Lucene5学习之Suggest关键字提示
首先需要搞清楚Suggest模块是用来解决什么问题的?Google我想大家都用过,当我们在搜索输入框里输入搜索关键字的时候,紧贴着输入框下方会弹出一个提示框,提示框里会列出Top N个包含当前用户输入的搜索关键字的搜索热词,如图:
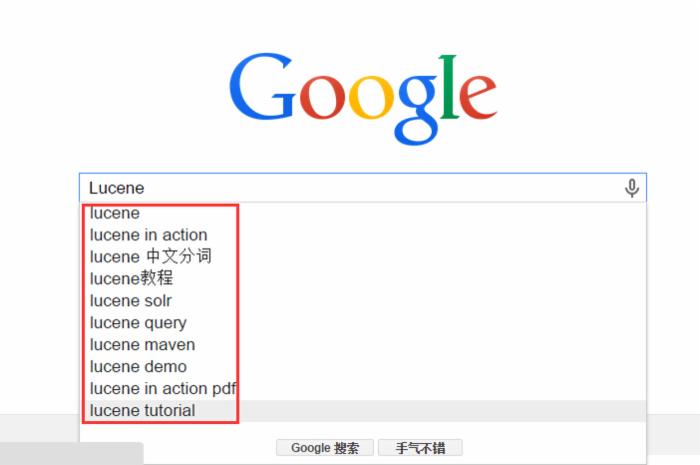
这里说的不是前端的这种JS效果,而说的是输入一个关键字如何获取相关的搜索热词,至于js效果,自己Google JQuery自动补全插件,我以前玩过,这里关注的是提示数据如何获取,当然你也可以使用数据库SQL like "%xxxx%"来实现(xxxx是你输入的搜索关键字),但Lucene来实现这个功能会更好,因为我们都知道Lucene的查询结果是可以根据相关度排序的,支持各种强大的Query查询,这是数据库SQL语法所不能实现的。在Lucene中,这种搜索关键字自动提示功能是由Suggest模块提供的。
要实现搜索关键字提示,首先你需要创建索引,此时创建索引就不是简简单单的借助IndexWrtier.addDocument了,而是需要通过 Suggest模块下的 AnalyzingInfixSuggester类去build,翻看 AnalyzingInfixSuggester类的源码一探究竟,先看看其成员变量声明部分:
public class AnalyzingInfixSuggester extends Lookup implements Closeable { /** Field name used for the indexed text. */ protected final static String TEXT_FIELD_NAME = "text"; /** Field name used for the indexed text, as a * StringField, for exact lookup. */ protected final static String EXACT_TEXT_FIELD_NAME = "exacttext"; /** Field name used for the indexed context, as a * StringField and a SortedSetDVField, for filtering. */ protected final static String CONTEXTS_FIELD_NAME = "contexts"; /** Analyzer used at search time */ protected final Analyzer queryAnalyzer; /** Analyzer used at index time */ protected final Analyzer indexAnalyzer; final Version matchVersion; private final Directory dir; final int minPrefixChars; private final boolean allTermsRequired; private final boolean highlight; private final boolean commitOnBuild; /** Used for ongoing NRT additions/updates. */ private IndexWriter writer; /** {@link IndexSearcher} used for lookups. */ protected SearcherManager searcherMgr; /** Default minimum number of leading characters before * PrefixQuery is used (4). */ public static final int DEFAULT_MIN_PREFIX_CHARS = 4; /** Default boolean clause option for multiple terms matching (all terms required). */ public static final boolean DEFAULT_ALL_TERMS_REQUIRED = true; /** Default higlighting option. */ public static final boolean DEFAULT_HIGHLIGHT = true; /** How we sort the postings and search results. */ private static final Sort SORT = new Sort(new SortField("weight", SortField.Type.LONG, true)); TEXT_FIELD_NAME:表示搜索关键字域,即我们用户输入的搜索关键字是在这个域上进行匹配的,这个域使用的是TextField且Store.YES,
EXACT_TEXT_FIELD_NAME:它跟 TEXT_FIELD_NAME类似,唯一区别就是它使用的是StringFeild且Store.NO,不要问我为什么知道
CONTEXTS_FIELD_NAME:这个域名其实也是用来过滤的,只是它是比较次要的过滤条件域,举个例子吧,比如你有title和content两个域,title表示新闻标题,content表示新闻内容,那这里的 CONTEXTS_FIELD_NAME表示的就是content域的域名,一般都是在title域里去过滤,content属于2次过滤或者说是次要级别的过滤,不知道这样说够明确不?
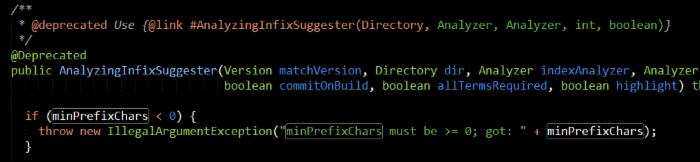
然后是两个分词器,分别对应查询时和创建索引时,两个分词器最好是保持一致, final Version matchVersion;这个就不用说了,Directory指的是索引目录,这个也不用多说大家都懂。minPrefixChars表示最小前缀字符长度,意思就是用户最少输入多少个字符我才开始搜索相关热词,设置这个值是为了避免用户输入字符过短导致返回的匹配结果太多影响性能,比如用户输入一个字符,然后程序就屁颠屁颠的去search,因为条件太宽泛,自然返回的结果集会很庞大,自然内存溢出或者响应时间很长,这样的应用你还会用吗?所以你懂的,所以内部做了一个最小输入字符长度的限制:
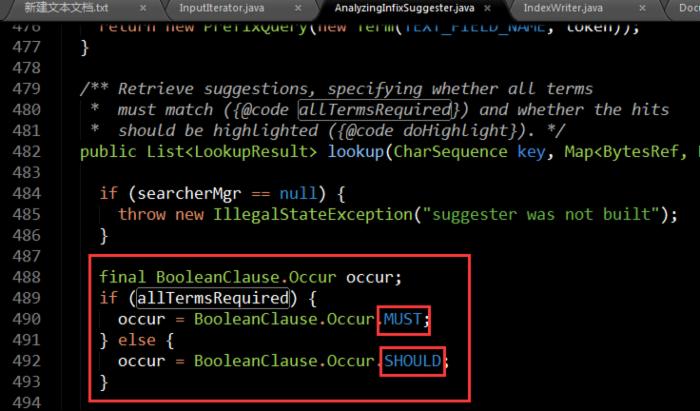
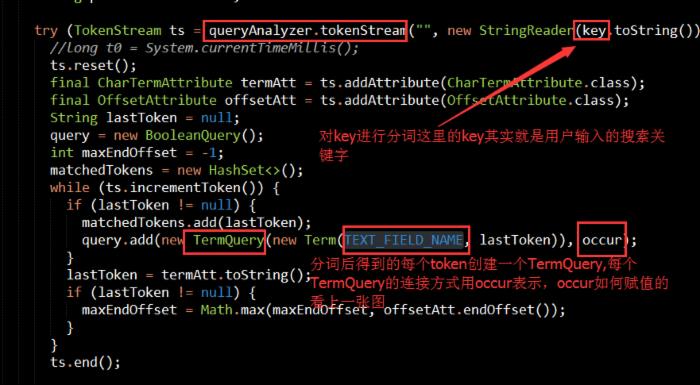
 boolean allTermsRequired这个布尔值用于搜索阶段,意思是用户输入的关键字需要全部匹配吗?举例说明吧,我怕说的太抽象,你们看不懂。假如我们创建了索引包含了title和content两个域,那么当用户输入了搜索关键字,用户可能输入的是lucene suggest,那么程序内部首先会对用户输入的搜索关键字进行分词,得到多个Term,有了多个Term然后new多个TermQuery,那这多个TermQuery之间是or链接还是and链接呢,所以有了
boolean allTermsRequired这个布尔值用于搜索阶段,意思是用户输入的关键字需要全部匹配吗?举例说明吧,我怕说的太抽象,你们看不懂。假如我们创建了索引包含了title和content两个域,那么当用户输入了搜索关键字,用户可能输入的是lucene suggest,那么程序内部首先会对用户输入的搜索关键字进行分词,得到多个Term,有了多个Term然后new多个TermQuery,那这多个TermQuery之间是or链接还是and链接呢,所以有了 allTermsRequired这个参数,意思就是所有Term都需要匹配吗,说白了就是所有的TermQuery需要用and链接吗?默认很显然是false,有人可能要问了,为什么必须是要全部匹配和非全部匹配呢,如果需要实现A匹配B不匹配C又匹配D匹配E不匹配.....对不起这种条件拼接方式默认的API无法实现(当然你可以通过继承重写自己来实现),因为用户的搜索关键字分词后得到的Term的个数不确定,多个Term之间谁该包含谁不该包含,这之间的排列组合情况太多,一个boolean值表示不了这么多种情况,所以只能是要么全部and全部or,说了那么多,你们再来看源码是不是轻松多了:
private IndexWriter writer;这个很明显是内部维护一个IndexWriter用来添加或更新索引数据的,protected SearcherManager searcherMgr,维护一个
SearcherManager是用来获取IndexSearcher对象以及释放IndexSearcher资源的,你可以认为SearcherManager是一个IndexSearcher的工具类,
private static final Sort SORT = new Sort(new SortField("weight", SortField.Type.LONG, true));
这句是重点,创建了一个排序器,默认按照weight域进行降序排序(之所以是降序是因为最后一个reverse参数设置为true了),降序意味着weigth值越大越排前面,至于这里的weight值表示什么,取决于你的InputInterator实现,接下来就来说说 InputInterator。
InputInterator接口决定了用于suggest搜索的索引数据从哪里来,说的官方点就是用于suggest搜素的索引的每个默认域的域值的数据来源需要用户来自定义,这本来也是合情合理的。
/** * Interface for enumerating term,weight,payload triples for suggester consumption; * currently only {@link AnalyzingSuggester}, {@link * FuzzySuggester} and {@link AnalyzingInfixSuggester} support payloads. */ public interface InputIterator extends BytesRefIterator { /** A term's weight, higher numbers mean better suggestions. */ public long weight(); /** An arbitrary byte[] to record per suggestion. See * {@link LookupResult#payload} to retrieve the payload * for each suggestion. */ public BytesRef payload(); /** Returns true if the iterator has payloads */ public boolean hasPayloads(); /** * A term's contexts context can be used to filter suggestions. * May return null, if suggest entries do not have any context * */ public Set<BytesRef> contexts(); /** Returns true if the iterator has contexts */ public boolean hasContexts(); 要理解InputInterator,你首先需要理解几个概念,InputInterator里的key,content,payload,weight都表示什么含义,下面分别来说明:
key:表示用户搜索关键字域,即用户输入的搜索关键字分词后的Term在这个域上进行匹配
content:源码注释里的解释是 A term's contexts context can be used to filter suggestions.太尼玛抽象了,我说的更直白更傻瓜点吧,意思就是contents是一个Term集合(只不过是用BytesRef字节形式表示的),
这个Term集合的每个元素是用来在CONTEXTS_FIELD_NAME表示的域里进行TermQuery,说白了就是在关键字的基础上再加个限制条件让返回的热词列表更符合你的要求,比如你搜iphone,可能在title域里搜索到iphone手机,可能还会返回iphone手机壳,可能你只想返回有关手机的热词不想返回有关手机壳的热词,假定你索引里还有个category类别的域,那这时你category域就是这里的context概念,你可以设置contexts的set集合为[手机],这样相当于在搜索关键字的TermQuery基础上再加一个或多个TermQuery(因为是set集合,内部会遍历set集合new多个TermQuery),记住,内部都是使用TermQuery实现查询过滤的,如果你想使用其他Query来实现过滤呢,对不起,你可以继承来重写,你懂的。
payload是用来存储一个额外信息,并以字节byte[]的形式写入索引中,当搜索返回后,你可以通过LookupResult结果对象的payload属性获取到该值,那最重要的就是要理解,为什么要设计这个payload呢,这要从 LookupResult类源码中找答案: 我们在创建索引的时候通过InputInterator接口的payload方法指定了payload数据从哪来获取并将它编码为BytesRef字节的形式,然后写入索引了,然后在查询时返回的结果集是用LookupResult包装的, 如图,LookupResult包含了如下信息: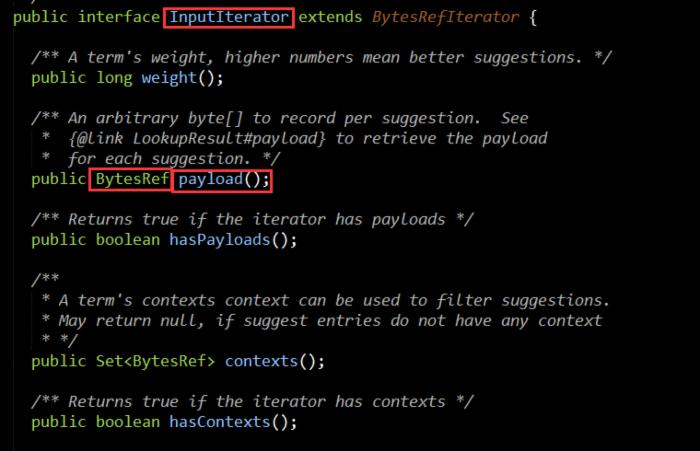
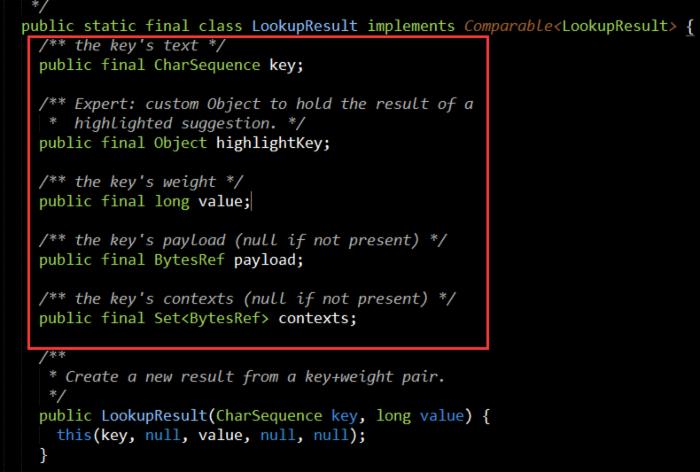
key:用户输入的搜索关键字,再返回给你
highlightKey:其实就是经过高亮的搜索关键字文本,假如你在搜索的时候设置了需要关键字高亮
value:即InputInterator接口中weight方法的返回值,即返回的当前热词的权重值,排序就是根据这个值排的
payload:就是 InputInterator接口中payload方法中指定的payload信息,设计这个payload就是用来让你存一些任意你想存的信息,这就留给你们自己去发挥想象了。
contexts:同理即InputInterator接口中contexts方法的返回值再原样返回给你。
OK,还是直接上示例代码吧,或许结合示例代码再来看我说的这些,你们会更容易理解。
创建了一个产品类:
package com.yida.framework.lucene5.suggest; import java.io.Serializable; /** * 产品类 * * @author Lanxiaowei * */ public class Product implements Serializable { /** 产品名称 */ private String name; /** 产品图片 */ private String image; /** 产品销售地区 */ private String[] regions; /** 产品销售量 */ private int numberSold; public Product(String name, String image, String[] regions, int numberSold) { this.name = name; this.image = image; this.regions = regions; this.numberSold = numberSold; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getImage() { return image; } public void setImage(String image) { this.image = image; } public String[] getRegions() { return regions; } public void setRegions(String[] regions) { this.regions = regions; } public int getNumberSold() { return numberSold; } public void setNumberSold(int numberSold) { this.numberSold = numberSold; } } 这个类是核心,决定了你的索引是如何创建的,决定了最终返回的提示关键词列表数据及其排序。
package com.yida.framework.lucene5.suggest; import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.io.UnsupportedEncodingException; import java.util.Comparator; import java.util.HashSet; import java.util.Iterator; import java.util.Set; import org.apache.lucene.search.suggest.InputIterator; import org.apache.lucene.util.BytesRef; public class ProductIterator implements InputIterator { private Iterator<Product> productIterator; private Product currentProduct; ProductIterator(Iterator<Product> productIterator) { this.productIterator = productIterator; } public boolean hasContexts() { return true; } /** * 是否有设置payload信息 */ public boolean hasPayloads() { return true; } public Comparator<BytesRef> getComparator() { return null; } public BytesRef next() { if (productIterator.hasNext()) { currentProduct = productIterator.next(); try { //返回当前Project的name值,把product类的name属性值作为key return new BytesRef(currentProduct.getName().getBytes("UTF8")); } catch (UnsupportedEncodingException e) { throw new RuntimeException("Couldn't convert to UTF-8",e); } } else { return null; } } /** * 将Product对象序列化存入payload * [这里仅仅是个示例,其实这种做法不可取,一般不会把整个对象存入payload,这样索引体积会很大,浪费硬盘空间] */ public BytesRef payload() { try { ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(bos); out.writeObject(currentProduct); out.close(); return new BytesRef(bos.toByteArray()); } catch (IOException e) { throw new RuntimeException("Well that's unfortunate."); } } /** * 把产品的销售区域存入context,context里可以是任意的自定义数据,一般用于数据过滤 * Set集合里的每一个元素都会被创建一个TermQuery,你只是提供一个Set集合,至于new TermQuery * Lucene底层API去做了,但你必须要了解底层干了些什么 */ public Set<BytesRef> contexts() { try { Set<BytesRef> regions = new HashSet<BytesRef>(); for (String region : currentProduct.getRegions()) { regions.add(new BytesRef(region.getBytes("UTF8"))); } return regions; } catch (UnsupportedEncodingException e) { throw new RuntimeException("Couldn't convert to UTF-8"); } } /** * 返回权重值,这个值会影响排序 * 这里以产品的销售量作为权重值,weight值即最终返回的热词列表里每个热词的权重值 * 怎么设计返回这个权重值,发挥你们的想象力吧 */ public long weight() { return currentProduct.getNumberSold(); } } 最后就是调用suggester.lookup查询返回LookupResult结果集,Over!
package com.yida.framework.lucene5.suggest; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.HashSet; import java.util.List; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.search.suggest.Lookup.LookupResult; import org.apache.lucene.search.suggest.analyzing.AnalyzingInfixSuggester; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.BytesRef; import com.yida.framework.lucene5.util.Tools; /** * Lucene关键字提示测试 * * @author Lanxiaowei * */ public class SuggesterTest { private static void lookup(AnalyzingInfixSuggester suggester, String name, String region) throws IOException { HashSet<BytesRef> contexts = new HashSet<BytesRef>(); contexts.add(new BytesRef(region.getBytes("UTF8"))); //先以contexts为过滤条件进行过滤,再以name为关键字进行筛选,根据weight值排序返回前2条 //第3个布尔值即是否每个Term都要匹配,第4个参数表示是否需要关键字高亮 List<LookupResult> results = suggester.lookup(name, contexts, 2, true, false); System.out.println("-- /"" + name + "/" (" + region + "):"); for (LookupResult result : results) { System.out.println(result.key); //从payload中反序列化出Product对象 BytesRef bytesRef = result.payload; InputStream is = Tools.bytes2InputStream(bytesRef.bytes); Product product = (Product)Tools.deSerialize(is); System.out.println("product-Name:" + product.getName()); System.out.println("product-regions:" + product.getRegions()); System.out.println("product-image:" + product.getImage()); System.out.println("product-numberSold:" + product.getNumberSold()); } System.out.println(); } public static void main(String[] args) { try { RAMDirectory indexDir = new RAMDirectory(); StandardAnalyzer analyzer = new StandardAnalyzer(); AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(indexDir, analyzer); //创建Product测试数据 ArrayList<Product> products = new ArrayList<Product>(); products.add(new Product("Electric Guitar", "http://images.example/electric-guitar.jpg", new String[] { "US", "CA" }, 100)); products.add(new Product("Electric Train", "http://images.example/train.jpg", new String[] { "US", "CA" }, 100)); products.add(new Product("Acoustic Guitar", "http://images.example/acoustic-guitar.jpg", new String[] { "US", "ZA" }, 80)); products.add(new Product("Guarana Soda", "http://images.example/soda.jpg", new String[] { "ZA", "IE" }, 130)); // 创建测试索引 suggester.build(new ProductIterator(products.iterator())); // 开始搜索 lookup(suggester, "Gu", "US"); lookup(suggester, "Gu", "ZA"); lookup(suggester, "Gui", "CA"); lookup(suggester, "Electric guit", "US"); } catch (IOException e) { System.err.println("Error!"); } } } OK,该说的都说了,可能说的比较啰嗦,还望见谅,希望对你们有所帮助,Demo源码还是一如既往的在底下附件里。
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙

一起交流学习!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

