服务端架构演进
先来看一看服务端架构的1.0版本:
架构介绍
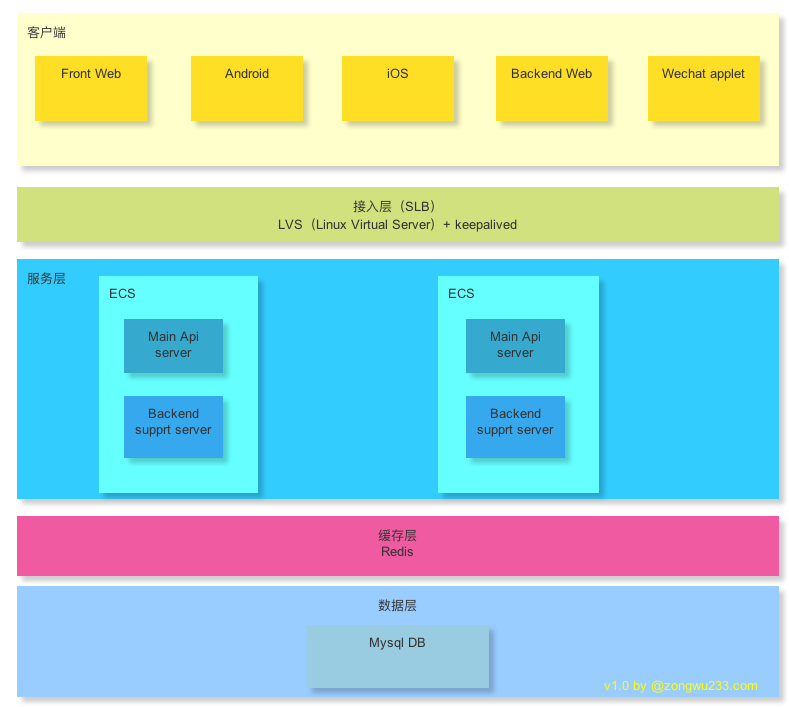
客户端包括:PC站和m站的web站点,Android和iOS App客户端,管理后台和小程序。其中主要流量来自于Android和iOS。
接入层:采用了阿里云的Service Load Balance。底层实现是通过LVS+keepalived。该层主要提供了负载均衡和双机热备功能,客户端通过域名访问API接口,当应用的其中一台机器出问题时,依然能保障正常服务。
服务层:实际上是使用两台阿里云ECS部署Main Api server 和support server 两个应用。Main Api server 提供App需要的API接口。support server提供运营管理后台页面需要的API接口。
缓存层:采用阿里云Redis服务8G主从版(标准版-双副本)。连接上限10000,QPS约80000。正常情况下完全满足我们的应用需求。不需要集群版本。
数据层:采用阿里云RDS服务高可用版,4Core8G。最大IOPS:4000,最大连接数:4000。偶尔出现慢SQL导致数据库CPU跑满、接口响应慢。
存在的几个主要问题
- 无法应用灵活的流量控制策略,当前所有流量最终会压到应用实例上,一旦出现流量过大现象,只能增加应用实例,或者改动应用响应逻辑并发布。
- 无自动化的负载均衡,新增ECS就必须同时修改SLB的后端服务配置,扩容方案不够灵活、需要人为介入并且不易配置。
- 管理后台应用与前台应用共用同一个数据库,后台耗时的读操作影响线上接口。
- Main Api server 是一个Monolith Application(巨石应用),任何业务的改动都需要发布该应用,打包发布时间较长。
- 非核心业务和核心业务共用资源,比如web容器线程、数据库连接池、Redis连接池等等,一旦非核心业务占用较多资源,将导致其他业务响应变慢。
考虑到后续业务发展、当前应用现状和服务端团队人员的实际情况,趁此机会我们决定向微服务架构方向演进。
选取微服务端架构方案时的一些原则:
- 高质量高可用的服务架构体系
- 技术实现成熟稳定
- 充分利用Docker容器优势
- 团队学习门槛较低
- 对当前应用系统入侵较小
- 减少不必要的部署和维护代价
- 方便支持非JVM的web服务
微服务架构实现
采用 Consul + Registrator + Nginx 方案做服务的注册与发现框架
简单介绍一下Consul 、Consul template 和Registrator:
Consul是一种 service mesh解决方案,提供具有服务发现和配置的工具,它提供了一些重要特性 1 :
- 服务发现
- 健康检查
- KV存储
- 多数据中心
Consul集群间使用了GOSSIP协议通信和Raft一致性算法,Consul本身是一个分布式的高可用的系统。
Consul template 通过解析模板,从Consul查询所需的配置数据,接下来后台进程监听 8 Consul中这些数据的变化,并将数据更新到配置的模版文件中。模板更新完成之后,可以配置后续执行命令。 7
Consul template的模板文件是采用 HashiCorp Configuration Language (HCL) 语法编写,同时提供了一些API函数。 4
Registrator是一种通过监控宿主机上所有的Docker容器的状态,自动地为Docker容器注册和反注册服务的组件。Registrator支持可拔插的服务注册,包括:Consul,etcd,SkyDNS2。 5
各组件协调工作如图:
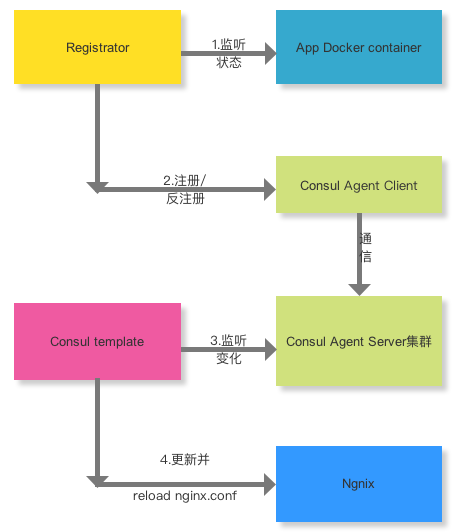
Registrator监听应用容器的变化,实时向consul注册/反注册容器内的服务,而consul template也在监听consul server的变化,任何服务的变更或者KV 存储的变更,都触发consul template 的模板文件的变化,这里,consul template 配置的模板一般是生成nginx.conf文件,最后调用nginx的reload config 命令,即可全自动地完成服务的刷新。
更详细的部署方案见 Consul+Registrator+Nginx方案的部署
服务间的调用
通过上面的方案完成服务的注册和发现,但是服务之间如何调用?
比如服务A要调用服务B的接口,服务A和服务B都已经注册到Consul server中,服务A要获取服务B的地址很方便,请求Consul Api 即可。可是服务B有多个实例,这时候调用策略有两种选择:
- 服务端负载均衡,服务A通过nignx调用服务B,负载均衡策略由nginx支持。
- 客户端负载均衡,服务A自行维护服务B的列表,自行选择一个负载均衡策略,然后调用服务B。
出于性能考虑,我们选取第二种方式,即客户端负载均衡。
通过封装Consul API 和Feign-ribbon,我们实现了客户端之间相互调用的中间件。
OpenResty
服务架构v1.0版本由于缺失统一网关,导致无法实现灵活的负载均衡、鉴权、流量控制等功能。为了方便实现网关的功能,采用 OpenResty 6 而不是Nginx来作为网关的基础组件。
通过 OpenResty 强大的lua脚本,可以对网络请求做各种复杂的控制和安全检测。
负载均衡是 OpenResty 自带功能。
请求鉴权,通过 lua 脚本调用用户中心接口完成各种场景的鉴权功能,如果鉴权失败,则阻断请求。
流量控制,通过 lua 脚本对请求的header和uri 解析,灵活定制流量控制策略。
蓝绿发布,结合consul、consul-template 和OpenResty,实现服务的蓝绿发布功能。
通过在网关处向 request header 中写入 request Id,支持完整请求链追踪的日志分析。
服务路由,v1.0版本的架构,受限于SLB的实现,必须为每一个业务应用单独配置一个端口和域名, 给客户端调用带来很大不便。新的架构可以采用统一的 API 域名,在网关处做服务路由即可(比如通过path区分业务服务),从而实现API 域名的收敛。
对接SLB服务的是OpenResty,目前有三个实例,后续任意应用水平扩展的时候,会自动注册到consul server,无需变动SLB配置。
应用资源拆分
新增的Finance应用是金币业务,使用独立数据库。
新增的Data server应用是搜集数据埋点业务,该应用需要存储客户端上报的大量的埋点数据,使用PostgreSQL,并且采用PostgreSQL自带的分表功能。
Support server是之前的管理后台服务,通过对Main Api server 的数据库配置主从架构,让Support server 的读操作走从库,写操作走主库,解决Support server 拖慢生产环境数据库的问题。
Kafka消息队列主要用于应用间异步通信的场景。Main Api server 和 Finance server 都会产生金币计费消息,Finance server应用负责消费该消息。
正文到此结束
- 本文标签: DNS 安全 需求 消息队列 运营 IO ribbon 微服务 站点 https 集群 API Docker core Service Lua QPS Nginx ip cat 管理 实例 src 用户中心 一致性 缓存 web 质量 进程 redis 解析 OpenResty IOS 高可用 连接池 云 线程 数据 Android Architect 分布式 JVM 自动化 数据库 UI App 阿里云 http id consul 端口 配置 域名 REST ECS 服务端 服务注册 部署 定制 负载均衡 sql 时间 架构演进 主机 主从架构 Feign 并发 协议
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

