手动造一个线程池(Java)
本次自己实现一个简单的线程池,主要是为了后续看 ThreadPool 的源码做准备的,是从别人的代码中改进的,从看别人的源码中学到一些东西,所以特意把这篇文章写出来,方便以后自己去回顾自己是如何学习。当然也希望分享出来可以对别人产生良好的影响!

使用Java的线程池
在自己实现一个线程池之前,首先要知道怎么用。因为知道怎么用之后才能去理解一些代码的编写。关于怎么用这里就不再多加赘述了,百度或者谷歌一下就好,为了不让读者花过多的时间去找,我找了一篇文章,说得比较清楚。
总览
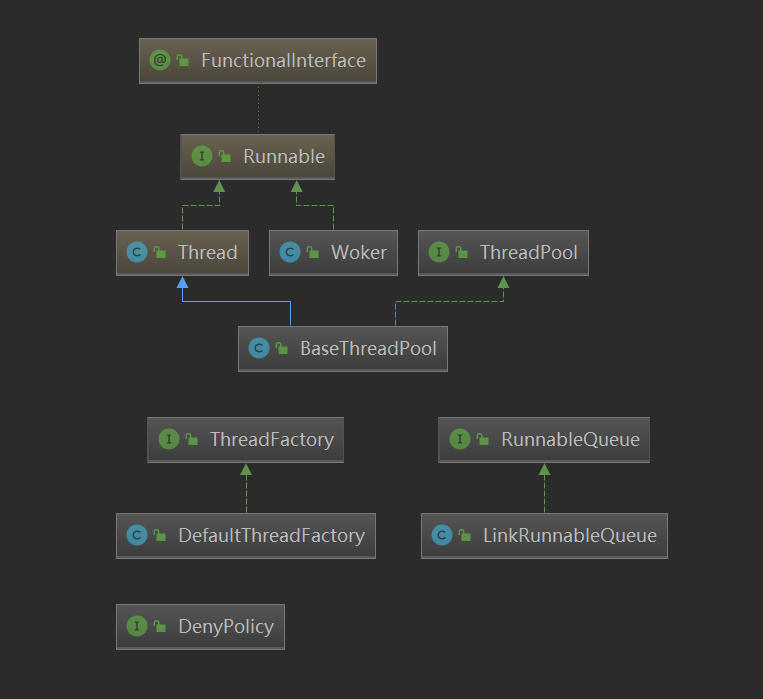
我们可以看到,除了 Thread 和 Runnable ,其他都是我们自己定义的,下面我们来逐一说明。
在我们开始分析之前,先说下线程池的工作流程,也方便大家后面看的时候心理有一个底。
线程池顾名思义就是一个存放多个线程的池子。那么在计算机语言中,我们就是用数据结构来存放线程,在本线程池中用的是一个队列来存放要处理任务的线程。所以在线程池一启动,线程池里面就应该有一定数量的线程数目了,那么这个线程的数目是多少我们先不用管,只需要知道有一些线程在等待用户把所需要线程执行的任务放进池子里面。然后线程池里面的线程就会自动帮你执行任务啦。
当然有些人说,我执行一个任务就创建一个线程就好了呀,何必大费周章呢。我们需要知道,来一个任务就创建一个线程,
-
创建线程需要时间 ,影响响应速度。
-
系统资源有限,如果有数以万计的线程需要创建,会大大消耗系统资源,会降低系统的稳定性。
其实有很多任务的时候,有些线程只是处理一些很轻的任务,很快就完成了,那么如果下一个任务刚好到达的时候,之前的线程也刚好完成工作了,那么这个线程就顺便接下到来的任务,这样的话岂不是提高了响应速度,然后又重复利用了线程,降低系统资源的损耗。岂不是一举两得。
之前都是恰巧,那么我们稍微放宽一点条件。如果线程执行完任务了,就先别退出呗。而是在等待执行任务,这个线程就可以看做被赋予 执行任务 的命令!**就等着任务来,任务一来,我就去执行。任务执行结束,线程就等,直到下一个任务来。周而复始,直到手动关闭!**这就是线程池的本质。
那么问题来了,线程池里面只有5个线程在等待执行任务,可是同时来了10个任务需要执行,那么有5个任务被执行了,剩下那5个放哪里?难道被丢弃?这可不是我们设计线程池的初衷!你肯定可以想到,肯定是拿一样数据结构去存储剩下的线程呀!(我们用队列存储,然后称为工作队列。)因为线程处理任务的时间是不一定的,肯定是有些线程处理的快,有些慢。所以谁先处理的快,谁就去处理剩下的任务。正所谓能者多劳!
再抛出一个问题,假如前面5个线程执行得很慢,那么后面那5个线程就需要等很久,这时候还不如直接创建线程去操作呢,没错,线程池在设计的时候也想到过这个问题,关于这个问题在后面我们设计的时候会说道,这里就先往下看吧!
既然涉及到多线程,那么肯定就涉及到同步的问题,对哪个对象需要同步呢?当然是任务队列啦。我们需要知道很有可能同时会有很多个线程对 同一个任务队列 取任务和放任务的,所以为了实现同步,我们这里用了 synchronized 关键字实现同步,也就是对这个任务队列加一把锁,哪个线程可以拿到操作任务队列的锁哪个线程就可以领取任务。没拿到这把锁的线程就死等,除非被中断或者手动关闭。
这里需要注意的是 挂起阻塞 和 等待拿锁 的区别。
-
挂起阻塞是该线程拿到锁之后调用
await方法才会进入的状态,前提是先拿到锁。被通知之后就会被唤醒,然后从await之后的代码执行。 -
等待拿锁是别的线程还在占有锁,此时的线程还没拿到锁,就会进入这个锁的entrySet序列等待,直到锁被释放然后再去抢,抢到为止!
经过上面的讲解,我们可以基本了解了线程池的设计思想和原理,下面补充点内容。
-
线程池内部有两个数据结构(队列)分别存放需要 执行任务的线程 (也叫工作线程)和所需要被**执行的任务*。
-
线程池初始化的线程放在 工作队列 里面,用户想要执行的任务放在 任务队列
-
在用户添加任务之后,会通知工作队列的线程去取任务啦!
-
工作队列的线程如果有空并且任务队列不为空,哪个线程拿到锁哪个线程就可以在任务队列取任务,然后任务队列的任务数就-1。
-
很多个线程去拿锁的时候,只能有一个线程拿到。 其他没拿到锁的线程不是阻塞等待,而是等待拿锁!
-
如果拿到锁之后任务队列为空,就挂起阻塞。如果被通知唤醒,继续执行3 4 5 6操作。
先看看我们这个整个线程池的流程图,这样设计的时候就知道怎么回事了!
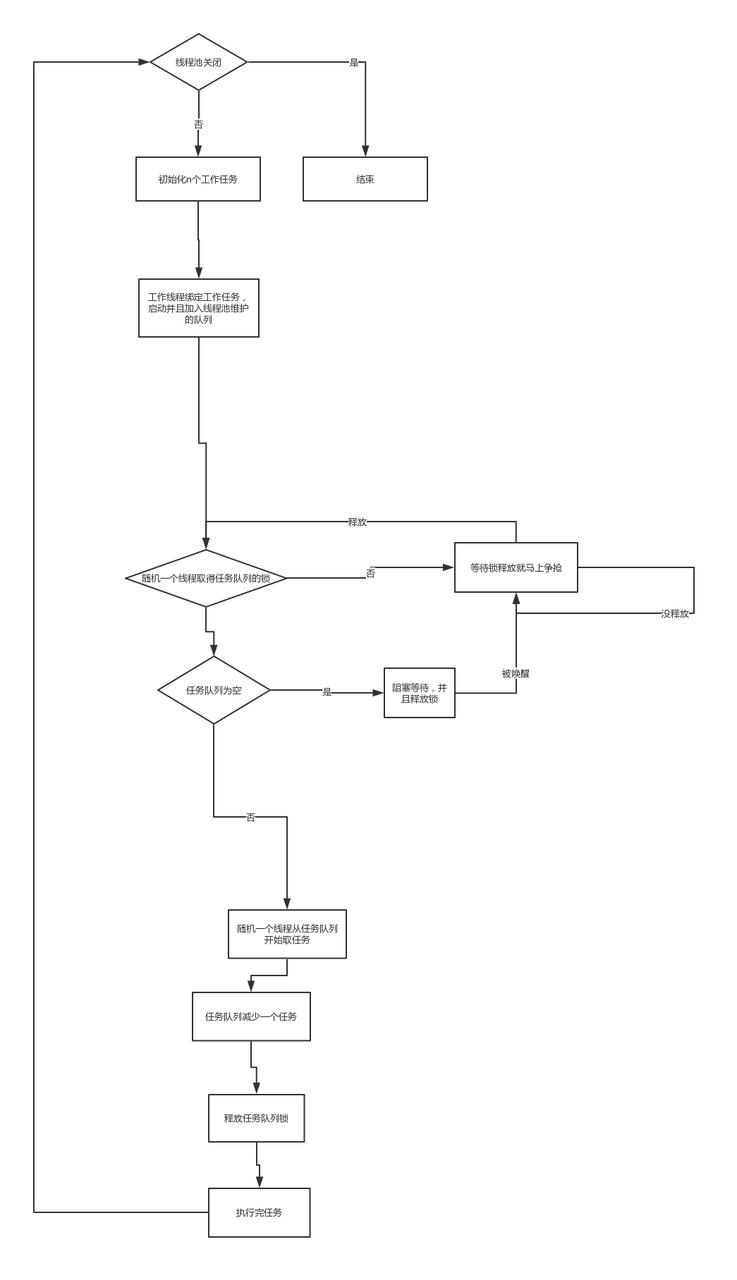
过程
BaseThreadPool
先看看这个类的基本属性
public class BaseThreadPool extends Thread implements ThreadPool {
/*初始化线程数*/
private int initSize;
/*最大工作线程数*/
private int maxSize;
/*核心线程数*/
private int coreSize;
/*当前活跃线程数*/
private int activityCount = 0;
/*指定任务队列的大小数*/
private int queueSize;
/*创建工作线程的工厂,在构造方法由线程池规定好*/
private ThreadFactory threadFactory;
/*1. 任务队列,在构造方法由线程池规定好*/
private RunnableQueue runnableQueue;
//2. 工作队列
private final static Queue<ThreadTask> threadQueue = new ArrayDeque<>();
//3. 本线程池默认的拒绝策略
private final static DenyPolicy DEFAULT_DENY_POLICY = new DenyPolicy.IgnoreDenyPolicy();
/*4. 默认的线程工厂*/
private final static ThreadFactory DEFAULT_THREAD_FACTORY =new DefaultThreadFactory();
/*线程池是否关闭,默认为false*/
boolean isShutdown = false;
private long keepAliveTime;
private TimeUnit timeUnit ;
复制代码
由上面的属性我们知道,我们自定义的线程池这个类是依赖于几个类的。
依次是 RunnableQueue , DenyPolicy , ThreadFactory 。
并且由总览图我们知道, BaseThreadPool 是实现了我们定义的 ThreadPool 接口和继承了Thread类,并且重写了run方法
run 里面的逻辑到后面再分析,这里可以先跳过这里。
@Override
public void run() { // BaseThreadPool
while (!isShutdown && !isInterrupted()){
try {
timeUnit.sleep(keepAliveTime);
} catch (InterruptedException e) {
//到这里就是关闭线程池了
isShutdown = true;
continue;
}
// 这里同步代码块,保证了每次访问的时候都是最新的数据!
synchronized (this){
if(isShutdown) break;
// 任务队列不为空,并且当前可以工作的线程小于coreCount,那么说明工作线程数不够,就先增加到maxSize
// 比如说coreSize 为20,initSize为10,maxSize 为30,
// 突然一下子来了20分线程进来,但是工作线程只有15个,由于某种原因可能那15个工作现场还没执行完,那么此时的任务队列肯定还有剩余的,发现此时线程还没到coreSize
// 那么就直接开maxSize个线程先把
if(runnableQueue.size() > 0){
for (int i = runnableQueue.size(); i < maxSize; i++) {
newThread();
}
}
// 任务队列为空,并且当前可以工作的线程数大于coreCount,工作线程数太多啦!那么就减少到coreCount
if(runnableQueue.size() == 0 && activityCount > coreSize){
for (int i = coreSize; i < activityCount; i++) {
removeThread();
}
}
}
}
}
复制代码
我们先来看下BaseThreadPool的构造方法
//1 用户传入初始化线程数,最大线程数,核心线程数,和任务队列的大小即可
public BaseThreadPool(int initSize, int maxSize, int coreSize,int queueSize) {
/*这里创建线程的工厂和拒绝策略都是用自己定义好的对象*/ this(initSize,maxSize,coreSize,queueSize,DEFAULT_THREAD_FACTORY,DEFAULT_DENY_POLICY,10,TimeUnit.SECONDS);
}
// 2
public BaseThreadPool(int initSize, int maxSize, int coreSize, int queueSize, ThreadFactory threadFactory, DenyPolicy denyPolicy, long keepAliveTime, TimeUnit timeUnit) {
this.initSize = initSize; //初始化线程池的初始化线程数
this.maxSize = maxSize; // 初始化线程池可以拥有最大的线程数
this.coreSize = coreSize; // 这个值的意义后面说
this.threadFactory = threadFactory; //初始化创建线程池的工厂
//自定义存放任务的队列
this.runnableQueue = new LinkRunnableQueue(queueSize,denyPolicy,this); //RunnableQueue的实现类,自己定义
this.keepAliveTime = keepAliveTime;
this.timeUnit = timeUnit;
this.init(); //初始化函数
}
// ---init()
public void init(){
/*启动本线程池*/
this.start();//BaseThreadPool 继承了 Thread,原因后面说
/*初始化initSize个线程在线程池中*/
for (int i = 0; i < initSize; i++) {
newThread();
}
}
// newThread()
public void newThread(){
/*创建工作线程,然后让工作线程等待任务到来被唤醒*/
Woker woker = new Woker(runnableQueue);
Thread thread = threadFactory.createThread(woker);
/*将线程和任务包装在一起*/
ThreadTask threadTask = new ThreadTask(thread,woker);
threadQueue.offer(threadTask);
this.activityCount++;
/*启动刚才新建的线程*/
thread.start();
}
// 再看看DefaultThreadFactory,就是
/*工厂创建一个新的线程*/
public class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger GROUP_COUNTER = new AtomicInteger(0); //线程组号
//计数
private static AtomicInteger COUNTER = new AtomicInteger(1);
private static final ThreadGroup group = new ThreadGroup("MyThreadPool-" + GROUP_COUNTER.getAndIncrement());
@Override
public Thread createThread(Runnable runnable) {
return new Thread(group,runnable,"threadPool-" + COUNTER.getAndIncrement());
}
}
复制代码
这里说明一下,我们是可以这样 new Thread(new Runnable(){....}).start 创建并且启动线程的。就是调用 Thread 需要传入一个 Runnable 实例的构造函数实例化 Thread 类,通过重写 Runnable 里面的 run 方法就可以指定线程在启动的时候需要做的事。
我们看到 DefaultThreadFactory 就只有一个创建线程的方法,就是把线程启动后需要做的任务指定一下和重命名一下线程,就是用上面说明的方法。所以传给需要传给 createThread 方法一个实现 Runnable 的类。而这个类就是 Woker
我们看下Woker的代码
//------------Woker BaseThreadPool依赖的类
/*工作线程的任务*/
public class Woker implements Runnable{
/*任务队列,方便后面取出任务*/
private RunnableQueue runnableQueue;
/*方便判断该内部任务对应的线程是否运行,确保可见性!*/
private volatile boolean running = true;
public Woker(RunnableQueue runnableQueue) {
this.runnableQueue = runnableQueue;
}
@Override
public void run() {
/*当前对应的线程正在运行并且没有被中断*/
while (running && !Thread.currentThread().isInterrupted()){
//调用take的时候,如果任务队列没任务就会阻塞在这,直到拿到任务
Runnable task = runnableQueue.take();
task.run();
}
}
public void stop(){
running = false;
}
}
复制代码
我们看到 run 方法,这个任务就是去到 任务队列 里面取任务,然后执行。直到当前工作停止或者当前线程被中断。而这个 任务队列 就是我们在调用构造函数的时候指定的对象,也就是这段代码
this.runnableQueue = new LinkRunnableQueue(queueSize,denyPolicy,this);
接下来看下 LinkRunnableQueue 是怎么实现的
public class LinkRunnableQueue implements RunnableQueue{//BaseThreadPool依赖的类
//指定任务队列的大小
private int limit;
//也是使用BaseThreadPool传进来的默认拒绝策略
private DenyPolicy denyPolicy;
//这里传进BaseThreadPool实例
private ThreadPool threadPool;
//这个就是真正存储Runnable实例对象的数据结构!也就是一个链表
private LinkedList<Runnable> queue = new LinkedList<>();
//构造函数,也就是初始化这个类的属性
public LinkRunnableQueue(int queueSize,DenyPolicy denyPolicy,ThreadPool pool) {
this.limit = queueSize;
this.denyPolicy = denyPolicy;
this.threadPool = pool;
}
//任务队列添加任务,这个方法一般由线程池的execute方法调用
@Override
public void offer(Runnable runnable) {
//因为任务队列只有一个,可能会有多个线程同时操作任务队列,所以要考虑同步问题
//取得queue的锁才能加入任务,拿不到所就进入queue的entrySet
synchronized (queue){
if(queue.size() > limit){
//如果此时任务队列超过限制的值,那么就拒绝!
denyPolicy.reject(runnable,threadPool);
}else{
//把任务加入到任务队列呗
queue.addLast(runnable);
//唤醒等待的线程,这些线程在queue的waitSet里面,要结合take方法
queue.notifyAll();
}
}
}
//线程从任务队列里面拿任务,如果拿不到就会阻塞,直到有任务来并且抢到
@Override
public Runnable take() {
//这里之前也说过了,要先拿到锁才能拿任务
synchronized (queue){
//如果任务队列为空,那么肯定拿不了,所以就等待呗
while (queue.size() == 0){
try {
//这个线程在这里就等待让出锁,直到执行offer方法从而被唤醒,然后
//再重新抢到锁,这里是个循环,如果被唤醒后,也抢到锁了,但是队列
//还是空的话,继续等待
queue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//到这里执行这个方法的线程就是抢到锁了,然后得到任务啦!
return queue.removeFirst();
}
}
//返回调用该方法时任务队列有多少个任务在等待
@Override
public int size() {
synchronized (queue){
return queue.size();
}
}
}
复制代码
代码的注释已经解释得很清楚了,这里主要是了解为什么Work中的 Runnable task = runnableQueue.take() 中没有任务会阻塞等待,本质就是
1 拿到queue对象锁之后,任务队列没任务,释放掉真正存储任务的对象的对象锁,从而进入该对象的waitSet队列里面等待被唤醒。
2 当然如果没拿到锁也会一直等待拿到锁,然后像1一样.
如果看到这里看不太明白的,大家可以先回去看一下java线程的基本知识和 synchronized 的详解,这样可以更好地把知识串联起来!
接下来我们再看下 工作队列 是什么样子。
ThreadTask在BaseThreadPool的一个内部类
//把工作线程和内部任务绑定在一起
class ThreadTask{
Thread thread;
Woker woker;
public ThreadTask(Thread thread, Woker woker) {
this.thread = thread;
this.woker = woker;
}
}
复制代码
从上面的代码我们知道,ThreadTask就是把一个工作线程和一个工作线程的任务封装在一起而已,这里主要是为了后面 线程池关闭 的时候可以让线程需要做的任务停止!
线程池关闭的操作 , BaseThreadPool 类的方法
/*shutdown 就要把 Woker 给停止 和 对应的线程给中断*/
@Override
public void shutDown() {
synchronized (this){
if(isShutDown())
return;
//设置标志位,让线程池线程也执行完run方法,然后退出线程。
isShutdown = true;
/*全部线程停止工作*/
for (ThreadTask task: threadQueue
) {
//1 这里就是把Woker实例对象的running置为false
task.woker.stop();
//2 中断执行对应任务的线程
task.thread.interrupt();
}
}
}
复制代码
可以看到关闭线程池,就是遍历存放工作线程的队列, 1和2都是破坏Woker对象的while循环条件 ,从而让Woker对象的 run 方法执行结束。(这里大家可以看下Woker这个类的 run 方法就明白我说的了)
我们在开始的时候说过, BaseThreadPool 启动的时候其实也是一个线程,在它的 init 方法中就调用了 start 方法表示执行 run 里面的逻辑,之前我们看了run的代码,但是没分析,现在就来分析吧
@Override
public void run() { //BaseThreadPool类的方法
//还记得shutDown()方法里面的 isShutdown = true语句吗?
//作用就是为了让这里下一次判断while循环的时候退出,然后执行完run啦!
while (!isShutdown && !isInterrupted()){
try {
timeUnit.sleep(keepAliveTime);
} catch (InterruptedException e) {
//如果线程池这个线程被中断
//到这里就是关闭线程池了,也是把isShutdown设置为我true!
isShutdown = true;
continue;
}
// 这里同步代码块,保证了每次访问的时候都是最新的数据!
synchronized (this){
if(isShutdown) break;
//任务队列不为空,并且当前可以工作的线程小于coreCount,那么说明工作 //线程数不够,就先增加到maxSize.
//比如说coreSize 为20,initSize为10,maxSize 为30,
//突然一下子来了20分线程进来,但是工作线程只有15个,由于某种原因可能
//那15个工作现场还没执行完,那么此时的任务队列肯定还有剩余的,发现此
//时线程还没到coreSize
//那么就直接开maxSize个线程先把
//如果发现现在工作的的线程已经过了coreSize就先不增加线程数啦
if(runnableQueue.size() > 0 && activityCount < coreSize){
for (int i = runnableQueue.size(); i < maxSize; i++) {
newThread();
}
}
// 任务队列为空,并且当前可以工作的线程数大于coreCount,工作线程数太多啦!那么就减少到coreCount基本大小把
if(runnableQueue.size() == 0 && activityCount > coreSize){
for (int i = coreSize; i < activityCount; i++) {
removeThread();
}
}
}
}
}
//----------removeThread()
// 线程池中去掉某个工作线程,这里的操作是不是很类似shutDown的内容
public void removeThread(){
this.activityCount--;
ThreadTask task = threadQueue.remove();
task.woker.stop();//就是破坏Woker对象的while循环的条件
}
复制代码
上面的注释讲解的比较清楚,有啥不懂的多看几篇,自己模拟一下思路就好啦!
在 run 方法中,重要的是关于线程池中的线程数量的动态变化的部分。
coreSize:线程池基本的大小,相当于一个分界线
initSize:线程池的初始化大小,这枚啥好说的
activityCount:当前工作线程的数量
maxSIze:线程池中最大的线程数目
说一下它们之间的关系
任务队列不为空的情况下
-
activityCount < coreSize的时候,就说明线程池的数量没到达基本大小,就新增线程,直接新增到最大!
-
activityCount >= coreSize的时候,说明当前线程池的工作线程数量已经到达基本大小,有任务来就需要等一下啦!
注意:这里的扩容机制只是简单地扩容,Java中实现的线程池并不是像我说那样扩容的,这就解决了开头的问题啦,具体的到时候还是分析源码的时候再说把!这里只是简单地实现一下!
测试
测试代码
package blogDemo.ThreadDemo;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class Test {
public static void main(String[] args) {
ThreadPool threadPool = new BaseThreadPool(4,30,6,30);
for (int i = 0; i < 20; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " is running and done.");
});
}
}
}
复制代码
测试结果
总结
本片文章就写到这里啦,大家看文章的时候可以一边看源码一边看解释,这样会更加容易理解,希望对读者后面理解java自带线程池有所帮助,下一篇文章就分析java自带的线程池的源码啦!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

