeger 用于分布式跟踪,以及 Kiali 为Istio提供基于服务网格的微服务可视化。同时结合云平台原生的监控和日志记录服务,例如谷歌云平台上Google Kubernetes Engine (GKE)]( https://cloud.google.com/kubernetes-engine /)的 Stackdriver ,我们为现代分布式应用程序提供了完整的可观测性解决方案。。
参考平台
为了演示Istio的可观测性工具,在系列的第一部分中,我们部署一个参考平台,包含了8个基于Go的微服务,以服务A-H来标识,1个Angular 7基于 TypeScript 的前端,4个MongoDB数据库实例和一个RabbitMQ队列用于基于事件队列的通信。
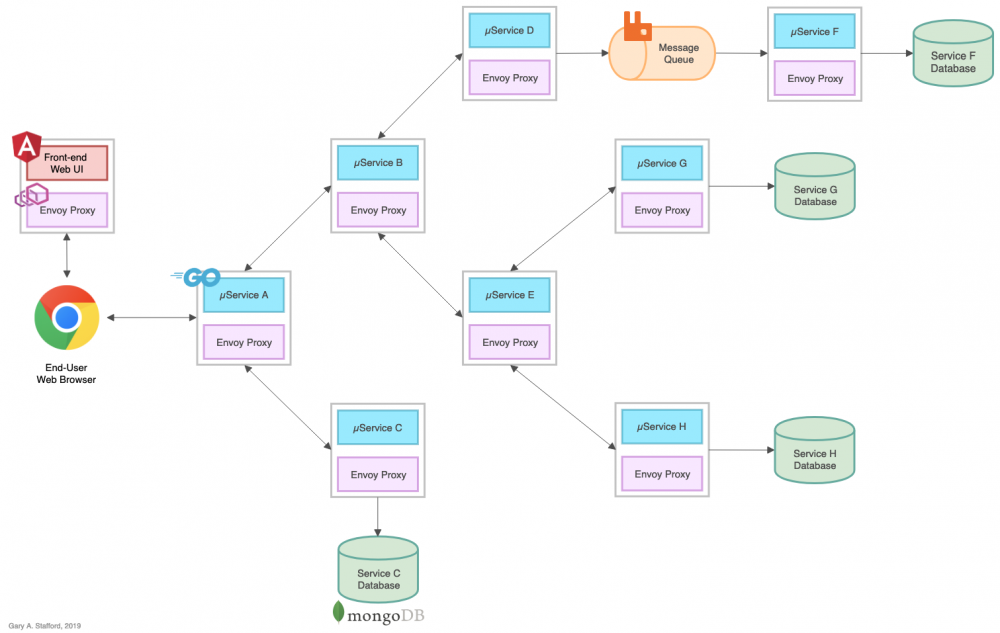
该参考平台旨在生成基于HTTP的服务到服务,基于TCP的服务到数据库以及基于TCP的服务到队列再到服务(RabbitMQ)的IPC(进程间通信)。服务A调用服务B和C,服务B调用服务D和E,服务D生产消息到RabbitMQ队列供服务F来消费并写入到MongoDB,依此类推。目标是在将系统部署到Kubernetes时使用Istio的可观测性工具来观察这些分布式通信。
日志记录
我们在第一部分说到,日志,指标和跟踪通常被称为可观测性的三大核心支柱。当我们在GCP上使用GKE时,我们能利用谷歌云的 Stackdriver Logging 产品。据谷歌宣称, Stackdriver Logging允许你存储,搜索,分析,监控和根据来自GCP甚至是AWS的数据和事件来进行告警。虽然Stackdriver logging不包含在Istio可观测性功能中,但是日志记录是整体可观测性策略的重要核心之一。
基于Go语言的微服务日志记录
有效的日志记录策略包含了记录的内容,何时记录以及如何记录。作为我们的日志记录策略的一部分,八个基于Go的微服务使用了 Logrus ,这是一个流行的结构化记录日志组件。这些微服务同时还实现了Banzai Cloud的 logrus-runtime-formatter ,关于这个日志插件有一篇优秀的文章, Golang runtime Logrus Formatter 。这两个日志记录软件包能让我们更好地控制记录的内容,何时记录和如何记录关于我们的微服务的信息。使用这个软件包需要的配置也相当少。
func init() {
formatter := runtime.Formatter{ChildFormatter: &log.JSONFormatter{}}
formatter.Line = true
log.SetFormatter(&formatter)
log.SetOutput(os.Stdout)
level, err := log.ParseLevel(getEnv("LOG_LEVEL", "info"))
if err != nil {
log.Error(err)
}
log.SetLevel(level)
}
Logrus比Go内置的简单的日志包 log 提供多了几个优点。日志不仅只记录致命性错误,同时我们也不应该在生产环境中输出所有明细的日志。本文中涉及到的微服务利用了Logrus的七种日志级别:Trace,Debug,Info,Warning,Error,Fatal和Panic。我们还将日志级别作为变量,允许在部署时在Kubernetes Deployment资源中轻松更改它。
这些微服务同时还利用了Banzai Cloud的 logrus-runtime-formatter 。这个格式化工具能自动地给日志消息标记上运行时/堆栈信息,包括函数名和代码行号,这些信息在排除故障时非常有用。我们也使用了Logrus的JSON日志格式。注意下面的日志条目是如何将JSON有效负载包含在消息中的。
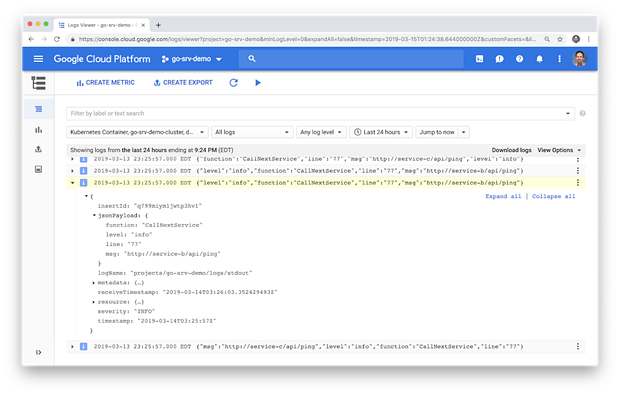
客户端层面的UI日志记录
同样地,我们使用 NGX Logger 增强了Angular UI的日志记录。NGX Logger是一个流行,简单的日志记录模块,目前用于Angular 6和7。它能将控制台输出打印得更好看,并允许将被POST到某个服务端URL的消息记录下来。在这次演示中,我们只将日志打印到控制台。与Logrus类似,NGX Logger也支持多种日志级别:Trace,Debug,Info,Warning,Error,Fatal和关闭。NGX Logger不仅可以输出消息,还允许我们将日志条目以合适的格式输出到Web浏览器的控制台。
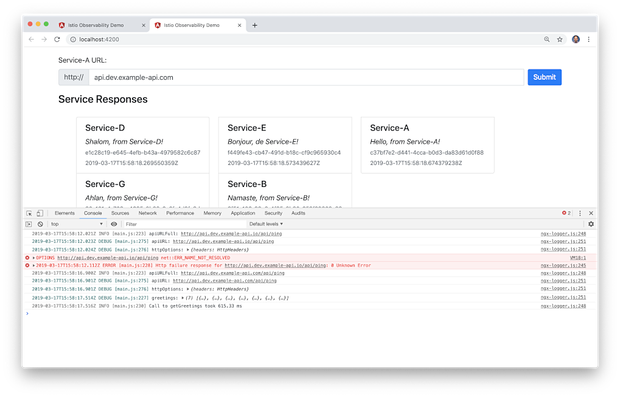
日志输出级别取决于不同的环境,生产与非生产。下图我们可以看到在本地开发环境中的日志条目,包括了Debug,Info和Error级别。
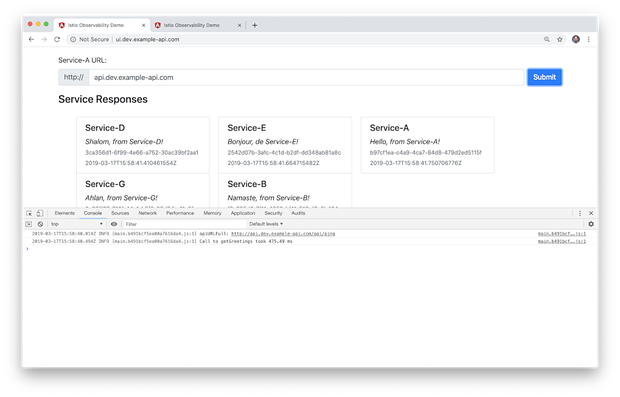
在下图基于GKE的生产环境中我们能看到相同的页面。但是请注意,我们无需修改任何配置,Debug级别的日志条目将不会输出到控制台中。我们不希望暴露包含潜在敏感信息的日志给生产环境的终端用户。
通过将以下三元运算符添加到 app.module.ts 文件中来实现控制日志记录级别。
LoggerModule.forRoot({
level: !environment.production ? NgxLoggerLevel.DEBUG : NgxLoggerLevel.INFO,
serverLogLevel: NgxLoggerLevel.INFO
})
指标
关于指标,我们来看看 Prometheus 和 Grafana 。这两个先进的工具已作为Istio部署的一部分被安装。
Prometheus
Prometheus是一个完全开源和社区型驱动的系统监控和告警工具,大约在2012年SoundCloud创建了这个项目。有趣的是,Prometheus于2016年加入 云原生计算基金会 (CNCF)作为第二个托管项目,众所周知第一个是 Kubernetes 。
根据 Istio文档 说明,Istio的Mixer中内置了一个Prometheus适配器,它可以暴露一个用于服务那些生成的度量值的端点。这里所说的Prometheus附加组件是一个预先配置了去收集Mixer端点上暴露的指标的Prometheus服务器。它提供了持久存储和查询Istio指标的机制。
GKE集群已跑起来,Istio也已安装,平台已部署,那怎么访问Prometheus?最简单的方法是使用 kubectl port-forward 来连接到Prometheus服务器。根据Google的说法,Kubernetes的 端口转发 从v1.10版本以后允许使用资源名称(例如服务名称)来选择匹配的pod。我们将本地端口转发到Prometheus pod上的端口。
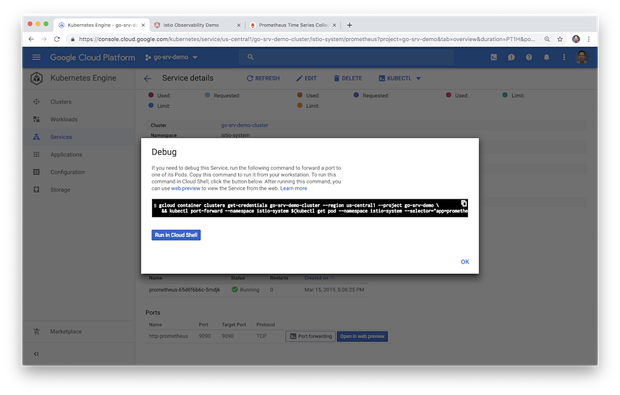
你可以使用Google Cloud Shell进行连接,也可以将命令复制粘贴到本地shell以从本地端口进行连接。以下是本文中使用的端口转发命令。
Grafana
kubectl port-forward -n istio-system /
$(kubectl get pod -n istio-system -l app=grafana /
-o jsonpath='{.items[0].metadata.name}') 3000:3000 &
Prometheus
kubectl -n istio-system port-forward /
$(kubectl -n istio-system get pod -l app=prometheus /
-o jsonpath='{.items[0].metadata.name}') 9090:9090 &
Jaeger
kubectl port-forward -n istio-system /
$(kubectl get pod -n istio-system -l app=jaeger /
-o jsonpath='{.items[0].metadata.name}') 16686:16686 &
Kiali
kubectl -n istio-system port-forward /
$(kubectl -n istio-system get pod -l app=kiali /
-o jsonpath='{.items[0].metadata.name}') 20001:20001 &
Prometheus 文档中写道,用户可使用名为 PromQL (Prometheus查询语言)的函数查询语言来实时选择和汇总时间序列数据。查询表达式的结果可在Prometheus的Web UI中显示为表格数据并绘制为图形,也可以通过Prometheus的 HTTP API 由外部系统使用。Web UI界面包含了一个下拉菜单,其中包含所有可用指标作为构建查询的基础。下面显示的是本文中使用的一些PromQL示例。
up{namespace="dev",pod_name=~"service-.*"}
container_memory_max_usage_bytes{namespace="dev",container_name=~"service-.*"}
container_memory_max_usage_bytes{namespace="dev",container_name="service-f"}
container_network_transmit_packets_total{namespace="dev",pod_name=~"service-e-.*"}
istio_requests_total{destination_service_namespace="dev",connection_security_policy="mutual_tls",destination_app="service-a"}
istio_response_bytes_count{destination_service_namespace="dev",connection_security_policy="mutual_tls",source_app="service-a"}
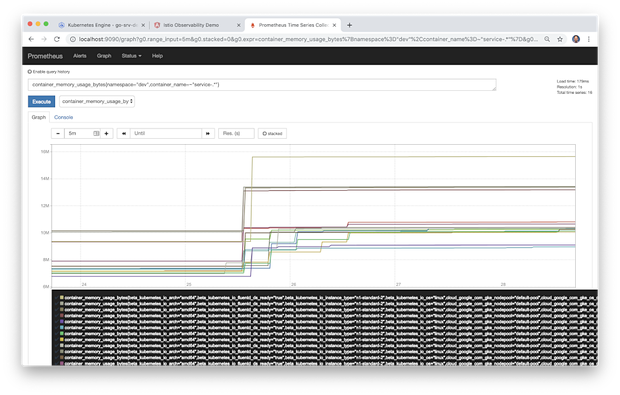
在下图显示的Prometheus控制台中,我们看到了部署到GKE的八个基于Go的微服务的示例图。该图显示了五分钟内的容器内存使用情况。在一半的时间内,服务处于休息状态。另一半时间区域,服务使用了 hey 工具来模拟负载。查看负载下服务的内存简况可以帮助我们确定容器内存最小值和限制,这会影响Kubernetes在GKE集群上的工作负载调度。诸如此类的度量标准也可能会发现内存泄漏或路由问题,例如下面的服务,它似乎比同类服务消耗的内存多25-50%。
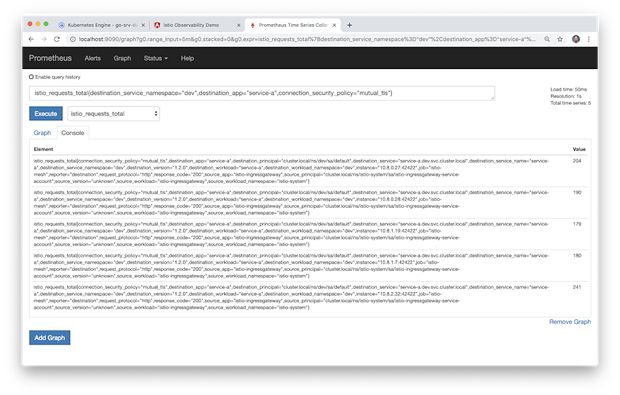
下面的另一个例子,这个图表表示系统处于负载状态下 dev 命名空间中对服务A的总的Istio请求。

比较上面的图表视图与控制台视图中显示的相同指标,多个指标显示了在检测的五分钟周期内, dev 命名空间里的服务A的多个实例。各个度量标准元素中的值指出了收集到的最新度量标准。
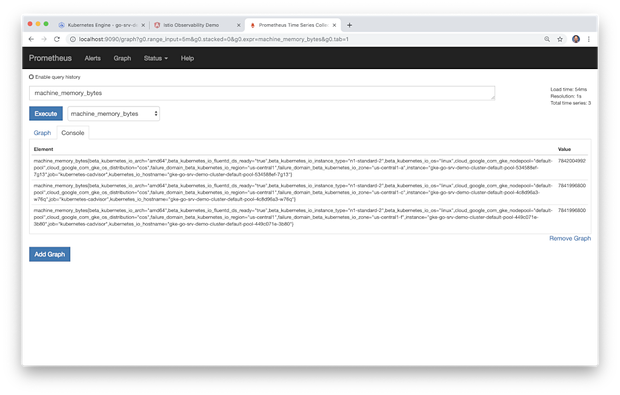
Prometheus同时还收集有关Istio组件,Kubernetes组件和GKE集群的基本指标。下面我们可以查看GKE集群中每个n1-standard-2虚机节点的总内存。
Grafana
Grafana自称是一个先进的时间序列分析开源软件。根据 Grafana Labs 的说法,( https://grafana.com/grafan a)Grafana允许你查询,可视化,提醒和了解熟悉你的指标,无论它们是存放在哪里。你可以轻松创建,浏览并共享具有丰富视觉效果的以数据驱动的仪表板。Grafana还能直观地让你为那些最重要的指标定义警报规则,它将不断评估规则并发送通知。
Istio文档 中写到,Grafana附加组件其实是一个预先配置好的Grafana实例。Grafana的容器基础镜像已被修改为支持Prometheus数据源和适配到Istio仪表板。Istio的基本安装文件,特别是Mixer,包含了一个默认的全局的(用于每个服务)度量标准的配置。预配置的Istio仪表板可与默认的Istio指标配置和Prometheus后端结合使用。
我们在下图可以看到预先配置的Istio负载仪表板。该大的仪表板的特定部分已过滤用于显示在GKE集群中 dev 命名空间中的出站服务指标。
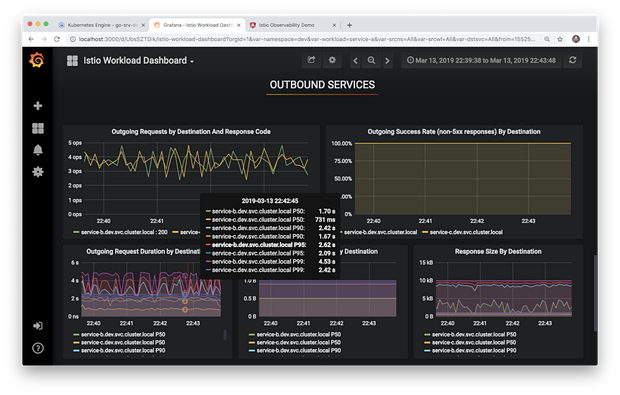
同样,在下面我们看到预先配置的Istio服务仪表板。该大的仪表板的特定部分已过滤用以显示GKE集群中Istio Ingress Gateway的客户端工作负载指标。
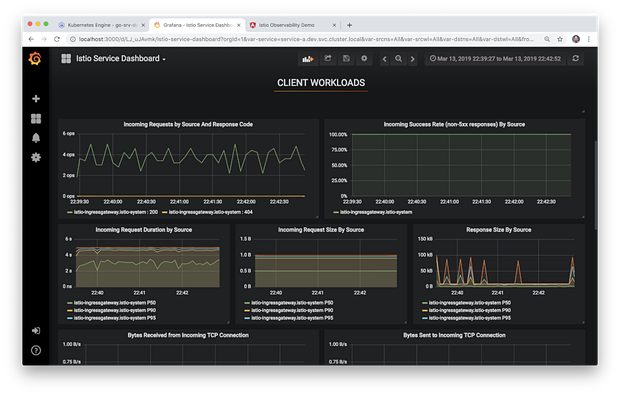
最后,我们看到预配置的Istio网格仪表板。此仪表板同样已过滤用以显示部署到GKE集群的组件的度量标准的表格视图。
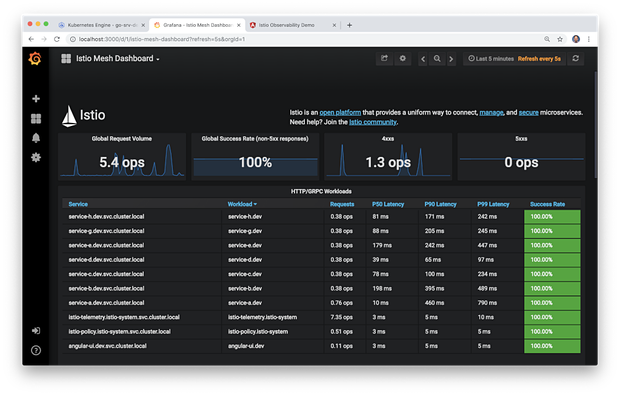
有效的可观测性策略一定不仅仅包括可视化结果的能力,还必须包括异常检测并通知(警报)合适的资源或直接采取行动以解决事件的能力。像Prometheus一样,Grafana能够发出警报和通知。你可以直观地为关键指标定义警报规则。Grafana将根据规则不断评估指标,并在违反预定义阈值时发送通知。
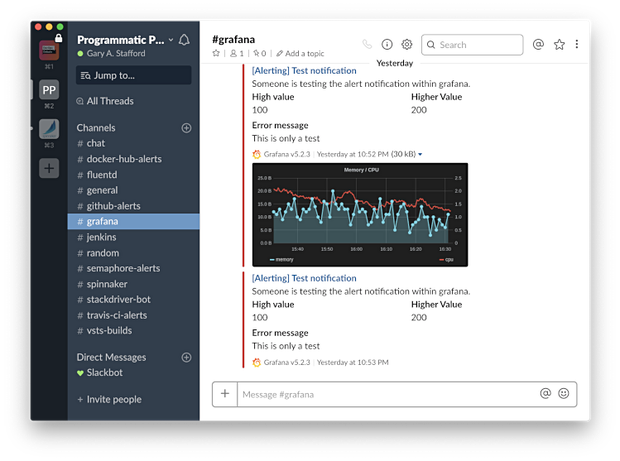
Grafana支持多种流行的 通知渠道 ,包括PagerDuty,HipChat,Email,Kafka和Slack。下面是一个新的通知频道,它向Slack支持频道发送警报通知。
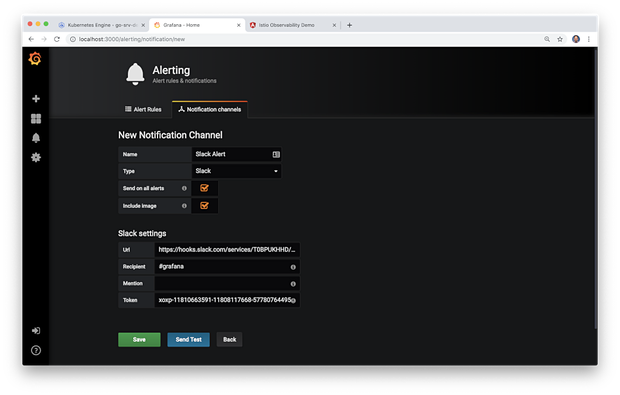
Grafana能够发送详细的基于文本和视图的通知。
链路跟踪
根据 Open Tracing 网站介绍,分布式跟踪(也称为分布式请求跟踪)是一种用于分析和监控应用程序的方法,尤其是那些使用微服务架构构建的应用程序。分布式跟踪有助于查明故障发生的位置以及导致性能低下的原因。
Istio 中说到,尽管Istio中的代理程序能够自动发送span信息,但应用程序需要能传播适当的HTTP头信息,这样当代理发送span时,该span可以正确地关联到单个跟踪中。为此,应用程序需要收集传入请求中的以下头部并将其传播到任何传出的请求。
x-request-id x-b3-traceid x-b3-spanid x-b3-parentspanid x-b3-sampled x-b3-flags x-ot-span-context
x-b3 头部一开始作为Zipkin项目的一部分。标题的B3部分以Zipkin的原始名称BigBrotherBird命名。在服务调用之间传递这些标头称为 B3传播 。根据 Zipkin 文档,这些属性在进程间传播,最终在下游(通常通过HTTP头)传播,以确保来自同一根的所有活动被收集在一起。
为了演示Jaeger的分布式跟踪,我修改了服务A,服务B和服务E,这三个服务会向其他上游服务发出HTTP请求。我添加了以下代码以便将标头从一个服务传播到下一个服务。Istio的边车代理,即 envoy 生成第一个 报头 。至关重要的是,你只需传播下游请求中存在且包含值的标头,如下代码所示。传播任何一个空的请求头将破坏分布式跟踪。
headers := []string{
"x-request-id",
"x-b3-traceid",
"x-b3-spanid",
"x-b3-parentspanid",
"x-b3-sampled",
"x-b3-flags",
"x-ot-span-context",
}
for _, header := range headers {
if r.Header.Get(header) != "" {
req.Header.Add(header, r.Header.Get(header))
}
}
下图在高亮的Stackdriver日志条目的JSON有效负载中,我们看到从根span传播所需的头部,其中包含一个值,在上游请求中从服务A传递到服务C.

Jaeger
Jaeger 是受 Dapper 和 OpenZipkin 启发,是 Uber科技 开源的一套分布式跟踪系统。它用于监控和为基于微服务的分布式系统提供故障排除功能,包括了分布式上下文传播,分布式事务监控,根源分析,服务依赖性分析以及性能和延迟优化。 Jaeger网站 对Jaeger的架构和通用的跟踪相关术语进行了很好的概述。
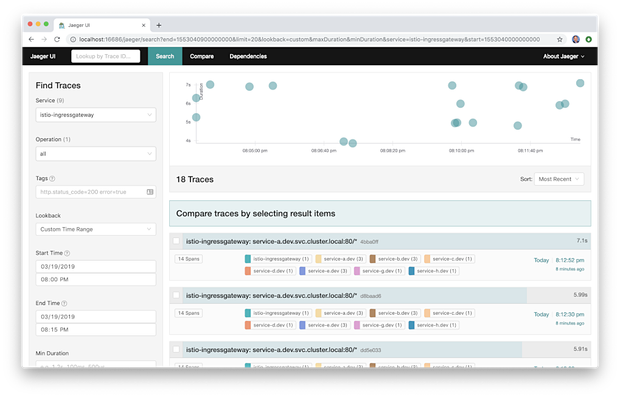
下面我们看到Jaeger UI的Traces(跟踪)页面。其显示在大约四十分钟时间内搜索Istio Ingress Gateway服务的结果。我们在顶部看到了跟踪时间线,下面是跟踪结果列表。正如 Jaeger网站 上所讨论的,跟踪由span组成。span表示Jaeger中具有操作名称的逻辑工作单元。一次跟踪代表了通过系统的执行路径,可以被认为是 有向无环图 (DAG)或 span 。如果你曾使用过类似Apache Spark这样的系统,那么你可能已经很熟悉DAG是什么。
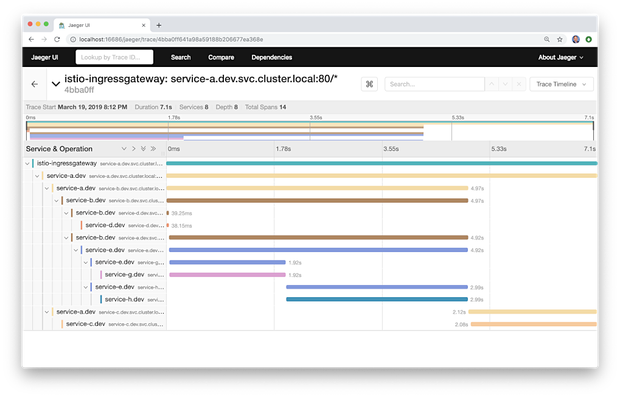
下面我们看到Jaeger UI的Trace Detail(跟踪详情)页面。该示例跟踪包含16个span,其中包含八个服务,七个基于Go的服务中和一个Istio Ingress Gateway。跟踪跟span都有各自的时间记录。跟踪中的根span是Istio Ingress Gateway。在终端用户的Web浏览器中加载的Angular UI通过Istio Ingress Gateway调用网格边缘服务A。从这一步开始,我们看到了服务到服务间IPC的预期流程。服务A调用服务B和C,服务B调用服务E,E又调用服务G和服务H。在该演示中,跟踪不贯穿RabbitMQ消息队列。这意味着你不能从RabbitMQ中看到包含从服务D到服务F的调用的跟踪。
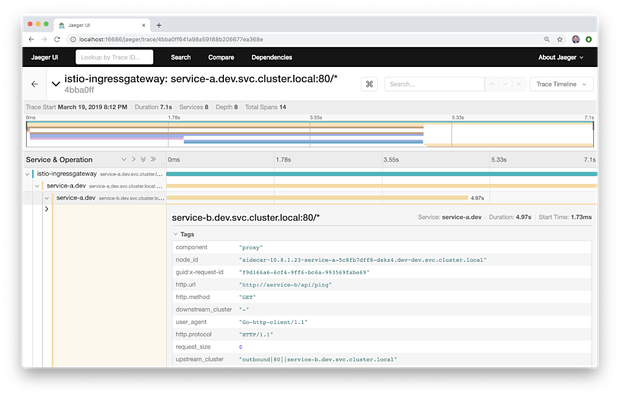
在Jaeger UI跟踪详情页中,你还可以定位到包含其他元数据的单个范围。元数据包括被调用的URL,HTTP方法,响应状态和其他几个头部信息。
Jaeger的最新版本还包括Compare(对比)功能和两个Dependencies(依赖)视图,力导向图和DAG。我发现这两种视图与Kiali相比比较原始,与Service Graph更相似。在Kiali成为可能之前,这些作为依赖图来说非常有用。
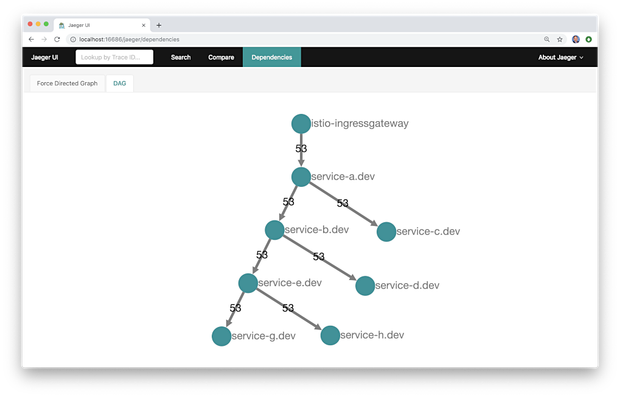
Kiali: 微服务观测
在 Kiali网站 上,我们大部分人对服务网格存在的问题得到了解答:我的Istio服务网格中有哪些微服务,它们是如何连接的?这里通过一个通用的Kubernetes Secret 对象来控制对Kiali API和UI的访问。默认登录名是 admin ,密码是 1f2d1e2e67df 。
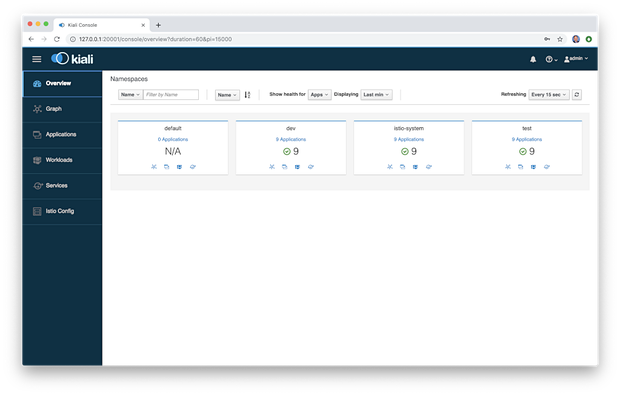
登录到Kiali后,我们能看到Overview菜单条目,它提供了Istio服务网格中所有命名空间的全局视图以及每个命名空间中的应用程序数。
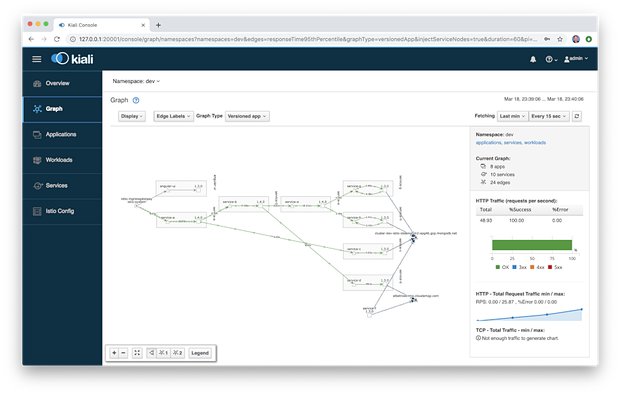
Kiali UI中的图形视图是在Istio服务网格中运行的组件的直观展示。下面,对集群的 dev 命名空间进行过滤,我们可以观察到Kiali映射了8个应用程序(工作负载),10个服务和24个边界(图形术语)。具体来说,我们看到服务网格边缘的Istio Ingress代理,Angular UI,八个基于Go的微服务及其处理流量的Envoy代理边车(在此示例中服务F没有从其他服务直接获取流量),外部MongoDB Atlas集群和外部CloudAMQP集群。注意服务到服务的流量走向,通过Istio是如何从服务流向其边车代理再流向另一个服务的边车代理,最后到达其他服务。
下面,我们看到了服务网格的类似视图,但此时Istio Ingress网关和服务A之间存在故障,以红色显示。我们还可以观察HTTP流量的总体指标,例如每分钟共多少请求,错误和状态代码。
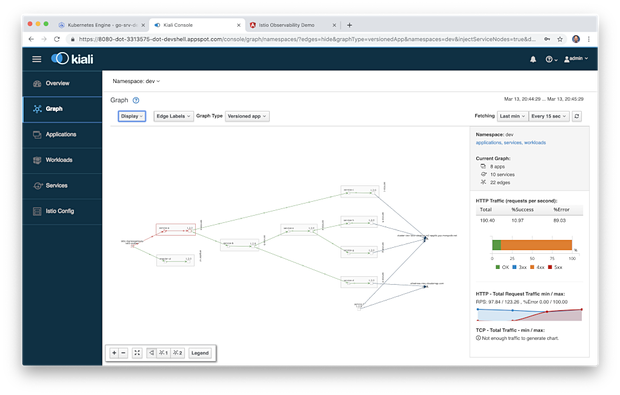
Kiali还可以显示图表中每个边界的平均请求时间和其他指标(即两个组件之间的通信)。
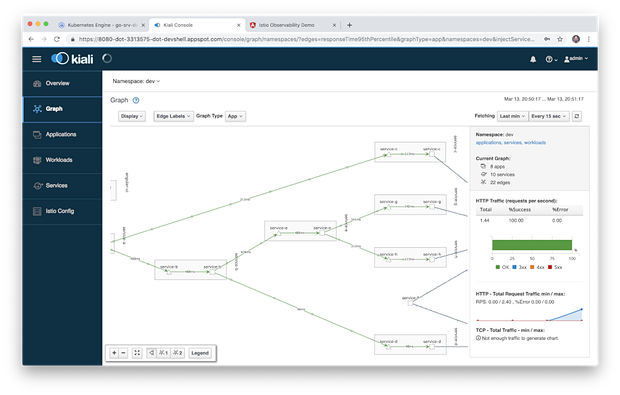
Kiali还可以显示部署的应用程序版本,如下所示,微服务中包含了版本1.3和1.4。
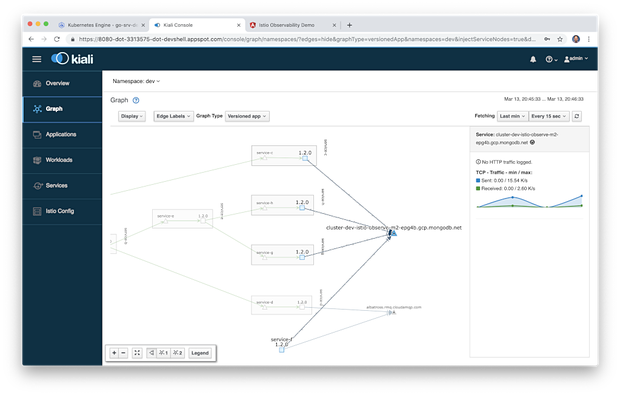
再说到外部的MongoDB Atlas集群,Kiali还允许我们查看在服务网格中的四个服务与外部集群的TCP流量。
“Applications(应用)”菜单列表列出了所有应用程序及其错误率,可以按命名空间和时间间隔进行筛选。在这里,我们看到Angular UI以16.67%的速率产生错误。
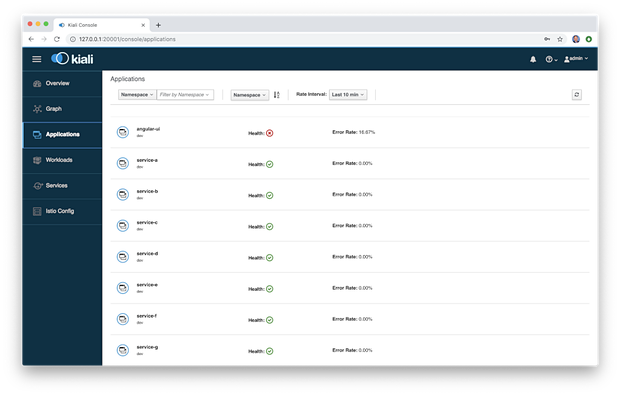
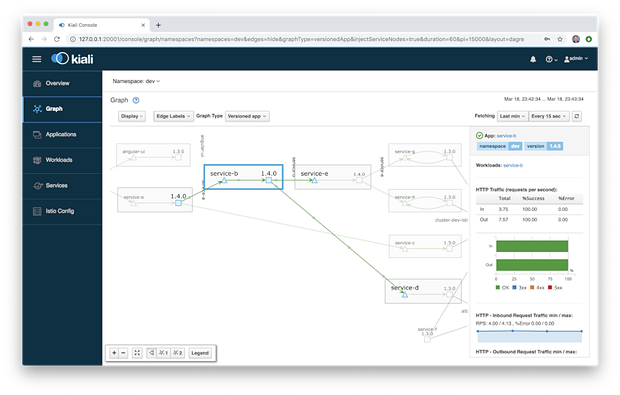
在Applications跟Workloads菜单条目中,我们可以深入查看组件以查看其详细信息,包括总体运行状况,Pod数量,服务和目标服务。下面我们可以查看在 dev 命名空间中服务B的详细信息。
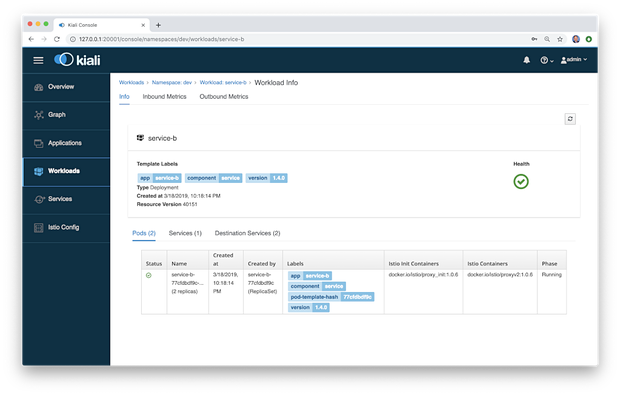
Workloads详细视图还包括入站和出站指标。下面是 dev 命名空间中服务A的出站流量,持续时间和大小度量标准。

最后,Kiali还提供了一个Istio Config菜单。Istio Config菜单显示用户环境中存在的所有可用Istio配置对象的列表。
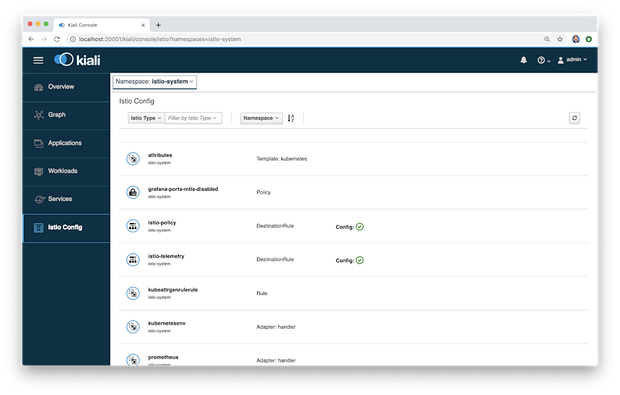
通常情况下,Kiali是我在解决平台问题时的第一个工具。一旦我确定了有问题的特定组件或通信路径,我就可以搜索Stackdriver日志和通过Grafana仪表板搜索Prometheus指标。
结论
在本系列文中,我们探索了当前最新版本的Istio服务网格中的一部分,可观测性工具集。它包括了Prometheus和Grafana,用于度量指标收集,监控和警报,Jaeger用于分布式跟踪,以及Kiali提供给Istio基于服务网格的微服务可视化。结合云平台本地监控和日志记录服务,例如谷歌云平台(GCP)上的Google Kubernetes Engine(GKE)Stackdriver,我们为现代分布式应用程序提供了完整的可观测性解决方案。
【原文链接】 Kubernetes-based Microservice Observability with Istio Service Mesh: Part 2 翻译:冯旭松
正文到此结束
- 本文标签: 可观测性 google cloud 插件 Connection Service zipkin 并发 端口 集群 API Kubernetes 谷歌 TypeScript Go语言 分布式 微服务 翻译 CDN 标题 数据 App 分布式事务 Uber Security id 适配器 服务器 js 网站 开源软件 空间 消息队列 Logging 服务端 amqp root https cat UI TCP json 开源 文章 希望 mongo web ip 产品 时间 实例 开发 ACE MQ bug apache shell 进程 基金 代码 parse dependencies http IO 分布式系统 zip mail 数据库 配置 Google MongoDB 软件 src ORM rabbitmq 部署 云 db 科技 安装
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

