在Ignite上运行微服务
从本文开始,会通过一个系列的篇幅来介绍使用Apache Ignite内存数据组织平台来构建容错、可扩展的基于微服务的解决方案。
详细信息参考:https://liyuj.gitee.io/doc/java/ServiceGrid.html
介绍
当前,很多公司都会将自己的应用或者解决方案构建于微服务架构之上,这样做的主要好处是,可以将一个解决方案拆分为一组松耦合的软件组件(微服务)。这些软件组件可能有自己的版本以及生命周期,甚至有自己的开发团队。此外,这些软件还可能使用不同的语言和技术来开发和维护。但是因为所有的微服务都会是更大的构件(软件或者解决方案)的一部分,所以它们至少需要一个机制来进行彼此的交互和数据交换。
同时,基于微服务的解决方案也会用于高负载或者需要处理快速增长的数据的场景,因此和不是基于微服务的应用和解决方案一样,它也会面临同样的问题和困难。
- 面向磁盘的数据库已经无法跟上快速增长的数据量,这些数据需要以并行的方式进行存储和处理,数据库正在成为整个应用或者解决方案的性能瓶颈;
- 软件的高可用性保证作为一个好功能已经成为过去式,当前,应用的高可用性已经成为事实上的标配。
从本文开始,会通过一个系列的篇幅来一步步地介绍使用Apache Ignite内存数据组织平台来构建容错、可扩展的基于微服务的解决方案。
使用Apache Ignite的基于微服务的解决方案
下图会描述整个解决方案的主要构成,之后会深入,一个一个定义它们的角色。
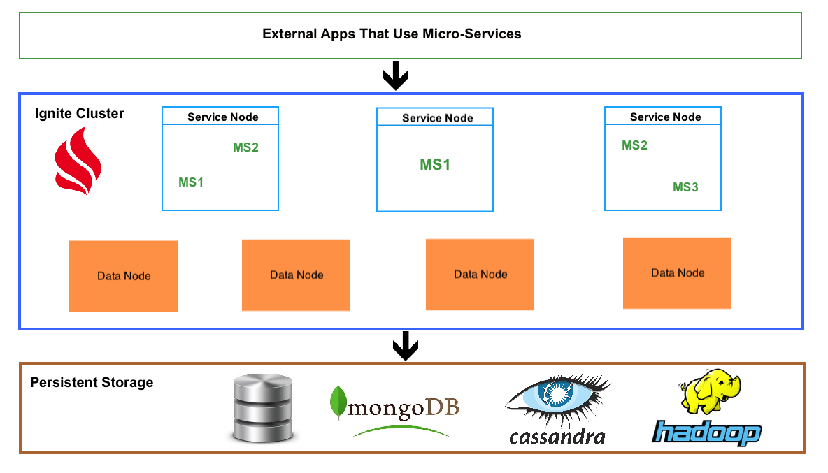
Ignite集群层
集群有两个作用:
首先,作为主要的数据存储,它直接在内存中保存数据集。因为数据离CPU更近,一个微服务不需要从磁盘上获取数据,这显著地提升了整体的性能。从上图来看,我们指定了一个特定的集群组(数据节点)来专门处理这个问题。
一个数据节点是一个Ignite服务端节点,它持有数据集的一部分,并且可以执行查询和计算。另外,有赖于基于对象序列化的二进制格式化技术,一个数据节点不需要部署模型对象和计算的支撑类,这个叫做对等类加载机制,它可以管理从应用逻辑节点(服务节点)预加载的计算类。
其次,集群管理微服务的生命周期,并且为微服务配备所有必要的API,比如与其他服务或者数据节点进行通信的API。要达到这一点,一个基于Ignite集群的解决方案需要包含前述的服务节点,这些节点部署有微服务,并且应用逻辑也在这里执行。一个服务节点可以部署一个或者多个微服务,这个取决于具体的应用以及负载情况。每个微服务都需要实现Ignite的Service接口,它直接就有了容错和访问其他微服务的能力。
Ignite会处理在服务节点范围内,一个微服务的一个或者多个副本的部署,并且会自动地进行容错和负载平衡。在上述的图1中,这类微服务被命名为 MS<N> (MS1,MS2等)。在多个服务和数据节点间传播负载的好处是,如果MS1微服务改变,不需要重启整个集群,所有需要做的就是在部署有MS1微服务的服务节点上更新MS1的相关类,因此只有所有节点的一个子集需要重启。
所有的节点(服务和数据节点)都是相互连接的,这使得部署在一个服务节点上的MS1可以与部署在任何其他的或者自身服务节点上的微服务进行通信,也可以向任何数据节点获取和发送数据以及计算。
持久化存储层
这一层是可选的,可以用于如下的场景:
- 在内存中持有所有的数据是不必要或者不可行的;
- 需要从基于磁盘的副本中恢复数据集的能力,这时整个集群需要停机或者需要重启。
要启用持久化存储层,只需要简单地提供一个实现了CacheStore接口的Ignite数据缓存就可以了。在默认支持的实现中,有RDBMS,MongoDB以及Cassandra。
外部应用层
这是微服务架构应用的”用户”,基本上来说,这是一个触发调用一个一个微服务的各种执行流程的层次。
这个层可以使用具体到每个微服务的外部协议来与微服务进行通信(而在内部,微服务间相互通信可以使用Ignite服务,或者使用Ignite客户端连接进行连接),这方面都很大的灵活性以及多样化的选择。
—-
作为一个系统,一个可能的架构由如下层次组成:
- Ignite集群层
- 持久化存储层
- 外部应用层
本文中会关注第一层(Ignite集群层),可以参考一个GitHub项目,他包含了日常中实现拟议的微服务架构所必须的构建块,尤其是要覆盖如下部分:
- 配置和启动数据节点;
- 使用Ignite的服务API的典型服务实现;
- 配置和启动驻有Ignite服务的服务节点;
- 一个连接到集群并且触发服务执行的虚拟应用。
微服务位于内存数据网格架构之上时的数据节点
正如第一篇中提到的,数据节点是持有数据集一部分数据的服务端节点,应用逻辑端会在这个数据集上执行查询和计算。通常来说,这种类型的节点对应用逻辑是透明的,因为这些节点只是简单地存储数据集,然后当应用访问数据时高效地进行处理就可以了。
下面会看一下在实现层面如何定义一个数据节点。
可以下载这个GitHub项目然后找到 data-node-config.xml,它会用于创建一个新的数据节点,这个配置包含了一组与数据节点有关的段落和参数。
首先,需要为每一个要部署到集群中的Ignite缓存配置一个特定的节点过滤器。这个过滤器会在缓存启动时被调用,它会定义一个要存储缓存数据的集群节点的子集–数据节点。同样的过滤器在网络拓扑发生变化时也会被调用,比如新节点加入集群或者旧节点离开集群。过滤器的实现需要加入每个节点的类路径中,不管该节点是否会成为数据节点。
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="nodeFilter">
<bean class="common.filters.DataNodeFilter"/>
</property>
</bean>
第二,实现过滤器,在本例中,使用了一个非常明确的实现,DataNodeFilter,它通过检查 data.node 参数来确定一个节点是否会被视为数据节点。如果一个节点在属性映射中配置了这个参数,那么他会成为一个数据节点然后数据会驻留于此,否则该节点会被忽略。
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("data.node");
return dataNode != null && dataNode;
}
第三,data-node-config.xml为每个使用这个配置启动的节点的属性映射添加了 data.node 属性,就像下面这样:
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="data.node" value="true"/>
</map>
</property>
最后,通过使用示例中的DataNodeStartup文件,或者将data-node-config.xml传递给Ignite的 ignite.sh/bat 脚本来启动一个数据节点的实例。如果选择了后者,那么一定要将java/app/common目录中的所有类文件构建成一个jar包,然后还要将这个jar文件加入到每个数据节点的类路径中。
微服务位于内存数据网格架构之上时的服务节点
在实现层次上服务节点的定义与前述数据节点的用法没有什么大的不同。基本上,需要建立一个方式,即指定一个特定的微服务将要部署在哪些节点上,它们会是整个集群的一个子集。
最初,需要使用服务网格API实现一个微服务,为后文起见,可以回顾一下那个GitHub示例中的已有服务实现,即Maintenance Service。
这个服务可以调度一个车辆维护的服务,并且可以查看已做保养的清单,它实现了所有服务网格的必要方法,包括 init(…) , execute(…) 以及 cancel(…),并且在这个接口中增加了新的方法:
public interface MaintenanceService extends Service {
public Date scheduleVehicleMaintenance(int vehicleId);
public List<Maintenance> getMaintenanceRecords(int vehicleId);
}
将这个维护服务配置并且部署到特定的Ignite节点(服务节点)上有几种方式。在本例中,通过maintenance-service-node-config.xml启动的每个节点,都可以考虑进行维护服务的部署,下面可以看一下配置。
首先,确保维护服务的实例只会被部署到指定了节点过滤器的节点上:
<bean class="org.apache.ignite.services.ServiceConfiguration">
<property name="nodeFilter">
<bean class="common.filters.MaintenanceServiceFilter"/>
</property>
</bean>
第二,维护服务使用的过滤器,只会被部署到在属性映射中配置了 maintenance.service.node 的节点上:
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("maintenance.service.node");
return dataNode != null && dataNode;
}
最后,通过如下的XML片段,使用maintenance-service-node-config.xml启动的每个节点在映射中都会包含这个属性:
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="maintenance.service.node" value="true"/>
</map>
</property>
就这些了,使用MaintenanceServiceNodeStartup文件,或者将maintenance-service-node-config.xml传递给Ignite的 ignite.sh/bat 脚本,就可以启动维护服务节点的一个或者多个实例,如果选择了后者,一定要确保将java/app/common和java/services/maintenance目录中的所有文件打包成一个jar文件,然后将这个jar文件添加到每个服务将要被部署的节点的类路径上。
示例中包含了另一个与车辆管理有关的Ignite服务,使用VehicleServiceNodeStartup文件或者使用经过vehicle-service-node-config.xml配置的 ignite.sh/bat ,可以启动至少一个部署有该服务的服务节点,如果选择了 ignite.sh/bat 方式,不要忘了组装一个jar文件然后将其加入相关节点的类路径上。
在内存数据网格之上运行微服务的示例应用
一旦准备好了数据节点,维护服务和车辆服务节点也都启动运行了,那么就可以运行第一个示例应用来访问这个分布式微服务了。
在示例中找到并且启动TestAppStartup,这个应用会接入集群,往预定义的缓存中注入虚拟数据,然后与服务进行交互。
MaintenanceService maintenanceService = ignite.services().serviceProxy(MaintenanceService.SERVICE_NAME, MaintenanceService.class, false); int vehicleId = rand.nextInt(maxVehicles); Date date = maintenanceService.scheduleVehicleMaintenance(vehicleId);
如果注意了,应用会使用服务代理来与服务进行交互,代理的好处就是,启动应用的节点不需要在本地类路径中持有服务的实现,也不需要在本地部署一个服务。
———–
描述的是集群如何与持久化存储集成以及外部应用如何发请求给微服务 — 应用与集群无关也不会依赖Ignite的API。
这里还会提到第二部分中介绍的GitHub工程,因此,要确保将其检出到本机并且更新到最新版。
数据节点的持久化存储
Ignite是一个内存数据平台,默认将数据保持在内存中。然而,也可以将其持久化到磁盘上。比如希望确保即使集群重启数据也不会丢失。 要开启持久化,只需要解决三个小事情:
- 决定使用什么技术作为持久化存储(关系数据库、MongoDB、Cassandra、Hadoop等等);
- 找到一个已有的CacheStore接口实现,或者如果有必要也可以自己开发一个;
- 将实现加入缓存配置中。
就这么多了!做完之后,第一部分中描述的数据节点,就会与持久化存储进行交互,如下图所示:
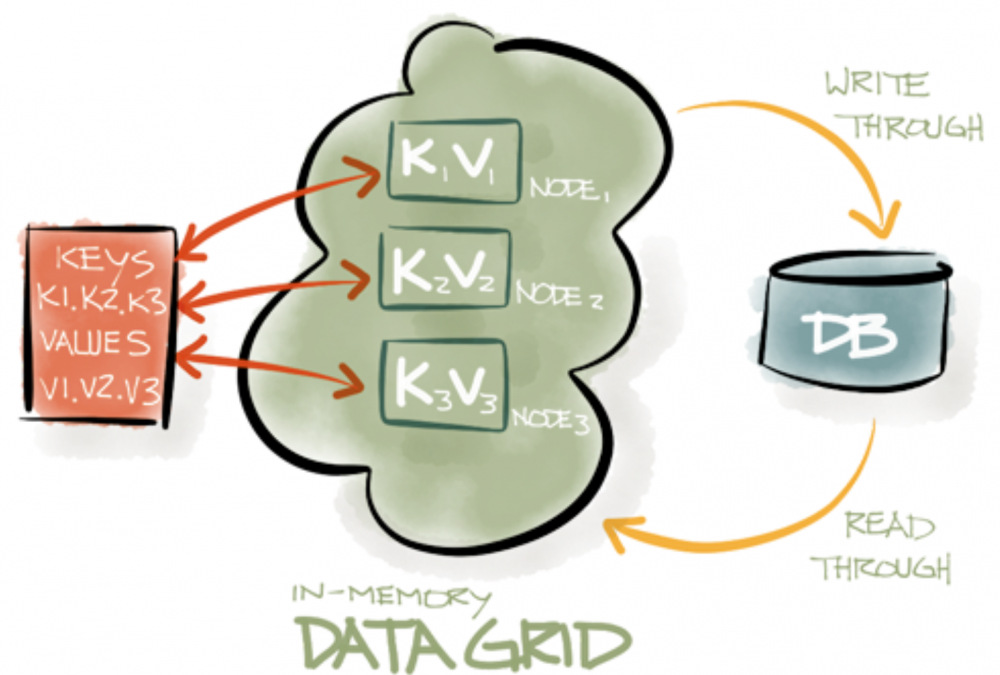
要强调的是,如果内存中的数据发生变更,数据会被自动地传播到磁盘上,或者如果内存中没有对应该主键的值,会即时从持久化中进行数据的预加载。 下面看一下基于这个GitHub工程,如何为微服务架构实现以及插入一个自定义的持久化存储。
为了演示方便,创建了一个虚拟持久化存储实现,它实际上将数据存储在一个 ConcurrentHashMap 中,这个演示只是为了说明,如果需要创建一个自定义的持久化存储实现,Ignite基本上只需要实现三个方法:
/** {@inheritDoc} */
public BinaryObject load(Long key) throws CacheLoaderException {
System.out.println(" >>> Getting Value From Cache Store: " + key);
return storeImpl.get(key);
}
/** {@inheritDoc} */
public void write(Cache.Entry entry) throws CacheWriterException {
System.out.println(" >>> Writing Value To Cache Store: " + entry);
storeImpl.put(entry.getKey(), entry.getValue());
}
/** {@inheritDoc} */
public void delete(Object key) throws CacheWriterException {
System.out.println(" >>> Removing Key From Cache Store: " + key);
storeImpl.remove(key);
}
下一步,在数据节点的配置中,通过在名为 maintenance 的缓存配置中添加一行代码,就可以开启这个自定义存储。
<property name="cacheStoreFactory">
<bean class="javax.cache.configuration.FactoryBuilder" factory-method="factoryOf">
<constructor-arg value="common.cachestore.SimpleCacheStore"/>
</bean>
</property>
最后,要检查一下Ignite集群与持久化存储的通信,怎么做呢,在开发环境中打开GitHub工程然后启动一个数据节点的实例(DataNodeStartup文件),一个维护服务节点的实例(MaintenanceServiceNodeStartup文件)和一个车辆服务节点的实例(VehicleServiceNodeStartup文件)。所有节点互联之后,启动TestAppStartup,它会接入集群,注入数据然后调用服务。TestAppStartup执行完毕后,打开 DataNodeStartup的日志窗口,就可以看到类似下面这样的一个字符串:
>>> Writing Value To Cache Store: Entry [key=1, val=services.maintenance.common.Maintenance [idHash=88832938, hash=1791054845, date=Tue Apr 18 14:55:52 PDT 2017, vehicleId=6]]
之所以显示这个字符串,是因为 TestAppStartup 触发了一个 maintenance 缓存的更新,它会自动地给前述虚拟持久化存储发送一个更新。
从外部应用接入
TestAppStartup 是一个与部署在Ignite集群中的微服务进行交互的应用样例,某种意义上来说它是一个内部应用,因为它直接接入集群并且调用了服务网格的API。
但是对于外部应用来说,它不可能也不应该知道集群及其整体的部署,那么它怎么与微服务进行交互呢?一个简单的方案就是,Ignite服务以不同的方式监听来自外部应用的请求然后做出响应。
比如,当MaintenanceService的一个实例部署进集群后,它通过一个预定义的端口开启一个服务套接字来接收远程的连接(查看MaintenanceServiceImpl可以了解更多细节)。那么使用ExternalTestApp启动一个外部应用之后,它就会使用服务套接字与服务连接,然后获得每个车辆的维护调度, ExternalTestApp 的输出大致如下:
>>> Getting maintenance schedule for vehicle:0
>>> Getting maintenance schedule for vehicle:1
>>> Getting maintenance schedule for vehicle:2
>>> Getting maintenance schedule for vehicle:3
>>> Getting maintenance schedule for vehicle:4
>>> Getting maintenance schedule for vehicle:5
>>> Getting maintenance schedule for vehicle:6
>>> Maintenance{vehicleId=6, date=Tue Apr 18 14:55:52 PDT 2017}
>>> Getting maintenance schedule for vehicle:7
>>> Getting maintenance schedule for vehicle:8
>>> Getting maintenance schedule for vehicle:9
>>> Shutting down the application.
在这个系列中,展示了在Ignite集群中如何部署和维护一个基于微服务的解决方案。这个方案不需要关注微服务生命周期以及高可用性等事情,交给Ignite就行了,只需要关注实际业务逻辑即可。再者,所有的数据以及微服务都是在整个集群中分布的,这就意味着不用再担心性能和容错性-Ignite都已经解决了。
来源:https://my.oschina.net/liyuj/blog/892755
正文到此结束
- 本文标签: list http 数据缓存 mongo 部署 协议 配置 App value src cache 模型 rand apache https map CTO key build bean 高可用 tk java git apr 代码 XML Service 分布式 微服务 目录 struct Datanode GitHub 实例 开发 Property id 缓存 db 集群 API MongoDB 参数 下载 服务端 Proxy node cat 管理 Cassandra 软件 ACE 希望 ConcurrentHashMap 端口 数据库 数据 HTML 组织 生命 IO HashMap Hadoop tar UI
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

