java日志框架探秘
| 编辑推荐: |
| 本文来自于网易云,本文主要分享不同的日志框架开源社区又提供了一套统一的日志框架api,apache commons-logging和slf4j,希望对您的学习有所帮助。 |
前言
当我们对一个日志框架在做技术选型的时候,除了需要满足业务功能外,另外两个考虑的重要因素就是性能和稳定性。目前市面上已经存在的日志框架有log4j,log4j 2,logback,java.util.logging。然而,现在主流的这几个日志框架基本都是基于实现类编程,而非接口编程,暴露了一些无关紧要的信息给用户,这种耦合没有必要,还有当应用系统在团队协作开发时,可能会同时出现多套日志框架,而且不同的日志框架api又各自独立。
一个简单的demo比较
1. logger.debug(" Entry: " + i + " is " + String.valueOf(Entry[i]));
2. logger.debug(" Entry: {} is {}", i, Entry[i]);
上述两条语句在输出结果上是一致的。但是在关闭debug日志时,无论是否生效,前者都需要进行字符串转换和字符串拼接,会在内存中产生大量新的对象,后者只是在需要的时候执行这些操作,log4j的官方测试结论是两者性能上差两个数量级,如果是log 4j 1.x或commons-logging,由于不支持{}写法,所以需要在输出前加判断:
3. if (logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
但是上述写法会进行两次日志级别判断,一次是 logger.isDebugEnabled() ,另一次是 logger.debug() 方法内部也会做的判断。这样会带来一点点效率问题,所以综上所述,第二种是目前最优的写法, 提供占位符,以参数化的方式打印日志,既省了一次日志级别判断,又避免了字符串拼接。
SLF4J的设计
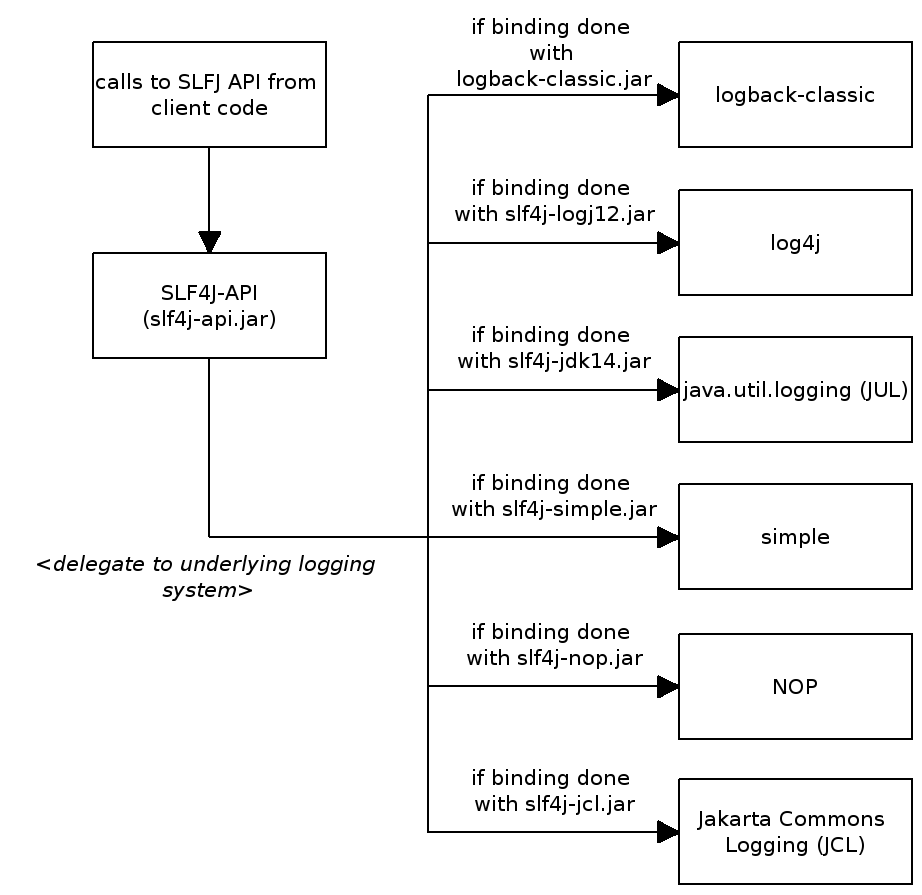
slf4j是对不同的日志框架提供的一个门面封装,可以在部署的时候不修改任何配置即可接入一种日志的实现方案,相对于commons-logging有如下两个额外的优点:
1.支持配置多个参数,并通过{}进行替换, 避免了logger.isXXXEnabled的判断
2.对OSGI机制更好的兼容支持
slf4j的几种应用模式
1.slf4j+log4j
需要如下配置文件和组件包:
(1) slf4j-api-${version}.jar
(2)slf4j-log4j12-${version}.jar
(3)log4j-${version}.jar
(4)log4j.properties(也可以是 log4j.xml)
2.slf4j+logback
需要如下配置:
( 1) slf4j-api-${version}.jar
(2) logback-core-${version}.jar
(3)logback-classic-${version}.jar
(4)logback.xml 或 logback-test.xml
slf4j怎样定位到具体需要用的log?
public static ContextSelectorStaticBinder getSingleton() {
return singleton;
}
static ContextSelectorStaticBinder singleton = new ContextSelectorStaticBinder();
private final ContextSelectorStaticBinder contextSelectorBinder = ContextSelectorStaticBinder.getSingleton();
public ILoggerFactory getLoggerFactory() {
if (!initialized) {
return defaultLoggerContext;
if (contextSelectorBinder.getContextSelector() == null)
{
throw new IllegalStateException("contextSelector cannot
be null. See also " + NULL_CS_URL);
}
return contextSelectorBinder.getContextSelector().
getLoggerContext();
}
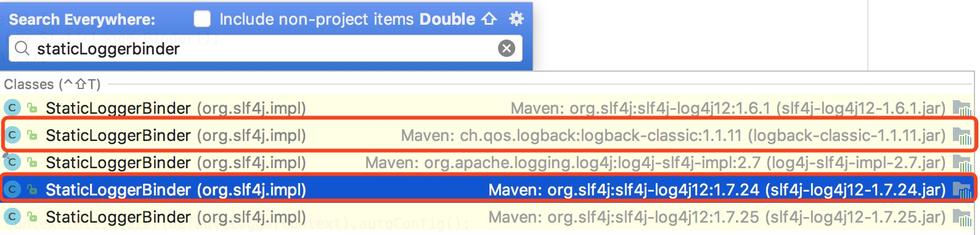
通过源码可以看出是先通过StaticLoggerBinder.SINGLETON.getLoggerFactory()获取ILoggerFactory,再根据ILoggerFactory的具体实现来获取Logger,通过观察 每个与具体日志系统对应的jar包,就会发现,相应的jar包都有一个org.slf4j.impl.StaticLoggerBinder的实现,不同的实现返回与该日志系统对应的LoggerFactory,因此就实现了所谓的静态绑定,达到只要选取不同jar包就能简单灵活配置的目的。
架构设计
java logging整体架构
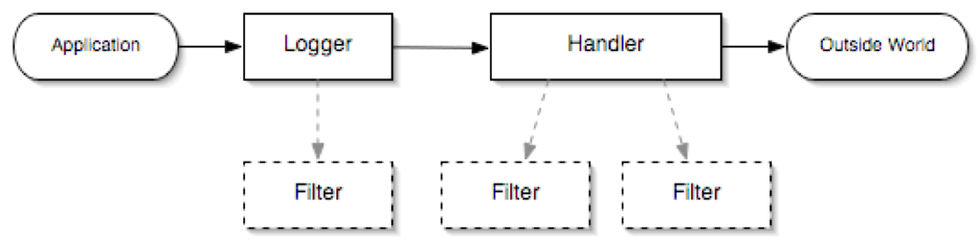
log4j整体架构
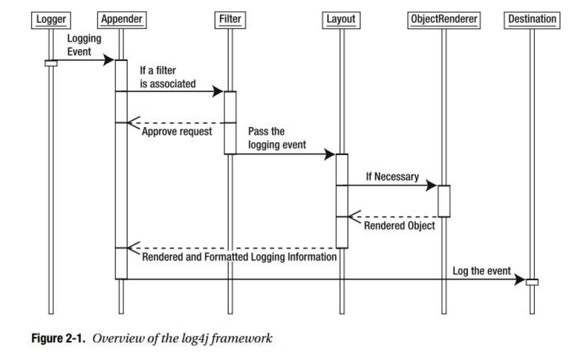
logback整体架构
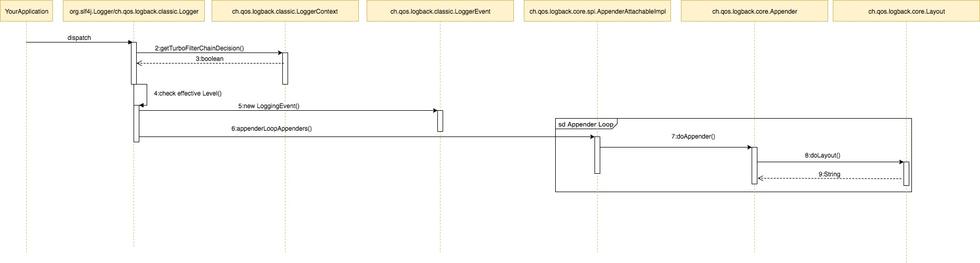
主要特性比较
log4j
1.api分离
2.基于下一代的LMAX Disruptor
3.支持slf4j,log4j 1.2,Commons Logging and java.util.logging APIs
4.自动重载配置文件,重新加载的过程中不会丢失日志事件
5.高级过滤
6.插件架构
7.无垃圾回收或较少的垃圾回收
8.支持lambda表达式
logback
1.相比log4j执行速度更快,内存占用更小
2.实现了slf4j api
3.使用xml或groovy作为配置文件
4.自动重载配置文件
5.I/O故障恢复不需要重启应用
6.自动移除老的归档日志
7.自动压缩归档日志文件
8.条件化配置文件
一些常见的问题
1.当一个spring boot工程中存在多个日志框架时,加载顺序是怎样的?
static {
Map systems = new LinkedHashMap();
systems.put("ch.qos.logback.core.Appender",
"org.springframework.boot.logging.logback.Logback
LoggingSystem");
systems.put("org.apache.logging.log4j.core.impl.
Log4jContextFactory",
"org.springframework.boot.logging.log4j2.Log4J
2LoggingSystem");
systems.put("java.util.logging.LogManager",
"org.springframework.boot.logging.java.Java
LoggingSystem");
SYSTEMS = Collections.unmodifiableMap(systems);
}
public static LoggingSystem get(ClassLoader classLoader)
{
String loggingSystem = System.getProperty
(SYSTEM_PROPERTY);
if (StringUtils.hasLength(loggingSystem)) {
if (NONE.equals(loggingSystem)) {
return new NoOpLoggingSystem();
}
return get(classLoader, loggingSystem);
}
for (Map.Entry entry : SYSTEMS.entrySet()) {
if (ClassUtils.isPresent(entry.getKey(), classLoader))
{
return get(classLoader, entry.getValue());
}
}
throw new IllegalStateException("No suitable logging
system located");
}
会按照logback->log4j2->java logging这样的顺序去查找,一旦找到某个日志框架的LoggingSystem存在,那么便会停止查找,然后以找到的这个配置为准
2.怎样控制logback当中同样的日志只打印一份
public final class Logger implements org.slf4j.Logger, LocationAwareLogger, AppenderAttachable, Serializable {
transient private boolean additive = true;
public void callAppenders(ILoggingEvent event) {
int writes = 0;
for (Logger l = this; l != null; l = l.parent) {
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
从源码可以看出additive这个选项默认设置是true,所以需要在logback-spring.xml中手动设置additivity为false,这样就不会去找当前日志的父类,只打印当前日志
3.spring boot是怎样去查找日志配置文件的?
public abstract class AbstractLoggingSystem extends LoggingSystem {
protected String[] getSpringConfigLocations() {
String[] locations = getStandardConfigLocations();
for (int i = 0; i < locations.length; i++) {
String extension = StringUtils.getFilenameExtension(locations[i]);
locations[i] = locations[i].substring(0,
locations[i].length() - extension.length() - 1) + "-spring."
+ extension;
}
return locations;
}
protected abstract String[] getStandardConfigLocations();
@Override
protected String[] getStandardConfigLocations() {
return new String[] { "logback-test.groovy", "logback-test.xml", "logback.groovy",
"logback.xml" };
}
从源码可以看出是先去查找对应日志框架原有的配置文件,都没找到的话再去查找logback-spring.xml
4.日志记录是选择同步方式还是异步方式?
1.当一个系统需要偶尔处理几次消息的突发增长,日志记录采用异步的方式可以延缓峰值,降低日志响应时间延迟,这样子峰值吞吐量比同步的方式更高。
2.如果日志记录是业务逻辑的一部分,比如审计,在日志记录期间发生问题并抛出异常,这个时候采用异步记录日志的方式就不那么容易将这个问题告知应用程序,这里虽然可以通过配置一个ExceptionHandler来部分缓解,但是没办法涵盖所有情况,所以这种情况采用同步方式会更好一些。
3.如果应用程序运行在cpu资源稀缺的环境下,比如一个CPU一个内核的机器,启动另一个线程不太可能带来更好的性能,这里就用同步方式。
4.如果应用程序持续记录消息的速率比系统的处理的吞吐量更快,这里采用异步处理的方式,队列很快会被填满,这样就需要采用一个更快的异步appender,或者减少记录,否则就只能采用同步的方式获得更好的吞吐量和更少的延迟。
最佳实践
1.logback同步和异步记录日志文件比较
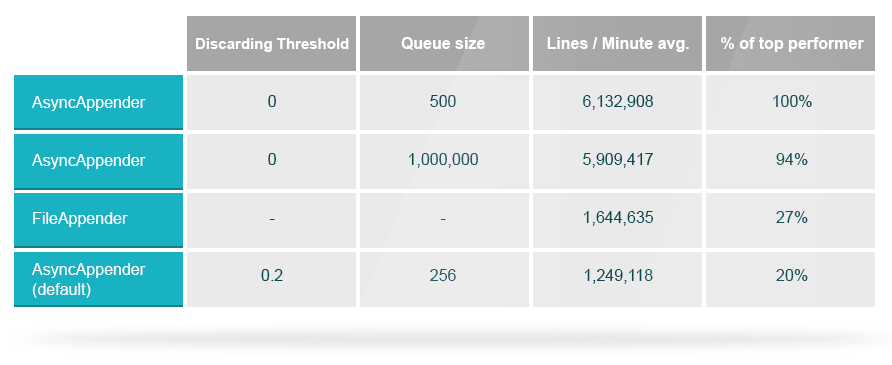
两者的区别在于FileAppender是直接将日志写入文件,AsyncAppender则是先将条目放入队列,再写入文件。默认的队列大小是256,当性能达到80%的时候,会停止进入较低级别的新日志(error和warn除外),从效率上来说,AsyncAppender的效率是FileAppender的3.7倍。
默认的AsyncAppender会造成5倍的性能下降,所以需要根据实际情况手动设置一个AsyncAppender的discardingThreshhold和queueSize。
<appender name="async" class="ch.qos.logback.classic.AsyncAppender"> <queueSize>500</queueSize> <discardingThreshold>0</discardingThreshold> <appender-ref ref="FILE" /> </appender>
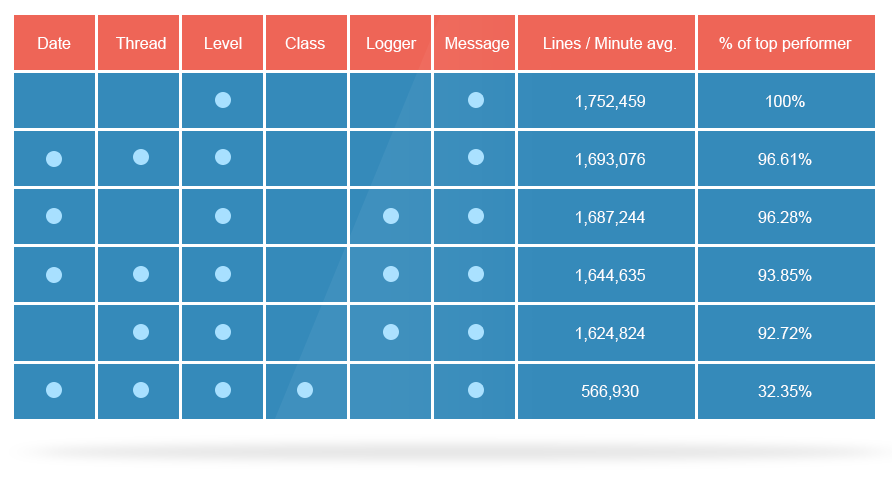
3.多个JVM往同一个文件里写日志使用prudent模式

<appender name="FILE_PRUDENT" > <file>logs/test.log</file> <prudent>true</prudent> </appender>
4.使用consoleAppender写文件比使用FileAppender提高13%的吞吐量

5.如果必须使用同步方式记录日志,根据MDC内容拆分日志,使用SiftingAppender比使用FileAppender吞吐量提升3.1倍

<appender name="SIFT" class="ch.qos.logback.classic.sift.SiftingAppender">
<discriminator>
<key>logid</key>
<defaultValue>unknown</defaultValue>
</discriminator>
<sift>
<appender name="FILE-${logid}" class="ch.qos.logback.core.FileAppender">
<file>logs/sift-${logid}.log</file>
<append>false</append>
</appender>
</sift>
</appender>
6.在分布式系统中,当一个请求需要经过多个子系统的时候,可以生成一个UUID放入请求中,每个请求在打印日志的时候都将该UUID放入MDC里面,后期还可与logstash捆绑到一起,便于后续查询相关日志
<appender name="ROOT_LOG_FILE_APPENDER" >
<!-- 文件路径 -->
<layout >
<pattern>%X{requestURI}</pattern>
</layout>
</appender>
log4j2与logback的异步处理性能对比
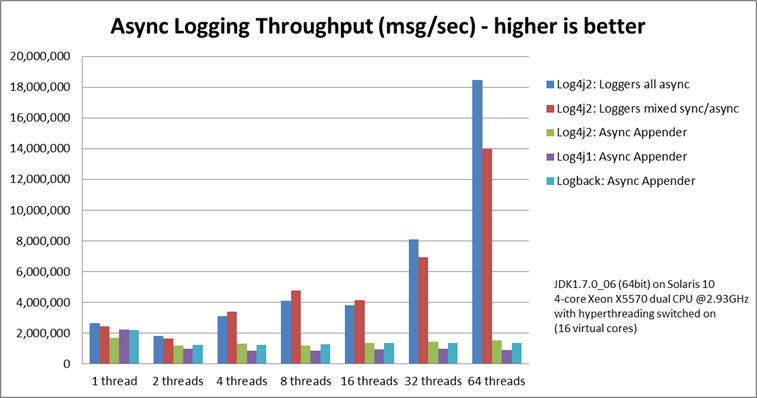
loggers all async采用的是Disruptor,而Async Appender采用的是ArrayBlockingQueue队列
DisruptorBlockingQueue优势分析
通过前面官方的的比较,可以看出log4j2在日志异步处理的性能方面是明显高于logback的,这主要得益于log4j2当中AsyncAppender的一个DisruptorBlockingQueue的底层实现,这是一个无锁的环形数组设计。在介绍DisruptorBlockingQueue之前,先来看下传统的java内存队列有哪些优缺点
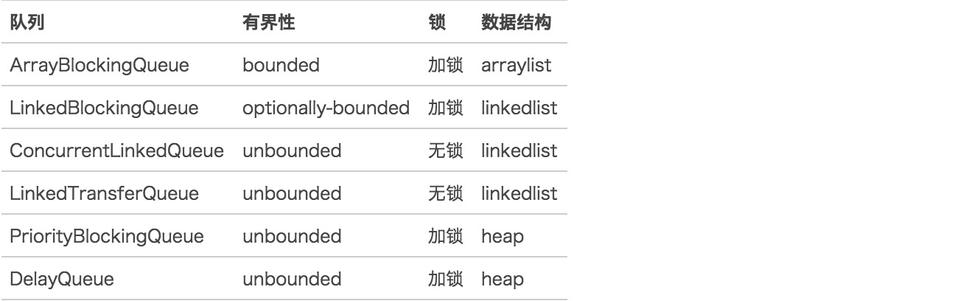
从上图可以看出传统的队列底层一般是基于数组、链表、堆来设计的,堆是为了实现带有优先级特性的队列。
单从数组和链表这两种数据结构来看,一个是基于数组的线程安全的队列,比较典型的是ArrayBlockingQueue,通过ReentrantLock加锁和条件condition的方式实现线程安全。另一种是基于链表的线程安全队列,主要有LinkedBlockingQueue和ConcurrentLinkedQueue,前者是基于ReentrantLock,后者是通过CAS这种无锁的方式。
通过不加锁实现的队列都是无界的,而加锁实现的是有界队列,在系统稳定性要求比较高的系统中,一般要求用有界队列,防止生产者生产过快导致内存溢出,还有一点就是防止java垃圾回收对系统性能的影响,一般优先采用array或heap结构的数据结构,这样只剩下ArrayBlockingQueue可选。
对于采用加锁的方式,线程竞争不到锁会挂起,在等待期间无法做任何事情。一个线程在持有锁的情况下被延迟执行,例如发生缺页、调度延迟等等类似情况,那么所以需要获得这个锁的线程都无法继续执行下去,假如持有锁的线程优先级较低,被阻塞线程优先级较高,此时就会发生优先级翻转。
在单线程情况下 ,无锁性能>CAS性能>加锁性能
在多线程情况下,为了保证线程安全,就必须采用CAS、volatile或者是加锁的方式
保证线程安全无非就两种方式:锁或者是原子变量
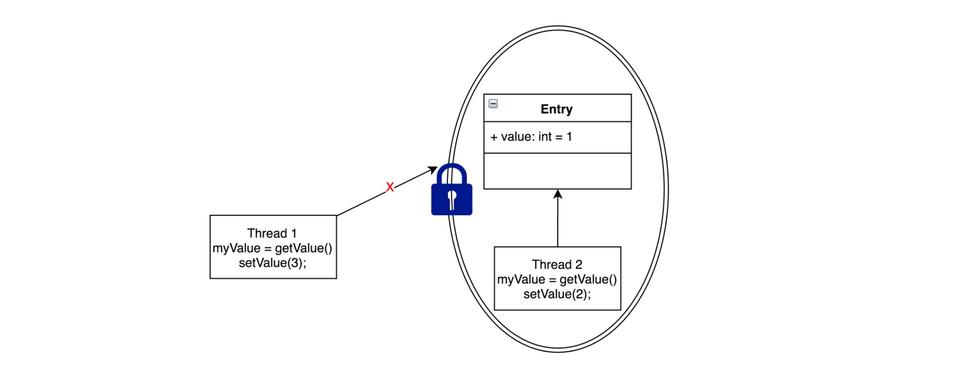
采用加锁的方式,会先默认线程会发生冲突,访问数据时先加锁再访问,通过锁定一个临界区,同一时间只能有一个线程访问。上图Thread2访问Entry加了锁,Thread1就没办法访问了。
ArrayBlockingQueue就是采用加锁的方式,保证了线程安全
public boolean offer(E e) {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count == items.length)
return false;
else {
insert(e);
return true;
}
} finally {
lock.unlock();
}
}
另外一种方式是采用原子变量,某个任务要么全部执行成功,要么全部执行失败,恢复到执行之前的状态。采用原子变量,会先假定不会发生冲突,如果不发生冲突,则直接执行成功,若发生冲突,则执行失败,回滚并重新执行,直到不发生冲突为止。如下图所示,CAS会先把线程当前Entry的值与当初取出来的值先做比较,如果相同,则赋值成功,否则赋值失败,这里会采用while/for重新执行,直到赋值成功为止。另外,CAS是一个CPU的指令,由CPU保证原子性。
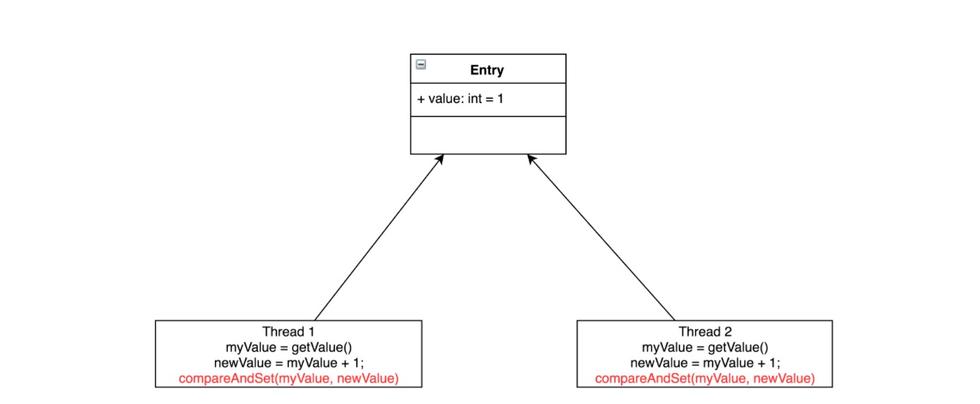
在高度竞争资源的情况下,锁的性能是要高于原子变量的性能.但是实际真实的环境下,原子变量的性能比锁的性能更好,而且不会产生死锁等活跃性问题。
内存伪共享问题
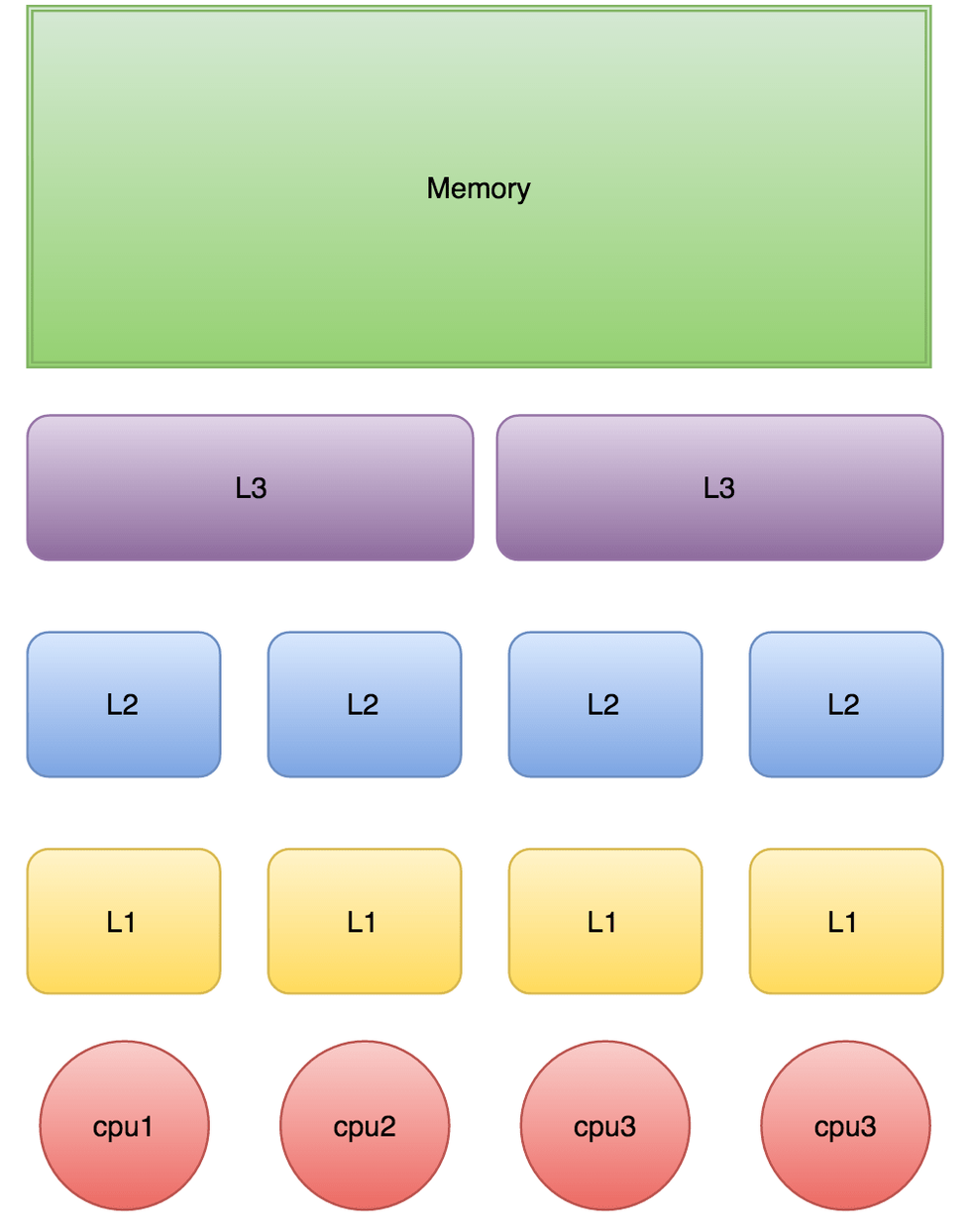
当CPU执行时,会先去L1查找数据,再去L2,L3当中去取,如果这些缓存中都没有的话,才会去主内存当中去取数据,走的越远,耗费时间越长。当线程之间需要共享一份数据的时候,需要有一个线程将数据写回主内存,另外一个线程再去主内存当中去取。
Cache是由多个缓存行组成的,每个缓存行占用64个字节,并有效的引用主内存的一块地址.CPU每次从主内存中拉数据的时候,都会将相邻的数据拉到同一个缓存行当中。例如访问一个Long类型数组的时候,当数组中其中一个值被加载到缓存的时候,它会自动加载另外七个,这也是为什么遍历连续内存块数据速度快的原因。
对于ArrayBlockingQueue来说,存在三个成员变量:
takeIndex:需要被取走的元素下标
putIndex:可被元素插入的位置的下标
count:队列中元素的数量
这三个变量很容易被放入同一个缓存行当中,当其中一个数据更新,都可能会导致另外两条被缓存的数据失效,从而不能达到完全共享的目的。
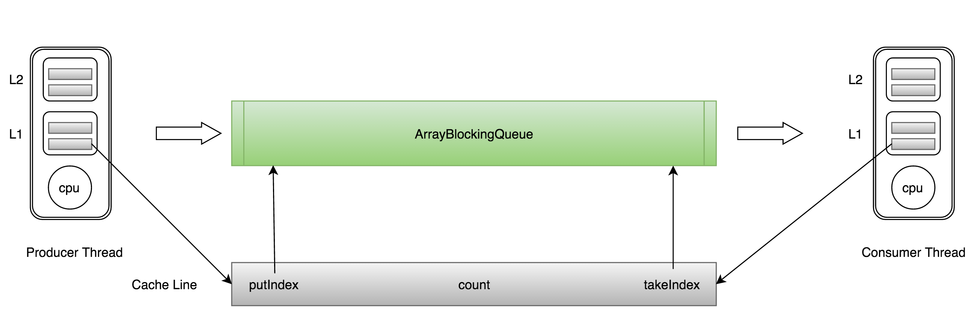
当生产者往ArrayBlockingQueue当中放入一条数据的时候,putIndex会被修改,导致消费者缓存中的缓存行失效,需要重新从主内存当中去拉取,这种无法充分利用缓存行的情况被叫做内存伪共享。
对于上述这种情况,一般的解决办法是增大数组元素的间隔长度使得不同的元素位于不同的缓存行当中,但这是一种以空间换时间的做法。
Disruptor的解决方案
1.环形数组结构
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
2.元素位置定位
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
3.无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
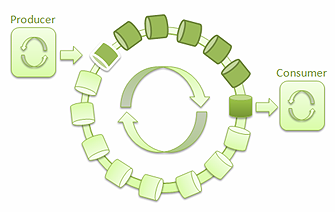
图1:单一生产者和单一消费者的 LMAX Disruptor
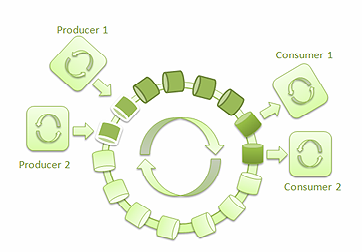
图2:多个生产者和多个消费者的 LMAX Disruptor
日志级别
DEBUG 级别记录一些上下文参数,以及输出结果
INFO 级别记录一些操作成功或者失败,类似于黑盒结果
WARN 级别记录CPU、一些阈值达到了,或者不主要的错误输入输出
补充点
1.排除重复引入的日志jar包
mvn dependency:tree -Dincludes= groupId : artifactId : version 可以不写全,需要执行多次
或
mvn depedency:tree|grep log
正文到此结束
- 本文标签: Collections volatile Logging MQ HashMap log4j2 云 源码 cat 多线程 Select 开发 http 垃圾回收 架构设计 Logback 测试 线程 API 遍历 参数 core Collection bug lambda ssl grep IDE Disruptor 快的 src IO 分布式系统 zab root 数据 App 插件 同步 cache 分布式 QPS apache https UI value 开源 Property Spring Boot 缓存 2019 XEN mina 配置 CTO key final 处理器 id JVM 部署 java db map 空间 XML 锁 queue 希望 equals tk spring tab 安全 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

