Nginx+Tomcat偶现502分析
业务为了负载均衡,前面放了个 Nginx,但最近 502 报警有点频繁,影响了 SLA,因此对这个问题做了较深入的研究。
502 Bad Gateway
简单来说就是 Nginx 找不到一个可用 的 upstream,可能的原因有:
- 压根是配置错误
- 连接 upstream server 发生错误/超时
- upstream server 到了处理瓶颈
还有一个重点是 轮询了 upstream server 后 任然没有一个可用的。但是不管什么原因,都能在 Nginx 的 error log 中找到报错详情。
upstream prematurely closed connection
在 Nginx 中找到错误日志(开了 debug):
[debug] 46093#46093: *606728052 http upstream process header [debug] 46093#46093: *606728052 malloc: 00007FB65E3834E0:4096 [debug] 46093#46093: *606728052 posix_memalign: 00007FB65C783D60:4096 @16 [debug] 46093#46093: *606728052 recv: eof:1, avail:1 [debug] 46093#46093: *606728052 recv: fd:65 0 of 4096 [error] 46093#46093: *606728052 upstream prematurely closed connection while reading response header from upstream, client: xxx [debug] 46093#46093: *606728052 http next upstream, 2 [debug] 46093#46093: *606728052 free keepalive peer [debug] 46093#46093: *606728052 free rr peer 4 4 [debug] 46093#46093: *606728052 free rr peer failed: 00007FB65C704F50 1 [debug] 46093#46093: *606728052 finalize http upstream request: 502
看了下 Nginx 代码,发现是 c->recv(); 读到的内容为 0,日志中也有显示 recv: fd:65 0 of 4096 ,说明没有获取到 response
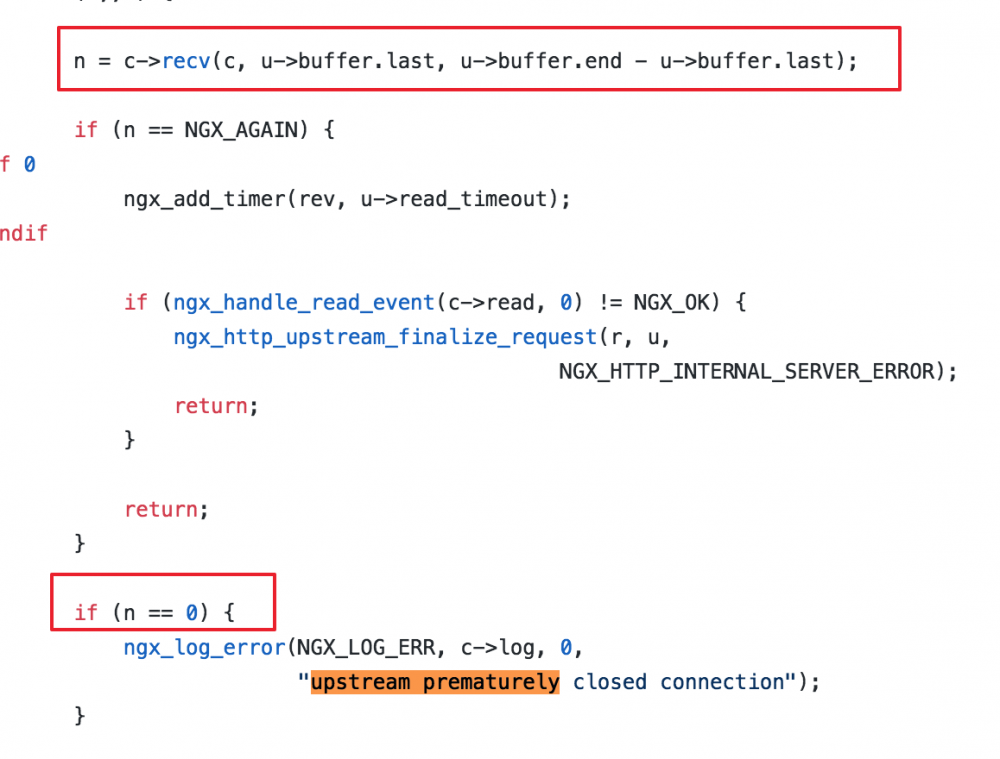
同时也查了 Tomcat access 日志,请求还没到 Tomcat。看情况就像日志里面说的,连接被断掉了。
一开始怀疑是网络原因导致连接断掉了,但出现较频繁,期间内网也无网络故障,应该和网络无关。
再看日志发现报错前后有很多 keepalive 信息,尝试关掉 keepalive,502 就没了,但这会对性能有一定影响,感觉有点因噎废食了,还得继续研究。
keepalive
HTTP 持久连接(HTTP persistent connection,也称作 HTTP keep-alive 或 HTTP connection reuse)是使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
一般 Nginx 会配置 keepalive 以提高性能:
upstream servers_test {
server 127.0.0.1:5001 max_fails=1 fail_timeout=10s weight=1;
server 127.0.0.1:5002 max_fails=1 fail_timeout=10s weight=1;
keepalive 10;
}
Syntax: keepalive connections; Activates the cache for connections to upstream servers. The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process. When this number is exceeded, the least recently used connections are closed.
可以配置每个 worker 对 upstream servers 最大长连接数量。同时这个长连接受 keepalive_requests(默认100) 和 keepalive_timeout(默认60s)配置的影响。
但 keepalive 也有缺陷,会加重 webserver 的负担,因为需要绑定一定数量的线程或者进程来维持长链接。注意 keepalive 并没有连接复用(即同一时间窗口不能处理多个请求,这个在 HTTP/2 中才实现),仅节省了新建/关闭连接的开销,类似连接池了。所以 webserver 一般都有类似 nginx 的 keepalive_requests、keepalive_timeout 配置,让空闲的连接断掉。
查看了 upstream(tomcat) 配置的 timeout 是20s,lighttpd 的 requests 是16,timeout 是 5s,都远小于 nginx 的配置。
原因就清楚了,upstream servers 先断了 keepalive 的长连接,但 nginx 仍使用了这个已经断掉的连接。
至于 nginx 为什么不主动检测一下连接是否可用呢?猜测应该是性能原因,一直检查连接池中的连接是否可用没必要,keepalive 协议本身也没业务心跳啥的。PS:商业版的 ngx_http_upstream_hc_module 可以主动监测(世界加钱可及)。
proxy_next_upstream
那么 Nginx 如何保证高可用呢?答案是重试。这就涉及另一个重要配置 proxy_next_upstream,在什么情况下进行重试,默认为 error timeout。按理说我们这个场景应该会重试,但没有重试。这是因为 Nginx 较新版本(1.9.13)多了个 non_idempotent 配置,默认 POST , LOCK , PATCH 等请求不重试,因为这些操作是非幂等操作,会对服务端数据造成影响(比如发消息接口,重试可能会重复发消息)。日志中也发现 502 的全都是 POST 请求。
要完全解决这个问题就需要对 proxy_next_upstream 配置簇深入看看,我们先做个测试。
Nginx 配置:
upstream servers_test {
server 127.0.0.1:5001 max_fails=1 fail_timeout=10s weight=1;
server 127.0.0.1:5002 max_fails=1 fail_timeout=10s weight=1;
keepalive 10;
}
location = /test {
proxy_connect_timeout 500ms;
proxy_read_timeout 10s;
proxy_send_timeout 10s;
proxy_next_upstream error timeout;
proxy_pass http://servers_test;
}
upstream server 是 Python flask 写的,返回自己的端口,方便直观看见落在了哪个节点:
@app.route('/test', methods=['GET', 'POST'])
def test():
return str(app.config['port']) + ' echo ' + str(time.asctime())
这算是一个比较典型的负载均衡配置,详细看看他是怎么工作的。不断 GET 请求发现 5001、5002 交替出现(weight=1),符合预期。当请求返回 5001 的时候,直接把 5002 停掉,再次请求发现返回了 5001 说明负载均衡有效,看看日志发生了什么:
# 按照轮询策略,选择了第二个 server (5002),符合预期 [debug] 39828#0: *38 get rr peer, current: 0000000000838438 0 [debug] 39828#0: *38 stream socket 10 [debug] 39828#0: *38 epoll add connection: fd:10 ev:80002005 [debug] 39828#0: *38 connect to 127.0.0.1:5002, fd:10 #44 # 但是连不上这个 [error] 18174#0: *35 connect() failed (111: Connection refused) while connecting to upstream [warn] 18174#0: *35 upstream server temporarily disabled while connecting to upstream [debug] 18174#0: *35 free rr peer failed: 0000000000804468 0 [debug] 18174#0: *35 close http upstream connection: 10 # 重试另一个 server,最终这次请求是成功的 [debug] 39828#0: *38 get rr peer, current: 0000000000838380 0 [debug] 39828#0: *38 stream socket 10 [debug] 39828#0: *38 epoll add connection: fd:10 ev:80002005 [debug] 39828#0: *38 connect to 127.0.0.1:5001, fd:10 #45 [debug] 39828#0: *38 http upstream connect: -2
只要失败 1 次(max_fails)接下来的 10s(fail_timeout)内都不会再请求这个 server,你不断请求就会发现,每隔 10s 上面的日志就会往复出现,直到 5002 server 恢复。还有个参数比较实用,slow_start,表示服务恢复后再等一会儿才发送请求过去,防止服务冷启动端口通了但实际不能服务的情况,如果是 upstream 是 tomcat 还可以设置其 bindOnInit="false" 表示服务都启动好了再绑定端口。
再试试 POST 请求,发现也会重试,和文档 non_idempotent 说的不一样呀,不过仔细一想,我是直接把 5002 服务停了或者模拟网络丢包,错误是 connect() failed、connection timed out 这些,明显可以重试的。再看看之前的错误,是 read response 的时候报错了,其实请求已经发出去了,这种情况肯定不能贸然重试(有可能是上文说的 keepalive 原因,也有可能是网络原因),nginx 也不知道 upstream 实际执行了没有。
这种情况需要精准控制 socket 的通讯过程,flask 就不方便模拟了,需要使用 socket 模块,在 recv() 之后 close 客户端连接:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import socket
import select
# 创建套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('0.0.0.0', 5002))
s.listen(100)
# 创建一个epoll对象
epoll = select.epoll()
epoll.register(s.fileno())
clients = {}
while True:
events = epoll.poll()
for fd, events in events:
if fd == s.fileno():
conn, addr = s.accept()
clients[conn.fileno()] = {
'conn': conn,
'addr': addr
}
print("new client {}".format(addr))
epoll.register(conn.fileno(), select.EPOLLIN | select.EPOLLET)
elif events == select.EPOLLIN:
# Available for read
recv = clients[fd]['conn'].recv(1024)
if recv:
# 接收包后直接断开客户端
print("recv {} from {}".format(recv.strip(), clients[fd]['addr']))
clients[fd]['conn'].close()
else:
# 客户端主动关闭连接
print("close client {}".format(clients[fd]['addr']))
del clients[fd]
epoll.unregister(fd)
else:
print(fd, events)
这样复现了问题(出现 502,报错也和线上一致),再使用 GET 请求,发现能失败重试,非常符合预期。然后加上 non_idempotent,虽然也有了重试,但是会有隐患,比如是 send/read timeout 错误,也会重试,可以把 5002 再改回 flask 程序,然后 sleep 11s,会发现返回的是 5001,但 5002 其实也执行了,会造成数据问题。
那怎么让 send/read timeout 不重试,其它 connection timed out 等情况重试呢?翻了一遍文档,发现个 proxy_next_upstream_timeout 配置参数,可以设置其和 proxy_read_timeout、proxy_send_timeout 一致或略小,这样 send/read 超时时也过了重试时间,也就不会重试了,测试了一下也和预期一致。
当然 proxy_next_upstream 还有很多其它选项,比如 http_500,这些我没加上,因为业务实际返回 500 的话很有可能是代码 bug 或者存储挂了,重试其它节点也一样,没必要,还容易雪崩。
结论
- 对于 upstream servers 是 Lighttpd、Nginx 等支持高并发的 webserver 可以关闭 keepalive
- 对于 upstream servers 是 Tomcat、Apache 这类 Web 容器建议开启 keepalive,以提高性能,并且超时等配置略大于 nginx( 让 Nginx 先断开长连接 ),keepalive 数量也要根据实际 QPS 配置,不能过大或过小
- 对于 upstream servers 主要是读为主的业务,或者业务非幂等操作安全(重试不会产生脏数据),建议设置 non_idempotent,并配置 proxy_next_upstream_timeout <= proxy_xxxx_timeout
- proxy_xxxx_timeout 也需要按实际情况进行调优,比如有文件上传操作 send_timeout 需要设置的长一点,接口耗时长的 rend_timeout 设置长一点
最终参考配置:
# 需要略小于upstream的对应配置
keepalive_timeout 30s;
keepalive_requests 10;
upstream servers_test {
server 127.0.0.1:5001 max_fails=1 fail_timeout=10s weight=1;
server 127.0.0.1:5002 max_fails=1 fail_timeout=10s weight=1;
keepalive 10;
}
location = /test {
proxy_connect_timeout 500ms;
proxy_read_timeout 60s;
proxy_send_timeout 10s;
proxy_next_upstream error timeout non_idempoten;
proxy_next_upstream_timeout 10s;
proxy_pass http://servers_test;
}
参考资料
http://nginx.org/en/docs/http/ngx_http_proxy_module.html
http://nginx.org/en/docs/http/ngx_http_upstream_module.html
https://lanjingling.github.io/2016/06/11/nginx-https-keepalived-youhua/
https://ningyu1.github.io/site/post/03-nginx-502-bad-gateway/
https://sofish.github.io/restcookbook/http%20methods/idempotency/
https://tomcat.apache.org/tomcat-7.0-doc/config/http.html
proxy_next_upstream may fail in some cases, https://github.com/openresty/openresty/issues/200
关于 NGINX 的 upstream 配置的 fail_timeout=0 参数的意义, https://www.v2ex.com/t/329726
正文到此结束
- 本文标签: 协议 Connection tar 长连接 QPS HTTP/2 文件上传 ip http 高可用 安全 TCP Nginx OpenResty IO Proxy IDE list tomcat ask 高并发 cat 并发 时间 web final 负载均衡 cache 连接池 数据 Select 端口 src id 进程 stream 代码 apache 参数 https ORM Keep-Alive UI HTML 测试 client 线程 服务端 幂等 GitHub REST git python bug 配置 App
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

