『互联网架构』软件架构-rocketmq之性能测试(63)
一起了解rocketmq的性能,以及阿里是如何应用rocketmq的。

(一)MQ性能测试原理
1.基本概念
- Producer
消息生产者,负责产生消息,一般由业务系统负责产生消息。
- Consumer
消息消费者,负责消费消息,一般是后台系统负责异步消费。
- Topic
消息主题,负责标记一类消息,生产者将消息发送到Topic,消费者从该Topic消费消息。
- Broker
消息中转角色,负责存储消息,转发消息,一般也称为 Server,在 JMS 规范中称为 Provider。
- NameServer
服务发现Server,用于生产者和消费者获取Broker的服务。
- Broker吞吐量——TPS
每秒钟Broker接收或者投递的消息条数。
2.组件架构图
这个图在明白不过了吧。
1) Producer 和 Consumer 与NameServer要建立长连接。
2)Topic里面的NameServer地址找到对应的Broker。
3)在实际中Producer,Consumer,NameServer都不是单点的。
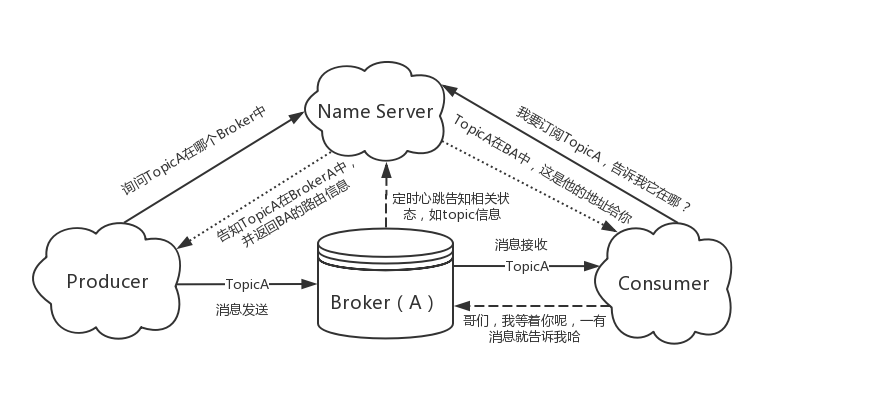
3.部署图
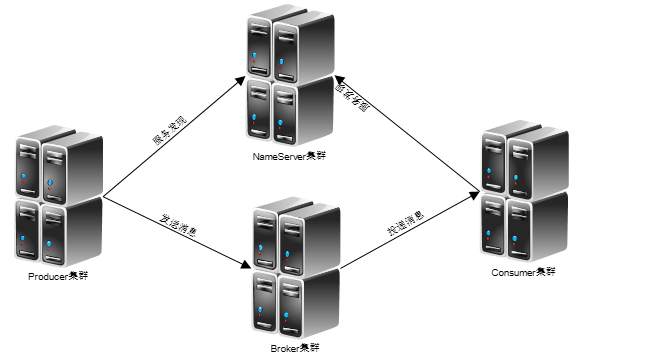
4.真正需要压测的组件
1) MQ真正用来投递和转发消息的组件是Broker,因此压测的对象是Broker。
2) MQ Broker组件吞吐量理论上来说具有水平扩展能力,即N台Broker是单台Broker吞吐量的N倍,因此压测通常部署单个节点Broker。
3) NameServer通常用来客户端服务发现,消息收发的请求对NameServer基本没有压力,因此测试过程中NameServer可单点部署。
(二)MQ性能测试基本场景
真实的环境nameserver是2个,一个nameserver不工作另一个nameserver可以提供正常的服务。阿里一般部署4个为了容灾。
1.Broker接收消息的能力
接收的能力其实就是producer集群发送信息的量,rocketMq端启动多个Broker来进行发送消息,在这种情况下没有消息端,纯粹来看broker接收消息的能力,为什么把这种场景单独列出来,也就是在以往的测试过程中,broker瓶颈是在接收消息这里,消费对于broker一般没有什么压力,它只要把消息投递出去就可以了,但是对于接收消息,它需要把请求进行反序列化,做个存储,这个非常消耗硬件的资源,所以通常来说broker接收消息的能力远小于他的投递能力的,消息的接收能力也是broker最重要的指标之一,所以一般情况把接收消息的能力单独放在一个场景下进行测试。有时候项目比较赶,其实很多时候只做消息发送的测试就足够了。
2.Broker同时接收消息并投递消息的能力
这个更加符合我们使用的场景:为了测试Broker同时接收和投递消息的能力,Producer以及Consumer通过NameServer连接到Broker,每个Producer的逻辑即无限循环无间断发送消息,Consumer等待消息投递;
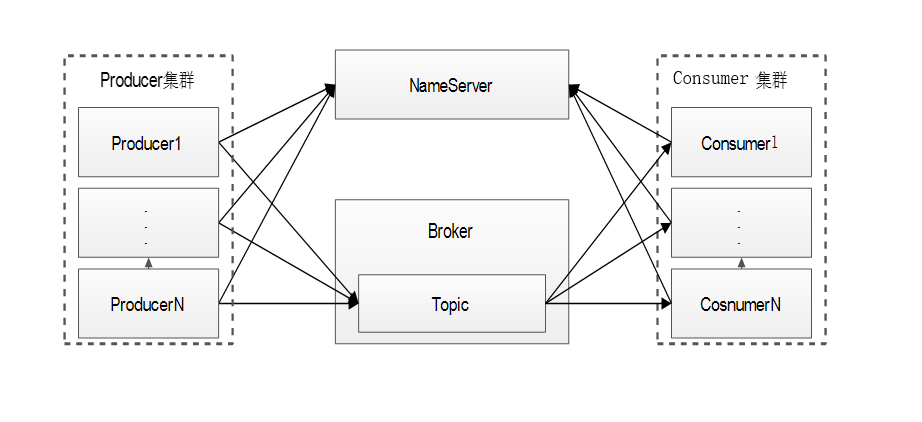
(三)MQ性能影响因素及相应测试手段
三大类:客户端的因素,客户端本身应用的因素,硬件的配置。
1.客户端因素
- 消息大小
> 1)1K(1024)字节
> 2)4K字节
> 3)6K字节 - 测试方式
> Producer发送的消息体长度设置为相应的长度即可,所有的消息投递到同一个Topic中。(这个跟kafka不同,kafka同样的物理机,同样的并发数,消息发到一个Topic里面还是多个Topic里面,不一样的kafka是物理上的实体,kafka里面的Q映射的都是物理的文件,消息是写在Q的物理文件上面,当你消息发送到不同的Topic里面去,存储在不同的物理文件中,写消息是随机写的概念,磁盘很容易被打爆了)在rocketMq里面的Topic只是逻辑上的实现,无论发到多个还是一个都是存储到一个物理文件上,按照顺序往后写,所以这时候测试不同的Topic和一个Topic效果是一样的。 - 评估结果
> 消息体越大则Broker的接收TPS越低。
吞吐量和TPS的概念:消息大-TPS越低;消息大-吞吐量是上升的;看业务是追求高TPS还是高吞吐量。
想吞吐量大就需要合并到一起完成消息的发送。
想高并发TPS高就把消息拆开多个消息来进行发送。
2.客户端因素
- 客户端(consumer和Provider)连接数
> 1)连接数少量(<1万)
> 2)连接数较多(1万<10万)
> 3)连接数大量(>10万) - 测试手段
> 初始化push consumer连接到Broker上,发送端发送消息 。一般都不让Provider就有1个或者少于3个,consumer做万级别的。主要查看消费能力。 - 评估结果
> 连接数越多则Broker的接收TPS越低。
3.客户端因素
什么叫消息投递比呢,即一条消息要被几个应用订阅,即一条消息Broker需要投递给多少订阅端,如一个Topic有1个group的消息费端来订阅,则消息投递一次,有5个group,则消息需要投递5次。
* 消息投递比(客户下单了,在应用中发送了一个消息,在地面方可能多个应用支付宝收到的钱,通知物流方取快件,一个消息被多少个订阅方订阅)
1)1:0
2)1:1
3)1:5
4)1:9
* 测试手段【前提不要为了投递给网卡打满了,就是带宽打满】
先初始化若干消费组(0~9),每个组内4~8个消费端,订阅同一个Topic启动Producer,向同一Topic发送消息
* 评估结果
投递比越大则Broker的接收TPS越低。
4.单机应用因素
刷盘:保存到内容就返回,写内存的速度高于写磁盘的速度。
* broker设置的刷盘类型
1)异步刷盘(ASYNC_FLUSH)
2)同步刷盘(SYNC_FLUSH)
* 测试手段
1)Broker配置为相应的刷盘方式。
2)启动Producer,向同一Topic发送消息。
* 评估结果
异步刷盘性能高于同步刷盘(若干倍,使用场景异步速度快,虽然异步比较快,但是对于钱金融这块还是多使用同步刷盘,对硬盘要求很高)
5.单机应用因素
相同配置的物理机优于虚拟机。高配置的机器优于低配置的机器A8系列的物理机优于S7、S9系列的物理机。
* 硬件以及架构
1)物理机
2)虚拟机
3)硬件架构硬件配置(cpu核数、内存大小)
* 测试手段
不同的宿主机结构,采用相同的压测场景,如均为1k消息Broker的接受性能,作为对比。
* 评估结果
硬件架构配置越好,则性能通常越高。
6.单机宿主机因素
网卡1000Mb,全双工,出口入口均为125MB
* 宿主机网卡带宽
1)千兆网卡
2)双千兆网卡
3)万兆网卡
4)双万兆
* 测试手段
不同网卡配置,相同测试场景,大量Producer并发以及大的消息体,查看网卡吞吐量。
* 评估结果
网卡带宽越低,则越有可能会是瓶颈。
7.单机宿主机因素
即磁盘的读取以及写入速度依赖于磁盘的转动速度以及读写的位置,读写越随机则性能越低。
* 宿主机磁盘类型
1)本地机械盘(写的影响不大,Mq本身是顺序写的。读取消息堆积的,机械盘效果很差)
2)本地固态盘(固态盘数据读写随机性不影响写入速度,不同的固态盘性能不通)
3)网络盘,如各种云盘(如果是异步刷盘没什么影响,同步刷盘毕竟走一层网络有点慢。网络盘即数据写入经过网络,然后写入远端盘;)
* 测试手段
不同磁盘类型,相同的压测场景,大量Producer并发发送消息
* 评估结果
固态盘性能高于机械盘,网络盘性能依赖于实测结果
8.单机应用因素
producer 发布了10条消息,第一个组消费了5条消息,第二个组消息8条,对于第一个组堆积了5条消息,第二个组堆积了2条消息。没有消费的消息就叫堆积。
内存不够的情况下,堆积的消息落到磁盘里面了,这时候从磁盘读开销IO很大,会跟消息的存储和其他IO进行竞争,竞争的结果影响整个的性能,异步刷盘,刷的很慢,同步就不说,肯定慢死,发送端的性能下降,消费也很慢。一个消费的堆积可能蝴蝶效应打垮整个mq的服务。所以尽可能不让消费端进行堆积,有报警机制。是不是消费端卡住了,消费端消费不过来了,需要进行消费端的扩容,反正尽量不要堆积。防止堆积。10万的流量,一个机器可以处理5万的流量,不是正好上2台这种刚刚好的情况,而是上10台或者是8台。虽然整体的性能下降但是可以保证系统的稳定性。冗余的重要性。
PS:对于架构来说rocketMq的性能至关重要,只要用到消息队列的都是比较核心的应用,所以很多东西需要处理。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

