一个 NullPointerException,竟然有这么多花样












案发现场
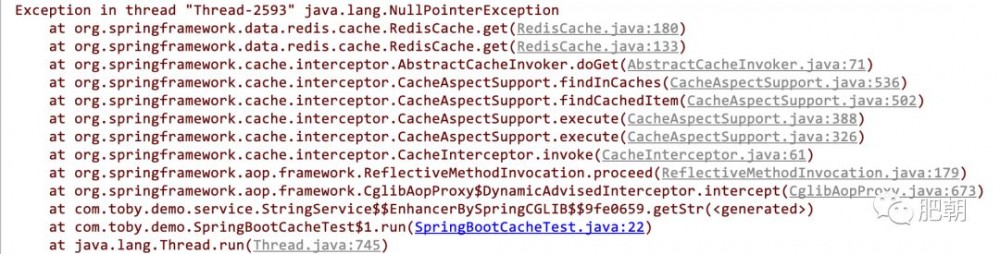
我们先看一下给出的异常栈
java.lang.NullPointerException
at org.springframework.data.redis.cache.RedisCache.get(RedisCache.java:180)
at org.springframework.data.redis.cache.RedisCache.get(RedisCache.java:133)
at org.springframework.cache.transaction.TransactionAwareCacheDecorator.get(TransactionAwareCacheDecorator.java:69)
at org.springframework.cache.interceptor.AbstractCacheInvoker.doGet(AbstractCacheInvoker.java:71)
at org.springframework.cache.interceptor.CacheAspectSupport.findInCaches(CacheAspectSupport.java:537)
at org.springframework.cache.interceptor.CacheAspectSupport.findCachedItem(CacheAspectSupport.java:503)
at org.springframework.cache.interceptor.CacheAspectSupport.execute(CacheAspectSupport.java:389)
at org.springframework.cache.interceptor.CacheAspectSupport.execute(CacheAspectSupport.java:327)
at org.springframework.cache.interceptor.CacheInterceptor.invoke(CacheInterceptor.java:61)
根据异常栈我们很轻松就能定位到源码位置
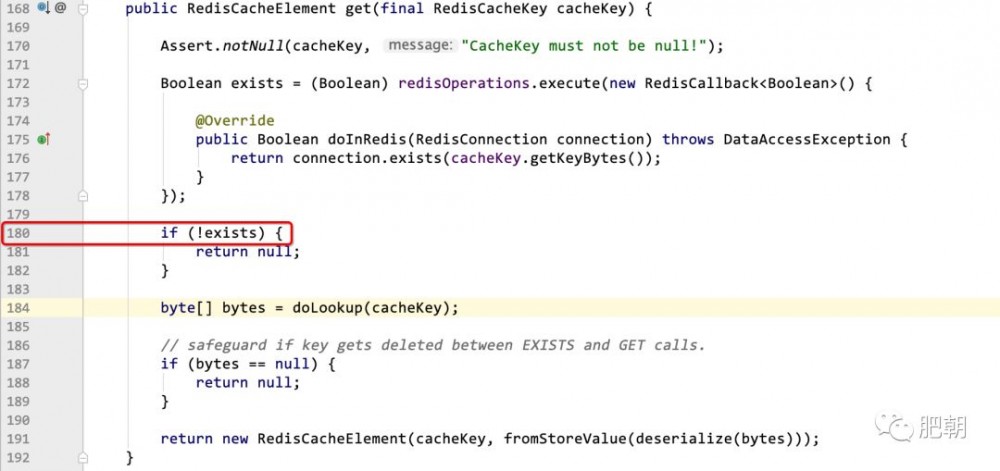
很明显 exists 为null,就会出现本篇的 NullPointerException 。当然如果这样三分钟没到本篇就 草率结束 ,明显有失肥朝的男儿本色!另外若当真如此草率,那么关注肥朝公众号的意义何在?肥朝公众号的老粉丝们都知道,肥朝的 海量 源码实战类文章,都有三个特点
-
从源码原理角度分析,为什么会出现这个问题?
-
如何解决掉这个问题?
-
我们如何深度思考,不断从这次经历中压榨出最大价值。(非常重点!)
比如就拿这个问题来说,按照我们正常的思维惯性,我们看到176行有个 return ,又知道 exists 是 null ,那么我们点进 connection.exists(cacheKey.getKeyBytes()) 这个方法一探究竟。
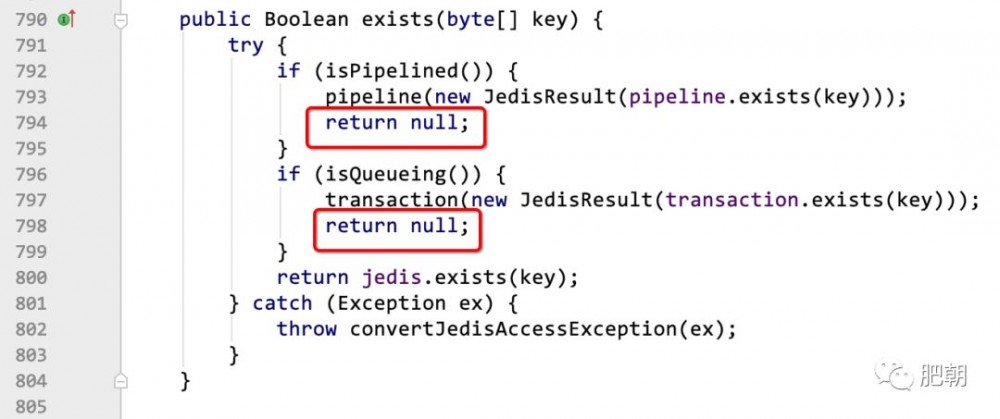
结果发现果然如我们所料,这里竟然有两个 return null 的情况,这个时候就有粉丝把持不住,要九浅一深直入源码分析,看这两个条件什么时候满足。但是肥朝想说的是,且慢动手!

你注意看这段代码
Boolean exists = (Boolean) redisOperations.execute(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
return connection.exists(cacheKey.getKeyBytes());
}
});
public interface RedisOperations<K, V> {
<T> T execute(RedisCallback<T> action);
}
我们现在已知 execute 的返回值 T (exists)为null, T 和 action 的返回值的关系,要看execute代码里面的具体实现的!这点很重要,也很容易被疏忽!由于文中提到了 随机 出现,那么这里就涉及到一个排查的技巧。一般和 随机 出现有关的,根据经验,主要从两个方向入手
1.根据多个异常的情况的入参数据来分析,看看多个异常情况的入参都有什么特点。
2.模拟并发量,因为很多问题本地重现不了是因为并发量不够。
该粉丝根据方式二,将自己的项目代码中的Redis代码抽取了一个最简模型,将问题重现。但是由于该模型是ssm项目,为了方便大家都能重现并参与其中,我用springboot抽取了相关模型,如下图:

真相大白
将上面的代码运行,果不其然出现了我们想要找的异常栈。
我们把断点打在了上面说的那两个可能返回null的地方,可能你却惊奇的发现,断点根本没有进去。那就只剩下一个可能了。那就是 redisOperations.execute() 方法。我们发现,demo中继承RedisTemplate自定义了RedisOperations,名为 RedisCustomTemplate 。然后我们在catch处打上断点。
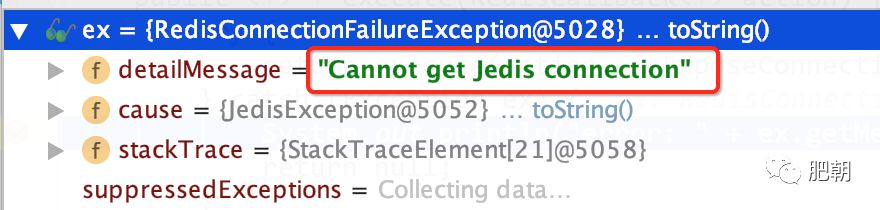
从这里我们就知道了。连接池参数blockWhenExhausted = true(默认),如果连接池没有可用Jedis连接,会等待maxWaitMillis(毫秒),依然没有获取到可用Jedis连接,会抛出这个异常。
根据沟通了解到,该同学生产代码中,catch住后是没有任何日志输出,直接返回了null,自然就导致了NullPointerException。
如何解决
肥朝认为解决问题要从两个方面入手。
1.连接池为什么不够?连接数不够时,盲目调大连接数是最常见的错误做法,根本解决办法还是要挖掘背后不够的原因,一般连接数不够,根据 《Redis开发与运维》 作者付磊在书中总结出无非是以下几点。
-
1.1 连接泄漏(较为常见)
-
1.2 业务并发量大,maxTotal确实设置小了。
-
1.3 Jedis连接还的太慢(Redis发生了阻塞,例如慢查询等原因)。
-
1.4 其他问题(例如丢包、DNS、客户端TCP参数配置)。
具体是属于上述哪个情况,自己对症下药。
2.自定义 RedisCache 。
我们知道 RedisCallback 确实会存在两个返回null的情况,根据
if (!exists) {
return null;
}
这样的判断方式,存在很大的空指针异常隐患,我们可以继承 RedisCache ,然后重写该方法,将这个判断的bug改掉,也可以去最大同性交友网站github上,查看最新版本的bug修复情况,当然很多公司更换jar版本都要走流程,所以具体处理方式,酌情处理。
问题复盘
在真相大白和给出解决方案后,那么我们就将整件事进行复盘。
1.提问的艺术
我们再回顾一下该粉丝的提问:“你们有没有遇到xxx问题”,其实显而易见,这样的提问方式,相信和他一样因为这个不规范,并且公司还有一定流量触发出问题的概率,小之又小。如果把“你们有没有遇到过xxx问题”换成“我遇到了一个xxx问题”,这样可能回复率还会多一丢丢。当然,问人毕竟是最低效的解决方式,最重要的还是,要掌握分析问题的技巧,以及源码实战的经验。当然很多同学反馈,公司根本没有源码实战经验的机会,因此,关注肥朝公众号,积累源码实战经验就显得格外重要了。
2.编码规范
如果同学没有吞掉异常,日志输出了真实异常
org.springframework.data.redis.RedisConnectionFailureException: Cannot get Jedis connection;
nested exception is redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool
那么这个问题简直是随便搜索一下都秒解决。但是关键就在于吞掉了真实异常,并且返回null,非常碰巧的是
public Boolean exists(byte[] key) {
try {
if (isPipelined()) {
pipeline(new JedisResult(pipeline.exists(key)));
return null;
}
if (isQueueing()) {
transaction(new JedisResult(transaction.exists(key)));
return null;
}
return jedis.exists(key);
} catch (Exception ex) {
throw convertJedisAccessException(ex);
}
}
该方法还有两个返回null的情况,给排查时造成了极大的迷惑性,容易让我们把精力放在了这里。
3.命名不规范。
在沟通中,我发现demo中 RedisCustomTemplate 这个成为问题最关键突破口的地方,在他们公司,竟然被起了一个欺骗性的命名。

我之前就在【 编码不规范,同事真的会两行泪? 】吐槽过这种欺骗性的命名,从这个案例中,我们再一次验证了,欺骗性的命名危害有多大,
4.异常输出。
从该粉丝的demo中,我们看到了这样的代码。
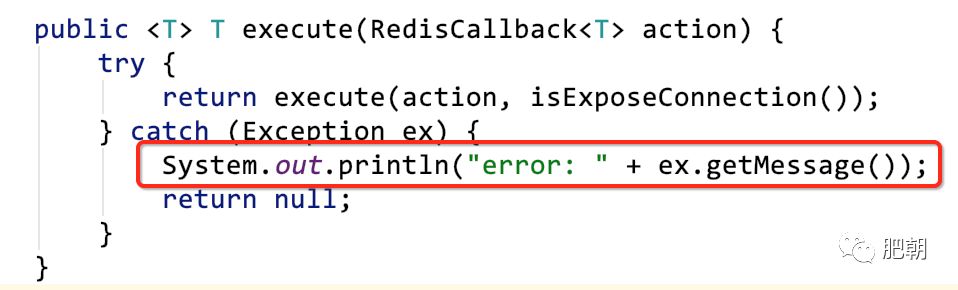
别以为这只是个demo无所谓,细节往往能看出编码的意识! 大家可以检查一下自己的项目,之前肥朝在【 面试官问我,Redis分布式锁如何续期?懵了。 】中就吐槽过这种输出方式。亦或者存在
ex.printStackTrace();
的方式。这样的方式存在两个非常大的隐患。
4.1 该方式用到了 synchronized ,当然这个还是小问题,毕竟synchronized在jdk 1.6做了很多优化,性能提升了很大。(这个很多优化到底是啥优化,后续肥朝再讲解)
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
4.2 这样的输出方式,无法将异常输出到日志文件。因为这个是jdk的方法,人家怎么可能输出到你要的文件路径。然后我们生产分析问题,都是要看日志,你通过这种方式输出,自然就会导致关键信息丢失!
4.3 ex.getMessage() 的方式,是无法输出异常栈信息的。我们来看一下阿里规范手册提到的输出方式:

敲黑板划重点
大家自行检查自己公司项目的代码 ,是否存在上述的问题。有则下面留言告诉肥朝。
写在最后
更多技术讨论,文中源码实战demo,源码实战技巧,欢迎加入我的知识星球 ,等你来撩!


正文到此结束
- 本文标签: Connection git queue bug 配置 key http MQ synchronized IDE 总结 ip message 模型 网站 TCP src DNS IO 提问 redis 锁 源码 文章 springboot cat tk 代码 dist 突破 cache 分布式锁 数据 开发 java ACE 分布式 学生 并发 GitHub client https Action EXHAUSTED UI 参数 spring Word id find 连接池 NSA
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
https://www.newcmy.com/register?aff=HBVX
建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。 -
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

