微服务--整体...
微服务 ---- “微”? “服务”?
微 : 体积小
服务 : 不同于系统 , 服务一个或者一组相对较小且独立的功能单元 ,是用户可以感知到的最小单位 !
广义 : 分布式系统解决方案,推动细粒度服务的使用,让这些服务协同合作!
《微服务》 与 《微服务框架》 的区别?
微服务架构 : 是将复杂的系统使用组件化的方式进行拆分,并使用轻量级通讯方式(protobuf)进行整合的一种设计方法。
微服务 :是通过 《微服务架构》这种架构方法拆分出来的一个独立的组件化的小应用。
微服务架构定义的精髓 ---- “分而治之,合而用之”
将复杂的事情拆分成小事情来做 , 通过轻量级通讯等方式把拆分的东西进行整合,使微小的功能合起来做大事情 。 ----- 例如,积木,机甲合体之类的。
《单体架构》 缺点 :
1、复杂性逐渐变高 :巨多的代码,各个模块之间区别比较模糊,逻辑不够用清晰,代码越多越复杂,遇到的问题越难解决。
2、技术债务逐渐上升 :公司人员流动,before 留下的坑 , 由于“ 复杂性逐渐变高 ”的原因,使 new 很难发现和解决.............在人员流动的这个长期过程中,问题逐渐变多,变大,变难------这就是 技术债务逐渐上升 !
3、维护成本大 :应用程序功能越来越多、团队越来越大时,沟通成本、管理成本显著增加。复杂性的逐渐提升,导致在维护时修改bug容易引入新的bug。
4、持续交付周期长 :随着代码变多,变复杂,任何一个修改都有可能踩坑,一旦踩坑,就会拖延交付的时间...
5、技术选型成本高 :单体架构倾向于采用统一的技术平台获方案来解决所有问题,如果想引进新的技术或方法,成本和风险都很大。
6、可扩展性差 :随着功能的增加,垂直扩展的成本将会越来越大;而对于水平扩展而言,因为所有代码都运行在同一个进程,没办法做到针对应用程序的部分功能做独立的扩展。
《微服务架构的特性》优点:
1、单一职责 :微服务架构中的每个服务,都是具有业务逻辑的,符合高内聚、低耦合原则以及单一职责原则的单元,不同的服务通过“管道”的方式灵活组合,从而构建出庞大的系统。
2、轻量级通讯 :( protobuf ) 服务之间通过轻量级的通信机制实现互通互联,而所谓的轻量级,通常指语言无关、平台无关的交互方式。
3、独立性 : 每个服务在应用交付过程中,独立地开发、测试和部署。
4、进程隔离 : 在微服务架构中,应用程序由多个服务组成,每个服务都是高度自治的独立业务实体,可以运行在独立的进程中,不同的服务能非常容易地部署到不同的主机上。
《微服务架构的特性》缺点:
1、运维要求极高 : 对于单体架构来讲,我们只需要维护好这一个项目就可以了,但是对于微服务架构来讲,由于项目是由多个微服务构成的,每个模块出现问题都会造成整个项目运行出现异常,想要知道是哪个模块造成的问题往往是不容易的,因为我们无法一步一步通过debug的方式来跟踪,这就对运维人员提出了很高的要求。
2、分布式的复杂性 :对于单体架构来讲,我们可以不使用分布式,但是对于微服务架构来说,分布式几乎是必会用的技术,由于分布式本身的复杂性,导致微服务架构也变得复杂起来。
3、接口调整成本高 :比如,用户微服务是要被订单微服务和电影微服务所调用的,一旦用户微服务的接口发生大的变动,那么所有依赖它的微服务都要做相应的调整,由于微服务可能非常多,那么调整接口所造成的成本将会明显提高。
4、重复劳动 :对于单体架构来讲,如果某段业务被多个模块所共同使用,我们便可以抽象成一个工具类,被所有模块直接调用,但是微服务却无法这样做,因为这个微服务的工具类是不能被其它微服务所直接调用的,从而我们便不得不在每个微服务上都建这么一个工具类,从而导致代码的重复。
选择《微服务架构》的理由!
1、开发简单 :微服务架构将复杂系统进行拆分之后,让每个微服务应用都开放变得非常简单,没有太多的累赘。对于每一个开发者来说,这无疑是一种解脱,因为再也不用进行繁重的劳动了,每天都在一种轻松愉快的氛围中工作,其效率也会整备地提高。
2、快速响应需求变化 :一般的需求变化都来自于局部功能的改变,这种变化将落实到每个微服务上,二每个微服务的功能相对来说都非常简单,更改起来非常容易,所以微服务非常适合敏捷开发方法,能够快速的影响业务的需求变化。
3、随时随地更新 :一方面,微服务的部署和更新并不会影响全局系统的正常运行;另一方面,使用多实例的部署方法,可以做到一个服务的重启和更新在不易察觉的情况下进行。所以每个服务任何时候都可以进行更新部署。
4、系统更加稳定可靠 :微服务运行在一个高可用的分布式环境之中,有配套的监控和调度管理机制,并且还可以提供自由伸缩的管理,充分保障了系统的稳定可靠性。
protocol buffer ---- 轻量级通讯方式
简介 :
Google Protocol Buffer (简称 Protobuf )是google旗下的一款轻便高效的结构化数据存储格式,平台无关、语言无关、可扩展,可用于通讯协议和数据存储等领域。所以很适合用做数据存储和作为不同应用,不同语言之间相互通信的数据交换格式,只要实现相同的协议格式即同一 proto文件被编译成不同的语言版本,加入到各自的工程中去。这样不同语言就可以解析其他语言通过 protobuf序列化的数据。目前官网提供了 C++,Python,JAVA,GO等语言的支持。google在2008年7月7号将其作为开源项目对外公布。
tips :
啥叫平台无关? Linux 、 mac 和 Windows 都可以用,32位系统,64位系统通吃
啥叫语言无关? C++ 、 Java 、 Python 、 Golang 语言编写的程序都可以用,而且可以相互通信那啥叫可扩展呢?就是这个数据格式可以方便的增删一部分字段啦~
最后啥叫序列化啊?解释得通俗点儿就是把复杂的结构体数据按照一定的规则编码成一个字节切片
protobuf的优势与劣势优势 :
优势 :
1:序列化后体积相比Json和XML很小,适合网络传输
2:支持跨平台多语言 3:消息格式升级和兼容性还不错
4:序列化反序列化速度很快,快于Json的处理速度
劣势 :
1:应用不够广(相比xml和json)
2:二进制格式导致可读性差
3:缺乏自描述
GRPC
gRPC 是一个高性能、开源和通用的 RPC 框架,面向移动和 HTTP/2 设计。
gRPC基于 HTTP/2标准设计,带来诸如双向流、流控、头部压缩、单 TCP连接上的多复用请求等特。这些特性使得其在移动设备上表现更好,更省电和节省空间占用。
具体:
在 gRPC里客户端应用可以像调用本地对象一样直接调用另一台不同的机器上服务端应用的方法,使得您能够更容易地创建分布式应用和服务。与许多 RPC系统类似, gRPC也是基于以下理念:
1、定义一个服务,指定其能够被远程调用的方法(包含参数和返回类型)。
2、在服务端实现这个接口,并运行一个 gRPC服务器来处理客户端调用。
3、在客户端拥有一个存根能够像服务端一样的方法。 gRPC客户端和服务端可以在多种环境中运行和交互 -从 google内部的服务器到你自己的笔记本,并且可以用任何 gRPC支持的语言 来编写。
RPC
RPC(Remote Procedure Call Protocol) ——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
简单来说,就是跟远程访问或者web请求差不多,都是一个client向远端服务器请求服务返回结果,但是web请求使用的网络协议是http高层协议,而rpc所使用的协议多为TCP,是网络层协议,减少了信息的包装,加快了处理速度。
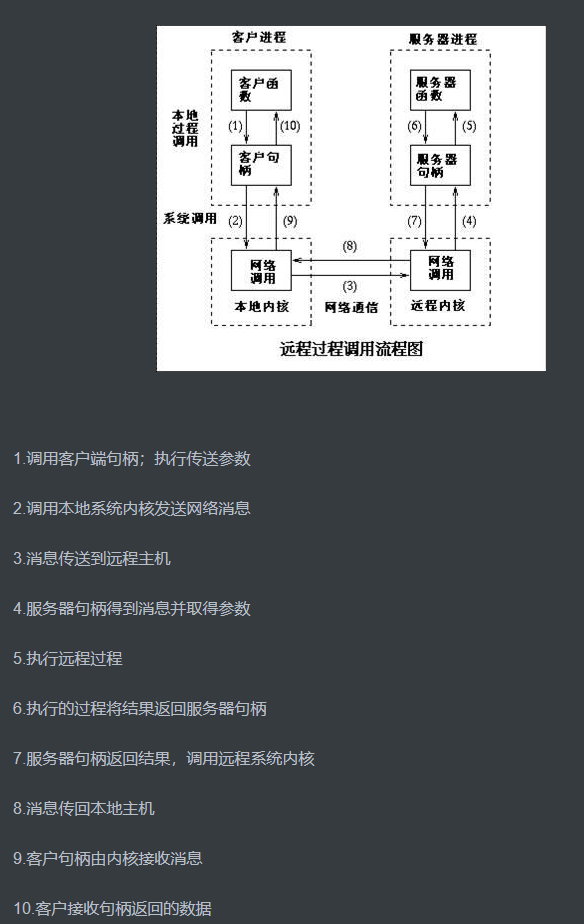
grpc的实例运行顺序
服务发现
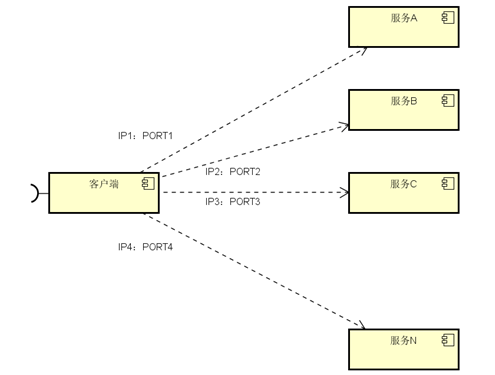
图中,客户端的一个接口,需要调用服务A-N。客户端必须要知道所有服务的网络位置的,以往的做法是配置是配置文件中,或者有些配置在数据库中。这里就带出几个问题:
需要配置N个服务的网络位置,加大配置的复杂性
服务的网络位置变化,都需要改变每个调用者的配置
集群的情况下,难以做负载(反向代理的方式除外)
总结起来一句话:服务多了,配置很麻烦,问题多多
那么,就产生了 服务发现 :下图

与之前一张不同的是,加了个 服务发现 模块。图比较简单,这边文字描述下。
服务A-N把当前自己的网络位置注册到服务发现模块(这里注册的意思就是告诉),服务发现就以K-V的方式记录下,K一般是服务名,V就是IP:PORT。服务发现模块定时的轮询查看这些服务能不能访问的了(这就是健康检查)。客户端在调用服务A-N的时候,就跑去服务发现模块问下它们的网络位置,然后再调用它们的服务。这样的方式是不是就可以解决上面的问题了呢?客户端完全不需要记录这些服务网络位置,客户端和服务端完全解耦!
下面的例子有助于我们理解服务发现的形式:
例如:
邮递员去某公司一栋大楼投递快件,向门卫询问员工甲在哪一个房间,门卫拿起桌上的通讯录查询,告知邮递员员工甲在具体什么位置。假如公司来了一个员工乙,他想让邮递员送过来,就要先让门卫知道自己在哪一个房间,需要去门卫那边登记,员工乙登记后,当邮递员向门卫询问时,门卫就可以告诉邮递员员工乙的具体位置。门卫知道员工乙的具体位置的过程就是服务发现,员工乙的位置信息可以被看作服务信息,门卫的通讯录就是上文中提到的数据交换格式,此例中员工乙就是上文的已方,门卫就是服务发现的提供者。
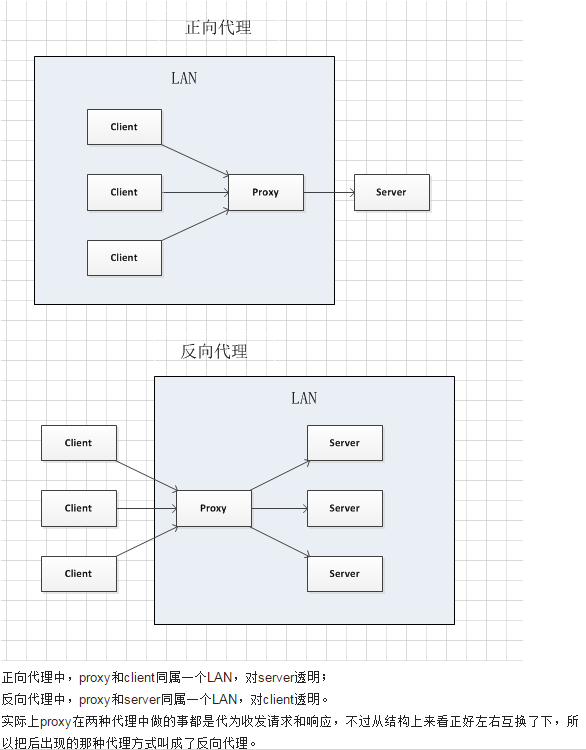
正向代理
正向代理 ,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。所以已知我们目标的原始服务。
反向代理
反向代理 是代理服务器的一种。服务器根据客户端的请求,从其关系的一组或多组后端服务器(如Web服务器)上获取资源,然后再将这些资源返回给客户端,客户端只会得知反向代理的IP地址,而不知道在代理服务器后面的服务器簇的存在
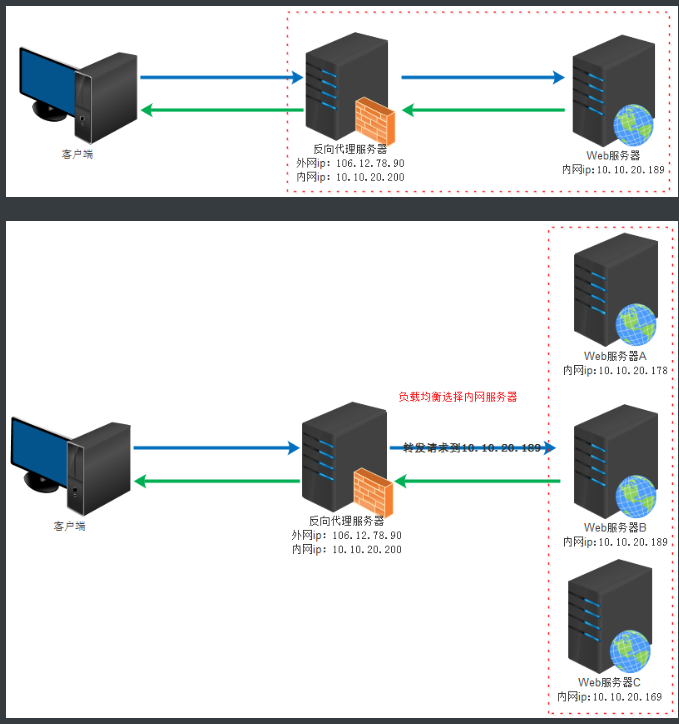
负载均衡
负载均衡 (Load Balance) 其意思就是分摊到多个操作单元上进行执行,例如Web 服务器 、 FTP服务器 、 企业 关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。
Consul
一套微服务框架中有多个服务需要管理,也就是说会有多个 gRPC , 一个一个管理会很繁琐,所以我们需要一个管理发现的机制。 ---------- Consul
所谓 Consul 是啥 ?
Consul是
HashiCorp 公司推出的
开源工具 ,
用于实现分布式系统的服务发现与配置 。 Consul是
分布式的、高可用的、可横向扩展的 。
它具备以下特性 :
服务发现 :consul通过DNS或者HTTP接口使服务注册和服务发现变的很容易,一些外部服务,例如saas提供的也可以一样注册。
健康检查 :健康检测使consul可以快速的告警在集群中的操作。和服务发现的集成,可以防止服务转发到故障的服务上面。
键/值存储 :一个用来存储动态配置的系统。提供简单的HTTP接口,可以在任何地方操作。
多数据中心 :无需复杂的配置,即可支持任意数量的区域。
运行 Consul代理 :Consul是典型的 C/S架构,可以运行服务模式或客户模式。每一个数据中心必须有至少一个服务节点, 3到5个服务节点最好。非常不建议只运行一个服务节点,因为在节点失效的情况下数据有极大的丢失风险。
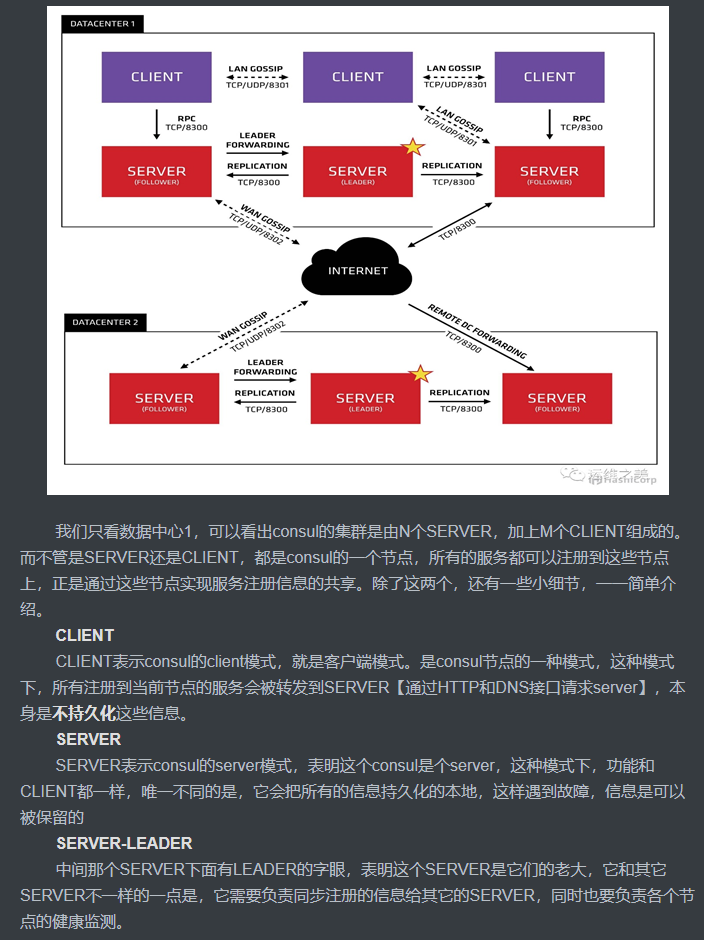
Consul的client mode把请求转向server,那么client的作用是什么?
consul可以用来实现分布式系统的服务发现与配置。client把服务请求传递给server,server负责提供服务以及和其他数据中心交互。题主的问题是,既然server端提供了所有服务,那为何还需要多此一举地用client端来接收一次服务请求。我想,采用这种架构有以下几种理由:
首先 server端的网络连接资源有限。对于一个分布式系统,一般情况下访问量是很大的。如果用户能不通过client直接地访问数据中心,那么数据中心必然要为每个用户提供一个单独的连接资源(线程,端口号等等),那么server端的负担会非常大。所以很有必要用大量的client端来分散用户的连接请求,在client端先统一整合用户的服务请求,然后一次性地通过一个单一的链接发送大量的请求给server端,能够大量减少server端的网络负担。
其次 ,在client端可以对用户的请求进行一些处理来提高服务的效率,比如将相同的请求合并成同一个查询,再比如将之前的查询通过cookie的形式缓存下来。但是这些功能都需要消耗不少的计算和存储资源。如果在server端提供这些功能,必然加重server端的负担,使得server端更加不稳定。而通过client端来进行这些服务就没有这些问题了,因为client端不提供实际服务,有很充足的计算资源来进行这些处理这些工作。
最后还有一点 ,consul规定只要接入一个client就能将自己注册到一个服务网络当中。这种架构使得系统的可扩展性非常的强,网络的拓扑变化可以特别的灵活。这也是依赖于client—server结构的。如果系统中只有几个数据中心存在,那网络的扩张也无从谈起了。
Micro
Micro解决了构建云本地系统的关键需求。它采用了微服务体系结构模式,并将其转换为一组工具,作为可伸缩平台的构建块。Micro隐藏了分布式系统的复杂性,并为开发人员提供了很好的理解概念。
Micro是一个专注于简化分布式系统开发的微服务生态系统。是一个工具集合, 通过将微服务架构抽象成一组工具。隐藏了分布式系统的复杂性,为开发人员提供了更简洁的概念。
关于插件化
Go Micro跟其他工具最大的不同是它是插件化的架构,这让上面每个包的具体实现都可以切换出去。举个例子,默认的服务发现的机制是通过Consul,但是如果想切换成etcd或者zookeeper 或者任何你实现的方案,都是非常便利的。
正文到此结束
- 本文标签: 开发者 需求 敏捷 企业 分布式 反向代理 远程访问 端口 数据库 代码 XML 服务端 缓存 java windows UI HTTP/2 json 开源 python consul 云 测试 负载均衡 配置 Google 实例 总结 http 服务注册 linux 协议 DNS zookeeper 管理 解析 开发 主机 bug 编译 js 房间 移动设备 空间 参数 src 专注 部署 服务器 https 集群 开源项目 TCP 快的 client 分布式系统 微服务 FTP服务 ip 进程 数据 时间 插件 ftp 高可用 正向代理 web remote 线程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

