手写Spring---配置config相关(5)
1.使用简单,改动灵活 2.不需要改动代码 复制代码
此时我们可以简单地做一下对比,以下是上一篇的测试代码中截取的一小段
GeneralBeanDefinition bd = new GeneralBeanDefinition();
bd.setBeanClass(ABean.class);
List<Object> args = new ArrayList<>();
args.add("abean01");
args.add(new BeanReference("cbean"));
bd.setConstructorArgumentValues(args);
bf.registerBeanDefinition("abean", bd);
bd = new GeneralBeanDefinition();
bd.setBeanClass(CBean.class);
args = new ArrayList<>();
args.add("cbean01");
bd.setConstructorArgumentValues(args);
bf.registerBeanDefinition("cbean", bd);
// 前置增强advice bean注册
bd = new GeneralBeanDefinition();
bd.setBeanClass(MyBeforeAdvice.class);
bf.registerBeanDefinition("myBeforeAdvice", bd);
复制代码
我们日常使用bean的方式有xml和注解的方式,以上的方式太过于繁琐了,所以我们之后希望提供一个使用xml这样的方式
<bean id = "abean" class = "MySpring.samples.ABean">
<constructor-arg type = "String" value = "abean01">
<constructor-arg ref = "cbean">
</bean>
复制代码
这样用户就会用的更加轻便
※ ② 配置方式的工作过程(非常重要,之后实现过程会按照以下流程进行)
定义一套xml标记---> 用户使用xml标记配置bean定义---> 用户xml配置文件---> 加载xml配置---> 解析xml配置---> 创建bean定义对象---> 注册bean定义到beanFactory 定义一套注解---> 用户在类上用注解标注bean定义---> 用户指定扫描的包---> 扫描指定包下的类---> 反射获取bean定义 ---> 创建bean定义对象---> 注册bean定义到beanFactory 最后两步是一样的,前面是比较相似的 复制代码
2.配置Config的实现
定义一套xml标记/注解
我们此时还不知道该从何入手,这些标记/注解该怎么定义,我们不难发现上面工作过程中它们都是对bean定义进行处理的,所以我们就可以开始分析了
1.bean定义需要指定什么信息(回顾BeanDefinition.class)?
Class<?> getBeanClass(); String getScope(); boolean isSingleton(); boolean isPrototype(); String getFactoryBeanName(); String getFactoryMethodName(); String getInitMethodName(); String getDestroyMethodName(); List<?> getConstructorArgumentValues(); public Object[] getConstructorArgumentRealValues(); public Constructor<?> getConstructor(); public Method getFactoryMethod(); List<PropertyValue> getPropertyValues(); 复制代码
比照我们日常使用时的xml
<beans>
<bean id="" class="" init-method="" destory-method="" scope="">
<constructor-arg type = "String" value = "abean01">
<constructor-arg ref = "cbean">
<property name="" value="">
...
</bean>
...
</beans>
复制代码
此时或许我们需要为此提供一个DTD或者XSD文档来说明用户该如何使用xml文档
2.注解方面的定义(也是参照BeanDefinition.class来定义)
1.指定类 2.指定beanName 3.指定scope 4.指定工厂方法 5.指定工厂bean 6.指定init method 7.指定destory method 8.指定构造参数依赖 9.指定属性依赖 复制代码
其中 1~7 我们可以定义一个 @Component 注解来完成
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Component {
String name() default "";
String scope() default BeanDefinition.SCOPE_SINGLETON;
String factoryBeanName() default "";
String factoryMethodName() default "";
String initMethodName() default "";
String destoryMethodName() default "";
}
复制代码
8,9我们可能就需要一个 @Autowired 和 @Qualifier,以下代码举例说明我们如何使用
@Component(initMethodName = "init",destoryMethodName = "destory")
public class ABean {
private String name;
private CBean cb;
@Autowired
private DBean dBean;
@Autowired
public ABean(@Value("说出你的愿望吧")String name, @Qualifier("CBean01")CBean cb){
super();
this.name = name;
this.cb = cb;
System.out.println("调用了含有CBean的构造方法");
}
}
复制代码
此时 @Component 注解加到类上面,表面它要成为一个bean,然后指定了初始化和销毁方法,此时我们已经不需要在 @Component 中再指定bean的名称了,因为我们已经在取到注解的时候是通过反射来取的,那时候已经取到了类的名称了。构造方法上面加入了 @Autowired ,表明我们创建该bean时应该调用此构造方法,在 ABean 的构造方法中,我们依赖了 CBean ,此时我们可能创建了 CBean 的多个实例呀,所以 @Qualifier 可以指定我们需要取到的就是名字叫做 CBean01 的那个实例吗,@Value 就是给定直接值的做法,比如名字。
3. 其他一些实现了依赖注入的包
① Java标准规范---javax.inject包
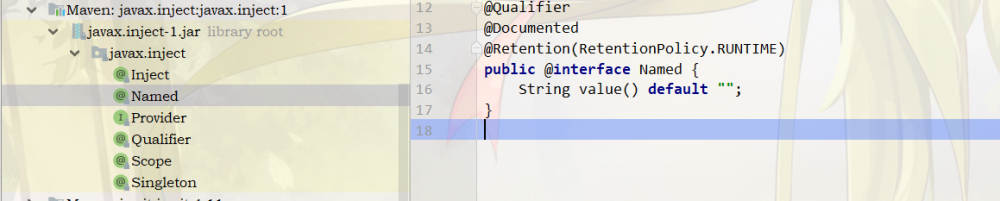
这里面定义了一些注解是用于实现依赖注入的,其中Named等同于刚刚的 @Component 注解,还有Qualifier和Scope等等也是一样的
② javax.Annocation(类同)
这里Resource是组件,postConstruct是指定初始化方法,preDestroy是销毁方法等
以上的这些在我们自己无法实现注入的情况下可以直接使用或者说借鉴它们来实现
用户如何指定自己的xml(扫描的包)
还记得前面我们总结的工作流程吗?
用户xml配置文件---> 加载xml配置---> 解析xml配置 用户指定扫描的包---> 扫描指定包下的类---> 反射获取bean定义 之后都是: 创建bean定义对象---> 注册bean定义到beanFactory 我们首先搞清楚这些步骤应该都会出现在哪个位置中 复制代码
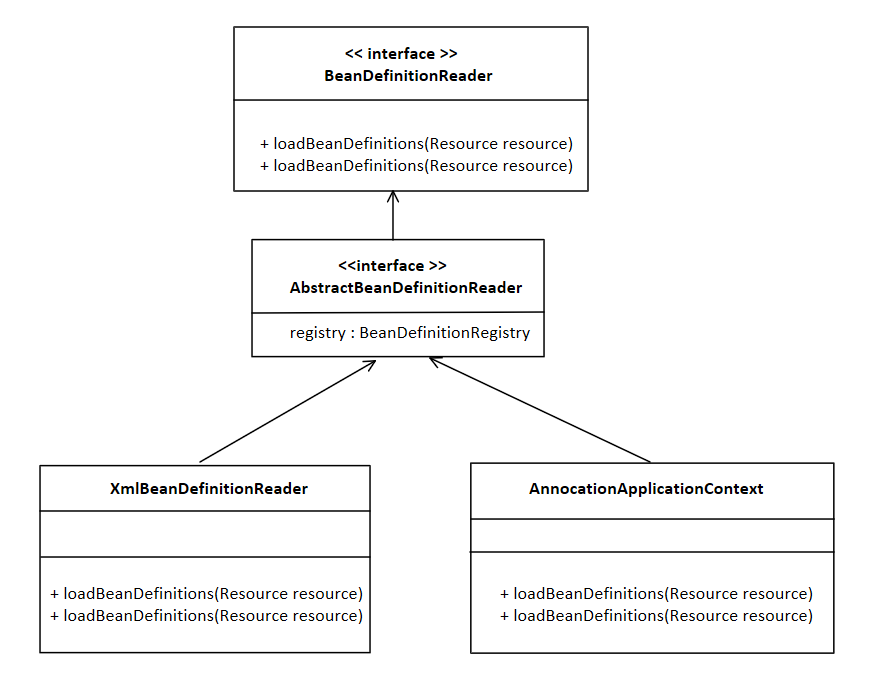
首先看 用户指定扫描的包---> 扫描指定包下的类---> 反射获取bean定义 这里所作的事情为解析bean配置,向BeanFactory注册bean定义,它不是beanFactory的事情,所以我们应该把它独立出来作为一个接口
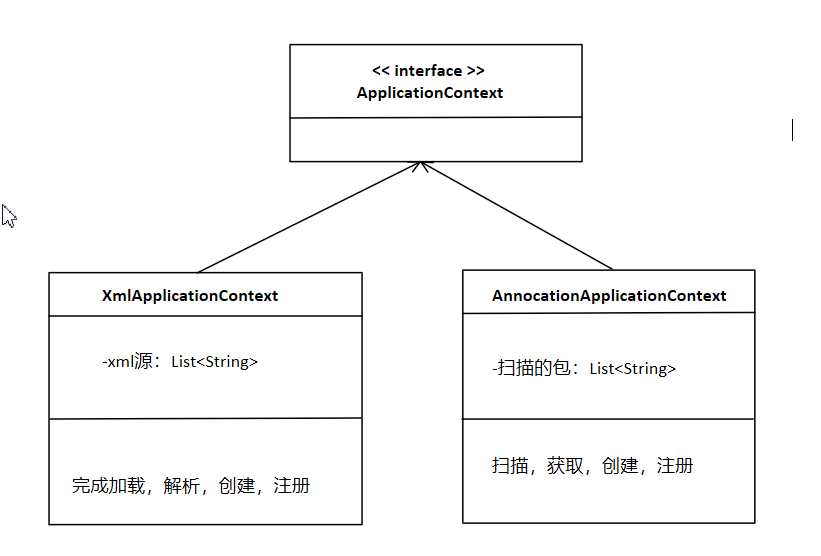
此时我们发现了,它们都要使用BeanFactory--->BeanDefinitionRegistry,所以我们在中间给它加一层抽象,持有BeanFactory
此时我们也可以进一步的设想,XmlApplicationContext中完成bean的加载,解析,创建注册,AnnocationApplicationContext中扫描后获取再创建注册,他们对bean进行了这些处理,是一定用到了我们之前实现了的BeanFactory和BeanDefinitionRegistry的(bean定义注册器).所以XmlApplicationContext和AnnocationApplicationContext都必须持有bean工厂,这时候就如下图,抽象类AbstractApplicationContext就持有了beanFactory
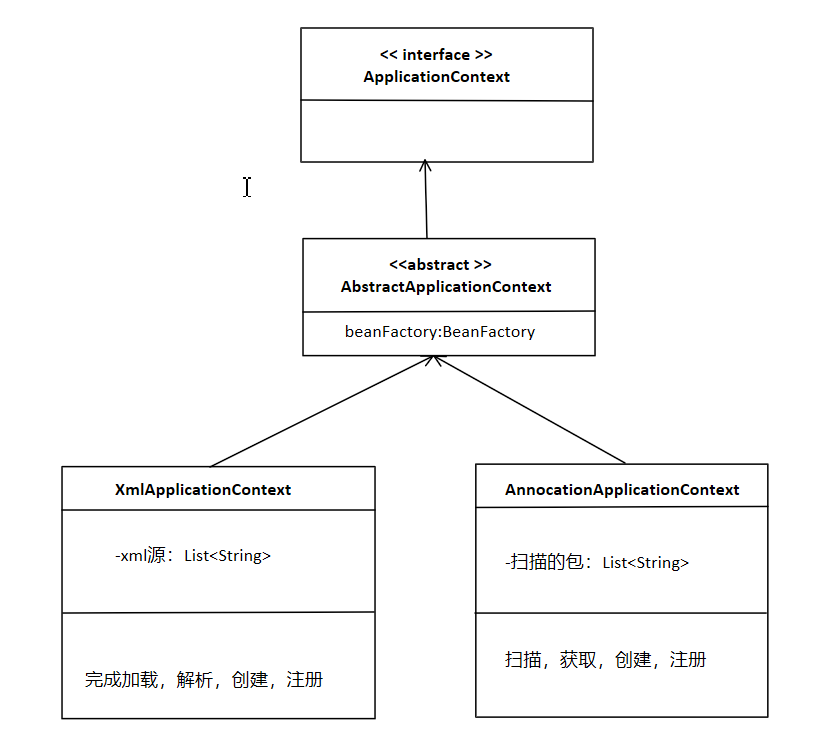
要知道以上图中的接口和类才能清楚了解他如何使用我们的框架,当然还有获取bean时使用的BeanFactory,但是我们此时会想到,用户可能使用框架的时候不想去了解太多这些东西,如果能把用户的这个学习成本降下来的话会更好,所以最好就是让用户只需要知道ApplicationContext及其子类是最好的,此时我们很容易想到的就是外观模式,把两者合并,让ApplicationContext也实现BeanFactory,然后beanFactory的行为实现统一写在抽象类中即可
如何实现xml的加载或者是注解的扫描
① xml的来源会有多种
文件系统,Classpath,URL,String··· 它们加载的方式也不一样,对于xml解析,想获得的仅仅为加载过程中的InputStream 所以我们只需要提供一个getInputStream的方式,后端获得流去解析即可,前面的加载过程可以不再关心 复制代码
此时我们将会这样设计
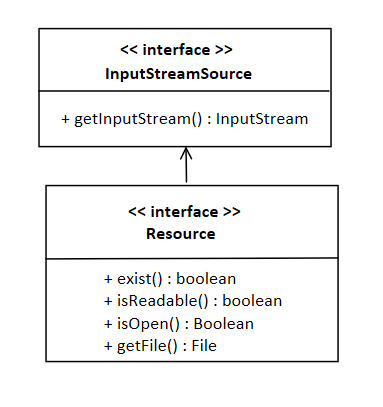
加入Resource接口提供了更多的方法,这样用途会更广,而且我们之后也基于Resource接口去实现,之后就是对于不同来源的处理,编写出FileSystemResource,ClassPathResource,UrlResource
② 这里我们定义不同的Resource类对应不同的xml来源
如何分辨创建它们的对象,因为用户给出的肯定是对于他们来说最容易接受的还是提供字符串形式的数据,这个分辨字符串创建对应的resource的工作就是加载,这个分辨可以交由给ApplicationContext来做
然而根据不同类型创建不同对象,其实也就是有点工厂模式的味道了,那我们的计划就是编写一个ResourceLoader接口去提供一个getResource()方法即可
那分辨的功能到底如何来做,我们只能对xml的来源指定规则,FileSystem的前缀是file,Classpath的前缀是classpath,url开头的不需要指定,本身就是有协议的,那工厂根据前缀来区分创建不同的Resource的对象
③ 注解方式如何进行扫描
到指定的包目录下找出所有的类文件,此时我们也是要独立出一个接口PathMatcher去实现这个功能的,我们这时候采用的是Ant Path表达式的方式(比如springMVC中的RequestMapping里面的路径也是用ant).

之后找到所有的.class文件后,我们需要的是类的名称(全限定类名),此时我们回忆,刚刚我们玩xml的时候,是否有一个接口Resource提供了getFile()方法,此时我们的实现中存在一个FileSystemResource的实现类,里面是持有File类型的file对象的
此时我们又回到谁来扫描的这件事情来,我们决定将扫描的事情外包给一个类 ClassPathBeanDefinitionScanner 去做,里面提供 scan(String...package) 方法,里面可以给入多个包,里面持有 BeanDefinitionRegistry 对象,之后之前的 AnnocationApplicationContext 就直接持有 ClassPathBeanDefinitionScanner的scanner 对象即可
在哪里启动扫描才是正确的呢,答案是 AnnocationApplicationContext 的构造方法中即可
解析xml,反射获取bean定义注解
加载和扫描的输出是什么?
Resource!!! 复制代码
这里就是两个方法,从resource里面加载bean定义,放入bean工厂里面去进行注册,抽象里面持有bean定义注册器即可
到目前为止,我们已经把整个架子都搭好了,接下来只是往架子里面填写相应的代码即可,相应的代码因为时间问题没来得及放入文章,以后会找机会补上,以后会继续更源码的东西,共勉,谢谢
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

