『互联网架构』软件架构-redis特性和集群特性(上)(48)
上次已经说到了redis其实就是nosql,这次具体redis是个什么样的东西。
源码文档:https://github.com/limingios/netFuture/tree/master/源码/『互联网架构』软件架构-redis特性和集群特性(48)

(一)Redis安装
通过虚拟机的方式在centos7下面安装下,这次我不通过docker的方式了,按照正常的方式,让老铁们熟悉redis的结构。
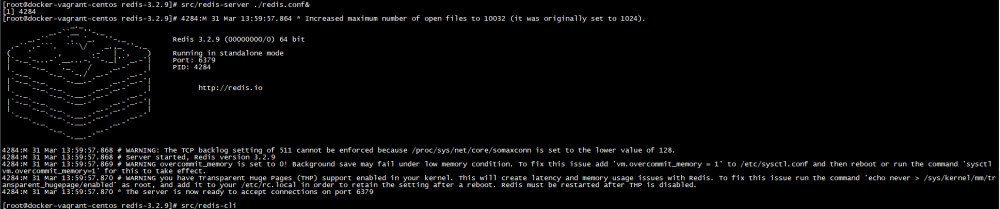
mkdir soft cd soft #虽然这个不是最新版本,但是这个版本已经够了解了。 #我一直说不要使用最新版本的, #如果新版本没有太多建设性的改变, #因为新版本资料少,出问题不好解决。 wget http://download.redis.io/releases/redis-3.2.9.tar.gz tar xvf redis-3.2.9.tar.gz cd redis-3.2.9 make install PREFIX=/root/soft/redis-3.2.9 #启动 src/redis-server ./redis.conf& ps -ef | grep redis #客户端连接 src/redis-cli

(二)常用命令
-
keys
>*表示区配所有
set liming 'hi' set liming2 'hi' set idig8 'hi' keys *

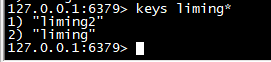
以liming开头的
keys liming*
-
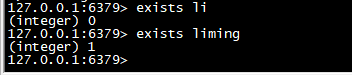
exists
>key是否存在
exists li exists liming
-
set
>设置 key 对应的值为 string 类型的 value。
set aa 'liming'

-
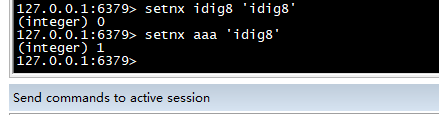
setnx
>设置 key 对应的值为 string 类型的 value。如果 key 已经存在,返回 0,否则返回1。nx 是 not exist 的意思。
setnx idig8 'idig8' setnx aa 'idig8'
-
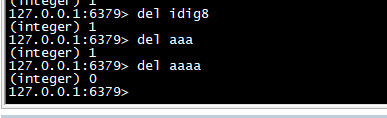
del
>删除某个key,存在返回1,不存在返回0
del idig8 del aaa
-
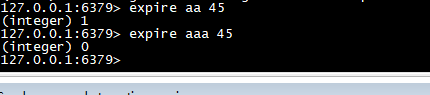
expire
>设置过期时间(单位秒),1 返回 设置成功,0 设置失败
expire aa 45 expire aaa 45
-
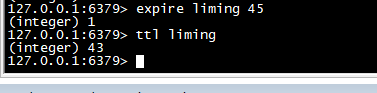
ttl
>查看剩下多少时间。返回负数则key失效,key不存在了
ttl liming expire liming 45 ttl liming
-
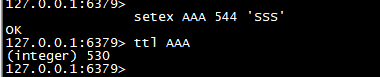
setex
>设置 key 对应的值为 string 类型的 value,并指定此键值对应的有效期。
setex AAA 544 'sss' ttl AAA
-
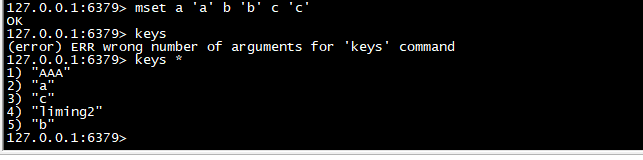
mset
>一次设置多个 key 的值,成功返回 ok 表示所有的值都设置了,失败返回 0 表示没有任何值被设置。其实实际生产中这个用处比较大,一次放入多个值,减少跟客户端的请求次数。
mset a 'a' b 'b' c 'c'
-
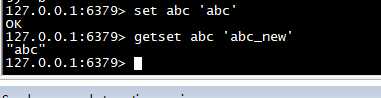
getset
>设置 key 的值,并返回 key 的旧值。
set abc 'abc' getset abc 'abc_new'
-
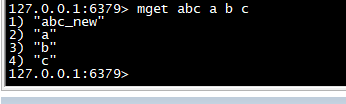
mget
>一次获取多个 key 的值,如果对应 key 不存在,则对应返回 nil。
mget abc a b c
-
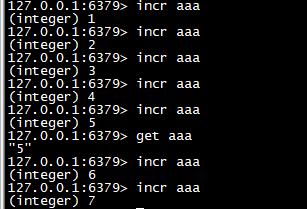
incr
>对key 的值做加加操作,并返回新的值。注意 incr 一个不是 int 的 value 会返回错误,incr 一个不存在的 key,则设置 key 为 1
incr aaa incr aaa incr aaa incr aaa
-
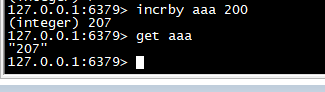
incrby
>同 incr 类似,加指定值 ,key 不存在时候会设置 key,并认为原来的 value 是 0
incrby aaa 200 get aaa
-
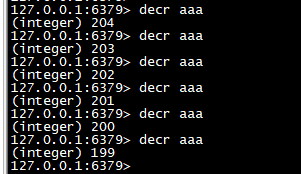
decr
>对 key 的值做的是减减操作,decr 一个不存在 key,则设置 key 为-1
decr aaa decr aaa decr aaa
-
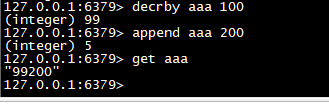
decrby
>同 decr,减指定值。
decrby aaa 100

-
append
>给指定 key 的字符串值追加 value,返回新字符串值的长度。
append aaa 200 get aaa
-
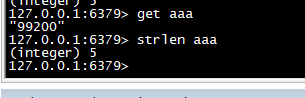
strlen
>取指定 key 的 value 值的长度。
strlen aaa
-
persist
>用于移除给定 key 的过期时间,使得 key 永不过期。
persist aaa

-
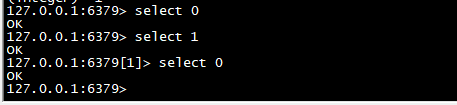
select
>默认的16个库。默认选中0库。选择数据库(0-15库)
select 0 select 1 select 0
-
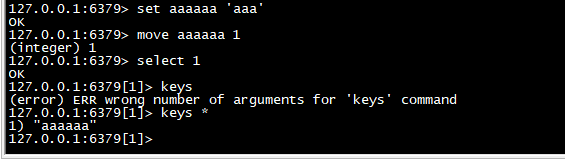
move
>key 迁移到 1库中
set aaaaaa 'aaaaaa' move aaaaaa 1 select 1 keys *
-
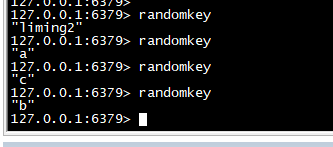
randomkey
>随机返回一个key
randomkey randomkey randomkey
-
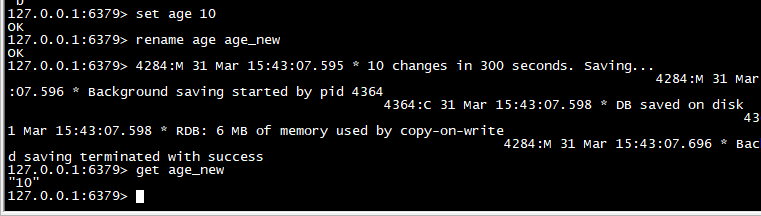
rename
>重命名
set age 10 rename age age_new get age_new
-
type
>返回数据类型
get age_new type age_new
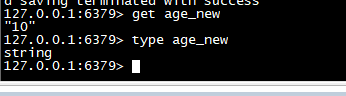
-
ping
>测试连接是否可以成功

-
quit
>退出连接

-
dbsize
>返回key的数量
dbsize

-
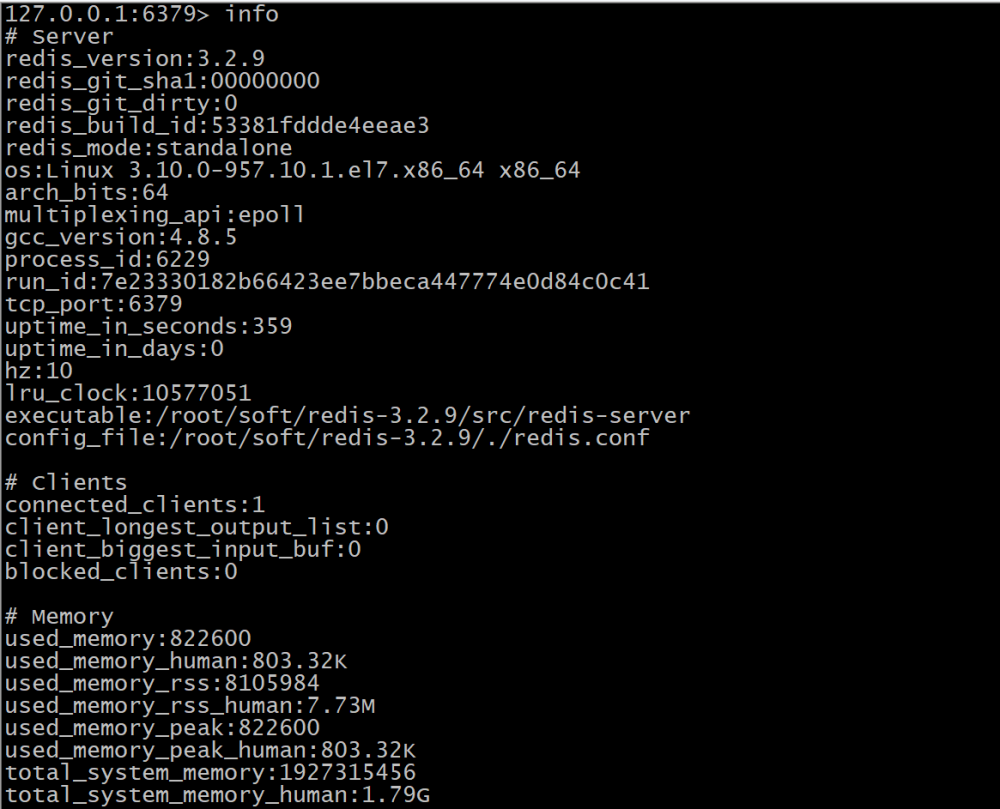
info
>输出redis信息
info
-
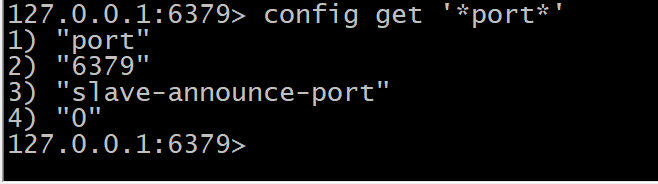
config get|set
>显示与修改配置
config get '*port*'
-
string
>格式: set key value
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
set abc 'abc' get abc

-
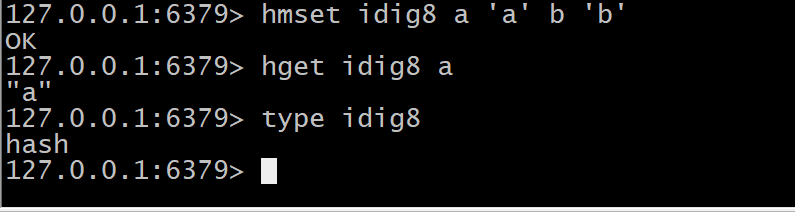
hash
>格式: hmset name key1 value1 key2 value2
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
hmset idig8 a 'a' b 'b' hget idig8 a type idig8
-
list(列表)
>Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
格式: lpush name value
在 key 对应 list 的头部添加字符串元素
格式: rpush name value
在 key 对应 list 的尾部添加字符串元素
格式: lrem name index
key 对应 list 中删除 count 个和 value 相同的元素
格式: llen name
返回 key 对应 list 的长度
lpush idiglist redis lpush idiglist mongodb lpush idiglist hbase llen idiglist lrange idiglist 0 10 type idiglist
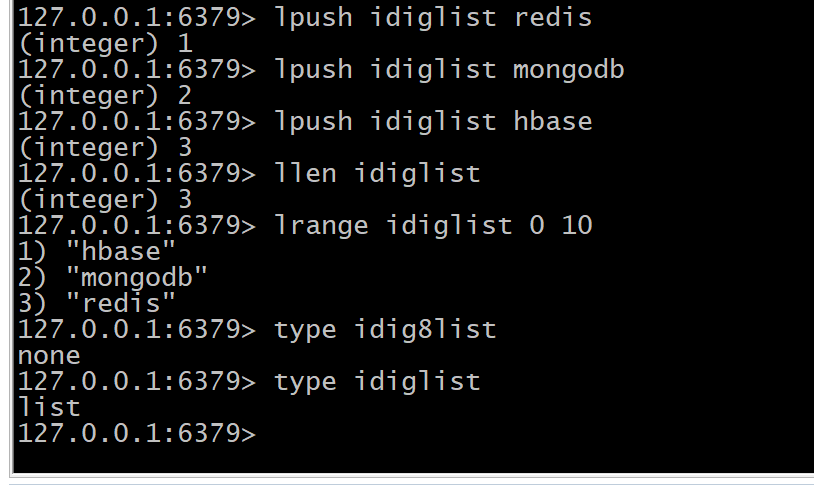
-
zset(sorted set:有序集合)
>格式: zadd name score value
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd idig88 1 redis zadd idig88 2 redis zadd idig88 3 java zadd idig88 4 mongodb zrangebyscore idig88 0 1000 type idig88
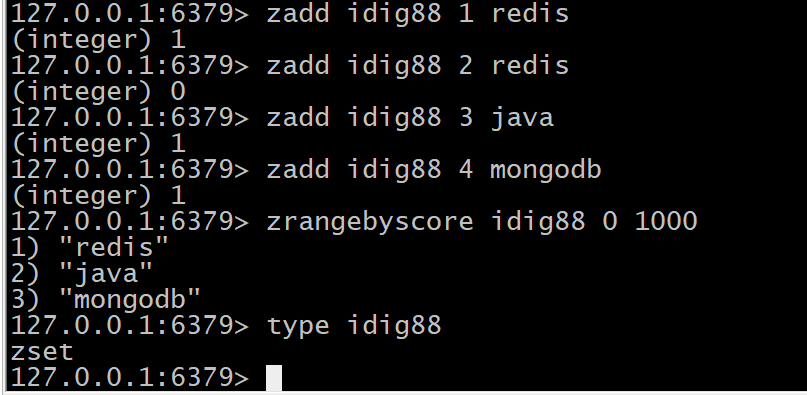
-
事务
>并非分布式事务,这个基本用不到,但是它支持,就提下。
redis 对事务的支持目前还比较简单。redis 只能保证一个 client 发起的事务中的命令可以连续的执行,而中间不会插入其他 client 的命令。 由于 redis 是单线程来处理所有 client 的请求的所以做到这点是很容易的。一般情况下 redis 在接受到一个 client 发来的命令后会立即处理并 返回处理结果,但是当一个 client 在一个连接中发出 multi 命令有,这个连接会进入一个事务上下文,该连接后续的命令并不是立即执行,而是先放到一个队列中。当从此连接受到 exec 命令后,redis 会顺序的执行队列中的所有命令。并将所有命令的运行结果打包到一起返回给 client.然后此连接就 结束事务上下文。
开启事物:exec 取消事物:discard 结束事物:exec
set age 20 set name 'idig8' get age get name #开始 multi incr age incr name #执行 exec get age get name
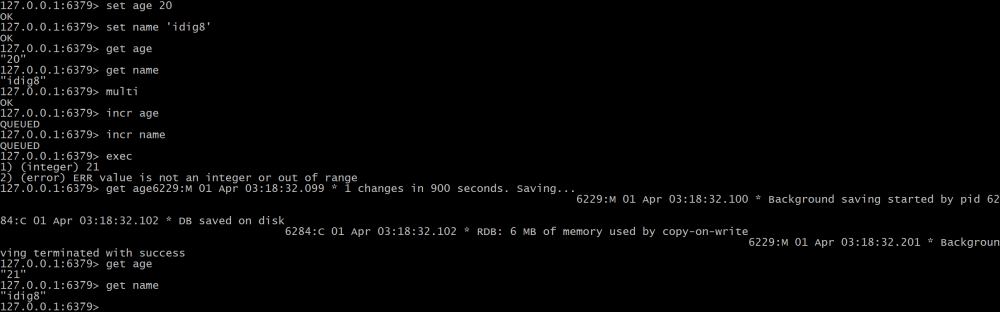
-
发布与订阅
>发布订阅(pub/sub)是一种消息通信模式,主要的目的是解耦消息发布者和消息订阅者之间的
耦合,这点和设计模式中的观察者模式比较相似。pub/sub 不仅仅解决发布者和订阅者直接代码级别耦合也解决两者在物理部署上的耦合。在redis实现是SUBSCRIBE (订阅主题)、 UNSUBSCRIBE(取消主题) 和 PUBLISH(推送)
订阅
subscribe idig8
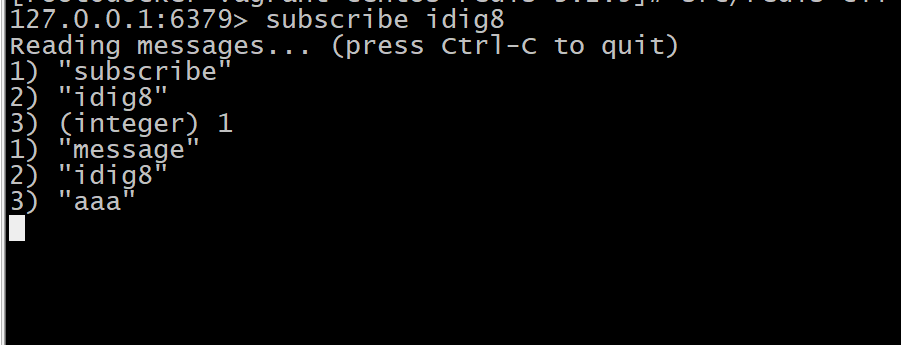
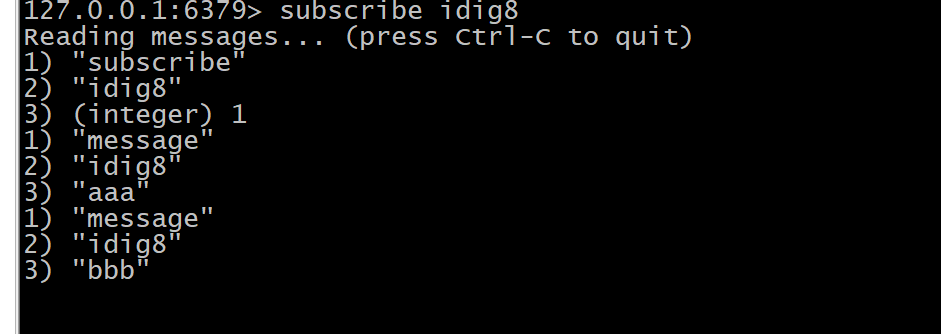
生产
publish idig8 aa publish idig8 bbb


-
持久化
>持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。Redis 提供了两种持久化方式:RDB(默认) 和AOF 。
RDB:
rdb是Redis DataBase缩写
RDB功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
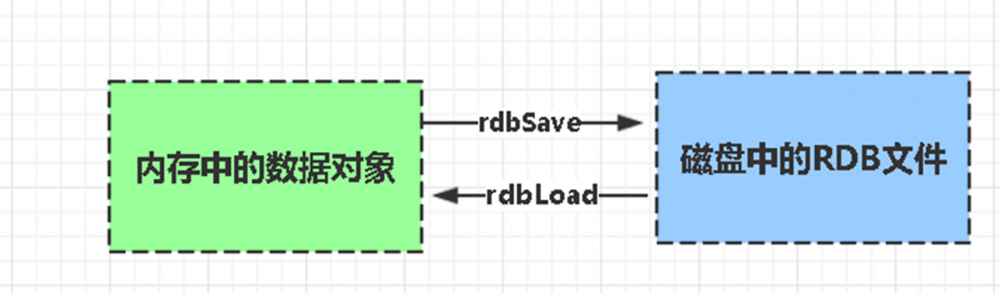
rdbSave函数: 将内存中的数据库数据以 RDB 格式保存到磁盘(文件)中,文件存在,那么新的 RDB 文件将替换已有的 RDB 文件。
在保存 RDB 文件期间, 主进程会被阻塞, 直到保存完成为止。
SAVE 和 BGSAVE 两个命令是操作 rdbSave函数的区别:
SAVE 直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。
BGSAVE 则 fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。因为 rdbSave 在子进程被调用,所以 Redis 服务器在 BGSAVE 执行期间仍然可以继续处理客户端的请求。
rdbLoad函数:是redis服务重启或者启动的时候回加载保存到磁盘的RDB文件加载到内存中会被阻塞。
https://redisbook.readthedocs.io/en/latest/internal/rdb.html#id4
存储结构:
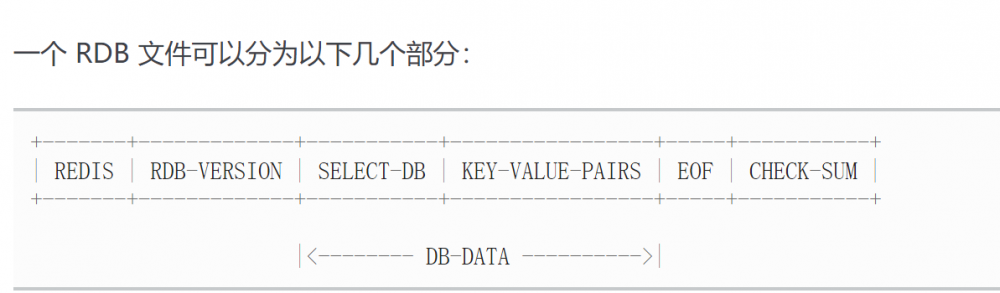
保存策略:
save 900 1
save 300 10 #300 秒内容如超过 10 个 key 被修改,则发起快照保存
save 60 10000
AOF:Aof是Append-only file缩写,每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
两个步骤都需要根据一定的条件来执行,Redis提供了三种条件。
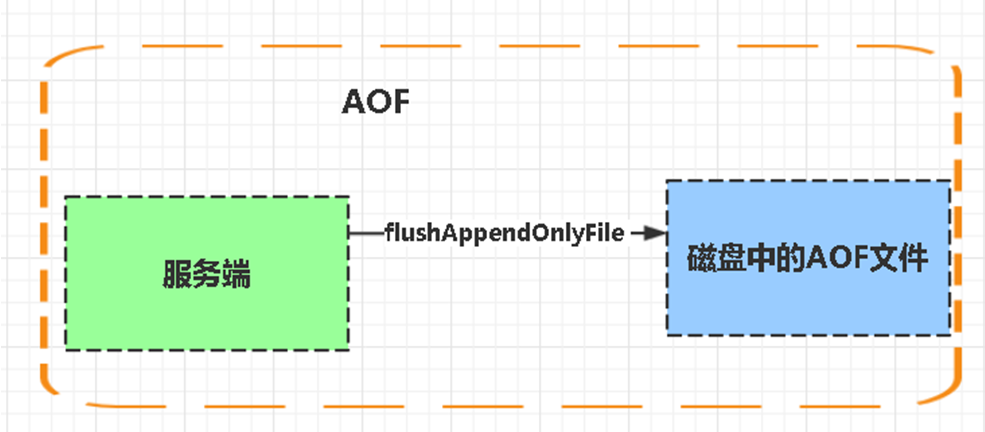
保存策略:
| 模式 | WRITE 是否阻塞 | SAVE 是否阻塞 | 停机时丢失的数据量 |
|---|---|---|---|
| AOF_FSYNC_NO 不保存 | 阻塞 | 阻塞 | 操作系统最后一次对 AOF 文件触发 SAVE 操作之后的数据。 |
| AOF_FSYNC_EVERYSEC 每一秒钟保存一次 | 阻塞 | 不阻塞 | 一般情况下不超过 2 秒钟的数据。 |
| AOF_FSYNC_ALWAYS 每执行一个命令保存一次 | 阻塞 | 阻塞 | 最多只丢失一个命令的数据。 |
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。
总结:RDB:数据 。AOF:数据+命令。
AOF更新频率RDB高 优先加载aof。
加载的时候没有RDB(数据文件要小)快吧。
-
api太多了
>直接发布文档吧,在源码里面有,直接看html文档吧
PS:常用都写了一遍,建议还是练练过一遍有点印象。命令还是很重要的。
百度未收录
>>原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
>>原文链接地址:上一篇:下一篇:
正文到此结束
- 本文标签: Master 测试 grep HBase API MongoDB 软件 core 2019 协议 tar 安全 redis HTML list src MQ 部署 服务器 centos 数据 App value dist IO rand root https 集群 UI 设计模式 key client 图片 缓存 wget git 互联网 配置 时间 分布式事务 IOS mongo java db 进程 安装 代码 Docker 百度 文章 分布式 tab 线程 NOSQL IT人 Select 总结 删除 id 源码 数据库 sql GitHub DOM 操作系统 http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

