到处是map、flatMap,啥意思?
最近入职一个有趣的年轻同事,提交了大量大量的代码。翻开git记录一看,原来是用了非常多的 java8 的语法特性,重构了代码。用的最多的,就是 map 、 flatMap 之类的。 但是其他小伙伴不愿意了,虽然有的人感觉代码变的容易懂了,但有更多的人感觉代码变的很晦涩。 那感觉就像是:脱了裤子放屁,多此一举。
这些函数的作用域,根据级别,我觉得可以分为三类。
简直是无所不在。
不要过分使用
我也不知道这些函数是从什么时候流行起来的,但它们与函数编程的关系肯定是非常密切的。好像是2004年的Scala开始的。
没什么神奇的,它们全部是语法糖,作用是让你的程序更简洁。你要是想,完全可以用多一点的代码去实现。不要为了炫技刻意去使用,物极必反,用不好的话,产生的效果会是非常负面的。比如java,它并不是一门函数编程语言,那么 lambda 就只是一种辅助;而你用java那一套去写 Lisp 代码的话,也只会不伦不类。
但语言还是要融合的,因为潮流就是这样。不去看他们背后的设计,我们仅从api的语义表象,横向看一下它们所表达的东西。
我们首先看一下其中的共性(注意:逻辑共性,并不适合所有场景),然后拿几个典型的实现,看一下在这个星球上,程序员们的表演。
这些抽象的概念
这些函数的作用对象,据说是一种称之为流的东西。那 流 到底是一种什么东西呢?请原谅我用一些不专业的话去解释。
不论是在语言层面还是分布式数据结构上,它其实是一个简单的数组。它有时候真的是一个简单的数组,有时候是存在于多台机器的分布式数组。在下文中,我们统称为 数组流 。
我们简单分为两类。
语言层面的:比如Java的Stream 分布式层面的:比如Spark的RDD 复制代码
它们都有以下几个比较重要的点。
函数可以作为参数
C语言当然是没问题的,可以把函数作为指针传入。但在不久之前,在Java中,这还得绕着弯子去实现(使用java概念中的Class去模拟函数,你会见到很多Func1、Func0这样奇怪的java类)。
函数作参数,是使得代码变得简洁的一个必要条件。我们通常的编程方法,大多是顺序执行一些操作。
array = new Array()
array = func1(array)
if(func2(array)){
array = func3(array)
}
array = func4(array)
复制代码
而如果函数能够当参数,我就能够尽量的将操作平铺。最终,还是要翻译成上面的语句进行执行的。
array = new Array() array.stream() .map(func1) .filter(func2) .flatMap(func3) .sorted(func4) ... 复制代码
编程模式完全变了,函数也有了语义。
sequential & parallel
如果我们的 数组流 太大,对于单机来说,就有顺序处理和并行处理两种方式。
通常,可以通过 parallel 函数进入并行处理模式。对于大多数本地操作,开了并行不见得一定会快。 java中使用ForkJoin那一套,线程的速度,你知道的...
而对于分布式数据流来说,本来就是并行的,这种参数意义就不大了。
函数种类
一般作用在数据流上的函数,会分为两类。
转换。Transformation 动作。Action 复制代码
转换,典型的特点就是 lazy 。 只有 action 执行的时候,才会真正参与运算。所以,你可以认为这些转换动作是一套被缓冲的操作。典型的函数如:map、flatMap等。它们就像烤串一样被串在一起,等着被撸。
动作。真正触发代码的运行,上面的一系列转换,也会像开了闸的洪水一样,一泻而下。典型的如 reduce 函数,就是这种。
以上的描述也不尽然,比如python的map,执行后就可以输出结果。这让人很没面子啊。
map & reduce
谈到map和reduce,大家就不约而同的想到了hadoop。然而,它不仅仅是大数据中的概念。
对于它俩的概念,我们仅做下面两行介绍。
map
将传入的函数依次作用到序列的每个元素,并把结果作为新的 数组流 返回。
reduce
reduce类似于一个递归的概念。最终会归约成一个值。看看这个公式:)
reduce([p1,p2,p3,p4],fn) = reduce([fn(p2,p4),fn(p1,p3)]) 复制代码
具体还是看谷歌的经典论文吧。
《MapReduce: Simplified Data Processing on Large Clusters》 ai.google/research/pu…
你能访问么?:)
map & flatMap
这两个函数经常被使用。它们有如下区别:
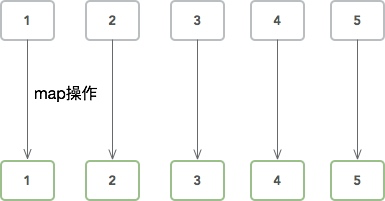
map
把 数组流 中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素个数相同的 数组流 。
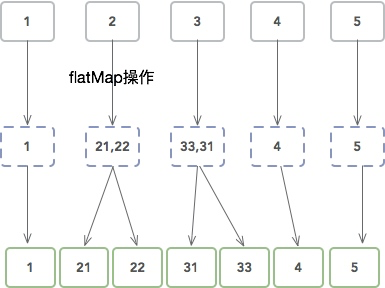
flatMap
flat是扁平的意思。它把 数组流 中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素相同的 数组流 。只不过,里面的元素也是一个子 数组流 。把这些子数组合并成一个数组以后,元素个数大概率会和原 数组流 的个数不同。
程序员们的表演
java8种的Stream
java8开始,加入了一个新的抽象,一个称之为流的东西:Stream。配合lambda语法,可以使代码变的特别的清爽、干净(有木有发现都快成了 Scala 了)。
一个非常好的向导: stackify.com/streams-gui…
Spark的RDD操作
spark的核心数据模型就是RDD,是一个有向无环图。它代表一个不可变、可分区、其内元素可并行计算的集合。 它是分布式的,但我们可以看下一个 WordCount 的例子。
JavaRDD<String> textFile = sc.textFile("hdfs://...");
JavaPairRDD<String, Integer> counts = textFile
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
counts.saveAsTextFile("hdfs://...");
复制代码
多么熟悉的Api啊,你一定在Hadoop里见过。
Flink 的 DataStream
Flink程序是执行分布式集合转换(例如,filtering, mapping, updating state, joining, grouping, defining windows, aggregating)的常规程序。Flink中的DataStream程序是实现在数据流上的transformation。
我们同样看一下它的一段代码。
DataStream<Tuple2<String, Integer>> counts = // split up the lines in pairs (2-tuples) containing: (word,1) text.flatMap(new Tokenizer()) // group by the tuple field "0" and sum up tuple field "1" .keyBy(0).sum(1); 复制代码
kafka stream的操作
kafka已经变成了一个分布式的流式计算平台。他抽象出一个 KStream 和 KTable ,与Spark的RDD类似,也有类似的操作。
KStream可以看作是KTable的更新日志(changlog),数据流中的每一个记录对应数据库中的每一次更新。
我们来看下它的一段代码。
KTable<String, Long> wordCounts = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("//W+")))
.groupBy((key, value) -> value)
.count();
wordCounts.toStream().to("streams-wordcount-output", Produced.with(stringSerde, longSerde));
复制代码
RxJava
RxJava是一个基于观察者模式的异步任务框架,经常看到会被用到Android开发中(服务端采用的也越来越多)。
RxJava再语言层面进行了一些创新,有一部分忠实的信徒。
语言层面的lambda
当然,对 Haskell 这种天生的函数编程语言来说,是自带光环的。但其他的一些语言,包括脚本语言,编译性语言,也吸收了这些经验。
它们统称为lambda。
Python
作为最流行的脚本语言,python同样也有它的lambda语法。最基本的map、reduce、filter等函数同样是存在的。
JavaScript
js也不能拉下,比如 Array.prototype.*() 等。它该有的,也都有了。
正文到此结束
- 本文标签: Hadoop 数据库 API list Word 服务端 递归 翻译 大数据 value http IO 编译 js 数据 key ask ORM stream java https UI Android src Action lambda git map 程序员 Java类 JavaScript token ip apr App 开发 scala 模型 windows HDFS 代码 参数 python 分布式 tab 线程 Google 谷歌 数据模型 id
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

