Java多线程之Executor框架和手写简易的线程池
线程池
什么是线程池
线程池一种线程使用模式,线程池会维护多个线程,等待着分配可并发执行的任务,当有任务需要线程执行时,从线程池中分配线程给该任务而不用主动的创建线程。
线程池的好处
如果在我们平时如果需要用到线程时,我们一般是这样做的:创建线程(T1),使用创建的线程来执行任务(T2),任务执行完成后销毁当前线程(T3),这三个阶段是必须要有的。
而如果使用线程池呢?
线程池会预先创建好一定数量的线程,需要的时候申请使用,在一个任务执行完后也不需要将该线程销毁,很明显的节省了T1和T3这两阶段的时间。
同时我们的线程由线程池来统一进行管理,这样也提高了线程的可管理性。
手写一个自己的线程池
现在我们可以简单的理解为线程池实际上就是存放多个线程的数组,在程序启动是预先实例化一定得线程实例,当有任务需要时分配出去。现在我们先来写一个自己的线程池来理解一下线程池基本的工作过程。
线程池需要些什么?
首先线程池肯定需要一定数量的线程,所以首先需要一个线程数组,当然也可以是一个集合。
线程数组是用来进行存放线程实例的,要使用这些线程就需要有任务提交过来。当任务量过大时,我们是不可能在同一时刻给所有的任务分配一个线程的,所以我们还需要一个用于存放任务的容器。
这里的预先初始化线程实例的数量也需要我们来根据业务确定。
同时线程实例的数量也不能随意的定义,所以我们还需要设置一个最大线程数。
//线程池中允许的最大线程数
private static int MAXTHREDNUM = Integer.MAX_VALUE;
//当用户没有指定时默认的线程数
private int threadNum = 6;
//线程队列,存放线程任务
private List<Runnable> queue;
private WorkerThread[] workerThreads;
线程池工作
线程池的线程一般需要预先进行实例化,这里我们通过构造函数来模拟这个过程。
public MyThreadPool(int threadNum) {
this.threadNum = threadNum;
if(threadNum > MAXTHREDNUM)
threadNum = MAXTHREDNUM;
this.queue = new LinkedList<>();
this.workerThreads = new WorkerThread[threadNum];
init();
}
//初始化线程池中的线程
private void init(){
for(int i=0;i<threadNum;i++){
workerThreads[i] = new WorkerThread();
workerThreads[i].start();
}
}
在线程池准备好了后,我们需要像线程池中提交工作任务,任务统一提交到队列中,当有任务时,自动分发线程。
//提交任务
public void execute(Runnable task){
synchronized (queue){
queue.add(task);
//提交任务后唤醒等待在队列的线程
queue.notifyAll();
}
}
我们的工作线程为了获取任务,需要一直监听任务队列,当队列中有任务时就由一个线程去执行,这里我们用到了前面提到的安全中断。
private class WorkerThread extends Thread {
private volatile boolean on = true;
@Override
public void run() {
Runnable task = null;
//判断是否可以取任务
try {
while(on&&!isInterrupted()){
synchronized (queue){
while (on && !isInterrupted() && queue.isEmpty()) {
//这里如果使用阻塞队列来获取在执行时就不会报错
//报错是因为退出时销毁了所有的线程资源,不影响使用
queue.wait(1000);
}
if (on && !isInterrupted() && !queue.isEmpty()) {
task = queue.remove(0);
}
if(task !=null){
//取到任务后执行
task.run();
}
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
task = null;//任务结束后手动置空,加速回收
}
public void cancel(){
on = false;
interrupt();
}
}
当然退出时还需要对线程池中的线程等进行销毁。
//销毁线程池
public void shutdown(){
for(int i=0;i<threadNum;i++){
workerThreads[i].cancel();
workerThreads[i] = null;
}
queue.clear();
}
好了,到这里我们的一个简易版的线程池就完成了,功能虽然不多但是线程池运行的基本原理差不多实现了,实际上非常简单,我们来写个程序测试一下:
public class ThreadPoolTest {
public static void main(String[] args) throws InterruptedException {
// 创建3个线程的线程池
MyThreadPool t = new MyThreadPool(3);
CountDownLatch countDownLatch = new CountDownLatch(5);
t.execute(new MyTask(countDownLatch, "testA"));
t.execute(new MyTask(countDownLatch, "testB"));
t.execute(new MyTask(countDownLatch, "testC"));
t.execute(new MyTask(countDownLatch, "testD"));
t.execute(new MyTask(countDownLatch, "testE"));
countDownLatch.await();
Thread.sleep(500);
t.shutdown();// 所有线程都执行完成才destory
System.out.println("finished...");
}
// 任务类
static class MyTask implements Runnable {
private CountDownLatch countDownLatch;
private String name;
private Random r = new Random();
public MyTask(CountDownLatch countDownLatch, String name) {
this.countDownLatch = countDownLatch;
this.name = name;
}
public String getName() {
return name;
}
@Override
public void run() {// 执行任务
try {
countDownLatch.countDown();
Thread.sleep(r.nextInt(1000));
System.out.println("任务 " + name + " 完成");
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getId()+" sleep InterruptedException:"
+Thread.currentThread().isInterrupted());
}
}
}
}
result:
任务 testA 完成
任务 testB 完成
任务 testC 完成
任务 testD 完成
任务 testE 完成
finished...
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at com.learn.threadpool.MyThreadPool$WorkerThread.run(MyThreadPool.java:75)
...
从结果可以看到我们提交的任务都被执行了,当所有任务执行完成后,我们强制销毁了所有线程,所以会抛出异常。
JDK中的线程池
上面我们实现了一个简易的线程池,稍微理解线程池的基本运作原理。现在我们来认识一些JDK中提供了线程池吧。
ThreadPoolExecutor
public class ThreadPoolExecutor extends AbstractExecutorService
ThreadPoolExecutor是一个ExecutorService ,使用可能的几个合并的线程执行每个提交的任务,通常使用Executors工厂方法配置,通过Executors可以配置多种适合不同场景的线程池。
ThreadPoolExecutor中的主要参数
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)
corePoolSize
线程池中的核心线程数,当外部提交一个任务时,线程池就创建一个新线程执行任务,直到当前线程数等于corePoolSize时不再创建新线程;
如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;
如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
maximumPoolSize
线程池中允许的最大线程数。如果当前阻塞队列已满,还在继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize。
keepAliveTime
线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间。默认情况下,线程一般不会被销毁,该参数只在线程数大于corePoolSize时才有用。
workQueue
workQueue必须是阻塞队列。当线程池中的线程数超过corePoolSize的时候,线程会进入阻塞队列进行等待。阻塞队列可以使有界的也可以是无界的。
threadFactory
创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个线程名。Executors静态工厂里默认的threadFactory,线程的命名规则是“pool-{数字}-thread-{数字}”。
RejectedExecutionHandler
线程池的饱和处理策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
•AbortPolicy:直接抛出异常,默认的处理策略
•CallerRunsPolicy:使用调用者所属的线程来执行当前任务
•DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务
•DiscardPolicy:直接丢弃该任务
如果上述提供的处理策略无法满足业务需求,也可以根据场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
ThreadPoolExecutor中的主要执行流程
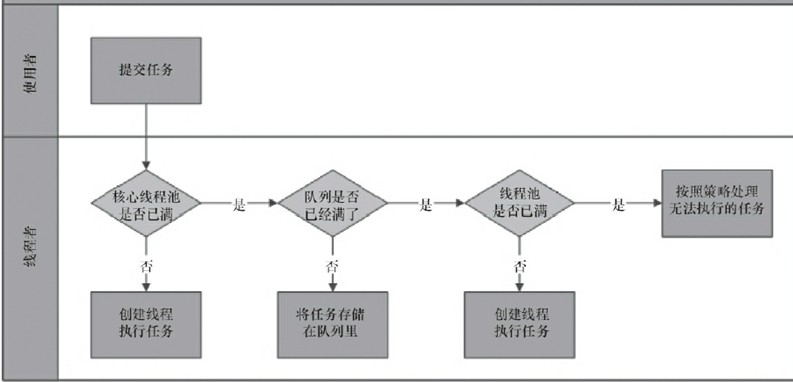
//图片来自网络
1.线程池判断核心线程池里的线程(corePoolSize)是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入2。
2.线程池判断工作队列(workQueue)是否已满。如果工作队列没有满,则将新提交的任务存储在该队列里。如果工作队列满了,则进入3。
3.线程池判断线程池的线程(maximumPoolSize)是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
这里需要注意的是核心线程池大小指得是corePoolSize参数,而线程池工作线程数指的是maximumPoolSize。
Executor
实际上我们在使用线程池时,并不一定需要自己来定义上面介绍的参数的值,JDK为我们提供了一个调度框架。通过这个调度框架我们可以轻松的创建好线程池以及异步的获取任务的执行结果。
调度框架的组成
任务
一般是指需要被执行的任务,多为使用者提供。被提交的任务需要实现Runnable接口或Callable接口。
任务的执行
Executor是任务执行机制的核心接口,其将任务的提交和执行分离开来。ExecutorService继承了Executor并做了一些扩展,可以产生Future为跟踪一个或多个异步任务执行。任务的执行主要是通过实现了Executor和ExecutorService接口的类来进行实现。例如:ThreadPoolExecutor和ScheduledThreadPoolExecutor。
结果获取
对结果的获取可以通过Future接口以及其子类接口来实现。Future接口提供了一系列诸如检查是否就绪,是否执行完成,阻塞以及获取结果等方法。
Executors工厂中的线程池
FixedThreadPool
new ThreadPoolExecutor(nThreads, nThreads, 0L,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
该线程池中corePoolSize和maximumPoolSize参数一致。同时使用无界阻塞队列,将会导致maximumPoolSize和keepAliveTime已经饱和策略无效,因为队列会一直接收任务,直到OOM。
SingleThreadExecutor
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>())
该线程池中corePoolSize和maximumPoolSize都为1,表示始终只有一个线程在工作,适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。同时使用无界阻塞队列,当任务多时极有可能OOM。
CachedThreadPool
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>()
CachedThreadPool类型的线程池corePoolSize为0,表示任务将会提交给队列,但是SynchronousQueue又是一个不包含任何容量的队列。所以每一个任务提交过来都会创建一个新的线程来执行,该类型的线程池适用于执行很多的短期异步任务的程序,或者是负载较轻的服务器。如果当任务的提交速度一旦超过任务的执行速度,在极端情况下可能会因为创建过多线程而耗尽CPU和内存资源。
ScheduledThreadPool
对于定时任务类型的线程池,Executor可以创建两种不同类型的线程池:ScheduledThreadPoolExecutor和SingleThreadScheduledExecutor,前者是包含若干个线程的ScheduledThreadPoolExecutor,后者是只包含一个的ScheduledThreadPoolExecutor。
ScheduledThreadPoolExecutor适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景。
SingleThreadScheduledExecutor适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场景。
new ThreadPoolExecutor(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue());
在对该类型线程池进行实例化时,我们可以看到maximumPoolSize设置为了Integer的最大值,所以很明显在极端情况下和CachedThreadPool类型一样可能会因为创建过多线程而耗尽CPU和内存资源。
DelayedWorkQueue是一种延时阻塞队列,此队列的特点为其中元素只能在其延迟到期时才被使用。ScheduledThreadPool类型在执行任务时和其他线程池有些不同。
1.ScheduledThreadPool类型线程池中的线程(假设现在线程A开始取任务)从DelayedWorkQueue中取已经到期的任务。
2.线程A获取到任务后开始执行。
3.任务执行完成后设置该任务下一次执行的时间。
4.将该任务重新放入到线程池中。
ScheduledThreadPool中存在着定时任务和延时任务两种。
延时任务通过schedule(...)方法以及重载方法和scheduleWithFixedDelay实现,延时任务通过设置某个时间间隔后执行,schedule(...)仅执行一次。
定时任务由scheduleAtFixedRate实现。该方法创建并执行在给定的初始延迟之后,随后以给定的时间段进行周期性动作,即固定时间间隔的任务。
特殊的scheduleWithFixedDelay方法是创建并执行在给定的初始延迟之后首先启用的定期动作,随后在一个执行的终止和下一个执行的开始之间给定的延迟,即固定延时间隔的任务。
固定时间间隔的任务不论每次任务花费多少时间,下次任务开始执行时间是确定的。对于scheduleAtFixedRate方法中,若任务处理时长超出设置的定时频率时长,本次任务执行完才开始下次任务,下次任务已经处于超时状态,会马上开始执行。若任务处理时长小于定时频率时长,任务执行完后,定时器等待,下次任务会在定时器等待频率时长后执行。
固定延时间隔的任务是指每次执行完任务以后都等待一个固定的时间。由于操作系统调度以及每次任务执行的语句可能不同,所以每次任务执行所花费的时间是不确定的,也就导致了每次任务的执行周期存在一定的波动。
需要注意的是定时或延时任务中所涉及到时间、周期不能保证实时性及准确性,实际运行中会有一定的误差。
Callable/Future
在介绍实现多线程的时候我们有简单介绍过Runnable和Callable的,这两者基本相同,不同在于Callable可以返回一个结果,而Runnable不返回结果。对于Callable接口的使用方法和Runnable基本相同,同时我们也可以选择是否对结果进行接收处理。在Executors中提供了将Runnable转换为Callable的api:Callable<Object> callable(Runnable task)。
Future是一个用于接收Runnable和Callable计算结果的接口,当然它还提供了查询任务状态,中断或者阻塞任务以及查询结果的能力。
boolean cancel(boolean mayInterruptIfRunning) //尝试取消执行此任务。
V get() //等待计算完成,然后检索其结果。
V get(long timeout, TimeUnit unit) //等待最多在给定的时间,然后检索其结果(如果可用)。
boolean isCancelled() //如果此任务在正常完成之前被取消,则返回 true 。
boolean isDone() //如果任务已完成返回true。
FutureTask是对Future的基本实现,具有启动和取消计算的方法,查询计算是否完整,并检索计算结果。FutureTask对Future做了一定得扩展:
void run() //将此future设置为其计算结果,除非已被取消。
protected boolean runAndReset() //执行计算而不设置其结果,然后重置为初始状态,如果计算遇到异常或被取消,则不执行此操作。
protected void set(V v) //将此Future的结果设置为给定值,除非Future已被设置或已被取消。
protected void setException(Throwable t) //除非已经设置了此 Future 或已将其取消,否则它将报告一个 ExecutionException,并将给定的 throwable 作为其原因。
FutureTask除了实现Future接口外,还实现了Runnable接口。所以FutureTask可以由Executor执行,也可以由调用线程直接执行futureTask.run()。
当FutureTask处于未启动或已启动状态时,执行FutureTask.get()方法将导致调用线程阻塞;
当FutureTask处于已完成状态时,执行FutureTask.get()方法将导致调用线程立即返回结果或抛出异常。
当FutureTask处于未启动状态时,执行FutureTask.cancel()方法将导致此任务永远不会被执行;
当FutureTask处于已启动状态时,执行FutureTask.cancel(true)方法将以中断执行此任务线程的方式来尝试停止该任务;
当FutureTask处于已启动状态时,执行FutureTask.cancel(false)方法将不会对正在执行此任务的线程产生影响(让正在执行的任务运行完成)。
关于是否使用Executors
在之前阿里巴巴出的java开发手册中,有明确提出禁止使用Executors:
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,
这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
在上面我们分析过使用Executors创建的几种线程池的使用场景和缺点,大多数情况下出问题在于可能导致OOM,在我实际使用中基本没有遇到过这样的情况。但是考虑到阿里巴巴这样体量的并发请求,可能遇到这种情况的几率较大。所以我们还是应该根据实际情况考虑是否使用,当然实际遵循阿里巴巴开发手册来可能会更好一点,毕竟这是国类顶尖公司常年在生产中积累下的经验。
最后,在本节中只是简单介绍线程池及其基本原理,帮助更好的理解线程池。并不涉及具体如何使用。
Linux公社的RSS地址 : https://www.linuxidc.com/rssFeed.aspx
本文永久更新链接地址: https://www.linuxidc.com/Linux/2019-04/158281.htm
正文到此结束
- 本文标签: CTO 开发 线程池 LinkedList db 配置 时间 操作系统 ACE id 测试 安全 需求 参数 http IO 服务器 阿里巴巴 多线程 REST ask 图片 2019 java cat API list core executor rand linux 线程 管理 value src cache 并发 tar 实例 ThreadPoolExecutor Service CountDownLatch IDE DOM volatile queue synchronized https UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

