『互联网架构』软件架构-redis特性和集群特性(中)(49)
上次说了redis的命令,这次说说redis的集群相关的知识。

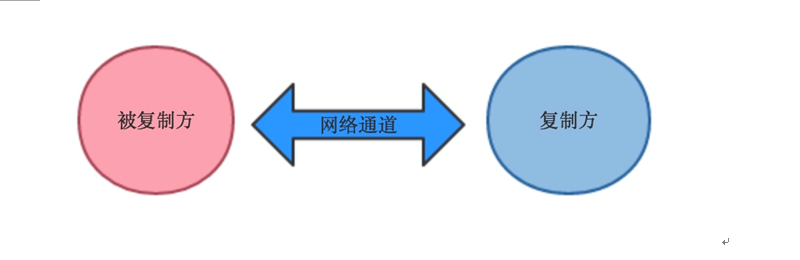
(一)复制
通常为被复制方(master)主动将数据发送到复制方(slave),复制方接收到数据存储在当前实例,最终目的是为了保证双方的数据一致,同时也是降低了master的压力。
-
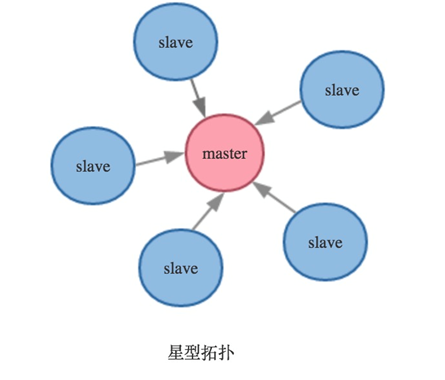
复制方式
>主(master)-从(slave)模式
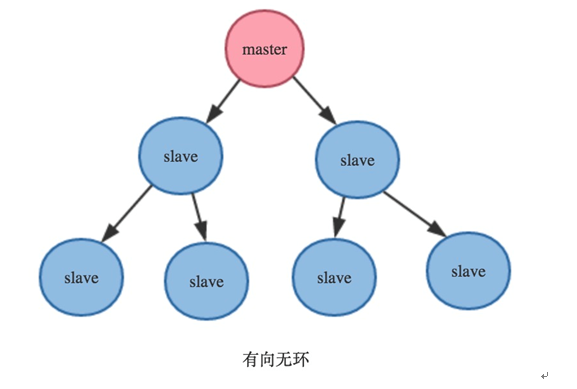
从(slave)-从(slave)
主从复制的流程图
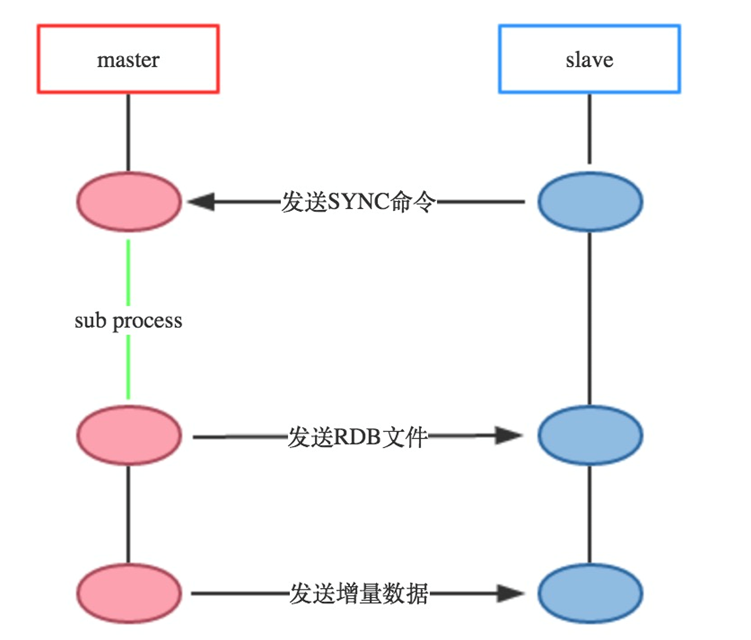
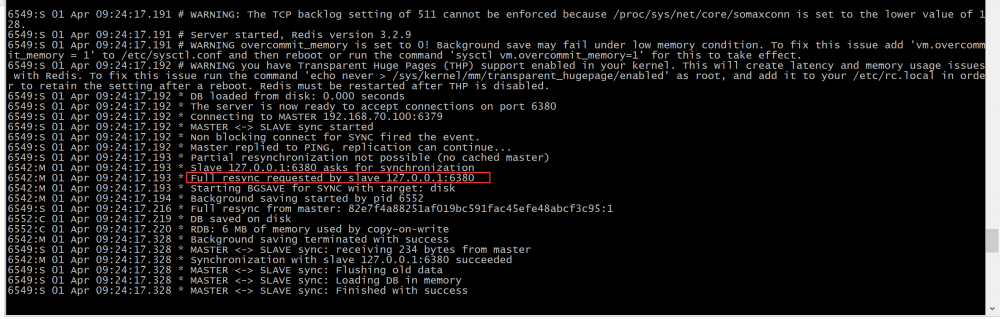
- slave向master发送sync命令。
- master开启子进程执行bgsave写入rdb文件,同时将子进程接收到的写命令缓存起来。
- 子进程写完,父进程得知,开始将RDB文件发送给slave。
- master发送完RDB文件,将缓存的命令也发给slave。
- master增量的把写命令发给slave。
(二)主从复制
在同一台机器上,启动两个redis,一个master,一个slave。
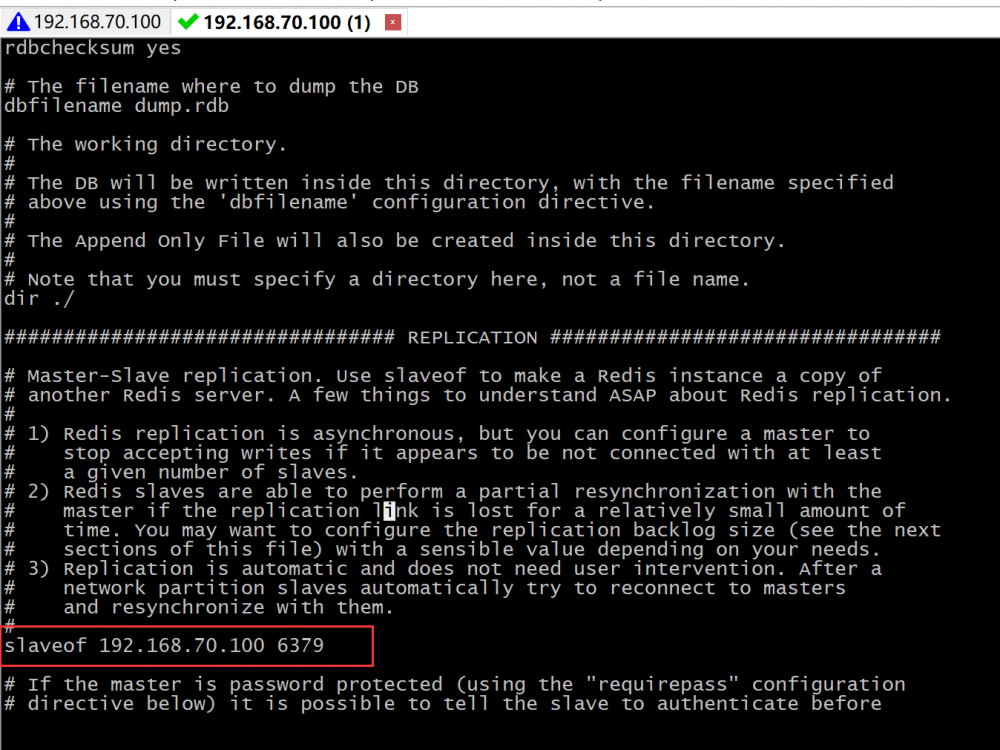
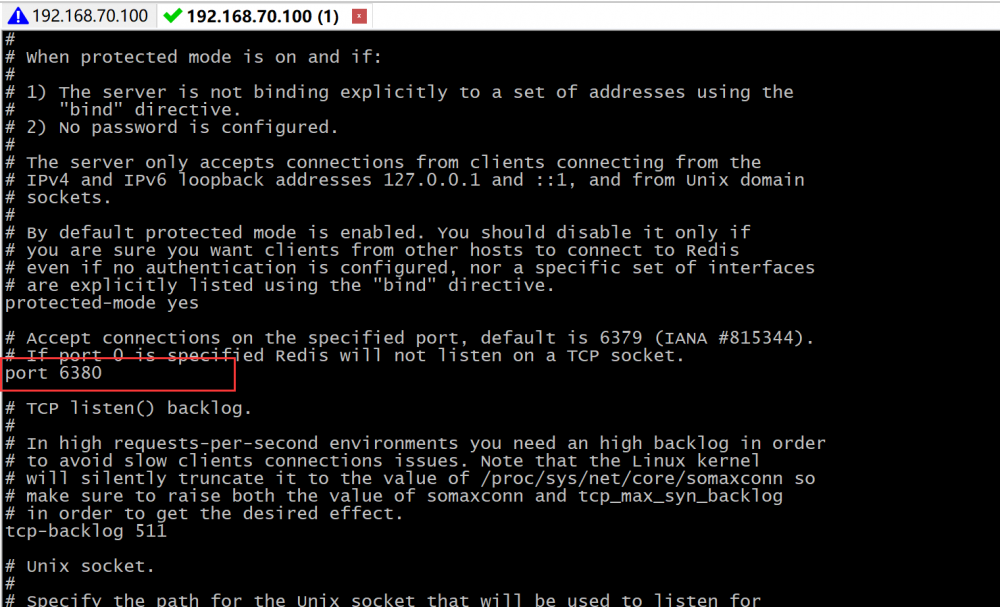
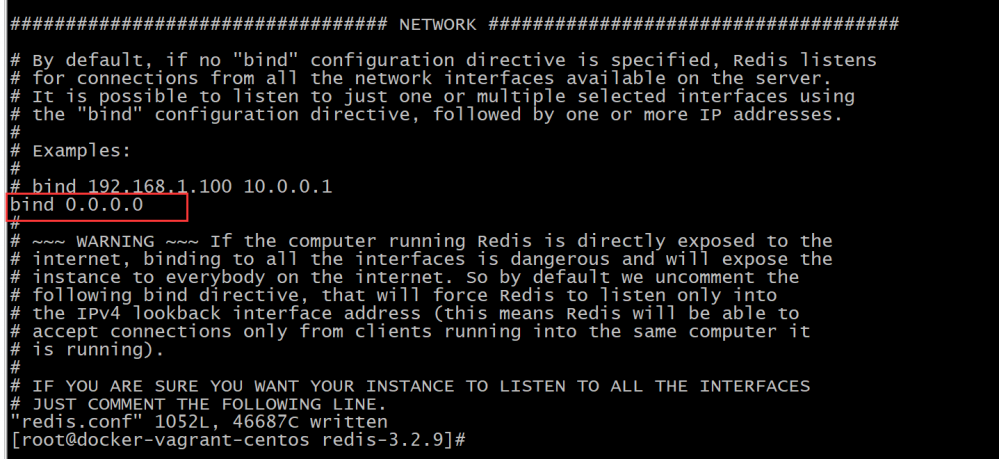
cp redis.conf redis-slave.conf pwd vi redis-slave.conf #更改slaveof # slaveof 192.168.70.100:6379 # port 6380 vi redis.conf #bind 0.0.0.0 #master ./bin/redis-server ./redis.conf & #slave ./bin/redis-server ./redis.conf & #slave的客户端 ./src/redis-cli -p 6380 #master的客户端 ./src/redis-cli -p 6379

-
测试
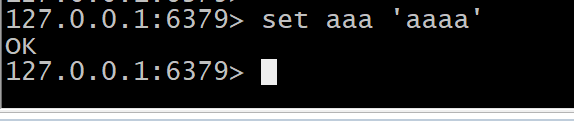
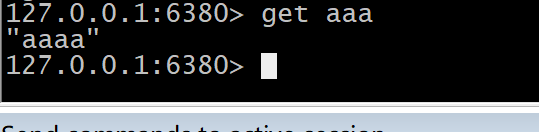
>master客户端set值,slave客户端能不能获取到
>6380 是slave的节点端口
>6379 是master的节点端口
#master set aaa 'aaaa' #slave get aaa config get 'slaveof*'
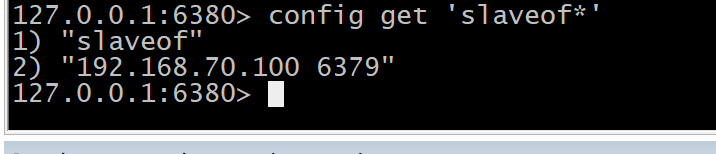
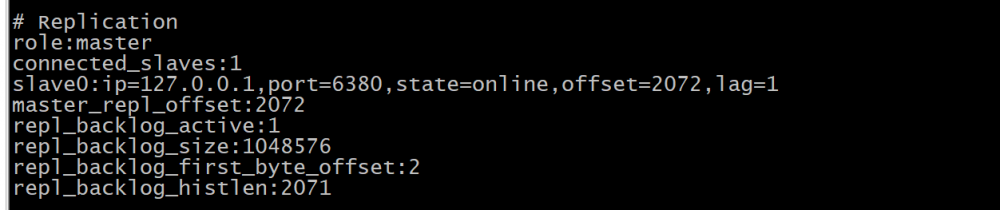
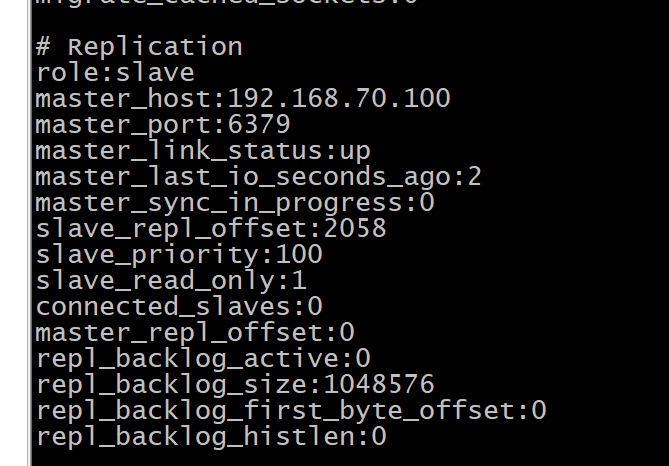
(二)集群
一个提供多个Redis(分布式)节点间共享数据的程序集。
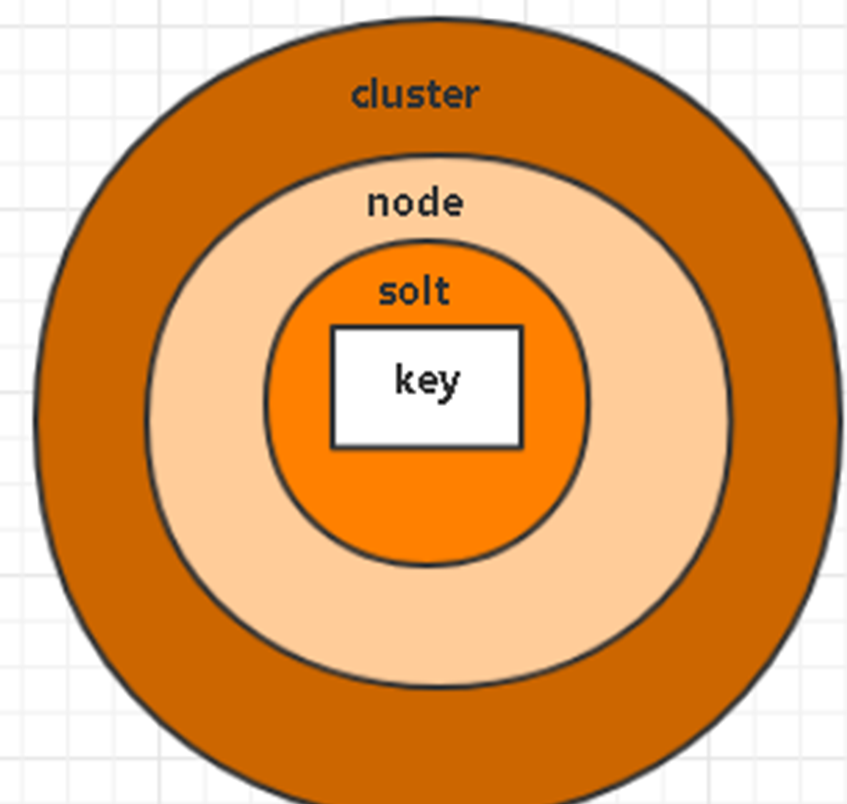
集群部署Redis 集群的键空间被分割为 16384 hash个槽(slot), 集群的最大节点数量也是 16384 个关系:cluster>node>slot>key。
-
分片
>Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;一个 Redis Cluster包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中,集群中的每个键都属于这16384个哈希槽中的一个,集群使用公slot=CRC16(key)/16384来计算key属于哪个槽,其中CRC16(key)语句用于计算key的CRC16 校验和。
按照槽来进行分片,通过为每个节点指派不同数量的槽,可以控制不同节点负责的数据量和请求数。
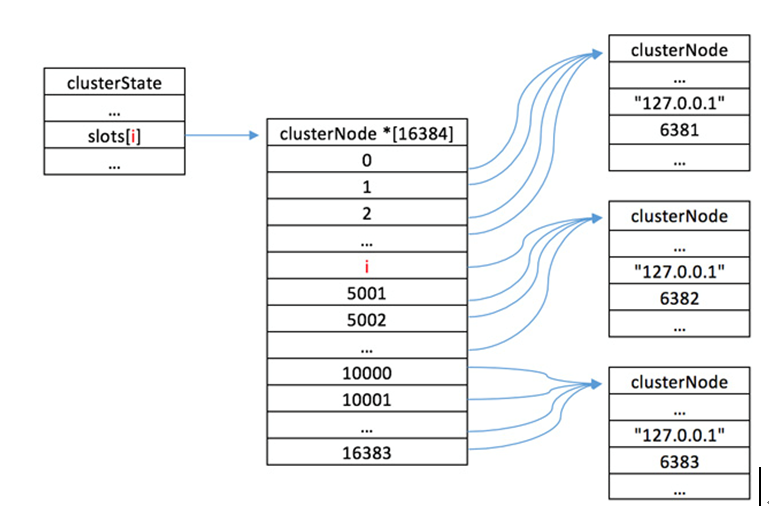
当前集群有3个节点,槽默认是平均分的
1. 节点 A (6381)包含 0 到 5499号哈希槽。
2. 节点 B (6382)包含5500 到 10999 号哈希槽。
3. 节点 C (6383)包含11000 到 16383号哈希槽。
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我像移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
-
数据迁移
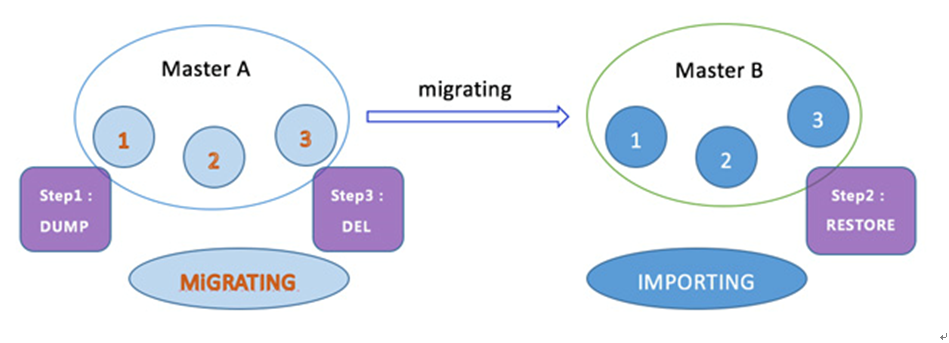
>数据迁移可以理解为slot(槽)和key的迁移,这个功能很重要,极大地方便了集群做线性扩展,以及实现平滑的扩容或缩容。
现在要将Master A节点中编号为1、2、3的slot迁移到Master B节点中,在slot迁移的中间状态下,slot 1、2、3在Master A节点的状态表现为MIGRATING(迁移),在Master B节点的状态表现为IMPORTING(入口)。

IMPORTING状态;被迁移slot 在目标Master B节点中出现的一种状态,准备迁移slot从Mater A到Master B的时候,被迁移slot的状态首先变为IMPORTING状态。
键空间迁移。
集群的节点内置了复制和高可用特性。
特点
1. 节点自动发现
2. slave->master 选举,集群容错
3. Hot resharding:在线分片
4. 基于配置(nodes-port.conf)的集群管理
5. 客户端与redis节点直连、不需要中间proxy层.
6. 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
PS:下次通过多台虚拟机搭建一套redis集群环境。这次主要了解下集群同步的原理和集群的扩展能力。
百度未收录
>>原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
>>原文链接地址:上一篇:已是最新文章
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

