synchronized原理
前边的文章中已经介绍了 synchronized 的基本用法 ,我们也知道了 synchronized 使用锁,来保证被锁定了代码同一时间只能有一个线程执行;那么 synchronized 关键字的实现原理是怎样的呢?
在《深入理解Java虚拟机》一书中,介绍了 HotSpot 虚拟机中,对象的内存布局分为三个区域:对象头(Header)、实例数据(Instance Data)和对齐数据(Padding)。而对象头又分为两个部分“Mark Word”和类型指针,其中“Mark Word”包含了线程持有的锁。
因此, synchronized 锁,也是保存在对象头中。JVM基于进入和退出 Monitor 对象来实现 synchronized 方法和代码块的同步,对于方法和代码块的实现细节又有不同:
-
代码块,使用
monitorenter和monitorexit指令来实现;monitorenter指令编译后,插入到同步代码块开始的位置,monitorexit指令插入到方法同步代码块结束位置和异常处,JVM保证每个monitorenter必须有一个monitorexit指令与之对应。线程执行到monitorenter指令处时,会尝试获取对象对应的Monitor对象的所有权 (任何一个对象都有一个Monitor对象预制对应,当一个Monitor被持有后,它将处于锁定状态) 。 -
方法:在《深入理解Java虚拟机》同步指令一节中,关于方法级的同步描述如下:
方法级的同步是隐式的,即无需通过字节码指令来控制,它实现在方法调用和返回操作之中。JVM可以从方法常量池中的方法表结构(method_info Structure) 中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法。当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有管程,然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放管程。在方法执行期间,执行线程获取了管程,其他线程就无法获取管程。
2. Java对象头
上边的介绍中,我们知道 synchronized 锁存在在Java对象的对象头中,那么,什么是Java的对象头呢?
HotSpot虚拟机中,对象在内存中存储的布局可以分为3个部分:对象头,实例数据和对齐填充。其中,实例数据部分是对象真正存储的有效信息,对齐填充并不是必然存在,虚拟机要求对象起始地址必须是8字节的整数倍,如果对象实例数据部分没有达到8字节的整数倍,需要对齐填充区来补全。
对象头包含两部分信息:Mark Word和类型指针。虚拟机通过类型指针确定这个对象是哪个类的实例。
Mark Word中主要包含了:哈希码(HashCode)、GC分代年龄、锁状态标识、线程持有的锁、偏向线程ID、偏向时间戳等,这些信息在32位和64位虚拟机中,分别占32bit和64bit。如果对象是数组类型,则需要多一个字宽存储数组的长度。32位JVM的Mark Word默认存储结构如下表所示:
| 锁状态 | 25bit | 4bit | 1bit是否偏向锁 | 2bit锁标志位 |
|---|---|---|---|---|
| 无锁状态 | 对象的 hashCode | 对象分代年龄 | 0 | 01 |
Mark Word中存储的数据会随着锁标志位的变化而变化:
| 锁状态 | 25bit | 4bit | 1bit | 2bit | |
|---|---|---|---|---|---|
| 23bit | 2bit | 是否是偏向锁 | 锁标志位 | ||
| 轻量级锁 | 指向栈中锁记录的指针 | 00 | |||
| 重量级锁 | 指向互斥量(重量级锁)记录的指针 | 10 | |||
| GC 标记 | 空 | 11 | |||
| 偏向锁 | 线程ID | Epoch | 对象分代年龄 | 1 | 01 |
64为虚拟机中,Mark Work存储结构如下表所示:
| 锁状态 | 25bit | 31bit | 1bit(cms_free) | 4bit 分代年龄 | 1bit 偏向锁 | 2bit 锁标志位 |
|---|---|---|---|---|---|---|
| 无锁 | unused | hashCode | 0 | 01 | ||
| 偏向锁 | ThreadID(54bit) Epoch(2bit) | 1 | 01 | |||
- 以上表格内容摘自《Java并发编程艺术》——方腾飞
3. 锁优化
上边介绍了 synchronized 锁,主要通过获取Monitor来获取锁,而获取和释放Monitor的成本会非常高,因为,线程之间需要进行用户态到内核态的切换。JDK 1.6为了减少获取锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,JDK 1.6中锁一共有4中状态依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。另外,还使用了很多的锁优化技术,如适应性自旋锁、锁消除、锁粗化等。
3.1 自旋锁和自适应自旋锁
首先,什么自旋锁?顾名思义就是一个线程不停的自旋(循环),以达到代码块只有一个线程执行的同步效果。那么为什么会引入自旋锁呢?因为在许多应用中,共享数据的锁定状态只会持续很短的时间,短时间内挂起和恢复线程是浪费的,因此,为了让线程保持运行,但是不去争夺同步资源,引入了自旋锁,即让线程执行一个忙循环,当持有锁的线程释放锁后,该线程再去获取锁。避免线程挂起和恢复消耗资源。
自旋锁在JDK 1.4.2 中已经引入了,但是默认是关闭的,可以使用 -XX:+UseSpinning 参数开启,在JDK 1.6 中默认开启。
上边介绍了引入自旋锁的需求,锁持续的时间很短,这种情况下,让线程自旋等待相比挂起和恢复,似乎是更高效的方式;但是,如果锁长时间未释放,那么线程将一直自旋下去,这样会张勇太多的处理器时间,白白消耗处理器资源做无用功,带来性能上的浪费。因此,自旋锁等待的时间必须要有一定的限制,超过了规定次数,还没有获得锁,线程就会挂起。自旋次数默认是10次,可以使用 -XX:PreBlockSpin 参数来修改。
上边的自旋锁已经可以自旋指定的次数了,这样相比原来不停的自旋或者直接挂起线程已经高效很多了;可是如果我们自旋10次之后,刚挂起线程,就获得了锁,有需要唤醒线程,我们的处理器肯定在想你为什么不多自旋一会,我们的自旋锁是否能够更加智能呢?
JVM 的开发者没有让我们失望,在JDK 1.6 中引入了自适应的自旋锁,自适应就是说自旋的时间不再是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。自适应自旋锁认为,如果同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在执行,那么虚拟机就会任务这次自旋锁很可能会再次成功,将会等待更长的时间;如果某个锁,很少更改获得,那么后边的线程将忽略自旋的过程,直接挂起,避免处理器资源的浪费。
3.2 锁消除
锁消除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。
那么 JVM 虚拟机是如何检测锁不可能存在数据竞争呢?另外,如果不存在数据竞争我们再写代码的时候不加锁不久可以了,虚拟机为什么还要做这个检测呢?
虚拟机使用逃逸分析技术,来检测锁是否存在竞争;虽然我们再写代码时,可能不会加锁,但是javac编译器会对我们的程序进行自动优化,因此可能就会引入部分我们自己都不知道的锁,所以,虚拟机的锁消除还是有必要的,而且也更好的优化了程序的性能。
3.3 锁粗化
锁粗化就是将多个连续的锁,连接在一起,扩展成一个范围更大的锁。但是,在刚学习多线程时,总是推荐我们同步代码块的范围要尽可能小,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也能尽快得到锁。
大部分情况下,我们遵循以上的原则是正确的,但是如果一系列连续的操作都对同一个对象加锁(例如:频繁调用一些同步方法,StringBuffer.append()等),程序将会频繁的进行加锁解锁过程,影响效率。因此,虚拟机如果检测到这种对同一对象加锁的连续操作,将会把加锁范围扩展到整个操作序列的外部。
3.4 偏向锁
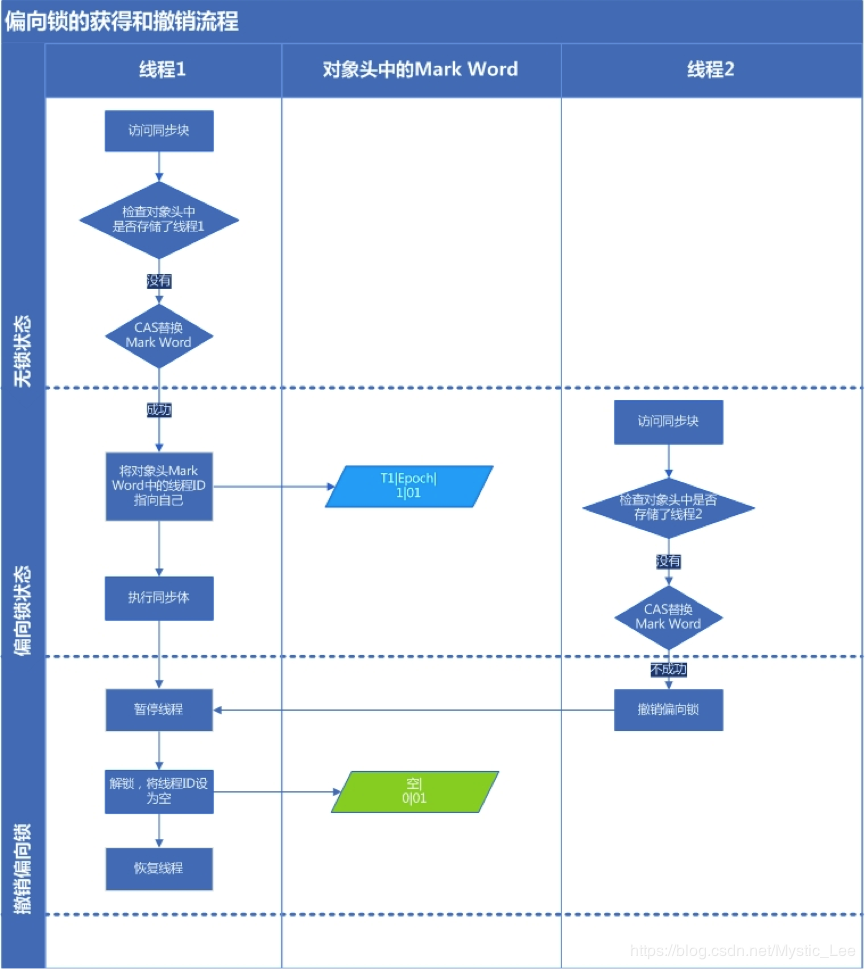
大多数情况下,锁总是由一个线程多次获得,这种情况下,为了降低线程获取锁的代价,引入了偏向锁。线程每次进入同步代码块,会在对象头中记录线程ID,一个该线程如果再次进入和退出同步代码块时,检测到对象头中存储的指向当前线程的偏向锁,则不需要使用CAS加锁和解锁;如果检测失败,则再检测一下对象头中的偏向锁标识是否设置为1,即当前是偏向锁:如果不是偏向锁,使用CAS竞争锁;如果是,使用CAS将对象头的偏向锁指向当前线程。
- 释放偏向锁 偏向锁的释放采用了一种只有竞争才会释放锁的机制,线程是不会主动去释放偏向锁,需要等待其他线程来竞争。偏向锁的撤销需要等待全局安全点(这个时间点是上没有正在执行的代码)。其步骤如下:
- 暂停拥有偏向锁的线程,判断锁对象是否还处于被锁定状态;
- 撤销偏向锁,恢复到无锁状态(01)或者轻量级锁的状态;
偏向锁获取和释放的流程大致如下图:(图片来源并发编程网-ifeve.com)
正文到此结束
热门推荐










相关文章





Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

