解读 Java 8 HashMap
这篇文章是记录自己分析 Java 8 的 HashMap 源码时遇到的疑问和总结,在分析的过程中笔者把遇到的问题都记录下来,然后逐一击破,如果有错误的地方,希望读者可以指正,笔者感激不尽。
疑问与解答
什么是 initial capacity?
The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created.
initial capacity 指定了 HashMap 内部的 hash table 的初始化容量,可以通过构造函数指定,默认的初始化容量为 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 复制代码
什么是 load factor?
The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
可以看到 load factor 是用于确定 hash table 何时扩容的重要参数之一。
为什么 initial capacity 太高或 load factor 太低会影响性能?
Iteration over collection views requires time proportional to the "capacity" of the HashMap instance (the number of buckets) plus its size (the number of key-value mappings). Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
An instance of HashMap has two parameters that affect its performance: initial capacity and load factor . The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
查看源码描述
描述主要提到三个问题:
- initial capacity 和 load factor 是重要的性能参数。
- 设置不当会影响迭代性能(如果迭代性能很重要的话)
- 设置不当会导致频繁的 rehash(伴随 hash table 的 rebuild,并且 hash table 的容量会成倍增加)
合理的 initial capacity 是多少?
笔者经过一番测试,在 hash 均匀分布的前提下,数据量从 100 ~ 千万级,initial capacity 设置从 1 到千万不等,发现这个值的大小对迭代性能和 rehash 的影响不是很大(到千万级别才会有稍微明显的效率问题),原因是扩容时,每次都会 double threshold,有效避免了高频率的扩容动作;对迭代性能的影响也非常低(10W数据,1亿初始容量,毫秒级别影响)。
合理的 load factor 是多少?
默认 0.75 即可,太低可能会导致频繁的扩容,并且有可能导致 java.lang.OutOfMemoryError: Java heap space
什么时候会发生 resize?
When putting data && (hashtable.length == 0 || entries.length >= threshold) Then resize() 复制代码
什么时候会发生 rehashed?
触发 resize 的时候,会发生一次扩容,并随 rehash。
为什么需要 rehashed?
扩容时会重建 hash table,由于新 hash table 的容量 = 旧 hash table 容量左移一位,因此需要 rehash,以确保新的 hash 落在 [0, new_capacity) 区间内。
如何确保 hash 落入 [0, capacity) 区间?
(capacity - 1) & (hashcode ^ (hashcode >>> 16))
capacity 取值范围: 2^(N+) - 1,0 < (N+) < 31。
在 hashCode 均匀分布的前提下(Object.hashCode() 默认为每个对象生成不同的 hash code,具体原理可以看 java doc), hashcode ^ (hashcode >>> 16) 可以降低 hash 冲突的几率(相对于 (capacity - 1) & hashcode ),原理是混合原始哈希码的高位和低位,以此来加大低位的随机性;(capacity - 1) & new_hash 可以保证计算出来的 index 落入 [0, capacity)。
为什么扩容后是原来的 2 倍,而不是 1.5 倍?3 倍?4 倍?
- 扩容原来的 2 倍可以让 rehash 的值更加稳定,整体的 hash 值均匀分散。
- 减少不必要的扩容空间(影响迭代性能)。
如何模拟 hash 碰撞?
通过覆写 Object##hashCode() 方法即可自定义 hashCode,就可以模拟 hash 碰撞,例如随机 hashCode 或固定 hashCode。
什么时候 HashMap 会采用红黑树保存节点数据?
Given TREEIFY_THRESHOLD = 8 When hashCount >= TREEIFY_THRESHOLD Then treeifyBin(bin) 复制代码
当出现同一个 hash 达到 8 次碰撞,就会从链表转换成红黑树。
什么是 hash table
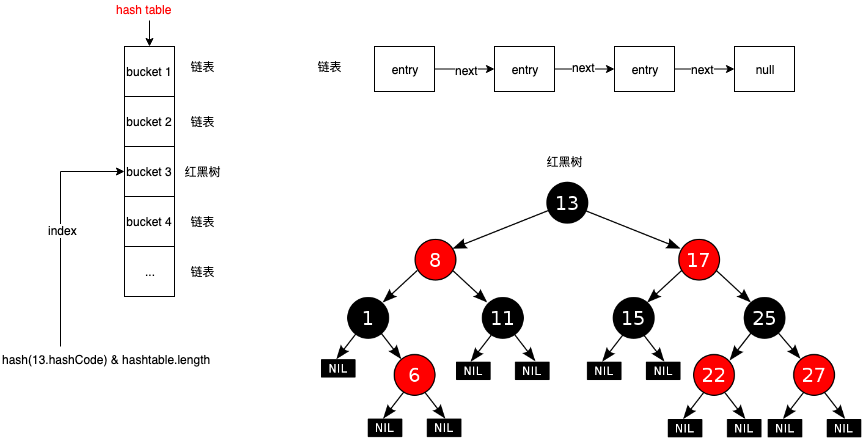
hash table 本质上是一个数组 + 链表或红黑树的数据结构, hash table 通过建立 hash 到数据节点的映射关系,巧妙的达成 O(1) 的检索效率。其中每个链表保存着 hash 冲突(key 不相等,hash 值相等)的数据项,默认情况下,当达到 8 个冲突时,链表就会转换成红黑树,转换之后还伴随着 O(n) -> O(log n) 的效率提升,不过这种情况出现的概率很低(在分散的 hash code 的前提下,相同的 hash 值产生 8 次冲突的概率仅为千万分之 6),不过可以通过人为模拟重现这种情况。
什么情况下,HashMap 的效率最差?
频繁的 hash 冲突是导致 HashMap 性能下降的罪魁祸首,当同一个 hash 值冲突达到 8 次及以上时, 此时 rbtree 可能需要经常通过左旋、右旋和着色来保持自身平衡,这个代价之大跟同一个 hash 值的冲突次数成正比,因此需要维护好重写的 hashCode 方法,使 hash code 尽可能分散。
为什么采用 RBTree 替代 LinkedList 来保存 hash 冲突的的节点?
用于提高哈希冲突条件下的性能,同时去除了以前版本遗留下来的问题,具体可以看这里 openjdk.java.net/jeps/180
什么是红黑树?

红黑树(英语:Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为"对称二叉B树",它现代的名字源于Leo J. Guibas和Robert Sedgewick于1978年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在 O(log n)时间内完成查找,插入和删除,这里的 n 是树中元素的数目。
上面是维基百科中的定义,同时红黑树还有 5 个性质,红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
- 节点是红色或黑色。
- 根是黑色。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
红黑树适合哪些应用场景?
时间敏感型程序。
红黑树有哪些应用场景?
Linux 内核和 epoll 系统调用实现中使用的完全公平调度程序使用红黑树。
什么是 fail-fast?
HashMap 通过这个机制确保迭代时,如果修改 map 的结构(增,删),一经发现则立即抛出 ConcurrentModificationException ,而不是等到未来的某个时刻再通知异常,可以通过这个机制来捕获程序的一些 BUG.
可以通过什么方式使 HashMap 线程安全.
在 HashMap 之上包装多一层,并且使用 synchronized 同步锁锁定 HashMap 实例的所有公开接口, Collections#synchronizedMap 已经提供了这样一种实现。
总结
通过阅读源码、查阅资料和动手验证,才知道 HashMap 的知识点那么多,不过都啃得差不多之后,就会觉得知识点很少(应该还有遗漏掉的或者不严谨的情况),确实让自己学到了很多之前不知道的知识点。
在接下来的文章中,笔者会通过 TDD (测试驱动开发)来记录如何实现一个精简版的 HashMap,避免一看就会,一做就废的尴尬局面。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

