详解多线程
一个任务通常就是一个程序,每个运行中的程序就是一个进程。当一个程序运行时,内部可能包含了多个顺序执行流,每个顺序执行流就是一个线程。
进程
定义:
当一个程序进入内存运行时,即变成一个进程。进程是处于运行过程中的程序,并且具有一定的独立功能,进程是系统进行资源分配和调度的一个独立单位。
进程的特点:
-
独立性: 是系统独立存在的实体,拥有自己独立的资源,有自己私有的地址空间。在没有经过进程本身允许的情况下,一个用户的进程不可以直接访问其他进程的地址空间。
-
动态性: 进程与程序的区别在于:程序只是一个静态的指令集合,而进程是一个正在系统中活动的指令集和,进程中加入了时间的概念。进程具有自己的生命周期和不同的状态,这些都是程序不具备的。
-
并发性: 多个进程可以在单个处理器上并发执行,多个进程之间不会相互影响。
并行性和并发性
并行: 指在同一时刻,有多条指令在多个处理上同时执行。(多核同时工作)
并发: 指在同一时刻只能有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。(单核在工作,单核不停轮询)
线程
多线程扩展了多进程的概念,使得同一个进程可以同时并发处理多个任务。
线程(Thread)也被成为轻量级的进程,线程是进程执行的单元,线程在程序中是独立的、并发的执行流
当进程被初始化后,主线程就被创建了。绝大数应用程序只需要有一个主线程,但也可以在进程内创建多条的线程,每个线程也是相互独立的。
一个进程可以拥有多个线程,一个线程必须有一个父进程。
线程可以拥有自己的堆栈、自己的程序计数器和自己的局部变量,但不拥有系统资源,它与父进程的其他线程共享该进程所拥有的全部资源,因此编程更加方便。
线程是独立运行的,它并不知道进程中是否还有其他的线程存在。线程的执行是抢占式的,即:当前运行的线程在任何时候都有可能被挂起,以便另外一个线程可以运行。
一个线程可以创建和撤销另一个线程,同一个进程中多个线程之间可以并发执行。
线程的调度和管理由进程本身负责完成。
归纳而言:操作系统可以同时执行多个任务,每个任务就是进程;进程可以同时执行多个任务,每个任务就是线程
多线程的优点:
-
进程之间不能共享内存,但线程之间共享内存非常容易
-
系统创建进程要为该进程重新分配系统资源,但创建线程的代价则小得多。因此多线程实现多任务并发比多线程的效率高。
-
Java语言内置了多线程功能支撑,简化了多线程的编程。
线程的创建和启动
一、继承Thread类创建线程类
步骤:
① 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,称为 线程执行体
② 创建Thread子类的实例,即创建了线程对象
③ 调用线程对象的start()方法来启动该线程
示例:
// 通过继承Thread类来创建线程类
public class FirstThread extends Thread
{
private int i ;
// 重写run方法,run方法的方法体就是线程执行体
public void run()
{
for ( ; i < 100 ; i++ )
{
// 当线程类继承Thread类时,直接使用this即可获取当前线程
// Thread对象的getName()返回当前该线程的名字
// 因此可以直接调用getName()方法返回当前线程的名
System.out.println(getName() + " " + i);
}
}
public static void main(String[] args)
{
for (int i = 0; i < 100; i++)
{
// 调用Thread的currentThread方法获取当前线程
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 20)
{
// 创建、并启动第一条线程
new FirstThread().start();
// 创建、并启动第二条线程
new FirstThread().start();
}
}
}
}
复制代码
注意点:
① 当Java程序开始运行后,程序至少会创建一个主线程,main()方法的方法体代表主线程的线程执行体
② 当线程类继承Tread类时,直接使用this即可以获取当前线程
③ 继承Thread类创建线程类,多个线程之间无法共享线程类的实例变量
二、实现Runnable接口创建线程类
步骤:
① 定义Runnable接口的实现类,并重写该接口的run()方法
② 创建Runnable实现类的实例,并以此实例作为Thread的target来创建Tread对象,该Tread对象才是真正的线程对象
// 通过实现Runnable接口来创建线程类
public class SecondThread implements Runnable
{
private int i ;
// run方法同样是线程执行体
public void run()
{
for ( ; i < 100 ; i++ )
{
// 当线程类实现Runnable接口时,
// 如果想获取当前线程,只能用Thread.currentThread()方法。
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++)
{
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 20)
{
SecondThread st = new SecondThread(); // ①
// 通过new Thread(target , name)方法创建新线程
new Thread(st , "新线程1").start();
new Thread(st , "新线程2").start();
}
}
}
}
复制代码
注意点:
① 实现Runnable接口创建线程类,必须通过Thread.currentThread()方法来获得当前线程对象
② 实现Runnable接口创建线程类,多个线程可以共享线程类的实例变量
三、使用Callable和Future创建线程
Callable接口提供了一个call()方法,call()方法比run()方法更强大:
① call()方法可以由返回值
② call()方法可以声明抛出异常
步骤:
① 创建Callable接口的实现类,并实现call()方法,该call()方法作为线程执行体,且该call()方法有返回值
② 使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值
③ 调用FutureTask对象的get()方法获得子线程执行结束的返回值
示例:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
//使用Callable接口和Future来创建线程
public class ThreadFuture {
//抛出异常
public static void main(String[] args) throws InterruptedException, ExecutionException {
//创建FutureTask对象,包装 Callable接口实例
FutureTask<Integer> task = new FutureTask<Integer>((Callable<Integer>)()->{
int sum = 0;
for(int i = 0;i<100;i++){
System.out.println(Thread.currentThread().getName()+":"+i);
sum += i;
}
//注意看这里有返回值
return sum;
});
//使用task作为 Thread类的target 来创建一个线程
Thread instance = new Thread(task);
//启动线程
instance.start();
//sleep一段时间,让上面的线程执行完毕
Thread.sleep(1000);
//这里可以调用task.get() 获取上面的那个线程的返回值
System.out.println("线程返回值:"+task.get());
}
}
复制代码
创建线程三种方式的对比:
实现Runnable接口、Callable接口创建线程
优点:
①实现的是接口,还可以继承其他类
② 多个线程可以共享同一个target对象,适合多个相同的线程来处理同一份资源的情况
缺点:
① 编程稍微复杂
② 获取当前线程必须用Thread.currentThread()方法来获得
继承Tread类创建线程
优点:
①编程简单
② 获取当前线程,可以直接使用this来获得
缺点:
① 已经继承了Thread类,不能继承其他类
线程的生命周期
线程的生命周期要经历新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocke)和死亡(Dead)5种状态。
尤其是当线程启动以后,它不可能一直“霸占”着CPU独自运行,所以CPU需要在多条线程之间切换,于是线程状态也会多次在运行、阻塞之间切换。
1、新建和就绪状态
当程序使用 new 关键字创建了一个线程之后,该线程就处于新建状态,此时它仅仅由Java虚拟机为其分配内存,并且初始化其成员变量的值。此时的线程对象没有表现出任何线程队动态特征,程序也不会执行线程的线程执行体。
当线程对象调用了 start() 方法之后,该线程处于就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态中的线程并没有开始运行,只是表示该线程可以运行了,至于该线程何时开始运行,取决于JVM里线程调度器的调度。
tips:
-
启动线程使用
start()方法,而不是run()方法,如果调用run()方法,则run()方法立即就会被执行,而且在run()方法返回之前,其他线程无法并发执行,也就是说,如果直接调用线程对象的run()方法,系统把线程对象当成一个普通对象,而run()方法也是一个普通方法,而不是线程执行体。 -
如果直接调用线程对象的
run()方法,则run()方法里不能直接通过getName()方法来获得当前执行线程的名字,而是需要使用Thread.currentThread()方法先获得当前线程,再调用线程对象的getName()方法来获得线程的名字。启动线程的正确方法是调用Thread对象的start()方法,而不是直接调用run()方法,否则就变成单线程程序了。 -
调用了线程的
run()方法之后,该线程已经不再处于新建状态,不要再次调用线程对象的start()方法。
2、运行和阻塞状态
如果处于就绪状态的线程获得了CPU,开始执行 run() 方法的线程执行体,则该线程处于运行状态。
但线程不可能一直处于运行状态,它在运行过程中会被中断,从而进入一个阻塞的状态
当发生如下情况时,线程将会进入阻塞状态:
1、线程调用 sleep() 方法主动放弃所占用的处理器资源。
2、线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
3、线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。
4、线程在等待某个通知(notify)。
5、程序调用了线程的 suspend() 方法将该线程挂起。但这个方法容易导致死锁,所以应该尽量避免使用该方法。
针对上面几种情况,当发生如下特定的情况时可以解除上面的阻塞,让该线程重新进入就绪状态。
1、调用 sleep() 方法的线程经过了指定时间。
2、线程调用的阻塞式IO方法已经返回。
3、 线程成功地获得了试图取得的同步监视器。
4、 线程正在等待某个通知时,其他线程发出了一个通知。
5、处于挂起状态的线程被调用了 resume() 恢复方法。
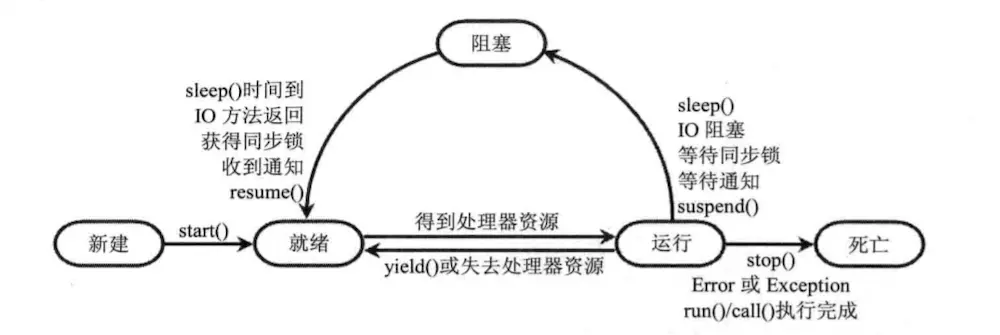
线程状态转化图
从图中可以看出,线程从阻塞状态只能进入就绪状态,无法直接进入运行状态。
而就绪和运行状态之间的转换通常不受程序控制,而是由系统线程调度所决定。
当处于就绪状态的线程获得处理器资源时,该线程进入运行状态;当处于运行状态的线程失去处理器资源时,该线程进入就绪状态。
但有一个方法例外,调用 yield() 方法可以让运行状态的线程转入就绪状态。
线程死亡
线程会以如下三种方式结束,结束后就处于死亡状态。
-
run()或call()方法执行完成,线程正常结束。 -
线程抛出一个未捕获的
Exception或Error。 -
直接调用该线程的
stop()方法来结束该线程——该方法容易导致死锁,通常不推荐使用。
tips:
1、当主线程结束时,其他线程不受任何影响,并不会随之结束。一旦子线程启动起来后,它就拥有和主线程相同的地位,它不会受主线程的影响。
2、为了测试某个线程是否已经死亡,可以调用线程对象的 isAlive() 方法,当线程处于就绪、运行、阻塞三种状态时,该方法将返回 true ;当线程处于新建、死亡两种状态时,该方法将返回 false 。
3、不要试图对一个已经死亡的线程调用 start() 方法使它重新启动,死亡就是死亡,该线程将不可再次作为线程执行。在线程已经死亡的情况下再次调用 start() 方法将会引发 IIIegalThreadException 异常。
4、不能对死亡的线程调用 start() 方法,程序只能对新建状态的线程调用start()方法,对新建的线程两次调用start()方法也是错误的,会引发 IIIegalThreadStateException 异常。
控制线程
1、join线程
Thread 提供了让一个线程等待另一个线程完成的方法: join() 方法。当在某个程序执行流中调用其他线程的 join() 方法时,调用线程将被阻塞,直到被 join() 方法加入的 join 线程执行完为止。
join() 方法通常由使用线程的程序调用,以将大问题划分成许多小问题,每个小问题分配一个线程。当所有的小问题都得到处理后,再调用主线程来进一步操作。
代码示例:
public class JoinThread extends Thread
{
// 提供一个有参数的构造器,用于设置该线程的名字
public JoinThread(String name)
{
super(name);
}
// 重写run()方法,定义线程执行体
public void run()
{
for (int i = 0; i < 100 ; i++ )
{
System.out.println(getName() + " " + i);
}
}
public static void main(String[] args)throws Exception
{
// 启动子线程
new JoinThread("新线程").start();
for (int i = 0; i < 100 ; i++ )
{
if (i == 20)
{
JoinThread jt = new JoinThread("被Join的线程");
jt.start();
// main线程调用了jt线程的join()方法,main线程必须等jt执行结束才会向下执行
jt.join();
}
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
复制代码
2、后台线程
有一种线程,它是在后台运行的,它的任务是为其他的线程提供服务,这种线程被称为“后台线程(Daemon Thread)”,又称为“守护线程”或“精灵线程”。JVM的垃圾回收线程就是典型的后台线程。
后台线程有个特征:如果所有的前台线程都死亡,后台线程会自动死亡。
调用 Thread 对象的 setDaemon(true) 方法可将指定线程设置成后台线程。
tips:
1、 Thread 类还提供了一个 isDaemon() 方法,用于判断指定线程是否为后台线程。
2、前台线程创建的子线程默认是前台线程,后台线程子线程默认是后台线程。
3、前台线程死亡后,JVM会通知后台线程死亡,但从它接收指令到做出响应,需要一定时间。
而且要将某个线程设置为后台线程,必须在该线程启动之前设置,也就是说, setDaemon(true) 必须在 start() 方法之前调用,否则会引发 llegalThreadStateException 异常。
3、线程睡眠:sleep
如果需要让当前正在执行的线程暂停一段时间,并进入阻塞状态,则可以通过调用 Thread 类的静态 sleep() 方法来实现。
4、线程让步yield()
yield() 方法是一个和 sleep() 方法有点相似的方法,它也是 Thread 类提供的一个静态方法,它也可以让当前正在执行的线程暂停,但它不会阻塞该线程,它只是将该线程转入就绪状态。
yield() 只是让当前线程暂停一下,让系统的线程调度器重新调度一次,完全可能的情况是:当某个线程调用了 yield() 方法暂停之后,线程调度器又将其调度出来重新执行。
实际上,当某个线程调用了 yield() 方法暂停之后,只有优先级与当前线程相同,或者优先级比当前线程更高的处于就绪状态的线程才会获得执行的机会。
关于 sleep() 方法和 yield() 方法的区别如下
-
sleep()方法暂停当前线程后,会给其他线程执行机会,不会理会其他线程的优先级;但yield()方法只会给优先级相同,或优先级更高的线程执行机会。 -
sleep()方法会将线程转入阻塞状态,直到经过阻塞时间才会转入就绪状态;而yield()不会将线程转入阻塞状态,它只是强制当前线程进入就绪状态。因此完全有可能某个线程调用yield()方法暂停之后,立即再次获得处理器资源被执行。 -
sleep()方法声明抛出了InterruptedException异常,所以调用sleep()方法时要么捕捉该异常,要么显式声明抛出该异常;而yield()方法则没有声明抛出任何异常。 -
sleep()方法比yield()方法有更好的可移植性,通常不建议使用yield()方法来控制并发线程的执行。
5、改变线程优先级
通过 Thread 类提供的 setPriority(int newPriority) 、 getPriority() 方法来设置和返回指定线程的优先级。
setPriority() 方法的参数可以是一个整数,范围是1~10之间,也可以使用 Thread 类的如下三个静态常量。
MAXPRIORITY:其值是10。
MIN PRIORITY:其值是1。
NORM_PRIORITY:其值是5。
线程同步
为了解决多个线程访问同一个数据时,会出现问题,因此需要进行线程同步。就像前面介绍的文件并发访问,当有两个进程并发修改同一个文件时就有可能造成异常。
1、同步代码块
为了解决线程同步问题,Java的多线程支持引入了同步监视器来解决这个问题,使用同步监视器的通用方法就是同步代码块。同步代码块的语法格式如下:
synchronized(obj)
{.....
//此处的代码就是同步代码块
}
复制代码
上面语法格式中synchronized后括号里的obj就是同步监视器,上面代码的含义是:线程开始执行同步代码块之前,必须先获得对同步监视器的锁定。
任何时刻只能有一个线程可以获得对同步监视器的锁定,当同步代码块执行完成后,该线程会释放对该同步监视器的锁定。
通常推荐使用可能被并发访问的共享资源充当同步监视器,代码示例如下:
public class DrawThread extends Thread
{
// 模拟用户账户
private Account account;
// 当前取钱线程所希望取的钱数
private double drawAmount;
public DrawThread(String name , Account account
, double drawAmount)
{
super(name);
this.account = account;
this.drawAmount = drawAmount;
}
// 当多条线程修改同一个共享数据时,将涉及数据安全问题。
public void run()
{
// 使用account作为同步监视器,任何线程进入下面同步代码块之前,
// 必须先获得对account账户的锁定——其他线程无法获得锁,也就无法修改它
// 这种做法符合:“加锁 → 修改 → 释放锁”的逻辑
synchronized (account)
{
// 账户余额大于取钱数目
if (account.getBalance() >= drawAmount)
{
// 吐出钞票
System.out.println(getName()
+ "取钱成功!吐出钞票:" + drawAmount);
try
{
Thread.sleep(1);
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
// 修改余额
account.setBalance(account.getBalance() - drawAmount);
System.out.println("/t余额为: " + account.getBalance());
}
else
{
System.out.println(getName() + "取钱失败!余额不足!");
}
}
// 同步代码块结束,该线程释放同步锁
}
}
复制代码
2、同步方法
同步方法就是使用 synchronized 关键字来修饰某个方法,则该方法称为同步方法。
对于 synchronized 修饰的实例方法(非static方法)而言,无须显式指定同步监视器,同步方法的同步监视器是 this ,也就是调用该方法的对象。
通过使用同步方法可以非常方便地实现线程安全的类,线程安全的类具有如下特征。
-
该类的对象可以被多个线程安全地访问。
-
每个线程调用该对象的任意方法之后都将得到正确结果。
-
每个线程调用该对象的任意方法之后,该对象状态依然保持合理状态。
代码示例:
public class Account
{
// 封装账户编号、账户余额两个成员变量
private String accountNo;
private double balance;
public Account(){}
// 构造器
public Account(String accountNo , double balance)
{
this.accountNo = accountNo;
this.balance = balance;
}
// accountNo的setter和getter方法
public void setAccountNo(String accountNo)
{
this.accountNo = accountNo;
}
public String getAccountNo()
{
return this.accountNo;
}
// 因此账户余额不允许随便修改,所以只为balance提供getter方法,
public double getBalance()
{
return this.balance;
}
// 提供一个线程安全draw()方法来完成取钱操作
public synchronized void draw(double drawAmount)
{
// 账户余额大于取钱数目
if (balance >= drawAmount)
{
// 吐出钞票
System.out.println(Thread.currentThread().getName()
+ "取钱成功!吐出钞票:" + drawAmount);
try
{
Thread.sleep(1);
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
// 修改余额
balance -= drawAmount;
System.out.println("/t余额为: " + balance);
}
else
{
System.out.println(Thread.currentThread().getName()
+ "取钱失败!余额不足!");
}
}
// 下面两个方法根据accountNo来重写hashCode()和equals()方法
public int hashCode()
{
return accountNo.hashCode();
}
public boolean equals(Object obj)
{
if(this == obj)
return true;
if (obj !=null
&& obj.getClass() == Account.class)
{
Account target = (Account)obj;
return target.getAccountNo().equals(accountNo);
}
return false;
}
}
复制代码
上面程序中增加了一个代表取钱的 draw() 方法,并使用了 synchronized 关键字修饰该方法,把该方法变成同步方法。
该同步方法的同步监视器是 this ,因此对于同一个 Account 账户而言,任意时刻只能有一个线程获得对 Account 对象的锁定,然后进入 draw() 方法执行取钱操作,这样也可以保证多个线程并发取钱的线程安全。
3、释放同步监视器的锁定
程序无法显式释放对同步监视器的锁定,线程会在如下情况下释放对同步监视器的锁定。
-
当前线程的同步方法、同步代码块执行结束,当前线程即释放同步监视器。
-
当前线程在同步代码块、同步方法中遇到
break、return终止了该代码块、该方法的继续执行,当前线程将会释放同步监视器。 -
当前线程在同步代码块、同步方法中出现了未处理的Error 或Exception,导致了该代码块、该方法异常结束时,当前线程将会释放同步监视器。
-
当前线程执行同步代码块或同步方法时,程序执行了同步监视器对象的wait0方法,则当前线程暂停,并释放同步监视器。
在如下所示的情况下,线程不会释放同步监视器:
-
线程执行同步代码块或同步方法时,程序调用
Thread.sleep()、Thread.yield()方法来暂停当前线程的执行,当前线程不会释放同步监视器。 -
线程执行同步代码块时,其他线程调用了该线程的
suspend()方法将该线程挂起,该线程不会释放同步监视器。当然,程序应该尽量避免使用suspend()和resume()方法来控制线程。
4、同步锁(Lock)
Lock、ReadWriteLock是Java5提供的两个根接口,并为Lock提供ReentrantLock(可重入锁)实现类,为ReadWriteLock提供了ReentrantReadWriteLock 实现类。
Java8新增了新型的StampedLock类,在大多数场景中它可以替代传统的ReentrantReadWriteLock。
ReentrantReadWriteLock为读写操作提供了三种锁模式:Writing、ReadingOptimistic、Reading。
在实现线程安全的控制中,比较常用的是ReentrantLock(可重入锁)。使用该Lock对象可以显式地加锁、释放锁,通常使用ReentrantLock的代码格式如下:
public class Account
{
// 定义锁对象
private final ReentrantLock lock = new ReentrantLock();
// 封装账户编号、账户余额的两个成员变量
private String accountNo;
private double balance;
public Account(){}
// 构造器
public Account(String accountNo , double balance)
{
this.accountNo = accountNo;
this.balance = balance;
}
// accountNo的setter和getter方法
public void setAccountNo(String accountNo)
{
this.accountNo = accountNo;
}
public String getAccountNo()
{
return this.accountNo;
}
// 因此账户余额不允许随便修改,所以只为balance提供getter方法,
public double getBalance()
{
return this.balance;
}
// 提供一个线程安全draw()方法来完成取钱操作
public void draw(double drawAmount)
{
// 加锁
lock.lock();
try
{
// 账户余额大于取钱数目
if (balance >= drawAmount)
{
// 吐出钞票
System.out.println(Thread.currentThread().getName()
+ "取钱成功!吐出钞票:" + drawAmount);
try
{
Thread.sleep(1);
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
// 修改余额
balance -= drawAmount;
System.out.println("/t余额为: " + balance);
}
else
{
System.out.println(Thread.currentThread().getName()
+ "取钱失败!余额不足!");
}
}
finally
{
// 修改完成,释放锁
lock.unlock();
}
}
// 下面两个方法根据accountNo来重写hashCode()和equals()方法
public int hashCode()
{
return accountNo.hashCode();
}
public boolean equals(Object obj)
{
if(this == obj)
return true;
if (obj !=null
&& obj.getClass() == Account.class)
{
Account target = (Account)obj;
return target.getAccountNo().equals(accountNo);
}
return false;
}
}
复制代码
同步方法或同步代码块使用与竞争资源相关的、隐式的同步监视器,并且强制要求加锁和释放锁要出现在一个块结构中,而且当获取了多个锁时,它们必须以相反的顺序释放,且必须在与所有锁被获取时相同的范围内释放所有锁。
Lock提供了同步方法和同步代码块所没有的其他功能,包括用于非块结构的 tryLock() 方法,以及试图获取可中断锁的 lockInterruptibly() 方法,还有获取超时失效锁的 tryLock(long,TimeUnit) 方法。
ReentrantLock 锁具有可重入性,也就是说,一个线程可以对已被加锁的 ReentrantLock 锁再次加锁, ReentrantLock 对象会维持一个计数器来追踪 lock() 方法的嵌套调用,线程在每次调用 lock() 加锁后,必须显式调用 unlock() 来释放锁,所以一段被锁保护的代码可以调用另一个被相同锁保护的方法。
死锁
当两个线程相互等待对方释放同步监视器时就会发生死锁一旦出现死锁,整个程序既不会发生任何异常,也不会给出任何提示,只是所有线程处于阻塞状态,无法继续。
死锁示例:
有两个类 A 和 B ,这两个类每个类都各含有两个同步方法,利用两个线程来进行操作。
首先线程1调用 A 类的同步方法 A1,然后休眠,此时线程2会开始工作,它会调用 B 类的同步方法 B1,然后也休眠。
此时线程1休眠结束,它继续执行方法 A1 ,A1的下一步操作是调用 B 中的同步方法 B2,因为此时 B 的对象示例正被线程2所占据,因此线程1只能等待对 B 的锁的释放。
此时线程2又苏醒了,它继续执行方法 B1,B1的下一步操作是调用 A 中的同步方法 A2,因此是 A 类的对象也被线程1给锁住了,因此线程2也只能等待,这样就造成了线程1和线程2相互等待,从而导致了死锁的发生。
代码示例:
//A类
class A
{
public synchronized void foo( B b )
{
System.out.println("当前线程名: " + Thread.currentThread().getName()
+ " 进入了A实例的foo()方法" ); // ①
try
{
Thread.sleep(200);
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
System.out.println("当前线程名: " + Thread.currentThread().getName()
+ " 企图调用B实例的last()方法"); // ③
b.last();
}
public synchronized void last()
{
System.out.println("进入了A类的last()方法内部");
}
}
//B类
class B
{
public synchronized void bar( A a )
{
System.out.println("当前线程名: " + Thread.currentThread().getName()
+ " 进入了B实例的bar()方法" ); // ②
try
{
Thread.sleep(200);
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
System.out.println("当前线程名: " + Thread.currentThread().getName()
+ " 企图调用A实例的last()方法"); // ④
a.last();
}
public synchronized void last()
{
System.out.println("进入了B类的last()方法内部");
}
}
//线程类
public class DeadLock implements Runnable
{
A a = new A();
B b = new B();
public void init()
{
Thread.currentThread().setName("主线程");
// 调用a对象的foo方法
a.foo(b);
System.out.println("进入了主线程之后");
}
public void run()
{
Thread.currentThread().setName("副线程");
// 调用b对象的bar方法
b.bar(a);
System.out.println("进入了副线程之后");
}
//主函数
public static void main(String[] args)
{
DeadLock dl = new DeadLock();
// 以dl为target启动新线程
new Thread(dl).start();
// 调用init()方法
dl.init();
}
}
复制代码
线程通信
1、传统的线程通信——通过Object类提供的方法实现
借助于 Object 类提供的 wait() 、 notify() 和 notifyAll() 三个方法。
这三个方法并不属于 Thread 类,而是属于 Object 类。但这三个方法必须由同步监视器对象来调用,这可分成以下两种情况。
-
对于使用synchronized修饰的同步方法,因为该类的默认实例(this)就是同步监视器,所以可以在同步方法中直接调用这三个方法。
-
对于使用synchronized修饰的同步代码块,同步监视器是synchronized后括号里的对象,所以必须使用该对象调用这三个方法。
关于这三个方法的解释如下:
-
wait():导致当前线程等待,直到其他线程调用该同步监视器的notify()方法或notifyAll()方法来唤醒该线程。 -
notify():唤醒在此同步监视器上等待的单个线程。如果所有线程都在此同步监视器上等待,则会选择唤醒其中一个线程。选择是任意性的。只有当前线程放弃对该同步监视器的锁定后(使用wait()方法),才可以执行被唤醒的线程。 -
notifyAll:唤醒在此同步监视器上等待的所有线程。只有当前线程放弃对该同步监视器的锁定后,才可以执行被唤醒的线程。
使用Condition控制线程通信
如果程序不使用synchronized 关键字来保证同步,而是直接便用Lock对象采保证同步,则系统中下存在隐式的同步监视器,也就不能使用 wait() 、 notify() 、 notifyAll() 方法进行线程通信了。
当使用Lock 对象来保证同步时,Java提供了一个 Condition 类来保持协调,使用 Condition 可以让那些已经得到Lock对象却无法继续执行的线程释放 Lock 对象, Condition 对象也可以唤醒其他处于等待的线程。
Condition 实例被绑定在一个 Lock 对象上。要获得特定 Lock 实例的 Condition 实例,调用 Lock 对象的 newCondition() 方法即可。 Condition 类提供了如下三个方法:
-
await():类似于隐式同步监视器上的wait()方法,导致当前线程等待,直到其他线程调用该Condition的signal()方法或signalAll()方法来唤醒该线程。 -
signal():唤醒在此Lock对象上等待的单个线程。如果所有线程都在该Lock对象上等待,则会选择唤醒其中一个线程。选择是任意性的。只有当前线程放弃对该Lock对象的锁定后(使用await()方法),才可以执行被唤醒的线程。 -
signalAIl():唤醒在此Lock对象上等待的所有线程。只有当前线程放弃对该Lock对象的锁定后,才可以执行被唤醒的线程。
public class Account
{
// 显式定义Lock对象
private final Lock lock = new ReentrantLock();
// 获得指定Lock对象对应的Condition
private final Condition cond = lock.newCondition();
// 封装账户编号、账户余额的两个成员变量
private String accountNo;
private double balance;
// 标识账户中是否已有存款的旗标
private boolean flag = false;
public Account(){}
// 构造器
public Account(String accountNo , double balance)
{
this.accountNo = accountNo;
this.balance = balance;
}
// accountNo的setter和getter方法
public void setAccountNo(String accountNo)
{
this.accountNo = accountNo;
}
public String getAccountNo()
{
return this.accountNo;
}
// 因此账户余额不允许随便修改,所以只为balance提供getter方法,
public double getBalance()
{
return this.balance;
}
public void draw(double drawAmount)
{
// 加锁
lock.lock();
try
{
// 如果flag为假,表明账户中还没有人存钱进去,取钱方法阻塞
if (!flag)
{
cond.await();
}
else
{
// 执行取钱
System.out.println(Thread.currentThread().getName()
+ " 取钱:" + drawAmount);
balance -= drawAmount;
System.out.println("账户余额为:" + balance);
// 将标识账户是否已有存款的旗标设为false。
flag = false;
// 唤醒其他线程
cond.signalAll();
}
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
// 使用finally块来释放锁
finally
{
lock.unlock();
}
}
public void deposit(double depositAmount)
{
lock.lock();
try
{
// 如果flag为真,表明账户中已有人存钱进去,则存钱方法阻塞
if (flag) // ①
{
cond.await();
}
else
{
// 执行存款
System.out.println(Thread.currentThread().getName()
+ " 存款:" + depositAmount);
balance += depositAmount;
System.out.println("账户余额为:" + balance);
// 将表示账户是否已有存款的旗标设为true
flag = true;
// 唤醒其他线程
cond.signalAll();
}
}
catch (InterruptedException ex)
{
ex.printStackTrace();
}
// 使用finally块来释放锁
finally
{
lock.unlock();
}
}
// 下面两个方法根据accountNo来重写hashCode()和equals()方法
public int hashCode()
{
return accountNo.hashCode();
}
public boolean equals(Object obj)
{
if(this == obj)
return true;
if (obj !=null
&& obj.getClass() == Account.class)
{
Account target = (Account)obj;
return target.getAccountNo().equals(accountNo);
}
return false;
}
}
复制代码
使用阻塞队列(BlockingQueue)控制线程通信
Java5提供了一个 BlockingQueue 接口,虽然 BlockingQueue 也是 Queue 的子接口,但它的主要用途并不是作为容器,而是作为线程同步的工具。
BlockingQueue 具有一个特征:
当生产者线程试图向 BlockingOueue 中放入元素时,如果该队列已满,则该线程被阻塞;
当消费者线程试图从 BlockingQueue 中取出元素时,如果该队列已空,则该线程被阻塞。
BlockingQueue 提供如下两个支持阻塞的方法。
-
put(E e):尝试把E元素放入
BlockingQueue中,如果该队列的元素已满,则阻塞该线程。 -
take():尝试从BlockingQueue的头部取出元素,如果该队列的元素已空,则阻塞该线程。
BlockingQueue 继承了 Queue 接口,当然也可使用 Queue 接口中的方法。这些方法归纳起来可分为如下三组。
-
在队列尾部插入元素。包括
add(E e)、offer(E e)和put(Ee)方法,当该队列已满时,这三个方法分别会抛出异常、返回false、阻塞队列。 -
在队列头部删除并返回删除的元素。包括
remove()、poll()和take()方法。当该队列已空时,这三个方法分别会抛出异常、返回false、阻塞队列。 -
在队列头部取出但不删除元素。包括
element()和peek()方法,当队列已空时,这两个方法分别抛出异常、返回false。
使用阻塞队列(BlockingQueue)来实现线程通信,以消费者生产者为例:
//生产者类
class Producer extends Thread
{
private BlockingQueue<String> bq;
public Producer(BlockingQueue<String> bq)
{
this.bq = bq;
}
public void run()
{
String[] strArr = new String[]
{
"Java",
"Struts",
"Spring"
};
for (int i = 0 ; i < 999999999 ; i++ )
{
System.out.println(getName() + "生产者准备生产集合元素!");
try
{
Thread.sleep(200);
// 尝试放入元素,如果队列已满,线程被阻塞
bq.put(strArr[i % 3]);
}
catch (Exception ex){ex.printStackTrace();}
System.out.println(getName() + "生产完成:" + bq);
}
}
}
//消费者类
class Consumer extends Thread
{
private BlockingQueue<String> bq;
public Consumer(BlockingQueue<String> bq)
{
this.bq = bq;
}
public void run()
{
while(true)
{
System.out.println(getName() + "消费者准备消费集合元素!");
try
{
Thread.sleep(200);
// 尝试取出元素,如果队列已空,线程被阻塞
bq.take();
}
catch (Exception ex){ex.printStackTrace();}
System.out.println(getName() + "消费完成:" + bq);
}
}
}
//主程序
public class BlockingQueueTest2
{
public static void main(String[] args)
{
// 创建一个容量为1的BlockingQueue
BlockingQueue<String> bq = new ArrayBlockingQueue<>(1);
// 启动3条生产者线程
new Producer(bq).start();
new Producer(bq).start();
new Producer(bq).start();
// 启动一条消费者线程
new Consumer(bq).start();
}
}
复制代码
线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互。在这种情形下,使用线程池可以很好地提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
与数据库连接池类似的是,线程池在系统启动时即创建大量空闲的线程,程序将一个 Runnable 对象或 Callable 对象传给线程池,线程池就会启动一个线程来执行它们的r un() 或 call() 方法。
当 run() 或 call() 方法执行结束后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个 Runnable 对象的 run() 或 call() 方法。
除此之外,使用线程池可以有效地控制系统中并发线程的数量,当系统中包含大量并发线程时,会导致系统性能剧烈下降,甚至导致JVM崩溃,而线程池的最大线程数参数可以控制系统中并发线程数不超过此数。
创建线程池
在Java5以前,开发者必须手动实现自己的线程池;从Java5开始,Java内建支持线程池。
Java5新增了一个 Executors 工厂类来产生线程池,该工厂类包含如下几个静态工厂方法来创建线程池。
-
newCachedThreadPool():创建一个具有缓存功能的线程池,系统根据需要创建线程,这些线程将会被缓存在线程池中。 -
newFixedThreadPool(int nThreads):创建一个可重用的、具有固定线程数的线程池。 -
newSingle ThreadExecutor():创建一个只有单线程的线程池,它相当于调用newFixedThread Pool()方法时传入参数为1。 -
newScheduledThreadPool(int corePoolSize):创建具有指定线程数的线程池,它可以在指定延迟后执行线程任务。corePoolSize指池中所保存的线程数,即使线程是空闲的也被保存在线程池内。 -
newSingle ThreadScheduledExecutor):创建只有一个线程的线程池,它可以在指定延迟后执行线程任务。 -
ExecutorService new WorkStealingPool(int parallelism):创建持有足够的线程的线程池来支持给定的并行级别,该方法还会使用多个队列来减少竞争。 -
ExecutorService new WorkStealingPool):该方法是前一个方法的简化版本。如果当前机器有4个CPU,则目标并行级别被设置为4,也就是相当于为前一个方法传入4作为参数。
上面7个方法中的前三个方法返回一个 ExecutorService 对象,该对象代表一个线程池,它可以执行 Runnable 对象或 Callable 对象所代表的线程;
而中间两个方法返回一个 ScheduledExecutorService 线程池,它是 ExecutorService 的子类,它可以在指定延迟后执行线程任务;
最后两个方法则是Java8新增的,这两个方法可充分利用多CPU并行的能力。这两个方法生成的 work stealing 池,都相当于后台线程池,如果所有的前台线程都死亡了, work stealing 池中的线程会自动死亡。
ExecutorService 代表尽快执行线程的线程池(只要线程池中有空闲线程,就立即执行线程任务)
程序只要将一个 Runnable 对象或 Callable 对象(代表线程任务)提交给该线程池,该线程池就会尽快执行该任务。
ExecutorService里提供了如下三个方法。
-
Future<?>submit(Runnable task):将一个Runnable对象提交给指定的线程池,线程池将在有空闲线程时执行Runnable对象代表的任务。其中Future对象代表Runnable任务的返回值,但run()方法没有返回值,所以Future对象将在run()方法执行结束后返回null。
但可以调用 Future 的 isDone() 、 isCancelled() 方法来获得 Runnable 对象的执行状态。
-
<T>Future-T>submit(Runnable task,T result):将一个Runnable对象提交给指定的线程池,线程池将在有空闲线程时执行Runnable对象代表的任务。其中result显式指定线程执行结束后的返回值,所以Future对象将在run()方法执行结束后返回result。 -
<T>Future-T>submit(Callable<T>task):将一个Callable对象提交给指定的线程池,线程池将在有空闲线程时执行Callable对象代表的任务。其中Future代表Callable对象里call()方法的返回值。
ScheduledExecutorService 代表可在指定延迟后或周期性地执行线程任务的线程池,它提供了如下4个方法。
-
ScheduledFuture<V> schedule(Callable-V> callable,long delay,TimeUnit unit):指定callable任务将在delay延迟后执行。 -
ScheduledFuture<?>schedule(Runnable command,long delay,TimeUnit unit):指定command任务将在delay延迟后执行。 -
ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit):指定command任务将在delay延迟后执行,而且以设定频率重复执行。也就是说,在initialDelay后开始执行,依次在initialDelay+period、initialDelay+2*period…处重复执行,依此类推。 -
ScheduledFuture<?>scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit):创建并执行一个在给定初始延迟后首次启用的定期操作,随后在每一次执行终止和下一次执行开始之间都存在给定的延迟。如果任务在任一次执行时遇到异常,就会取消后续执行;否则,只能通过程序来显式取消或终止该任务。
用完一个线程池后,应该调用该线程池的shutdown0方法,该方法将启动线程池的关闭序列,调用 shutdown() 方法后的线程池不再接收新任务,但会将以前所有已提交任务执行完成。当线程池中的所有任务都执行完成后,池中的所有线程都会死亡;
另外也可以调用线程池的 shutdownNow() 方法来关闭线程池,该方法试图停止所有正在执行的活动任务,暂停处理正在等待的任务,并返回等待执行的任务列
表。
使用线程池来执行线程任务的步骤如下。
①调用 Executors 类的静态工厂方法创建一个 ExecutorService 对象,该对象代表一个线程池。
②创建 Runnable 实现类或 Callable 实现类的实例,作为线程执行任务。
③调用 ExecutorService 对象的 submit() 方法来提交 Runnable 实例或 Callable 实例。
④当不想提交任何任务时,调用 ExecutorService 对象的 shutdown() 方法来关闭线程池。
代码示例:
public class ThreadPoolTest
{
public static void main(String[] args)
throws Exception
{
// 创建足够的线程来支持4个CPU并行的线程池
// 创建一个具有固定线程数(6)的线程池
ExecutorService pool = Executors.newFixedThreadPool(6);
// 使用Lambda表达式创建Runnable对象
Runnable target = () -> {
for (int i = 0; i < 100 ; i++ )
{
System.out.println(Thread.currentThread().getName() + "的i值为:" + i);
}
};
// 向线程池中提交两个线程
pool.submit(target);
pool.submit(target);
// 关闭线程池
pool.shutdown();
}
}
复制代码
Java8增强的ForkJoinPool
Java7提供了 ForkJoinPool 来支持将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果。 ForkJoinPool 是 ExecutorService 的实现类,因此是一种特殊的线程池。
ForkJoinPool 提供了如下两个常用的构造器。
-
ForkJoinPool(int parallelism):创建一个包含parallelism个并行线程的ForkJoinPool。 -
ForkJoinPool():以Runtime.availableProcessors()方法的返回值作为parallelism参数来创建ForkJoinPool。
Java8进一步扩展了 ForkJoinPool 的功能,Java8为 ForkJoinPool 增加了通用池功能。
ForkJoinPool 通过如下两个静态方法提供通用池功能。
-
ForkJoinPool commonPool():该方法返回一个通用池。
通用池的运行状态不会受 shutdown() 或 shutdownNow() 方法的影响。当然,如果程序直接执行 System.exit(0) ;来终止虚拟机,通用池以及通用池中正在执行的任务都会被自动终止。
-
int getCommonPoolParallelism():该方法返回通用池的并行级别。
创建了 ForkJoinPool 实例之后,就可调用 ForkJoinPool 的 submit(ForkJoin Task task) 或 invoke(ForkJoinTask task) 方法来执行指定任务了。
其中 ForkJoinTask 代表一个可以并行、合并的任务。
ForkJoinTask 是一个抽象类,它还有两个抽象子类: RecursiveAction 和 Recursive Task 。
其中 Recursive Task 代表有返回值的任务,而 RecursiveAction 代表没有返回值的任务。
下面以执行没有返回值的“大任务”(简单地打印0-300的数值)为例,程序将一个“大任务”拆分成多个“小任务”,并将任务交给 ForkJoinPool 来执行。
// 继承RecursiveAction来实现"可分解"的任务
class PrintTask extends RecursiveAction
{
// 每个“小任务”只最多只打印50个数
private static final int THRESHOLD = 50;
private int start;
private int end;
// 打印从start到end的任务
public PrintTask(int start, int end)
{
this.start = start;
this.end = end;
}
@Override
protected void compute()
{
// 当end与start之间的差小于THRESHOLD时,开始打印
if(end - start < THRESHOLD)
{
for (int i = start ; i < end ; i++ )
{
System.out.println(Thread.currentThread().getName() + "的i值:" + i);
}
}
else
{
// 如果当end与start之间的差大于THRESHOLD时,即要打印的数超过50个
// 将大任务分解成两个小任务。
int middle = (start + end) / 2;
PrintTask left = new PrintTask(start, middle);
PrintTask right = new PrintTask(middle, end);
// 并行执行两个“小任务”
left.fork();
right.fork();
}
}
}
/**
* description: 主函数
**/
public class ForkJoinPoolTest
{
public static void main(String[] args)
throws Exception
{
ForkJoinPool pool = new ForkJoinPool();
// 提交可分解的PrintTask任务
pool.submit(new PrintTask(0 , 300));
pool.awaitTermination(2, TimeUnit.SECONDS);
// 关闭线程池
pool.shutdown();
}
}
复制代码
上面定义的任务是一个没有返回值的打印任务,如果大任务是有返回值的任务,则可以让任务继承 Recursive Task<T> ,其中泛型参数T就代表了该任务的返回值类型。下面程序示范了使用 Recursive Task 对一个长度为100的数组的元素值进行累加。
// 继承RecursiveTask来实现"可分解"的任务
class CalTask extends RecursiveTask<Integer>
{
// 每个“小任务”只最多只累加20个数
private static final int THRESHOLD = 20;
private int arr[];
private int start;
private int end;
// 累加从start到end的数组元素
public CalTask(int[] arr , int start, int end)
{
this.arr = arr;
this.start = start;
this.end = end;
}
@Override
protected Integer compute()
{
int sum = 0;
// 当end与start之间的差小于THRESHOLD时,开始进行实际累加
if(end - start < THRESHOLD)
{
for (int i = start ; i < end ; i++ )
{
sum += arr[i];
}
return sum;
}
else
{
// 如果当end与start之间的差大于THRESHOLD时,即要累加的数超过20个时
// 将大任务分解成两个小任务。
int middle = (start + end) / 2;
CalTask left = new CalTask(arr , start, middle);
CalTask right = new CalTask(arr , middle, end);
// 并行执行两个“小任务”
left.fork();
right.fork();
// 把两个“小任务”累加的结果合并起来
return left.join() + right.join(); // ①
}
}
}
/**
* description: 主函数
**/
public class Sum
{
public static void main(String[] args)
throws Exception
{
int[] arr = new int[100];
Random rand = new Random();
int total = 0;
// 初始化100个数字元素
for (int i = 0 , len = arr.length; i < len ; i++ )
{
int tmp = rand.nextInt(20);
// 对数组元素赋值,并将数组元素的值添加到sum总和中。
total += (arr[i] = tmp);
}
System.out.println(total);
// 创建一个通用池
ForkJoinPool pool = ForkJoinPool.commonPool();
// 提交可分解的CalTask任务
Future<Integer> future = pool.submit(new CalTask(arr , 0 , arr.length));
System.out.println(future.get());
// 关闭线程池
pool.shutdown();
}
}
复制代码
线程相关的类
ThreadLocal类
ThreadLocal,是Thread Local Variable(线程局部变量)的意思,它就是为每一个使用该变量的线程都提供一个变量值的副本,使每一个线程都可以独立地改变自己的副本,而不会和其他线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有该变量一样。
它只提供了如下三个public方法。
-
T get():返回此线程局部变量中当前线程副本中的值。 -
void remove():删除此线程局部变量中当前线程的值。 -
void set(T value):设置此线程局部变量中当前线程副本中的值。
代码示例:
/**
* description: 账户类
**/
class Account
{
/* 定义一个ThreadLocal类型的变量,该变量将是一个线程局部变量
每个线程都会保留该变量的一个副本 */
private ThreadLocal<String> name = new ThreadLocal<>();
// 定义一个初始化name成员变量的构造器
public Account(String str)
{
this.name.set(str);
// 下面代码用于访问当前线程的name副本的值
System.out.println("---" + this.name.get());
}
// name的setter和getter方法
public String getName()
{
return name.get();
}
public void setName(String str)
{
this.name.set(str);
}
}
/**
* description: 线程类
**/
class MyTest extends Thread
{
// 定义一个Account类型的成员变量
private Account account;
public MyTest(Account account, String name)
{
super(name);
this.account = account;
}
public void run()
{
// 循环10次
for (int i = 0 ; i < 10 ; i++)
{
// 当i == 6时输出将账户名替换成当前线程名
if (i == 6)
{
account.setName(getName());
}
// 输出同一个账户的账户名和循环变量
System.out.println(account.getName() + " 账户的i值:" + i);
}
}
}
/**
* description: 主程序
**/
public class ThreadLocalTest
{
public static void main(String[] args)
{
// 启动两条线程,两条线程共享同一个Account
Account at = new Account("初始名");
/*
虽然两条线程共享同一个账户,即只有一个账户名
但由于账户名是ThreadLocal类型的,所以每条线程
都完全拥有各自的账户名副本,所以从i == 6之后,将看到两条
线程访问同一个账户时看到不同的账户名。
*/
new MyTest(at , "线程甲").start();
new MyTest(at , "线程乙").start ();
}
}
复制代码
程序结果如图:

线程局部变量互不干扰的情形
分析:
上面 Account 类中的三行粗体字代码分别完成了创建 ThreadLocal 对象、从 ThreadLocal 中取出线程局部变量、修改线程局部变量的操作。
由于程序中的账户名是一个 ThreadLocal 变量,所以虽然程序中只有一个 Account 对象,但两个子线程将会产生两个账户名(主线程也持有一个账户名的副本)。
两个线程进行循环时都会在 i=6 时将账户名改为与线程名相同,这样就可以看到两个线程拥有两个账户名的情形,如图所示。
从上面程序可以看出,实际上账户名有三个副本,主线程一个,另外启动的两个线程各一个,它们的值互不干扰,每个线程完全拥有自己的 ThreadLocal 变量,这就是 ThreadLocal 的用途。
ThreadLocal 和其他所有的同步机制一样,都是为了解决多线程中对同一变量的访问冲突。
在普通的同步机制中,是通过对象加锁来实现多个线程对同一变量的安全访问的。 该变量是多个线程共享的 ,所以要使用这种同步机制,需要很细致地分析在什么时候对变量进行读写,什么时候需要锁定某个对象,什么时候释放该对象的锁等。在这种情况下,系统并没有将这份资源复制多份,只是采用了安全机制来控制对这份资源的访问而已。
ThreadLocal 从另一个角度来解决多线程的并发访问, ThreadLocal 将需要并发访问的资源复制多份,每个线程拥有一份资源,每个线程都拥有自己的资源副本,从而也就没有必要对该变量进行同步了。
ThreadLocal 提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的整个变量封装进 ThreadLocal ,或者把该对象与线程相关的状态使用 ThreadLocal 保存。
ThreadLocal 并不能替代同步机制,两者面向的问题领域不同。同步机制是为了同步多个线程对相同资源的并发访问,是多个线程之间进行通信的有效方式;
而 ThreadLocal 是为了隔离多个线程的数据共享,从根本上避免多个线程之间对共享资源(变量)的竞争,也就不需要对多个线程进行同步了。
通常建议:
如果多个线程之间需要共享资源,以达到线程之间的通信功能,就使用同步机制;如果仅仅需要隔离多个线程之间的共享冲突,则可以使用 ThreadLocal 。
包装线程不安全的集合
像 ArrayList 、 LinkedList 、 HashSet 、 TreeSet 、 HashMap 、 TreeMap 等都是线程不安全的,也就是说,当多个并发线程向这些集合中存、取元素时,就可能会破坏这些集合的数据完整性。
如果程序中有多个线程可能访问以上这些集合,就可以使用 Collections 提供的类方法把这些集合包装成线程安全的集合。 Collections 提供了如下几个静态方法。
-
<T>Collection<T>synchronizedCollection(Collection<T>c):返回指定collection对应的线程安全的collection。 -
static<T>List<T>synchronizedList(List<T>list):返回指定List对象对应的线程安全的List对象。 -
static<K,V>Map<K,V> synchronizedMap(Map<K,V>m):返回指定Map对象对应的线程安全的Map对象。 -
static<T>Set<T>synchronizedSet(Set<T>s):返回指定Set对象对应的线程安全的Set对象。 -
static<K,V>SortedMap<K,V>synchronizedSortedMap(SortedMap<K,V>m):返回指定SortedMap对象对应的线程安全的SortedMap对象。 -
static<T>SortedSet-T>synchronizedSortedSet(SortedSet<T>s):返回指定SortedSet对象对应的线程安全的SortedSet对象。
例如需要在多线程中使用线程安全的HashMap对象,则可以采用如下代码:
//使用Collections的synchronizedMap方法将一个普通的HashMap包装成线程安全的类 HashMap m=Collections.synchronizedMap(new HashMap()); 复制代码
tips:
如果需要把某个集合包装成线程安全的集合,则应该在创建之后立即包装,如上程序所示,当 HashMap 对象创建后立即被包装成线程安全的 HashMap 对象。
线程安全的集合类
线程安全的集合类可分为如下两类:
-
以
Concurrent开头的集合类,如ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkip ListSet、ConcurrentLinkedQueue和ConcurrentLinkedDeque -
以
CopyOnWrite开头的集合类,如CopyOnWriteArrayList、CopyOnWriteArraySet
其中以 Concurrent 开头的集合类代表了支持并发访问的集合,它们可以支持多个线程并发写入访问,这些写入线程的所有操作都是线程安全的,但读取操作不必锁定。
以 Concurrent 开头的集合类采用了更复杂的算法来保证永远不会锁住整个集合,因此在并发写入时有较好的性能。
在默认情况下, ConcurrentHashMap 支持16个线程并发写入,当有超过16个线程并发向该 Map 中写入数据时,可能有一些线程需要等待。实际上,程序通过设置 concurrencyLevel 构造参数(默认值为16)来支持更多的并发写入线程。
与前面介绍的 HashMap 和普通集合不同的是,因为 ConcurrentLinkedQueue 和 ConcurrentHashMap 支持多线程并发访问,所以当使用迭代器来遍历集合元素时,该迭代器可能不能反映出创建迭代器之后所做的修改,但程序不会抛出任何异常。
Java8扩展了 ConcurrentHashMap 的功能,Java8为该类新增了30多个新方法,这些方法可借助于 Stream 和 Lambda 表达式支持执行聚集操作。 ConcurrentHashMap 新增的方法大致可分为如下三类:
-
forEach系列(forEach,forEachKey,forEach Value,forEachEntry) -
search系列(search,searchKeys,search Values,searchEntries) -
reduce系列(reduce,reduce ToDouble,reduce ToLong,reduceKeys,reduceValues)
除此之外, ConcurrentHashMap 还新增了 mappingCount() 、 newKeySet() 等方法,增强后的 ConcurrentHashMap 更适合作为缓存实现类使用。
CopyOnWriteAtraySet
由于 CopyOnWriteAtraySet 的底层封装了 CopyOnWriteArmayList ,因此它的实现机制完全类似于 CopyOnWriteArrayList 集合。
对于 CopyOnWriteArrayList 集合,,它采用复制底层数组的方式来实现写操作。
当线程对 CopyOnWriteArrayList 集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。
当线程对 CopyOnWriteArrayList 集合执行写入操作时(包括调用 add()、 remove() 、 set()`等方法)该集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。
由于对 CopyOnWriteArmayList 集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。
需要指出的是,由于 CopyOnWriteArrayList 执行写入操作时需要频繁地复制数组,性能比较差。
但由于读操作与写操作不是操作同一个数组,而且读操作也不需要加锁,因此读操作就很快、很安全。由此可见, CopyOnWriteArayList 适合用在读取操作远远大于写入操作的场景中,例如缓存等。
正文到此结束
- 本文标签: 垃圾回收 ConcurrentHashMap 缓存 ip cat 多线程 Collections 锁 http 处理器 Collection HashMap 连接池 mina 进程 管理 实例 开发 ask queue IO 集合类 synchronized 测试 线程 IDE DOM 操作系统 DDL producer 线程通信 静态方法 rand java 数据库 数据 遍历 返回值类型 core 线程池 executor 线程同步 JVM HashSet spring description 开发者 App 参数 src 调度器 cache Thread pool equals 并发 rmi tar UI 空间 list 同步 ACE ORM id ArrayList stream map 时间 value consumer 生命 Service 希望 LinkedList lambda https 安全 代码 key final 删除 Action
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

