Spring Cloud 参考文档(Spring Cloud Sleuth介绍)
Spring Cloud Sleuth介绍
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案。
术语
Spring Cloud Sleuth借用了 Dapper 的术语。
Span:基本工作单元,例如,发送RPC是一个新的span,就像向RPC发送响应一样,Span由span的唯一64位ID标识,另一个64位ID标识其所属的Trace。Span还有其他数据,例如描述、带时间戳的事件、键值annotations(标签),导致它们的span的ID以及进程ID(通常是IP地址)。
span可以启动和停止,它们可以跟踪自己的时间信息,创建span后,必须在将来的某个时刻停止它。
启动Trace的初始span称为 root span ,该span的ID值等于trace ID。
Trace:一组span形成的树状结构,例如,如果运行分布式大数据存储,则可能由 PUT 请求形成trace。
Annotation:用于及时记录事件的存在,使用 Brave 工具,不再需要为 Zipkin 设置特殊的事件来了解客户端和服务器是谁、请求在哪里开始以及在哪里结束,然而,出于学习目的,标记这些事件以突出发生了什么类型的操作。
- cs :Client Sent,客户端发起了一个请求,这个annotation表示span的开始。
- sr :Server Received,服务器端获得了请求并开始处理它,从此时间戳中减去
cs时间戳会显示网络延迟。 - ss :Server Sent,在请求处理完成时注释(当响应被发送回客户端时),从此时间戳中减去
sr时间戳会显示服务器端处理请求所需的时间。 - cr :Client Received,表示span的结束,客户端已成功从服务器端收到响应,从此时间戳中减去
cs时间戳会显示客户端从服务器接收响应所需的全部时间。
下图显示了系统中的 Span 和 Trace ,以及Zipkin annotations:
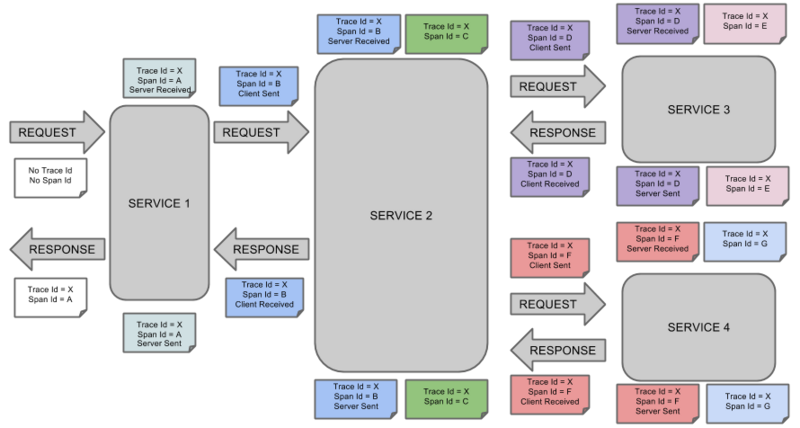
标记的每种颜色表示一个span(有七个span — 从 A 到 G ),请考虑以下标记:
Trace Id = X Span Id = D Client Sent
此标记表示当前span的 Trace Id 设置为 X , Span Id 设置为 D ,此外,还发生了 Client Sent 事件。
下图显示了span的父—子关系:
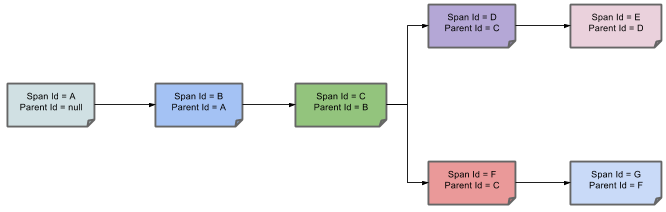
用途
以下部分参考上图中显示的示例。
使用Zipkin进行分布式跟踪
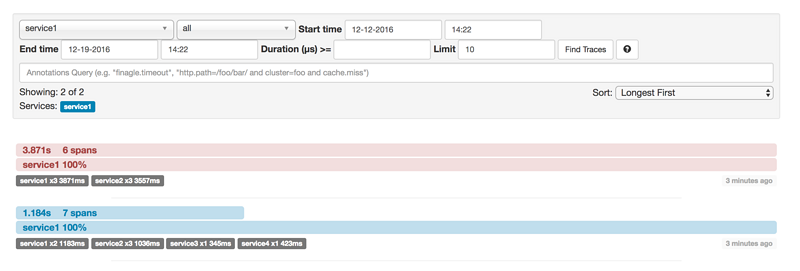
这个例子有七个span,如果你进入Zipkin中的trace,你可以在第二个trace中看到这个数字,如下图所示:
但是,如果选择特定trace,则可以看到四个span,如下图所示:
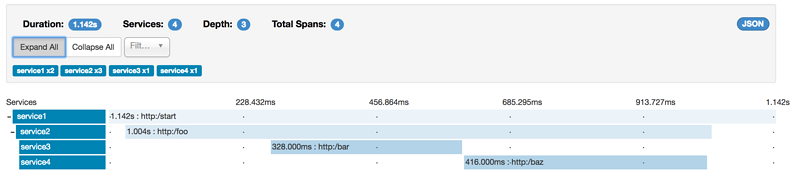
选择特定trace时,你会看到合并的span,这意味着,如果通过Server Received和Server Sent或Client Received和Client Sent annotations向Zipkin发送了两个span,则它们将显示为单个span。
在这种情况下,为什么七个和四个span之间存在差异?
- 一个span来自
http:/startspan,它具有Server Received(sr)和Server Sent(ss)annotations。 - 两个span来自从
service1到service2的http:/foo端点的RPC调用,Client Sent(cs)和Client Received(cr)事件发生在service1端,Server Received(sr)和Server Sent(ss)事件发生在service2端,这两个span形成一个与RPC调用相关的逻辑span。 - 两个span来自从
service2到service3的http:/bar端点的RPC调用,Client Sent(cs)和Client Received(cr)事件发生在service2端,Server Received(sr)和Server Sent(ss)事件发生在service3端,这两个span形成一个与RPC调用相关的逻辑span。 - 两个span来自从
service2到service4的http:/baz端点的RPC调用,Client Sent(cs)和Client Received(cr)事件发生在service2端,Server Received(sr)和Server Sent(ss)事件发生在service4端,这两个span形成一个与RPC调用相关的逻辑span。
因此,如果我们计算物理span,我们有一个来自 http:/start ,两个来自 service1 调用 service2 ,两个来自 service2 调用 service3 ,两个来自 service2 调用 service4 ,总之,我们总共有七个span。
从逻辑上讲,我们看到四个总Span的信息,因为我们有一个与传入请求到 service1 相关的span和三个与RPC调用相关的span。
可视化错误
Zipkin允许你可视化trace中的错误,当抛出异常而没有被捕获时,在span上设置了适当的标签,然后Zipkin可以正确地着色,你可以在trace列表中看到一条红色的trace,出现这种情况是因为抛出了异常。
如果单击该trace,则会看到类似的图片,如下所示:
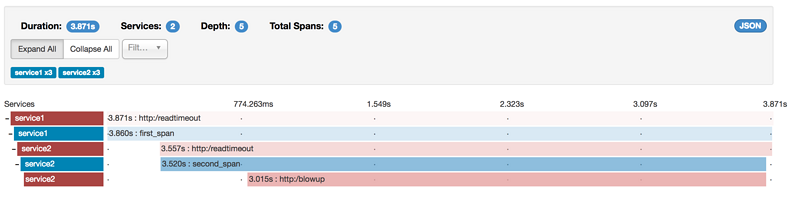
如果你随后单击其中一个span,则会看到以下内容:
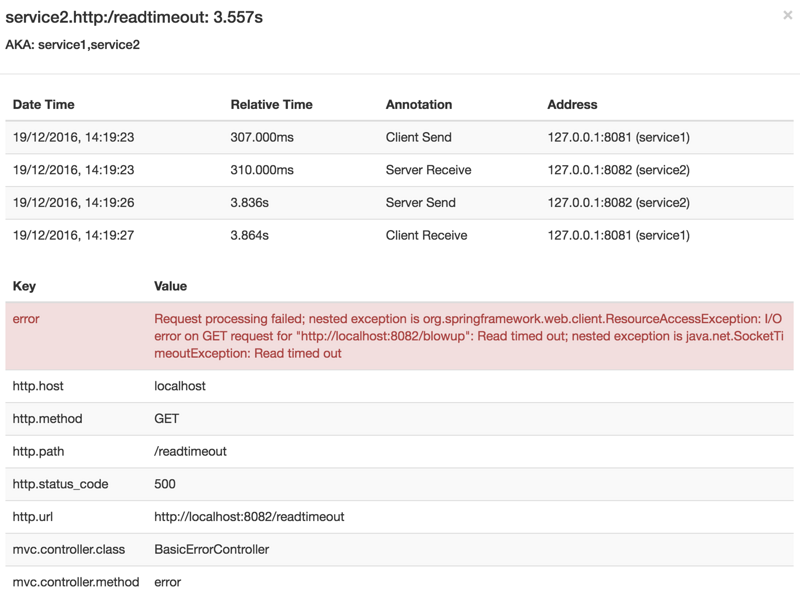
span显示错误的原因以及与之相关的整个堆栈跟踪。
Brave的分布式跟踪
从版本 2.0.0 开始,Spring Cloud Sleuth使用 Brave 作为跟踪库,因此,Sleuth不再负责存储上下文,而是将该工作委托给Brave。
由于Sleuth与Brave有不同的命名和标记约定,Spring决定从现在开始遵循Brave的约定,但是,如果要使用遗留的Sleuth方法,可以将 spring.sleuth.http.legacy.enabled 属性设置为 true 。
实例

点击这里查看实例!
Zipkin中的依赖关系图应类似于以下图像:

日志相关
当使用grep通过扫描等于(例如) 2485ec27856c56f4 的trace ID来读取这四个应用程序的日志时,你将获得类似于以下内容的输出:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2 service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4 service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3 service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3] service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4 service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4] service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
如果你使用日志聚合工具(例如 Kibana 、 Splunk 等),你可以排序发生的事件,Kibana的一个例子类似于下图:
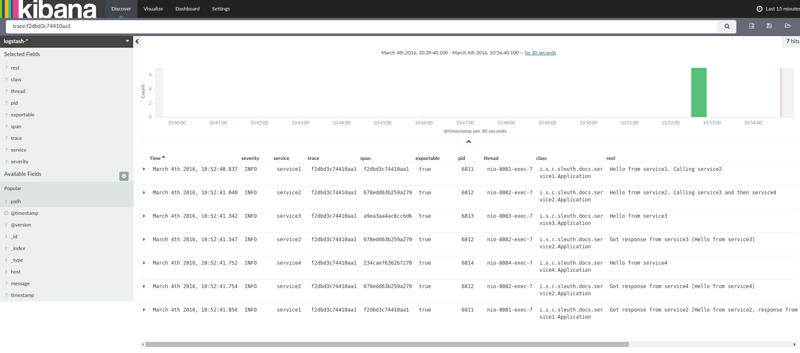
如果要使用Logstash,以下列表显示Logstash的Grok模式:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}/s+%{LOGLEVEL:severity}/s+/[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}/]/s+%{DATA:pid}/s+---/s+/[%{DATA:thread}/]/s+%{DATA:class}/s+:/s+%{GREEDYDATA:rest}" }
}
}
如果要将Grok与Cloud Foundry中的日志一起使用,则必须使用以下模式:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT/s+%{TIMESTAMP_ISO8601:timestamp}/s+%{LOGLEVEL:severity}/s+/[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}/]/s+%{DATA:pid}/s+---/s+/[%{DATA:thread}/]/s+%{DATA:class}/s+:/s+%{GREEDYDATA:rest}" }
}
}
JSON化Logback与Logstash一起使用
通常,你不希望将日志存储在文本文件中,而是存储在Logstash可以立即选择的JSON文件中,为此,你必须执行以下操作(为了便于阅读,在 groupId:artifactId:version notation中传递依赖项)。
依赖关系设置
ch.qos.logback:logback-core net.logstash.logback:logstash-logback-encoder:4.6
Logback设置
请考虑以下Logback配置文件示例(名为 logback-spring.xml )。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
那个Logback配置文件:
build/${spring.application.name}.json
如果使用自定义 logback-spring.xml ,则必须在 bootstrap 而不是 application 属性文件中传递 spring.application.name ,否则,你的自定义logback文件无法正确读取该属性。
传播span上下文
span上下文是必须传播到跨进程边界的任何子span的状态,span上下文的一部分是Baggage,trace和span ID是span上下文的必需部分,Baggage是可选部分。
Baggage是一组存储在span上下文中的键:值对,Baggage随着trace一起移动,并附在每一个span上,Spring Cloud Sleuth了解如果HTTP header以 baggage- 为前缀,则标题与行李相关,并且对于消息,它以 baggage_ 开头。
目前对baggage条目的数量或大小没有限制,但是,请记住,太多可能会降低系统吞吐量或增加RPC延迟,在极端情况下,由于超出传输级别的消息或header容量,过多的baggage可能会使应用程序崩溃。
以下示例显示了在span上设置baggage:
Span initialSpan = this.tracer.nextSpan().name("span").start();
ExtraFieldPropagation.set(initialSpan.context(), "foo", "bar");
ExtraFieldPropagation.set(initialSpan.context(), "UPPER_CASE", "someValue");
Baggage与Span标签
Baggage随trace而行(每个子span包含其父级的baggage),Zipkin不知道baggage,也不接收这些信息。
从Sleuth 2.0.0开始,你必须在项目配置中明确传递baggage键名称。
标签附加到特定span,换句话说,它们仅针对特定span呈现,但是,你可以按标记搜索以查找trace,假设存在具有搜索标记值的span。
如果你希望能够根据baggage查找span,则应在根span中添加相应的条目作为标记。
span必须在scope内。
以下清单显示了使用baggage的集成测试:
设置
spring.sleuth:
baggage-keys:
- baz
- bizarrecase
propagation-keys:
- foo
- upper_case
代码
initialSpan.tag("foo",
ExtraFieldPropagation.get(initialSpan.context(), "foo"));
initialSpan.tag("UPPER_CASE",
ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));
添加Sleuth到项目
本节介绍如何使用Maven或Gradle将Sleuth添加到项目中。
要确保你的应用程序名称在Zipkin中正确显示,请在 bootstrap.yml 中设置 spring.application.name 属性。
只有Sleuth(log相关)
如果你想在没有Zipkin集成的情况下仅使用Spring Cloud Sleuth,请将 spring-cloud-starter-sleuth 模块添加到你的项目中。
以下示例显示如何使用Maven添加Sleuth:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
spring-cloud-starter-sleuth
以下示例显示如何使用Gradle添加Sleuth:
Gradle
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}
spring-cloud-starter-sleuth
通过HTTP Sleuth与Zipkin一起使用
如果你想要Sleuth和Zipkin,请添加 spring-cloud-starter-zipkin 依赖项。
以下示例显示了如何为Maven执行此操作:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
以下示例显示了如何为Gradle执行此操作:
Gradle
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}
在RabbitMQ或Kafka上Sleuth与Zipkin一起使用
如果你想使用RabbitMQ或Kafka而不是HTTP,添加 spring-rabbit 或 spring-kafka 依赖项,默认目标名称是 zipkin 。
如果使用Kafka,则必须相应地设置属性 spring.zipkin.sender.type 属性:
spring.zipkin.sender.type: kafka
spring-cloud-sleuth-stream 已弃用且与这些目标不兼容。
如果你想在RabbitMQ上使用Sleuth,请添加 spring-cloud-starter-zipkin 和 spring-rabbit 依赖项。
以下示例显示了如何为Maven执行此操作:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
spring-cloud-starter-zipkin spring-rabbit
Gradle
dependencyManagement { 1
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin" 2
compile "org.springframework.amqp:spring-rabbit" 3
}
覆盖Zipkin的自动配置
Spring Cloud Sleuth从2.1.0版开始支持向多个跟踪系统发送trace,为了使其工作,每个跟踪系统都需要有一个 Reporter<Span> 和 Sender ,如果要覆盖提供的bean,则需要为它们指定一个特定的名称,为此,你可以分别使用 ZipkinAutoConfiguration.REPORTER_BEAN_NAME 和 ZipkinAutoConfiguration.SENDER_BEAN_NAME 。
@Configuration
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter() {
return AsyncReporter.create(mySender());
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}
额外的资源
你可以 点击这里 观看 Reshmi Krishna 和 Marcin Grzejszczak 关于Spring Cloud Sleuth和Zipkin的视频。
你可以在 openzipkin/sleuth-webmvc-example存储库 中检查Sleuth和Brave的不同设置。
正文到此结束
- 本文标签: 图片 rabbitmq stream root js UI App dependencies Word zipkin Agent web https 配置 注释 REST http ORM 分布式 Spring Cloud Sleuth zip ip 标题 时间 list core bean id Sleuth spring pom cat 代码 value src Service 希望 amqp maven 进程 大数据 key client Property MQ Spring cloud UTC tab grep Bootstrap XML build message IO bug tag 测试 tar IDE json example Logging NIO Kibana Logback 服务器 数据 实例 provider ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

