Java NIO:浅析 I/O 模型
也许很多朋友在学习NIO的时候都会感觉有点吃力,对里面的很多概念都感觉不是那么明朗。在进入Java NIO编程之前,我们今天先来讨论一些比较基础的知识:I/O模型。下面本文先从同步和异步的概念 说起,然后接着阐述了阻塞和非阻塞的区别,接着介绍了阻塞IO和非阻塞IO的区别,然后介绍了同步IO和异步IO的区别,接下来介绍了5种IO模型,最后介绍了两种和高性能IO设计相关的设计模式(Reactor和Proactor)。
以下是本文的目录大纲:
一.什么是同步?什么是异步?
二.什么是阻塞?什么是非阻塞?
三.什么是阻塞IO?什么是非阻塞IO?
四.什么是同步IO?什么是异步IO?
五.五种IO模型
六.两种高性能IO设计模式
一.什么是同步?什么是异步?
同步和异步的概念出来已经很久了,网上有关同步和异步的说法也有很多。以下是我个人的理解:
同步就是 :如果有多个任务或者事件要发生,这些任务或者事件必须逐个地进行,一个事件或者任务的执行会导致整个流程的暂时等待,这些事件没有办法并发地执行;
异步就是 :如果有多个任务或者事件发生,这些事件可以并发地执行,一个事件或者任务的执行不会导致整个流程的暂时等待。
这就是同步和异步。举个简单的例子,假如有一个任务包括两个子任务A和B,对于同步来说,当A在执行的过程中,B只有等待,直至A执行完毕,B才能执行;而对于异步就是A和B可以并发地执行,B不必等待A执行完毕之后再执行,这样就不会由于A的执行导致整个任务的暂时等待。
如果还不理解,可以先看下面这2段代码:
1void fun1() {
2
3 }
4
5 void fun2() {
6
7 }
8
9 void function(){
10 fun1();
11 fun2()
12 .....
13 .....
14 }
这段代码就是典型的同步,在方法function中,fun1在执行的过程中会导致后续的fun2无法执行,fun2必须等待fun1执行完毕才可以执行。
接着看下面这段代码:
1void fun1() {
2
3}
4
5void fun2() {
6
7}
8
9void function(){
10 new Thread(){
11 public void run() {
12 fun1();
13 }
14 }.start();
15
16 new Thread(){
17 public void run() {
18 fun2();
19 }
20 }.start();
21
22 .....
23 .....
24}
这段代码是一种典型的异步,fun1的执行不会影响到fun2的执行,并且fun1和fun2的执行不会导致其后续的执行过程处于暂时的等待。
事实上,同步和异步是一个非常广的概念,它们的重点 在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。 我觉得可以将同步和异步与Java中的synchronized关键字联系起来进行类比。当多个线程同时访问一个变量时,每个线程访问该变量就是一个事件,对于同步来说,就是这些线程必须逐个地来访问该变量,一个线程在访问该变量的过程中,其他线程必须等待;而对于异步来说,就是多个线程不必逐个地访问该变量,可以同时进行访问。
因此,个人觉得同步和异步可以表现在很多方面,但是记住其关键在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。一般来说,可以通过多线程的方式来实现异步,但是千万记住不要将多线程和异步画上等号,异步只是宏观上的一个模式,采用多线程来实现异步只是一种手段,并且通过多进程的方式也可以实现异步。
二.什么是阻塞?什么是非阻塞?
在前面介绍了同步和异步的区别,这一节来看一下阻塞和非阻塞的区别。
阻塞就是 :当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞就是 :当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于 当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
举个简单的例子:
假如我要读取一个文件中的内容,如果此时文件中没有内容可读,对于同步来说就是会一直在那等待,直至文件中有内容可读;而对于非阻塞来说,就会直接返回一个标志信息告知文件中暂时无内容可读。
在网上有一些朋友将同步和异步分别与阻塞和非阻塞画上等号,事实上,它们是两组完全不同的概念。注意,理解这两组概念的区别对于后面IO模型的理解非常重要。
同步和异步着重点在于多个任务的执行过程中,一个任务的执行是否会导致整个流程的暂时等待;
而阻塞和非阻塞着重点在于发出一个请求操作时,如果进行操作的条件不满足是否会返会一个标志信息告知条件不满足。
理解阻塞和非阻塞可以同线程阻塞类比地理解,当一个线程进行一个请求操作时,如果条件不满足,则会被阻塞,即在那等待条件满足。
三.什么是阻塞IO?什么是非阻塞IO?
在了解阻塞IO和非阻塞IO之前,先看下一个具体的IO操作过程是怎么进行的。
通常来说,IO操作包括:对硬盘的读写、对socket的读写以及外设的读写。
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作,也就是说一个完整的IO读请求操作包括两个阶段:
1)查看数据是否就绪;
2)进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
四.什么是同步IO?什么是异步IO?
我们先来看一下同步IO和异步IO的定义,在《Unix网络编程》一书中对同步IO和异步IO的定义是这样的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
An asynchronous I/O operation does not cause the requesting process to be blocked.
从字面的意思可以看出: 同步IO即 如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;
而 异步IO为 如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的, IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成 。也就是说在异步IO中,不会对用户线程产生任何阻塞。
这是同步IO和异步IO关键区别所在, 同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念。
阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。 也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。
五.五种IO模型
在《Unix网络编程》一书中提到了五种IO模型,分别是:阻塞IO、非阻塞IO、多路复用IO、信号驱动IO以及异步IO。
下面就分别来介绍一下这5种IO模型的异同。
1.阻塞IO模型
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。
当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。
典型的阻塞IO模型的例子为:
1data = socket.read();
如果数据没有就绪,就会一直阻塞在read方法。
2.非阻塞IO模型
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
典型的非阻塞IO模型一般如下:
1while(true){
2 data = socket.read();
3 if(data!= error){
4 处理数据
5 break;
6 }
7}
但是对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
3.多路复用IO模型
多路复用IO模型是目前使用得比较多的模型。Java NIO实际上就是多路复用IO。
在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。
在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。
也许有朋友会说,我可以采用 多线程+ 阻塞IO 达到类似的效果,但是由于在多线程 + 阻塞IO 中,每个socket对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈。
而多路复用IO模式,通过一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用IO比较适合连接数比较多的情况。
另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态时通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。
不过要注意的是,多路复用IO模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用IO模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
4.信号驱动IO模型
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
5.异步IO模型
异步IO模型才是最理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
也就说在异步IO模型中,IO操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用IO函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用IO函数进行实际的读写操作;而在异步IO模型中,收到信号表示IO操作已经完成,不需要再在用户线程中调用iO函数进行实际的读写操作。
注意,异步IO是需要操作系统的底层支持,在Java 7中,提供了Asynchronous IO。
前面四种IO模型实际上都属于同步IO,只有最后一种是真正的异步IO,因为无论是多路复用IO还是信号驱动模型,IO操作的第2个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞。
六.两种高性能IO设计模式
在传统的网络服务设计模式中,有两种比较经典的模式:
一种是 多线程,一种是线程池。
对于多线程模式,也就说来了client,服务器就会新建一个线程来处理该client的读写事件,如下图所示:
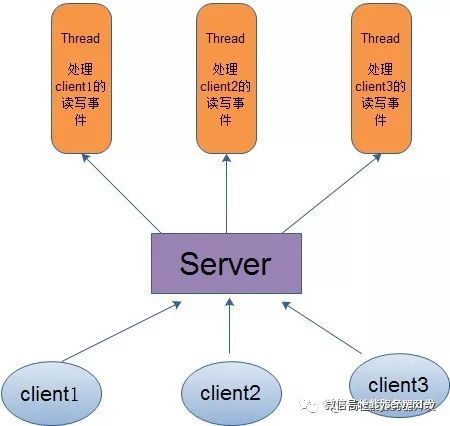
这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。
因此,为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
因此便出现了下面的两种高性能IO设计模式:Reactor和Proactor。
在Reactor模式中,会先对每个client注册感兴趣的事件,然后有一个线程专门去轮询每个client是否有事件发生,当有事件发生时,便顺序处理每个事件,当所有事件处理完之后,便再转去继续轮询,如下图所示:
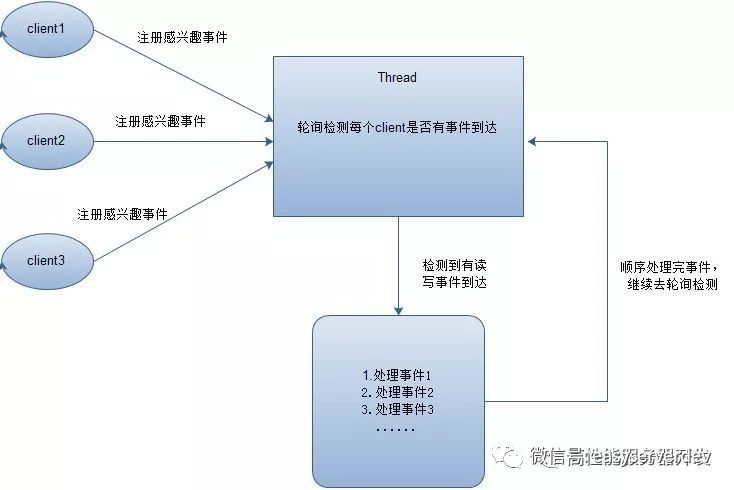
从这里可以看出,上面的五种IO模型中的多路复用IO就是采用Reactor模式。注意,上面的图中展示的 是顺序处理每个事件,当然为了提高事件处理速度,可以通过多线程或者线程池的方式来处理事件。
在Proactor模式中,当检测到有事件发生时,会新起一个异步操作,然后交由内核线程去处理,当内核线程完成IO操作之后,发送一个通知告知操作已完成,可以得知,异步IO模型采用的就是Proactor模式。
在我们开始进入Java NIO编程主题。NIO是Java 4里面提供的新的API,目的是用来解决传统IO的问题。本文下面分别从Java NIO的几个基础概念介绍起。
以下是本文的目录大纲:
一.NIO中的几个基础概念
二.Channel
三.Buffer
四.Selector
若有不正之处,请多多谅解并欢迎批评指正。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3919162.html
一.NIO中的几个基础概念
在NIO中有几个比较关键的概念:Channel(通道),Buffer(缓冲区),Selector(选择器)。
首先从Channel说起吧,通道,顾名思义,就是通向什么的道路,为某个提供了渠道。在传统IO中,我们要读取一个文件中的内容,通常是像下面这样读取的:
1public class Test {
2 public static void main(String[] args) throws IOException {
3 File file = new File("data.txt");
4 InputStream inputStream = new FileInputStream(file);
5 byte[] bytes = new byte[1024];
6 inputStream.read(bytes);
7 inputStream.close();
8 }
9}
这里的InputStream实际上就是为读取文件提供一个通道的。
因此可以将NIO 中的Channel同传统IO中的Stream来类比,但是要注意,传统IO中,Stream是单向的,比如InputStream只能进行读取操作,OutputStream只能进行写操作。而Channel是双向的,既可用来进行读操作,又可用来进行写操作。
Buffer(缓冲区),是NIO中非常重要的一个东西,在NIO中所有数据的读和写都离不开Buffer。比如上面的一段代码中,读取的数据时放在byte数组当中,而在NIO中,读取的数据只能放在Buffer中。同样地,写入数据也是先写入到Buffer中。
下面介绍一下NIO中最核心的一个东西:Selector。可以说它是NIO中最关键的一个部分,Selector的作用就是用来轮询每个注册的Channel,一旦发现Channel有注册的事件发生,便获取事件然后进行处理。
比如看下面的这个例子:
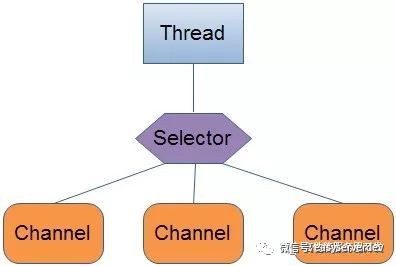
用单线程处理一个Selector,然后通过Selector.select()方法来获取到达事件,在获取了到达事件之后,就可以逐个地对这些事件进行响应处理。
二.Channel
在前面已经提到,Channel和传统IO中的Stream很相似。虽然很相似,但是有很大的区别,主要区别为:通道是双向的,通过一个Channel既可以进行读,也可以进行写;而Stream只能进行单向操作,通过一个Stream只能进行读或者写;
以下是常用的几种通道:
FileChannel
SocketChanel
ServerSocketChannel
DatagramChannel
通过使用FileChannel可以从文件读或者向文件写入数据;通过SocketChannel,以TCP来向网络连接的两端读写数据;通过ServerSocketChanel能够监听客户端发起的TCP连接,并为每个TCP连接创建一个新的SocketChannel来进行数据读写;通过DatagramChannel,以UDP协议来向网络连接的两端读写数据。
下面给出通过FileChannel来向文件中写入数据的一个例子:
1public class Test {
2 public static void main(String[] args) throws IOException {
3 File file = new File("data.txt");
4 FileOutputStream outputStream = new FileOutputStream(file);
5 FileChannel channel = outputStream.getChannel();
6 ByteBuffer buffer = ByteBuffer.allocate(1024);
7 String string = "java nio";
8 buffer.put(string.getBytes());
9 buffer.flip(); //此处必须要调用buffer的flip方法
10 channel.write(buffer);
11 channel.close();
12 outputStream.close();
13 }
14}
通过上面的程序会向工程目录下的data.txt文件写入字符串"java nio", 注意在调用channel的write方法之前必须调用buffer的flip方法,否则无法正确写入内容,至于具体原因将在下篇博文中具体讲述Buffer的用法时阐述。
三.Buffer
Buffer,故名思意,缓冲区,实际上是一个容器,是一个连续数组。Channel提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由Buffer。具体看下面这张图就理解了:
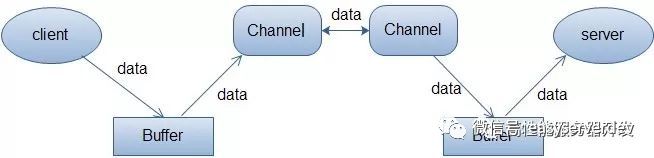
上面的图描述了从一个客户端向服务端发送数据,然后服务端接收数据的过程。客户端发送数据时,必须先将数据存入Buffer中,然后将Buffer中的内容写入通道。服务端这边接收数据必须通过Channel将数据读入到Buffer中,然后再从Buffer中取出数据来处理。
在NIO中,Buffer是一个顶层父类,它是一个抽象类,常用的Buffer的子类有:
ByteBuffer
IntBuffer
CharBuffer
LongBuffer
DoubleBuffer
FloatBuffer
ShortBuffer
如果是对于文件读写,上面几种Buffer都可能会用到。但是对于网络读写来说,用的最多的是ByteBuffer。
关于Buffer的具体使用以及它的limit、posiion和capacity这几个属性的理解在下一篇文章中讲述。
四.Selector
Selector类是NIO的核心类,Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
与Selector有关的一个关键类是SelectionKey,一个SelectionKey表示一个到达的事件,这2个类构成了服务端处理业务的关键逻辑。
欢迎关注公众号『easyserverdev』。如果有任何技术或者职业方面的问题需要我提供帮助,可通过这个公众号与我取得联系,此公众号不仅分享高性能服务器开发经验和故事,同时也免费为广大技术朋友提供技术答疑和职业解惑,您有任何问题都可以在微信公众号直接留言,我会尽快回复您。

正文到此结束
- 本文标签: TCP 开发 kk id tk ip 数据 设计模式 操作系统 免费 服务端 tag db UI 时间 key 文章 短连接 并发 unix cat Select Word 长连接 stream 协议 进程 代码 Android http IO Reactor 服务器 线程 多线程 HTML src NIO synchronized java tar Netty CTO client 微信公众号 session 目录 API UDP 同步 线程池 模型 https 管理
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

