spring自己对AOP的运用 -- spring事物(transaction)原理
aop即Aspect-Oriented Programming,面向切面编程。
- Aspect:切面。在代码的执行过程中,总是有一些逻辑在多个模块中是一样的,这个时候,这些多个处理逻辑一样的地方就可以放在一个地方处理。这种处理就感觉像是在代码的各个模块文件中,横向切开了一刀,插入额一段新的逻辑,这些新逻辑的代码文件像是横叉在所有代码的一个切面,经过这个平面处理之后再回到原有的执行逻辑
- Join Point:公共程序执行的位置,对于spring来说,表示方法的执行(要支持字段的更新可以选择AspectJ)
- Point cut:适配所有Join Point的表达式,用来筛选是和执行公共代码的方法
- Advice:切面中实际执行的代码,它可以在方法执行前、执行后、扔出异常等等的位置
- Target Object:切面执行完后,原始程序需要执行的内容,对于切面来说,这个就是需要它代理要执行的对象
- Advisor:代码实现,负责组织好 Advice/Point cut/要代理的对象 的关系
spring 4.2.x 文档介绍
Aop代码中运用
可以使用xml或者注解的方式在项目中使用aop,以注解为例,一般使用可以引用 AspectJ,自己创建一个类,在类上标注好注解 @Aspect
@Aspect
public class LogAspect {}
复制代码
在xml中开启扫描即可找到这个注解
<aop:aspectj-autoproxy /> 复制代码
在代码中建立好对应的 Point Cut
@Pointcut("execution(* paxi.maokitty.verify.spring.aop.service.ExecuteService.*(..))")
public void allClassPointCut(){}
复制代码
这里PointCut表达式指定类paxi.maokitty.verify.spring.aop.service.ExecuteService所有方法都是目标对象
建立自己需要执行的方法( advice )
@Before("allClassPointCut()")
public void beforeAspectExecuteService(JoinPoint joinPoint){
LOG.info("beforeAspectExecuteService execute method:{}",new Object[]{joinPoint.getStaticPart().toShortString()});
}
复制代码
即可达到对应的目标,而且这种方式做到了对原有代码的无入侵,体验很好。 完整的可运行实例请戳这里
通过代码的方式组织aop可以戳这里
spring中的事务对aop的使用
事务
此处不讨论分布式事务
事务是数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。当事务被提交给了数据库,数据库需要确保该事务中的所有操作都成功完成并且结果被永远保存在数据库中。如果事务中有的操作没有成功的完成,则事务中的所有操作都需要回滚,回到事务执行前的状态,同时,该事务对数据库的其他事务执行没有影响。数据库事务一般拥有以下四个特性
- 原子性:事务中所有的操作要么都成功要么都失败
- 一致性:确保数据库从一个一致状态转变成另一个一致的状态
- 隔离性:多个事务并发执行不会互相影响
- 持久性:已被提交的事务对数据库的修改应该永远的保存在数据库中
数据库事务描述-维基百科
java对事务的代码实现
java中操作数据库操作的关键类是 Connection ,它代表了对数据库的一个连接,通过对应的方法
connection.commit() con.rollback();
事务demo实例戳这里
java事务处理全解析 - 无知者云spring中运用事务
spring中最简单的实现只需要直接在要使用事务的类上添加注解 @Transactional ,并在xml中添加注解的扫描 <tx:annotation-driven transaction-manager="txManagerTest"/> 基本就可以利用spring的事务了
spring事务使用戳我
spring对事务的实现则是通过aop来实现的。spring在扫描tx标签的时候,碰到transactional标注的类或者方法,会创建对应的AOP代理,在调用的时候则是AOP代理去执行,先按照AOP的方式执行相应的逻辑,再执行用户定义的方法,如果有问题则执行对应的事务
@Trace(
index = 13,
originClassName = "org.springframework.transaction.interceptor.TransactionAspectSupport",
function = "protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,final InvocationCallback invocation) throws Throwable"
)
public void invokeWithinTransaction(){
//...
Code.SLICE.source("final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);")
.interpretation("查到对应方法的事务配置");
Code.SLICE.source("final PlatformTransactionManager tm = determineTransactionManager(txAttr);")
.interpretation("拿到transactionManager,比如用户在xml中配置的 org.springframework.jdbc.datasource.DataSourceTransactionManager");
Code.SLICE.source("final String joinpointIdentification = methodIdentification(method, targetClass);")
.interpretation("获取transaction标注的方法");
//...
Code.SLICE.source("TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);/n" +
" Object retVal = null;/n" +
" try {/n" +
" retVal = invocation.proceedWithInvocation();/n" +
" }/n" +
" catch (Throwable ex) {/n" +
" // target invocation exception/n" +
" completeTransactionAfterThrowing(txInfo, ex);/n" +
" throw ex;/n" +
" }/n" +
" finally {/n" +
" cleanupTransactionInfo(txInfo);/n" +
" }/n" +
" commitTransactionAfterReturning(txInfo);/n" +
" return retVal;")
.interpretation("这里就是标准的事务处理流程 1:获取事务;2:执行用户自己的方法;3:如果执行过程中抛出了异常执行异常抛出后的事务处理逻辑 4:清除事务信息 5:提交事务");
//...
}
复制代码
spring扫描tx注解到执行事务代码追踪详情戳这里
spring 事务具体执行逻辑
spring自定义了事务的传播逻辑
- PROPAGATION_REQUIRED :如果没有事务就新建一个,有的话就在那个事务里面执行。默认配置
- PROPAGATION_SUPPORTS:没有事务就什么都不做,有事务则在当前事务中执行
- PROPAGATION_MANDATORY:如果没有事务就抛出异常
- PROPAGATION_REQUIRES_NEW:创建新的事务,如果已经存在一个事务,就先把这个事务暂停,执行完新建的事务之后再恢复
- PROPAGATION_NOT_SUPPORTED:方法不会在事务中执行,如果存在事务,会在方法执行期间被挂起
- PROPAGATION_NEVER:如果有事务就抛出异常
- PROPAGATION_NESTED:如果已经有一个事务,就再嵌套一个执行,被嵌套的事务可以独立于封装事务进行提交或者回滚,如果不存在事务,则新建事务
这里就注意到 所谓 物理事务 和 逻辑事务的区别
- 物理事务就是底层数据库提供的事务支持
- 逻辑事务则是spring自己管理的事务,它与物理事务最大的区别就在于事务的传播行为,即多个事务在方法间调用时,事务是如何传播的
spring对事务的隔离机制
- TRANSACTION_READ_UNCOMMITTED :在一个事务中一行数据的改变,再实际提交之前,会被另一个事务读到,也就是说如果改变数据的事务发生回滚,那么其它线程读到的数据就是无效的
- TRANSACTION_READ_COMMITTED:事务一行数据的改变,只有在数据提交之后才能读到
- TRANSACTION_REPEATABLE_READ: 事务一行数据的改变,只有在数据提交之后才能读到。两个事务,一个事务读到一行数据,另一个事务立马进行了修改,如果第一个事务对数据再次进行读取,此时它读到的数据还和之前一样
- TRANSACTION_SERIALIZABLE:一个事务读取到满足where条件的数据之后,另一个事务同时插入了一行满足这个条件的数据,第一个事务再次读取并不会读到这个新的数据
事务的隔离机制与传播机制源码注解解释各自含义 ,实际就是Connection的定义
对不用的隔离机制,也就产生了 脏读、不可重复读、幻读的场景
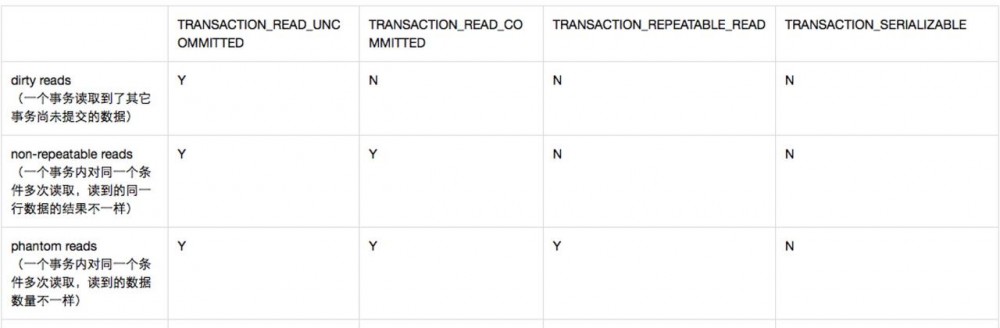
Y表示会存在,N表示不存在
实质上就是在不同隔离机制下,多个事务读取数据的影响
spring的具体源码实现
spring自定义的传播机制,实际上就是代码的处理逻辑,在不同的场景下做出的限制
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
复制代码
它底层去提交事务或是回滚事务,本质上还是java的Connection来最终执行操作,另外对于对于一次访问的多个数据库的事务操作,spring自己将连接与线程建立了关联关系,即每个线程都持有的是同一个连接,来保证期望相同的数据库操作在同一个事务里面。 源码的详细追踪实例可以戳这里
正文到此结束
热门推荐









相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

