Spring源码解读(1)-IOC容器BeanDefinition的加载
spring的两大核心:IOC(依赖注入)和AOP(面向切面),IOC本质上就是一个线程安全的hashMap,put和get方法就对应IOC容器的bean的注册和获取,spring通过读取xml或者使用注解配置的类生成一个BeanDefinition放入到容器中,获取的时候通过BeanDefinition的配置通过asm、反射等技术完成属性的注入最终获取一个bean,获取bean的方法就getBean(),我们无需关心实现细节,直接按照spring提供的注解或者xml配置方式使用即可。
2、IOC容器
虽然IOC本质上是一个线程安全的hashMap,使用时直接通过getBean()获取(@Autowired本质也是通过getBean()获取),这样在使用bean实例的时候,就不用关心bean的创建,只管用就行了,IOC会在程序启动时,自动将依赖的对象注入到目标对象中,非常简单,省心。但是如果不了解IOC中bean的注册和获取原理,当使用Spring无法获取一个bean的时候,针对抛出的异常可能一头雾水。
IOC容器的实现包含了两个非常重要的过程:
- xml的读取生成BeanDefinition注册到IOC中
- 通过BeanDefinition实例化bean,并从IOC中通过getBean()获取
//spring源码中将一个bean的BeanDefinition放入到IOC中 this.beanDefinitionMap.put(beanName, beanDefinition); 复制代码
//Spring源码中通过beanName获取一个bean
public Object getBean(String name) throws BeansException {
assertBeanFactoryActive();
return getBeanFactory().getBean(name);
}
复制代码
这两个过程还对应了两个非常核心的接口:
BeanDefinitionRegistry和BeanFactory,一个向IOC中注册BeanDefinition,一个从IOC获取Bean实例对象。
读IOC源码必须从了解BeanDefinition开始,BeanDefinition是一个接口,无论是通过xml声明还是通过注解定义一个bean实例,在IOC容器中第一步总是为其对应生成一个BeanDefinition,里面包含了类的所有基本信息。
其中AbstractBeanDefinition实现BeanDefinition,这个接口有两个子接口GenericBeanDefinition和RootBeanDefinition,再来看看BeanDefinition中的一些方法
-
getBeanClassName()获取bean的全限定名,
-
getScope()获取该类的作用域,
-
isLazyInit()该类是否为懒加载,
-
getPropertyValues()获取配置的属性值列表(用于setter注入),
-
getConstructorArgumentValues()获取配置的构造函数值(用于构造器注入)等bean的重要信息,如果通过注解的方式,还会包含一些注解的属性信息,
总而言之 ,BeanDefinition包含了我们定义的一个类的所有信息,然后通过 BeanDefinitionRegistry接口的registerBeanDefinition注册到IOC容器中,最后通过BeanDefinition结合asm,反射等相关技术,通过BeanFactory接口的getBean()获取一个实例对象好像也不是什么困难的事情了。当然这只是表层的大致原理,实际上spring在实现IOC的时候,用了大量的设计模式,比如:单例模式、模板方法、工厂模式、代理模式(AOP基本上全是)等,此外面向对象的基本原则中的单一职责、开放封闭原则等随处可见,具体的源码解读还是在之后的笔记里介绍。
3、读取xml配置文件
读取源码需要通过调试去看,Spring启动时首先会读取xml配置文件,xml文件可以从当前类路径下读,也可以从文件系统下读取,以下是用于调试的简单案例:
@Test
public void testSpringLoad() {
ClassPathXmlApplicationContext application = new ClassPathXmlApplicationContext("spring/spring-context.xml");
BankPayService bankPayService = (BankPayService) application.getBean("bankPayService");
Assert.assertNotNull(bankPayService);
}
复制代码
xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd"
default-lazy-init="true">
<bean id="bankPayService" class="com.yms.manager.serviceImpl.BankPayServiceImpl"/>
<context:property-placeholder location="classpath*:app-env.properties"/>
<context:component-scan base-package="com.yms.market"/>
</beans>
复制代码
执行测试案例,肯定是成功的,打断点开始调试,首先会进入ClassPathXmlApplicationContext的构造函数中:
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, ApplicationContext parent){
super(parent);
//获取当前环境 装饰传入的路径
setConfigLocations(configLocations);
if (refresh) {
//程序入口
refresh();
}
}
复制代码
构造函数中最关键的部分是refresh()方法,该方法用于刷新IOC容器数据,该方法由AbstractApplicationContext实现。
@Override
public void refresh() {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// 让子类去刷新beanFactory 进入这里查看
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}}}
复制代码
在refresh方法中主要完成了加载xml文件的环境配置、xml文件读取,注册BeanFactoryPostProcessor处理器、注册监听器等工作,其中比较核心的是第二行代码ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
//加载xml配置文件,生成BeanDefinition并注册到IOC容器中
refreshBeanFactory();
//获取加载完xml文件之后的beanFactory对象
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
复制代码
refreshBeanFactory和getBeanFactory都是由AbstractApplicationContext的子类AbstractRefreshableApplicationContext实现的,
@Override
protected final void refreshBeanFactory() throws BeansException {
//如果beanFactory不为空 ,清除老的beanFactory
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建一个beanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
//设置bean是否允许覆盖 是否允许循环依赖
customizeBeanFactory(beanFactory);
//加载beans声明,即读取xml或者扫描包 生成BeanDefinition注册到IOC
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
复制代码
在Spring中DefaultListableBeanFactory是一个非常重要的类,它实现了BeanDefinitionRegistry和BeanFactory接口,并且完成了这两个接口的具体实现,DefaultListableBeanFactory的类图如下:
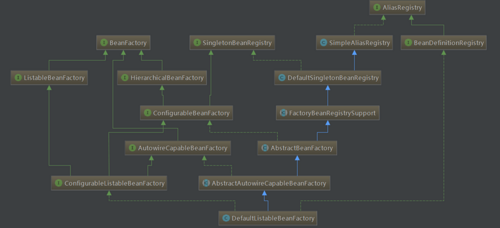
我们已经知道BeanDefinitionRegistry完成了BeanDefinition的注册,BeanFactory完成了getBean()中bean的创建,其中xml读取和bean的 注册的入口就是loadBeanDefinitions(beanFactory)这个方法,loadBeanDefinitions是一个抽象方法,由类AbstractXmlApplicationContext实现。loadBeanDefinitions在AbstractXmlApplicationContext有很多个重载方法,在不通阶段方法使用的参数值不同,接下来看看各个loadBeanDefinitions的调用顺序:
创建XmlBeanDefinitionReader对象
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//Spring将读取xml操作委托给了XmlBeanDefinitionReader对象
//并且传入DefaultListableBeanFactory将生成的beandefinition注册到IOC中
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
//设置Spring中bean的环境
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 设置beanDefinitionReader验证属性,子类可以重写该方法使用自定义reader对象
initBeanDefinitionReader(beanDefinitionReader);
//通过beanDefinitionReader读取xml
loadBeanDefinitions(beanDefinitionReader);
}
复制代码
Spring对于读取xml文件。并不是由DefaultListableBeanFactory亲力亲为,而是委托给了XmlBeanDefinitionReader,在该类内部会将xml配置文件转换成Resource,Spring封装了xml文件获取方式,我们使用ClassPathXmlApplicationContext读取xml,因此Spring会通过ClassLoader获取当前项目工作目录,并在该目录下查找spring-context.xml文件,当然我们还可以使用FileSystemXmlApplicationContext从文件系统上以绝对路径的方式读取文件
继续查看第二个loadBeanDefinitions(beanDefinitionReader):
获取配置文件路径集合
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
//默认返回为空 子类可以实现该方法 读取指定文件
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
//获取我们配置的xml文件路径集合
String[] configLocations = getConfigLocations();
if (configLocations != null)
{
reader.loadBeanDefinitions(configLocations);
}
}
复制代码
在这个方法中,最终获取到了我们通过ClassPathXmlApplicationContext对象传进来的xml配置文件路径,然后由进入委托对象XmlBeanDefinitionReader的loadBeanDefinitions方法中:
@Override
public int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException {
Assert.notNull(locations, "Location array must not be null");
int counter = 0;
for (String location : locations) {
//循环读取配置的所有配置文件路径
counter += loadBeanDefinitions(location);
}
//返回此次加载的BeanDefinition个数
return counter;
}
复制代码
在XmlBeanDefinitionReader中,会循环读取配置的所有配置文件路径,并将读取到的bean的声明创建成BeanDefinition,并将此次生成的数量返回,继续查看loadBeanDefinitions:
public int loadBeanDefinitions(String location, Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
//实际执行到这里
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
return loadCount;
}
}
复制代码
这个方法就是上面所说的Spring将xml配置文件封装成Resourse,最终获取到Resourse的过程,这部分代码没什么好看的,就是找到ClassPathResource将xml路径放进去,然后调用loadBeanDefinitions(resources),再来看这个方法:
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
复制代码
这个方法将Resource封装城了EncodedResource对象,这个对象有一个属性encoding,如果设置了xml文件的编码,在这里读取xml文件的时候会根据该编码进行读取,继续往下看:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
//获取前面加载到的xml配置资源文件
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//之所以将路径都封装到Resource里面,就是使其提供一个统一的getInputStream方法
//获取文件流对象,XmlBeanDefinitionReader无需关心xml文件怎么来的
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//终于来到了最最核心的方法 解析文件流
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
复制代码
spring的代码风格好像有一个特点,凡是真正开始做事的方法入口都会以do为前缀,经过前面一系列对xml配置文件的设置,终于来到了doLoadBeanDefinitions(inputSource, encodedResource.getResource()),在这个方法里Spring会读取每一个Element标签,并根据命名空间找到对应的NameSpaceHandler去读取解析Node生成BeanDefinition对象。经过一系列操作Resouse最终会被转换成InputSource对象,这个类也没什么特别的,只是除了文件流之外多了一些参数而已,比如XSD,DTD的publicId,systemId约束,文件流的编码等,最重要的还是InputStream,然后来看看这个方法:
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) {
//主要是校验文件 通过查找DTD文件约束 校验文件格式
//读取xml文件生成DOC
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
}
复制代码
这个方法完成两件事情:
-
通过inputSource生成Document对象
-
解析Document并将生成BeanDefinition注册到IOC中
4、解析DOC生成BeanDefinition
文件校验和生成DOC文档都是一些校验操作,如果想自定义DTD文档让Spring加载,后面还会细说这部分内容,暂且放下,现在主要是看看IOC的BeanDefinition的生成过程,接下来进入registerBeanDefinitions:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
//获取加载之前IOC容器中的BeanDefinition数量
int countBefore = getRegistry().getBeanDefinitionCount();
//具体解析 注册
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//返回本次加载的BeanDefinition数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
复制代码
在这个方法里,首先创建BeanDefinitionDocumentReader,这是个接口用于完成BeanDefinition向IOC容器注册的功能,Spring只提供了唯一的实现DefaultBeanDefinitionDocumentReader,查看registerBeanDefinitions:
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
//root 在这个测试里就是<beans></beans>
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
复制代码
该方法第一步首先回去xml的根节点,在这个测试xml里就是标签了,然后将根节点作为参数传入到下面的方法中解析doRegisterBeanDefinitions:
protected void doRegisterBeanDefinitions(Element root) {
//获取profile环境变量
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
Assert.state(this.environment != null, "Environment must be set for evaluating profiles");
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
//判断该root下的bean是否是前面通过web.xml或者前面设置的bean的环境值
//如果不是 不需要解析当前root标签
if (!this.environment.acceptsProfiles(specifiedProfiles)) {
return;
}
}
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(this.readerContext, root, parent);
//解析bean所要执行的方法,该方法实际是空的 允许子类扩展 去读取自定义的node
//属于模板方法
preProcessXml(root);
//真正解析beans的方法
parseBeanDefinitions(root, this.delegate);
//beans解析完之后需要执行的方法,实际也是通过子类扩展 是模板方法
postProcessXml(root);
this.delegate = parent;
}
复制代码
这个方法看起来很多,其实真正核心的只有两部分:
-
读取beans的profile属性,判断是否属于被激活的组,如果不是则不解析
-
创建BeanDefinitionParserDelegate,委托该类执行beans解析工作。
最后通过parseBeanDefinitions(root, this.delegate)方法将beans的解析交给BeanDefinitionParserDelegate
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//判断是否是默认的命名空间 也就是beans
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//判断是否是xml配置的bean,如果是则调用该方法解析
parseDefaultElement(ele, delegate);
}
else {
//否则按照自定义方式解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
//否则按照自定义方式解析
delegate.parseCustomElement(root);
}
}
复制代码
这个方法很重要,这里已经开始解析了,首先会判断,要解析的root是否是beans标签,如果是再判断子元素是否是元素,正常来讲,我们使用spring的时候都会再标签下配置,所以不出意外都会走到for循环里,然后在for循环里判断是否是默认命名空间的时候就会发生变化:
-
如果是则走parseDefaultElement(ele, delegate);
-
如果是
<mvc:annotation-driven>、 <context:component-scan base-package="***"/>等则会走到自定义元素解析delegate.parseCustomElement(ele)里
自定义解析加载到最后还是会跟加载默认命名空间的bean一样,所以在这里只分析自定义命名空间的解析,不过值得提一下的是自定义解析方法里会首先根据Element的命名空间找到NamespaceHandler,然后由该NamespaceHanler去解析
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
//获取元素的命名空间
String namespaceUri = getNamespaceURI(ele);
//获取命名空间解析器
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
//解析自定义元素
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
复制代码
由于后面会自己实现一个NamespaceHandler解析自定义的标签,会专门说明Spring如何查找NamespaceHandler以及如何解析自定义元素,这里只是了解下NamespaceHandler的概念即可,接着看Spring解析
查看parseDefaultElement:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
//解析 import
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
//解析alias
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
//解析bean
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// 如果还是beans 递归调用
doRegisterBeanDefinitions(ele);
}
}
复制代码
这个方法里面就是几个if判断,用于解析对应的标签,其中import alias相当于是去读取另一个xml文件,最后还是会调用解析bean,所以在这里只看解析bean的方法processBeanDefinition(ele, delegate):
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//将bean的属性都读取到到BeanDefinitionHolder上
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
//如果bean里面有自定义标签 来决定是否再次解析
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 将生成的BeanDefinitionHolder注册到IOC中
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 发送注册事件
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
复制代码
在这个方法里 ,之前分析的逻辑才逐渐清晰起来,代码的条例也很清晰
-
BeanDefinitionParserDelegate将bean标签的属性读取到BeanDefinitionHolder对象中
-
如果beans下还有其他自定义标签决定是否有必要再次解析
-
将BeanDefinition注册到IOC中
-
发送注册事件
首先来看第一步,读取node属性到BeanDefinitionParserDelegate中
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
//获取class全限定名
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
//设置beanClass或者beanClassName
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//读取node属性 将配置的属性 塞入合适的字段中
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
//记录lookup-method配置
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//记录replaced-method配置
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析构造函数(构造器注入)
parseConstructorArgElements(ele, bd);
//解析属性(setter注入)
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
finally {
this.parseState.pop();
}
return null;
}
复制代码
这个方法完成了读取一个bean包括将node属性读入到BeanDefinition,读取bean的构造函数配置(是构造器注入的前提),读取bean的属性配置(是setter注入的前提),其实将node属性读取到BeanDefinition很简单,仅仅是一一对应而已,真正的复杂点在于读取构造函数参数、读取属性值参数。
5、构造器和属性参数解析
来看下面一段配置:
<bean id="userDao" class="spring.road.beans.models.UserDao"/>
<!--setter注入-->
<bean id="beanService" class="spring.road.beans.models.BeanService">
<property name="mapper" ref="userDao"/>
<property name="name" value="lijinpeng"/>
<property name="sex" value="false"/>
</bean>
<!--构造器注入-->
<bean id="person" class="spring.road.beans.models.Person">
<constructor-arg name="age" value="26"/>
<constructor-arg name="name" value="dangwendi"/>
<constructor-arg name="userDao" ref="userDao"/>
<constructor-arg name="sex" value="true"/>
</bean>
复制代码
这段配置使用了两种注入方式:
property属性解析
setter注入就是我们通过为属性赋值,如果属性值都是string类型的还很好解决,如果pojo类的属性值不是String,而是比如像Boolean、int、Date等这些数据的时候,必须要进行数据转换操作才可以在getBean()的时候将property配置的属性通过反射注入到对应的字段里,这好像也不是什么困难的事情,但是如果是ref引用类型呢,这个问题该如何解决呢?Spring很巧妙的解决了这个问题,用RuntimeBeanReference来表示ref引用的数据,用TypedStringValue表示普通String字符串。既然一个pojo类的所有配置都会读取到BeanDefinition,所以在xml中配置的属性必然也会存储到BeanDefinition中,继续看源码会发现BeanDefinition中用MutablePropertyValues类表示属性集合,该类中propertyValueList就是property集合数据,Spring用PropertyValue存储了property的name value信息。
//在BeanDefinition类中 MutablePropertyValues getPropertyValues(); //在MutablePropertyValues类中的属性 private final List<PropertyValue> propertyValueList; //在PropertyValue中的属性 private final String name; private final Object value; 复制代码
根据上面xml配置可以得知value可能需要类型转换,也可能是引用ref,鉴于getBean阶段无法直接赋值,所以需要一个中间类保存数据,在getBean()反射阶段根据类型去转换成对象,再次查看parsePropertyElements方法:
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//解析bean下的property属性节点
if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {
parsePropertyElement((Element) node, bd);
}
}
}
复制代码
parsePropertyElement解析bean下的property属性节点
public void parsePropertyElement(Element ele, BeanDefinition bd) {
//获取property的name 这个很简单
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
if (!StringUtils.hasLength(propertyName)) {
error("Tag 'property' must have a 'name' attribute", ele);
return;
}
this.parseState.push(new PropertyEntry(propertyName));
try {
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
//获取获取property的value 这个需要用中间类表示
Object val = parsePropertyValue(ele, bd, propertyName);
PropertyValue pv = new PropertyValue(propertyName, val);
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}
finally {
this.parseState.pop();
}
}
复制代码
山重水复疑无路,柳暗花明又一村,下面方法即是实现过程:
public Object parsePropertyValue(Element ele, BeanDefinition bd, String propertyName) {
String elementName = (propertyName != null) ?
"<property> element for property '" + propertyName + "'" :
"<constructor-arg> element";
// Should only have one child element: ref, value, list, etc.
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// Child element is what we're looking for.
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
subElement = (Element) node;
}
}
}
//是否有ref属性
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
//是否有value属性
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
//ref和value只能存在一个
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
//如果是ref 则转换成RuntimeBeanReference
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(ele));
return ref;
}
else if (hasValueAttribute) {
//如果是String则转换成TypedStringValue
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
valueHolder.setSource(extractSource(ele));
return valueHolder;
}
else if (subElement != null) {
return parsePropertySubElement(subElement, bd);
}
else {
// Neither child element nor "ref" or "value" attribute found.
error(elementName + " must specify a ref or value", ele);
return null;
}
}
复制代码
看有注释行的代码,结合上面的分析,大概能了解setter注入的第一阶段BeanDefinition保存属性数据的方式了,在调用BeanFactory的getBean()方法时,在反射阶段获取到值对象时可以根据类型去获取值,如果是TypedStringValue则只需校验值是否应该转换,如果需要转换即可,至于如何转换,如果是RuntimeBeanReference更简单了,直接通过getBean()获取就好了,请记住这两个类型,在分析getBean()阶段属性值解析的时候就会用到他们。
构造函数constructor-arg解析
构造器注入其实比setter注入要稍微麻烦一点,之所以说麻烦其实就是要借助相关技术去实现,因为构造器可能会有很多重载,在xml配置中如果参数顺序不同可能会调用不同的构造函数,导致注入失败,所以如果要保存构造参数值,必须匹配到唯一合适的构造函数,并且在xml配置的constructor-arg必须按照一定规则与匹配的构造函数一一对应,才可以在getBean()阶段注入成功。
当我自己尝试去写的时候,以为只需要通过反射获取构造函数的参数名即可,但是很不幸,通过反射拿到的参数名是诸如arg1 arg2 这样的name,所以只能通过读取类的字节码文件了, 以前看过《深入了解java虚拟机》这本书,知道可以通过读取字节码文件的方式获取参数名,但是里面的各种索引,字段表集合啊什么的想记住真的好难,而且我的水平还远远达不到那个高度,所以就用现成的吧, 我当时是用javassite实现的,看了spring的源码,发现spring是用asm实现的,当然这个阶段是在getBean()阶段实现的,之所以介绍是因为必须要先了解为什么Spring要这么保存构造参数,后面的getBean在分析这块源码,还是先来看看构造函数参数在BeanDefinition的保存吧。
spring允许在xml中通过index、name、type来指定一个参数,在BeanDefinition中使用ConstructorArgumentValues存储构造函数参数集合,在ConstructorArgumentValues包含了两个集合一个配置了索引的indexedArgumentValues参数集合,另一个没有配置索引的genericArgumentValues构造函数参数集合,然后构造函数参数值用内部类ValueHolder表示,这个类里包含了参数的value,类型,参数名等。
//在BeanDefinition类中 ConstructorArgumentValues getConstructorArgumentValues(); //在ConstructorArgumentValues类中 //使用了索引的构造函数参数值集合 private final Map<Integer, ValueHolder> indexedArgumentValues = new LinkedHashMap<Integer, ValueHolder>(0); //未使用索引的构造函数参数值集合 private final List<ValueHolder> genericArgumentValues = new LinkedList<ValueHolder>(); //在ValueHolder中的属性 private Object value; private String type; private String name; private Object source; 复制代码
构造函数参数的存储结构分析完了,接下来看看代码吧,其实存储和属性值的存储是一样的 ,这里只看关键的代码:
public void parseConstructorArgElements(Element beanEle, BeanDefinition bd) {
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (isCandidateElement(node) && nodeNameEquals(node, CONSTRUCTOR_ARG_ELEMENT)) {
parseConstructorArgElement((Element) node, bd);
}
}
}
复制代码
解析constructor-arg标签parseConstructorArgElement
public void parseConstructorArgElement(Element ele, BeanDefinition bd) {
//获取index
String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);
//获取type
String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);
//获取name
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//如果index不为空 保存到indexedArgumentValues集合中
if (StringUtils.hasLength(indexAttr)) {
try {
int index = Integer.parseInt(indexAttr);
if (index < 0) {
error("'index' cannot be lower than 0", ele);
}
else {
try {
this.parseState.push(new ConstructorArgumentEntry(index));
//将value转换成RuntimeBeanReference或者TypedStringValue
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
//保存type
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
//保存name
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {
error("Ambiguous constructor-arg entries for index " + index, ele);
}
else {
//保存构造函数参数值
bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);
}
}
finally {
this.parseState.pop();
}
}
}
catch (NumberFormatException ex) {
error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);
}
}
//index未配置 保存到普通集合中genericArgumentValues
else {
try {
this.parseState.push(new ConstructorArgumentEntry());
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
//保存构造函数参数值
bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);
}
finally {
this.parseState.pop();
}
}
}
复制代码
至此,一个xml配置的bean被完全存放到了BeanDefinition中,其实基于扫描注解配置也是一样的,只不过在做很多清理工作,针对下面配置简要说明下基于注解的处理:
<context:component-scan base-package="com.yms.market"/> 复制代码
-
首先spring读取到这个node,会查找该node的NameSpaceHandler,然后调用parse方法解析
-
然后读取到属性base-package,转换成对应路径后查找该路径下所有的class文件
-
读取class文件的注解,查看是否实现了特定注解,如果实现了注解则处里方式与xml配置的处理相同,否则不处理。
真实的处理过程比较复杂,也是用了很多设计模式,用了很多类来处理,但是我想说的是,无论是用过注解还是通过xml,最终的处理方式都是一样的,都是先生成一个BeanDefinition注册到IOC中,然后通过getBean()获取。
6、BeanDefinitionRegistry注册
BeanDefinition创建完成了,还差最后一步,将生成的BeanDefinition注册到IOC中,这就必须往回看了。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//将bean的属性都读取到到BeanDefinitionHolder上
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
//如果bean里面有自定义标签 来决定是否再次解析
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 将生成的BeanDefinitionHolder注册到IOC中
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 发送注册事件
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
复制代码
这段代码应该还很熟悉,这次看最后一步registerBeanDefinition
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 获取beanName
String beanName = definitionHolder.getBeanName();
//注册BeanDefinition,key为beanName,value是BeanDefinition
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 如果配置别名的话获取别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String aliase : aliases) {
//注册别名
registry.registerAlias(beanName, aliase);
}
}
}
复制代码
该方法完成了以下事情
- 将BeanDefinition用beanName作为key注册到IOC容器中
- 如果配置了别名,将beanName与别名映射起来。
再来看具体的注册过程registry.registerBeanDefinition,注册是调用BeanDefinitionRegistry的registerBeanDefinition方法,在刚开始的分析说过DefaultListableBeanFactory实现了BeanDefinitionRegistry和BeanFactory,而且实现了具体逻辑,下面的内容就是Spring注册的过程,为了看的清晰我省去了很多异常和无用的代码:
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
{
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
//验证
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
}
}
//这里保证了线程安全
synchronized (this.beanDefinitionMap) {
BeanDefinition oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!this.allowBeanDefinitionOverriding) {
//不允许覆盖抛出异常
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
if (this.logger.isWarnEnabled()) {
}
else {
if (this.logger.isInfoEnabled()) {
}
}
}
else {
this.beanDefinitionNames.add(beanName);
this.frozenBeanDefinitionNames = null;
}
//注册进去喽
this.beanDefinitionMap.put(beanName, beanDefinition);
}
resetBeanDefinition(beanName);
}
复制代码
到此为止,IOC容器的第一步为bean生成BeanDefinition并注册到IOC容器中完成,接下来就是第二步,通过BeanFactory实现依赖注入了。
正文到此结束
- 本文标签: Listeners ioc 本质 synchronized web db cat 代码 解析 list ACE bean bug 字节码 递归 java node 线程 IDE App value Service id equals 自定义标签 spring tab description 数据 CTO key http Property 文件系统 LinkedList tag 目录 源码 tar 调试 CEO XML entity BeanDefinition AOP 索引 HashSet classpath https UI 空间 实例 src 处理器 IO HashMap 类图 测试 struct 配置 设计模式 DOM schema message mapper token stream ssl ip map 注释 Document final 监听器 ORM Lua Qualifier root 安全 基本原则 parse 参数
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

