轻松构建微服务之高效缓存
在分布式系统中最好耗性能的地方就是最后端的数据库,一般情况下数据库上的insert操作很快,而update和delete操作如果带有索引也不会慢,前提要控制好单表的数据量,并且不要建太多索引, 而最容易出现性能问题的往往是select语句,我们抛开join和group不说,大多数应用都是读多写少而且,而且带有排序和limit等耗时操作,有些查询还需要根据非索引字段进行过滤,以及like操作会加剧慢查询, 在微服务中这些查询接口往往以rpc的形式对外提供服务,因为网络开销导致整体响应时间增加,所以在某些性能要求较高的业务中引入缓存是非常必要的,下面我们将引入缓存的具体位置进行分类介绍.
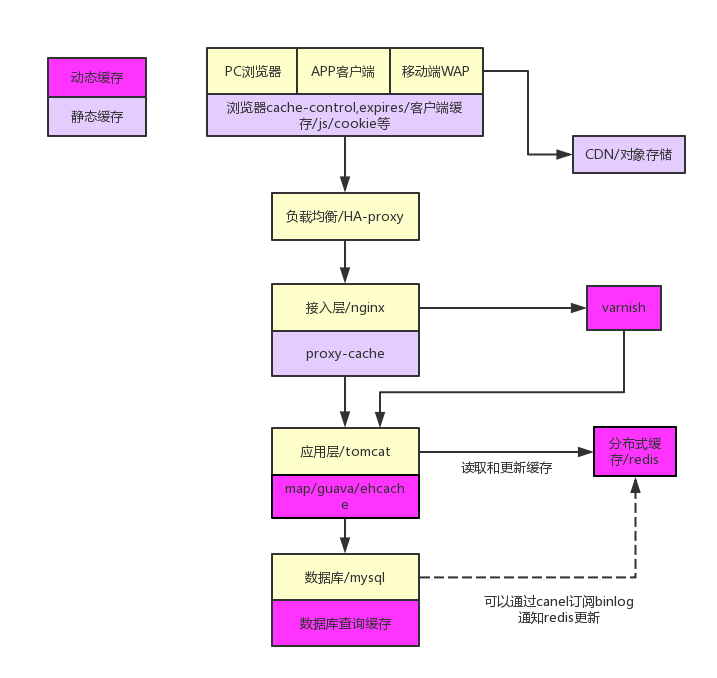
客户端缓存
移动客户端可以将一些静态资源缓存在设备上,避免重复从应用层获取,在网络不通畅的情况下也可以避免没有数据前端UI错乱, 而PC端浏览器一般可以通过nginx设置cache-control,expires,if-modified-since来控制缓存,避免重复请求服务器,也可以通过 cookie将一部分数据存在用户浏览器中,下次请求可以将cookie发送给服务端,一般用cookie存储用户登录信息
CDN缓存
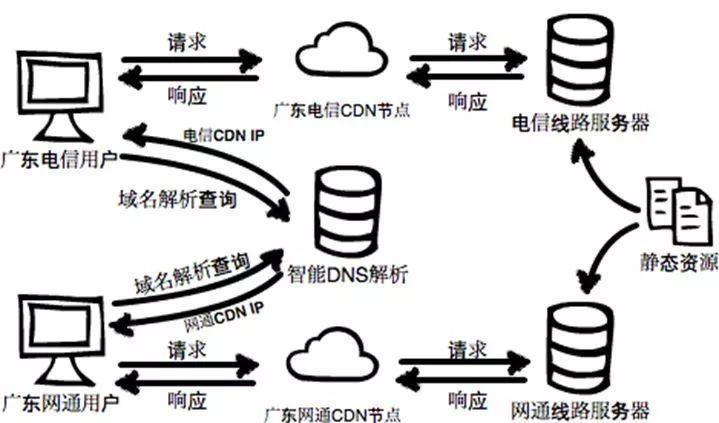
一些静态资源,尤其是图片,我们可以在高并发的情况下,让用户优先访问离用户最近并且同一个网络供应商的CDN节点,避免跨运营商垮地域访问, 相比于集中式的机房内的服务器,CDN厂商的覆盖范围更广,在每个运营商,每个地区都有自己的POP点,所以总可以找到更加靠近用户网络的CDN节点就近获取静态资源,CDN节点一般用来存储 不频繁变更的静态图片,页面等资源,一般发布新版本,或者上新一个新活动都可以提前将这些静态资源提前推送到CDN节点进行预热,使用CDN一般通过CNAME的方式将域名解析交给CDN厂商的DNS服务器和全局负载均衡器
反向代理层缓存
反向代理层一般需要做动静分离,将静态资源存在在ngnix本地,静态资源一般数据库大请求频繁,做动静分离可以使应用层可以有更多资源处理动态请求,而静态资源不用直接请求应用层,可以极大提高系统吞吐量 在做了动静分离后,浏览器可以直接通过ajax请求服务端获取动态数据,浏览器将数据进行整合后显示给用户.
分布式缓存
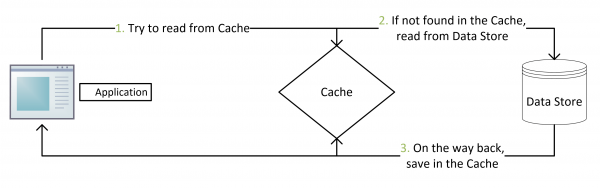
目前分布式缓存一般单独部署在应用层进行读写控制,读取的时候先去查询缓存服务器,没有命中在去查询数据库并写入缓存,更新的时候先更新数据库,然后在将缓存失效, 使用分布式缓存来替代应用层在JVM内缓存,可以避免各个JVM内缓存不一致的情况,也让缓存可以集群化部署更容易水平扩展,
目前分布式缓存主要由memecache和redis,memecache主要提供key-value存储,内存使用率较高,对大数据性能较好,但是集群支持不友好. 而redis提供多种数据结构,string,set,list,zset,hash等,还提供了RDB全量持久化,和AOF增量持久化,将内存中得数据化存储在硬盘上,重启可以再次加载使用,不过开启持久化后会影响redis的内存使用率,尤其是开启AOF同步后还会影响redis的写性能,redis还提供了集群化master-slave数据备份以及多master进行分片来提高吞吐量. 不过memecache采用多线程模型,分为主线程和worker线程,而redis是单线程IO复用模型,对于IO操作可以将性能发挥的最大化,但是redis也提供了排序,聚合等操作,这些操作在单线程下会影响吞吐量. memechache集群只能通过客户端在读写的时候根据统一的分片算法选择对应的机器,不支持master-slave数据备份
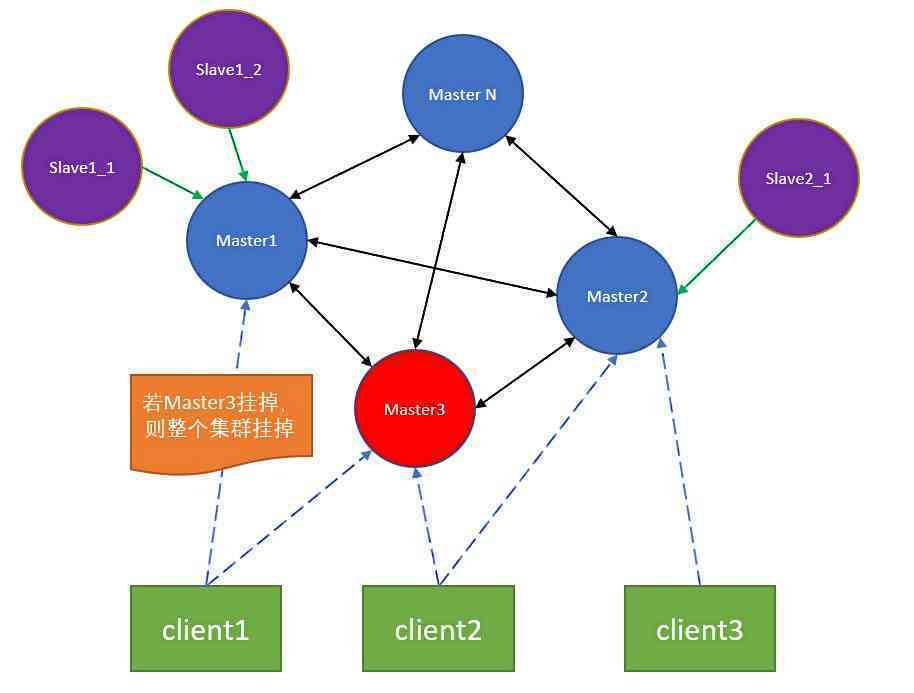
redis提供分片功能,将整个集群的16384个slot根据服务器的性能和读写频率分道不同的master节点上,每个master可以下挂若干个slave节点,slave从master异步同步数据,当master挂了之后,slave可以通过选举生成新德master, master可以提供读写服务,而slave只提供读服务,而redis集群对外提供服务也可以单独加一层proxy也可以直接连接客户端,两种方式各有利弊,可根据实际场景进行选择
像redis和memecache这种提供内存服务的应用,内存管理的效率直接影响系统的性能,在C语言中我们使用malloc和free分配和释放内存,对于开发人员如果malloc和free不匹配容易造成内存泄露,频繁使用也会造成大量的内存碎片,而且频繁进行这种系统调用也会影响性能.
memecache会预先申请一块内存,然后将这块内存切分为若干个chunk,chunk的大小可以根据一个增长因子控制,比如增长因子为1.25,第一组chunk的大小为88字节,则第二组的大小为88*1.25=114字节,让后将相同大小的chunk归类为一个slab,当客户端有一个写请求后,会根据写入数据的大小选择对应的chunk,如果这个值占用空间小于chunk大小就会造成一定空间的浪费,删除缓存的时候会标记这个chunk未使用.
而redis是现场申请内存的方式进行存储数据,也很少对内存进行优化,所以redis一定程度上会产生内存碎片,并且当redis发生swap的时候也不会触发内存整理.
当然redis并不是所有数据都存储在内存中,当物理内存用完时或者达到某一个阈值,redis可以将一些很久没有用到的value存储到磁盘,只将key存在内存中,也就是所谓的swap操作,需要计算哪些key需要交换到磁盘,不过这种情况下当客户端发起一个读请求,value不在内存中得时候需要从硬盘读取,默认情况下redis会阻塞.
目前经过benchmark测试,redis性能要优于memecache,原因可能是memecache用了libevent库,而该库为了迎合通用做了大量的代码冗余,而redis使用libevent里面的两个文件修改实现了epoll event loop,另一方面redis是单线程的,不用考虑精装修改资源的情况,而memecache采用CAS的方式,CAS的实现需要为每一个cache key设置一个隐藏的token, 这个token会作为版本号,在set的时候会递增,带来CPU和内存的双重开销,尽管开销很小,在QPS很高的情况下会带来性能上的细微差别.
JVM本地缓存
本地缓存,这类缓存一般存储在JVM堆空间内,由于容量受限制,也会影响到FullGC,当然也可以考虑使用堆外内存或者用jemalloc管理内存, 所以我们只是通过本地缓存来缓存一些并发访问量特别高并且查询数据库很耗时的数据,而且这类数据可能不一定和数据库完全保持一致,所以业务不会使用改变量做一些金额和状态相关的核心操作. 这类缓存的典型代表为guava和ehcache,也有一些缓存放在ORM框架中,去缓存数据中的查询操作.
数据库缓存
数据库本身也会有缓存功能,目前建议只针对一些读多写少特别频繁的业务表开启,大多数情况都建议关闭,因为mysql的缓存中当有任何一条记录的update操作就会将缓存失效,如果频繁update就会导致数据库频繁缓存和清除
使用说明
- 容量评估
在使用缓存前,最好做下容量评估,缓存系统主要消耗的是服务器内存,因此使用缓存时候必须对应用需要缓存的数据大小进行评估,包括缓存的数据结构,过期时间,缓存大小,缓存数量,然后根据未来一定时间内的业务增长情况进行预估.
- 业务分离
建议将使用的缓存进行分离,核心业务和非核心业务可以使用不同的缓存实例,最好能做到业务之间相互隔离,避免不同业务线共用一套缓存导致冲突.
- 监控
所有的缓存实例都需要有监控,内存使用情况,慢查询,大对象,任何缓存key都设置过期时间,过期时间最好在原有设置上加减一个随机值,避免一起失效导致雪崩。
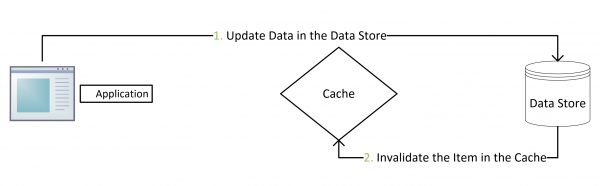
- 先更新数据库,后失效缓存
以下为先更新数据库后清缓存的两种情况,一种最后缓存清空后下一次读请求就会恢复,另外一种发生的概率很小

以下为先清缓存后更新数据库,会导致缓存中得数据一直是脏数据

其次,我们要考虑下如果数据库是主从部署,从库支持读取,那么数据写入主库后,而应用读取从库还未更新的数据并写入缓存导致缓存里的数据一直是脏数据,这种情况我们可以提供一种供参考的方案:通过canel订阅mysql的binlog的方式去修改缓存可以避免该问题。
- 应用不要过渡依赖缓存
我们一般不会要求缓存服务器的更新和数据库的更新在同一个事物内,所以肯定有概率缓存和数据库不一致的情况,所以 数据的最终一致性最好不要依赖缓存,可以在应用层和或者数据库CAS的方式增加校验,另外应用也不应该严重依赖缓存,当缓存服务器挂掉之后至少要保证服务能够在没有高并发情况下继续正常对外提供服务, 当然也不要过渡依赖缓存服务器的持久化功能,毕竟并不能完整复原历史数据.
正文到此结束
- 本文标签: 高并发 Proxy 服务器 redis 解析 ORM memecache 备份 CDN 数据 域名 性能问题 删除 分布式 JVM 部署 Nginx 负载均衡 UI 空间 开发 http 服务端 索引 并发 update DNS sql 时间 list 运营 Master token 微服务 mysql https 集群 代码 value src 物理内存 一致性 反向代理 占用空间 线程 多线程 key lib IO 模型 QPS db 数据库 管理 实例 Ajax 图片 分布式系统 缓存 测试 swap 大数据 Select 同步 cache
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

