从源码角度认知ArrayList,LinkedList和HashMap
本文会从源码(JDK 1.8)的角度来分析以下几个Java中常用的数据结构,主要会分析原理与实现,以及每个数据结构所支持的常用操作的复杂度。
- ArrayList
- LinkedList
- HashMap
1.存储结构对比:
ArrayList是通过一串Object数组来存储数据。所有操作都是通过数组索引来进行。 LinkedList是通过双向链表结构来存储数据,对数据的操作都是通过索引进行。 HashMap<K, V>是基于哈希表这个数据结构的Map接口具体实现,允许null键和null值(最多只允许一个key为null,但允许多个value为null)。这个类与HashTable近似等价,区别在于HashMap不是线程安全的并且允许null键和null值。由于基于哈希表实现,所以HashMap内部的元素是无序的,类似于我们使用的“字典”。HashMap是采用数组+链表实现的,非线程安全。 复制代码
2.方法对比
ArrayList:
/** * Appends the specified element to the end of this list.
* * @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
复制代码
LinkedList:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/** * Inserts element e before non-null Node succ. */
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
根据源码可以看出,ArrayList的增删操作调用了System.arrayCopy,是将数组平移得到,这样处理内存消耗和速度都很大,而LinkedList是通过链表指针进行的增删操作,因此LinkedList的效率更高。
而对于查询方法,,ArrayList是通过下标直接获取返回,而LinkedList需要移动指针来查询,对于数据量大情况来说,ArrayList比较适合查询。
复制代码
HashMap的原理:
HashMap是基于拉链法处理碰撞的散列表的实现,一个存储整型元素的HashMap的内部存储结构如下图所示:
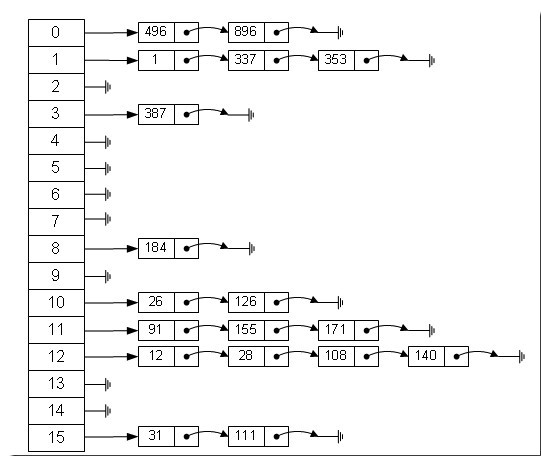
我们可以看到,HashMap是采用数组+链表实现的,在JDK 1.8中,对HashMap做了进一步优化,引入了红黑树。当链表的长度大于8时,就会使用红黑树来代替链表。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

