99.9%的Java程序员都说不清的问题:JVM中的对象内存布局?
点击上方 石杉的架构笔记 ,右上选择“ 设为星标 ”
每日早8点半,精品技术文章准时送上
往期文章
BAT 面试官是如何360°无死角考察候选人的(上篇)
每秒上万并发下的Spring Cloud参数优化实战
分布式事务如何保障实际生产中99.99%高可用
记一位朋友斩获 BAT 技术专家Offer的面试经历
亿级流量架构系列之如何支撑百亿级数据的存储与计算
作者:李瑞杰
目前就职于阿里巴巴,资深 JVM 研究人员
在 Java 程序中,我们拥有多种新建对象的方式。除了最为常见的 new 语句之外,我们还可以通过反射机制、Object.clone 方法、反序列化以及 Unsafe.allocateInstance 方法来新建对象。
其中,Object.clone 方法和反序列化通过直接复制已有的数据,来初始化新建对象的实例字段。
Unsafe.allocateInstance 方法则没有初始化实例字段,而 new 语句和反射机制,则是通过调用构造器来初始化实例字段。
我们先来考察new语句,准备一个类,如下图所示

让我们编译他的字节码:
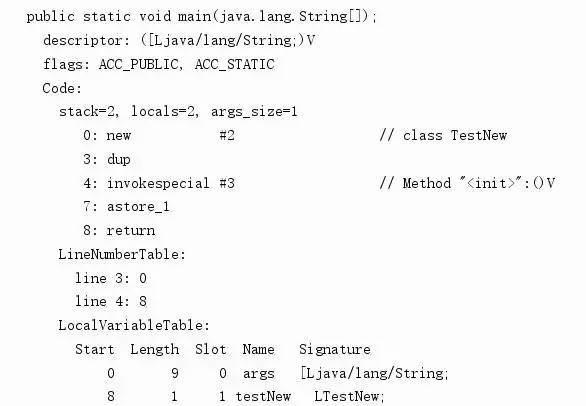
可以看到,new语句编译而成的字节码将包含用来请求内存的 new 指令,以及用来调用构造器的 invokespecial 指令。
本文不是专门介绍invoke系列指令的,我会在后面的文章中介绍invoke系列指令。
不过在这里我多说一嘴, 字节码中的invokespecial指令通常用于调用私有实例方法、构造器,以及使用super关键字调用父类的实例方法或构造器,和所实现接口的默认方法。
提到构造器,就不得不提到 Java 对构造器的诸多约束。首先,如果一个类没有定义任何构造器的话, Java 编译器会自动添加一个无参数的构造器。
我们刚才的TestNew类,他的字节码编译出来后,有下面的片段。

在JAVA源码中,我们没有定义构造器,但是生成出来的字节码,已经自动帮我们添加了一个无参数的构造器。他使用的invokespecial方法最终调用的是其父类Object类的构造器方法。
我将讲述JVM的构造器调用原则,那就是,如果子类的构造器需要调用父类的构造器。如果父类存在无参数构造器的话,该调用可以是隐式的。也就是说, Java 编译器会自动添加对父类构造器的调用。
但是,如果父类没有无参数构造器,那么子类的构造器则需要显式地调用父类带参数的构造器。
显式调用有两种,一是直接使用“super”关键字调用父类构造器,二是使用“this”关键字调用同一个类中的其他构造器。
无论是直接的显式调用,还是间接的显式调用,都需要作为构造器的第一条语句,以便优先初始化继承而来的父类字段。
可以不优先初始化继承来的父类字段吗? 可以,如果你能使用字节码注入工具的话。
当我们调用一个构造器时,它将优先调用父类的构造器,直至 Object 类。这些构造器的调用者皆为同一对象,也就是通过 new 指令新建而来的对象。
事实上,我上面的陈述意味着:通过 new 指令新建出来的对象,它的内存其实涵盖了所有父类中的实例字段。
也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
下面我将介绍 压缩指针技术 。在 Java 虚拟机中,每个 Java 对象都有一个对象头,它由标记字段和类型指针所构成。
标记字段用以存储 Java 虚拟机有关该对象的运行数据,如哈希码、GC 信息以及锁信息,而类型指针则指向该对象的类。
在64位的JVM中,对象头的标记字段占 64 位,而类型指针又占了 64 位。也就是说,每一个 Java 对象在内存中的额外开销就是 16 个字节。
为了尽量较少对象的内存使用量,64位JVM引入了压缩指针的概念,将堆中原本64位的Java对象指针压缩成32位的。
这样一来,对象头中的类型指针也会被压缩成32位,使得对象头的大小从16字节降至12字节。
当然,压缩指针不仅可以作用于对象头的类型指针,还可以作用于引用类型的字段,以及引用类型数组。
它的原理是什么?答案是 内存对齐 。
我们规定,默认情况下,JVM堆中对象的起始地址需要对齐至8的倍数,如果一个对象用不到8N 个字节,那么空白的那部分空间就浪费掉了, 这些浪费掉的空间我们称之为对象间的填充。
大家知道,指针里面存放的是地址,由于堆中对象的起始地址是对齐至8的倍数,所以指针存放一个引用(或者对象的类)的内存地址时,根本就不用存放最后的三位二进制数。
因为所有对象或类的内存地址都对齐了8,所以他们的内存地址的最低三位总是0,32位的指针就可以寻址到 2 的 35 次方个字节,也就是 32GB 的地址空间(超过 32GB 则会关闭压缩指针)。
我们可以通过配置虚拟机的内存对齐选项来进一步提升寻址范围。但是,这同时也可能增加对象间填充,导致压缩指针没有达到原本节省空间的效果。
就算是关闭了压缩指针,Java 虚拟机还是会进行内存对齐。此外,内存对齐不仅存在于对象与对象之间,也存在于对象中的字段之间。
比如说,Java 虚拟机要求long字段、double字段,以及非压缩指针状态下的引用字段地址为8的倍数。
这是为什么呢?
CPU的缓存行机制大家应该有所耳闻,如果字段不是对齐的,那么就有可能出现跨缓存行的字段。
该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。
我们将在后期文章关于volatile关键词的本质分析的过程中,再次考察到CPU缓存行的相关机制。
最后我要提一句的是, 字段重排列技术 ,就是我刚才提到的,对象的字段之间存在的内存对齐。这指的是重新分配字段的先后顺序,以达到内存对齐的目的
它有以下 两个规则:
其一
,如果一个字段占据C个字节,那么该字段的偏移量需要对齐至NC。这里的偏移量指的是字段地址与对象的起始地址差值。
以Long类为例,它仅有一个long类型的实例字段。在使用了压缩指针的 64 位虚拟机中,尽管对象头的大小为12个字节,该 long 类型字段的偏移量也只能是16,而中间空着的4个字节便会被浪费掉。
其二 ,子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
说白了,比如B继承了A,A是B的父类,A中所有的字段,在B中都有,而且是先放A的字段,再放B的字段。而且B类对象放A类字段时,需要与父类对应字段的偏移量保持一致。
接下来我说一个拓展内容吧 ,什么是虚共享?
假设两个线程分别访问同一对象中不同的 volatile 字段,逻辑上它们并没有共享内容,因此不需要同步。
如果这两个字段恰好在同一个缓存行中,那么对这些字段的写操作会导致缓存行的写回,也就造成了实质上的共享。
Java8还引入了一个新的注释@Contended,用来解决对象字段之间的虚共享。
Java 虚拟机会让不同的@Contended字段处于独立的缓存行中,因此你会看到大量的空间被浪费掉,避免无谓的缓存行同步操作。
具体的算法属于实现细节了,大家有兴趣可以去用:
-XX:-RestrictContended
这个虚拟机选项,查看Contended字段的内存布局。
END
划至底部,点击“ 在看 ”,是你来过的仪式感!
推荐阅读:
-
简历写了会Kafka,面试官90%会让你讲讲acks参数对消息持久化的影响!
-
面试最让你手足无措的一个问题:你的系统如何支撑高并发?
-
Java高阶必备:如何优化Spring Cloud微服务注册中心架构?
-
高并发场景下,如何保证生产者投递到消息中间件的消息不丢失?
-
从团队自研的百万并发中间件系统的内核设计看Java并发性能优化!
-
如果20万用户同时访问一个热点缓存,如何优化你的缓冲架构?
更多文章:
-
2018年原创汇总
-
2019年原创汇总(持续更新)
-
爆款推荐
-
面试专栏
欢迎长按下图关注公众号 石杉的架构笔记

BAT架构经验倾囊相授

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

