DockOne微信分享(二一零):平安证券Kubernetes容器集群的DevOps实践
【编者的话】最近两三年,Docker容器技术及Kubernetes编排调度系统,在DevOps领域,大有星火燎原,一统天下之势。平安证券IT团队一直紧跟最新技术,践行科技赋能。本次分享,聚焦于公司在DevOps转型过程中的几个典型的技术细节的解决方案,希望对同行有所借鉴和帮助。
生产环境的高可用Master部署方案
Kubernetes的高可用Master部署,现在网络上成熟的方案不少。大多数是基于Haproxy和Keepalived实现VIP的自动漂移部署。至于Haproxy和Keepalived,可独立出来,也可寄生于Kubernetes Master节点。
我司在IT设备的管理上有固定的流程,VIP这种IP地址不在标准交付范围之内。于是,我们设计了基于DNS解析的高可用方案。这种方案,是基于Load Balancer变形而来。图示如下:
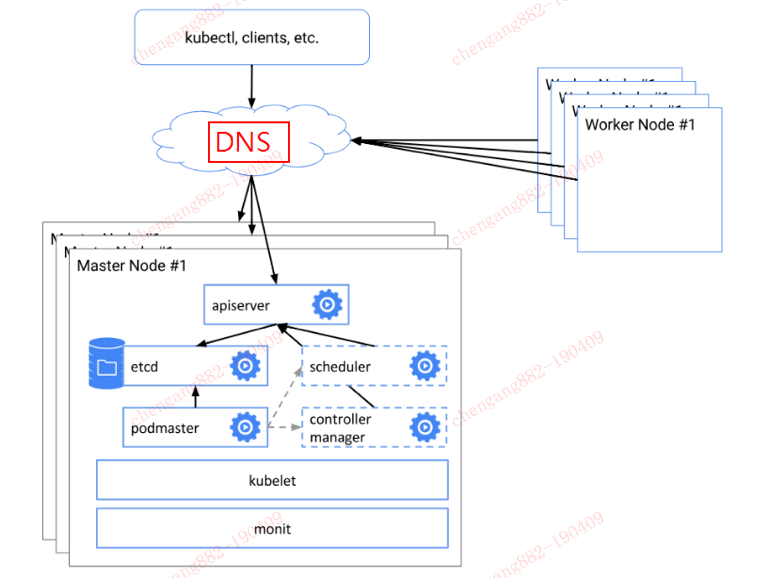
这种构架方案,平衡了公司的组织结构和技术实现。如果真发生Master挂掉,系统应用不受影响,DNS的解析切换可在十分钟内指向新的Master IP,评估在可接受范围之内。
公司内部安装Master节点时,使用的基本工具是Kubeadm,但是作了脚本化改造及替换成了自己的证书生成机制。经过这样的改进之后,使用kubeadm进行集群安装时,就更有条理性,步骤更清晰,更易于在公司进行推广。
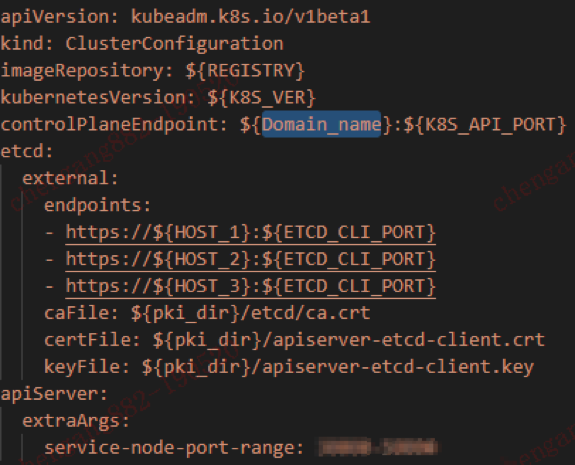
底层的etcd集群使用独立的Docker方式部署,但共享kubeadm相关目录下的证书文件,方便了api-server和etcd的认证通信。脚本的相关配置如下:
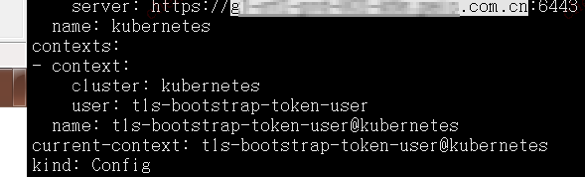
当以DNS域名的形式进行部署后,各个证书配置认证文件,就不会再以IP形式连接,而是以DNS域名形式连接api-server了。如下图所示:
分层的Docker镜像管理
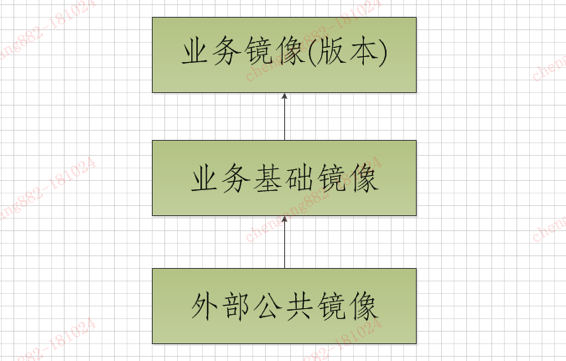
接下来,我们分享一下对Docker镜像的管理。Docker的企业仓库,选用的是业界流行的Harbor仓库。根据公司研发语言及框架的广泛性,采用了三层镜像管理,分为公共镜像,业务基础镜像,业务镜像(tag为部署发布单),层层叠加而成,即形成标准,又照顾了一定的灵活性。
- 公共镜像:一般以alpine基础镜像,加上时区调整,简单工具。
- 业务基础镜像:在公共镜像之上,加入JDK、Tomcat、Node.js、Python等中间件环境。
- 业务镜像:在业务基础镜像之上,再加入业务软件包。
Dashboard、Prometheus、Grafana的安全实践
尽管在Kubernetes本身技术栈之外,我司存在体系化的日志收集,指标监控及报警平台,为了运维工具的丰富,我们还是在Kubernetes内集成了常用的Dashboard、Prometheus、Grafana组件,实现一些即时性运维操作。
那么,这些组件部署,我们都纳入一个统一的Nginx一级url下,二级url才是各个组件的管理地址。这样的设计,主要是为了给Dashborad及Prometheus增加一层安全性(Grafana自带登陆验证)。
这时,可能有人有疑问,Dashboard、kubectl都是可以通过cert证书及RBAC机制来实现安全性的,那为什么要自己来引入Nginx作安全控制呢?
在我们的实践过程中,cert证书及RBAC方式,结合SSH登陆帐号,会形成一系列复杂操作,且推广难度高,我们早期实现了这种模式,但目前公司并不具备条件,所以废弃了。公司的Kubernetes集群,有专门团队负责运维,我们就针对团队设计了这个安全方案。
Prometheus的二级目录挂载参数如下:
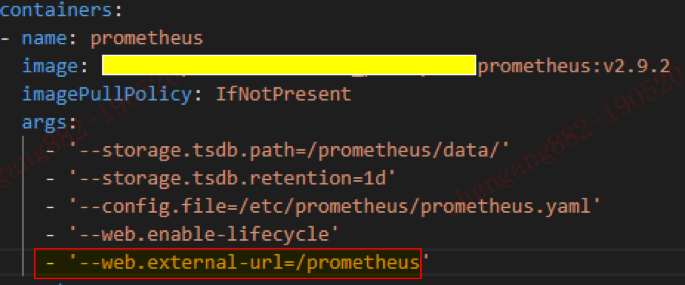
Grafana的二级目录挂载参数如下:
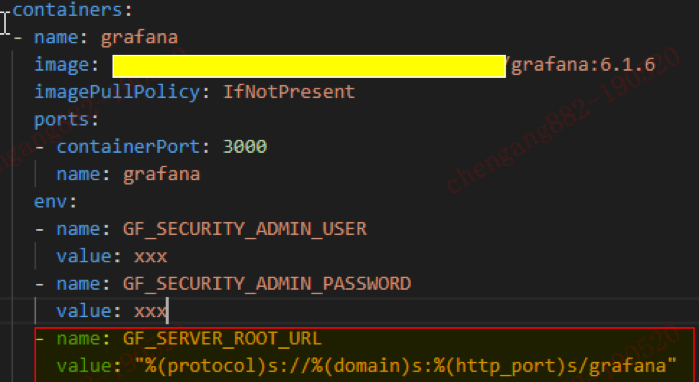
Dashboard在Nginx里的配置如下:
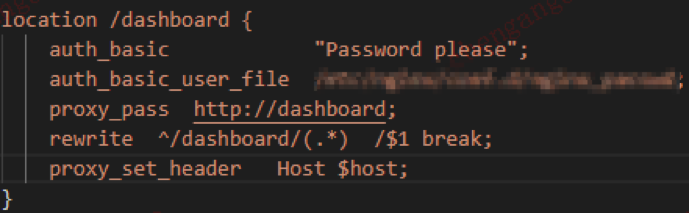
一个能生成所有软件包的Jenkins Job
在CI流水线实践,我们选用的GitLab作为源代码管理组件,Jenkins作为编译组件。但为了能实现更高效标准的部署交付,公司内部实现一个项目名为prism(棱镜)的自动编译分发部署平台。在容器化时代,衍生出一个Prism4k项目,专门针对Kubernetes环境作CI/CD流程。Prism4k版的构架图如下所示:
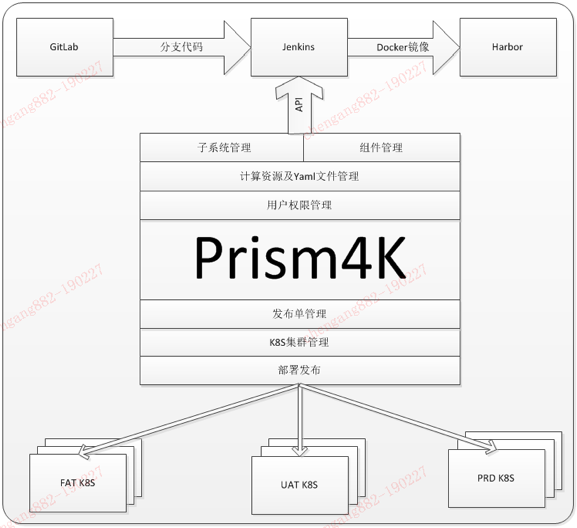
在这种体系下,Jenkins就作为我们的一个纯编译工具和中转平台,高效的完成从源代码到镜像的生成。
由于每个IT应用相关的变量,脚本都已组织好,放到Prism4k上。故而,Jenkins只需要一个Job,就可以完成各样各样的镜像生成功能。其主要Pipeline脚本如下(由于信息敏感,只列举主要流程,有删节):
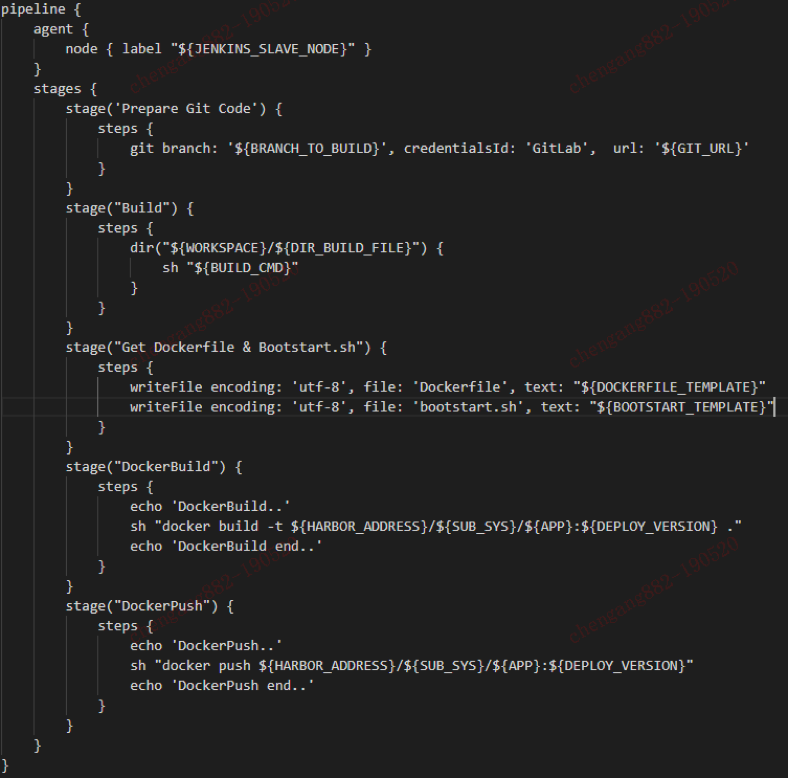
在Jenkins中,我们使用了一个Yet Another Docker Plugin,来进行Jenkins编译集群进行Docker生成时的可扩展性。作到了编译节点的容器即生即死,有编译任务时,指定节点才生成相关容器进行打包等操作。
计算资源在线配置及应用持续部署
在Prism4k平台中,针对Jenkins的Job变量是通过网页配置的。在发布单的编译镜像过程中,会将各个变量通过API发送到Jenkins,启动Jenkins任务,完成指定task任务。
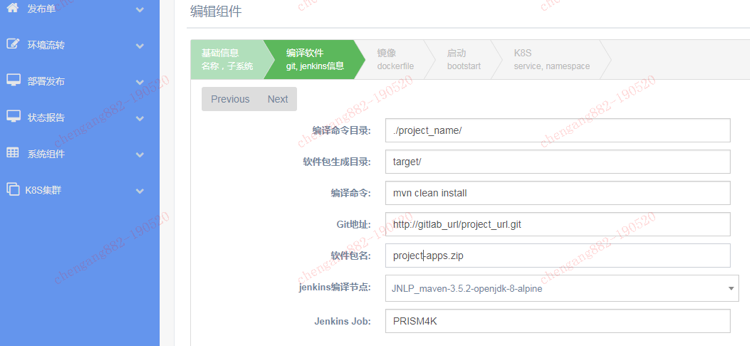
Pod的实例数,CPU和内存的配置,同样通过Web方式配置。

在配置好组件所有要素之后,日常的流程就可以基于不同部门用户的权限把握,实现流水线化的软件持续交付。
- 研发:新建发布单,编译软件包,形成镜像,上传Harbor库。
- 测试:环境流转,避免部署操作污染正在进行中的测试。
- 运维:运维人员进行发布操作。
在FAT这样的测试环境中,为加快测试进度,可灵活的为研发人员赋予运维权限。但在更正式的测试环境和线上生产环境,作为金融行业的IT建设标准,则必须由运维团队成员操作。
下面配合截图,了解一下更具体的三大步骤。
- 发布单
在Prism4k与Jenkins的API交互,我们使用了Jenkins的Python库。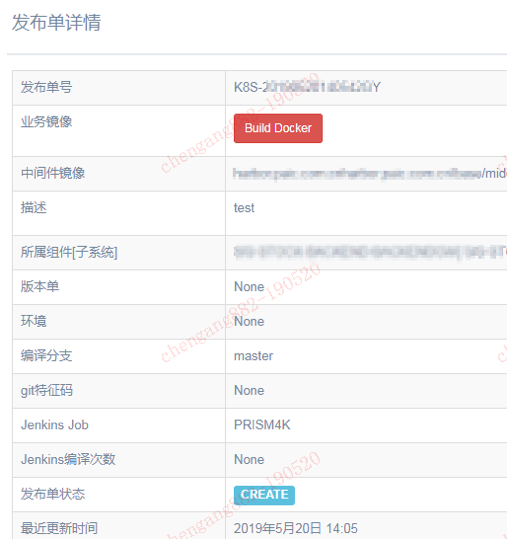
- 环境流转

- 部署
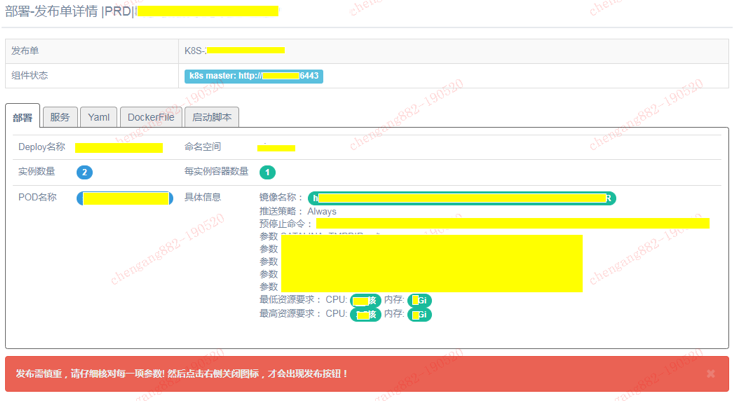
在部署操作过程中,会将这次发布的信息全面展示给运维同事,让运维同事可以进行再次审查,减少发布过程中的异常情况。
总结
由于 Kubernetes 版本的快速更新和发布,我们对于其稳定性的功能更为青睐,而对于实验性的功能,或是需要复杂运维技能的功能,则保持理智的观望态度。所以,我们对Kubernetes功能只达到了中度使用。当然,就算是中度使用,Kubernetes的运维和使用技巧,还是有很多方面在此没有涉及到,希望以后有机会,能和各位有更多的沟通和交流。愿容器技术越来越普及,运维的工作越来越有效率和质量。
Q&A
Q:镜像有进行安全扫描吗:
A:外部基本镜像进入公司内部,我们基于Harbor内置的安全功能进行扫描。
Q:平安证券的Kubernetes团队和平安科技的容器云团队是怎么分工的?
A:平安科技的容器云是成熟而独立的产品。证券的Kubernetes团队更多的是基于自身业务特性作私有Kubernetes云,有需要时,会使用平安科技的容器云产品。
Q:alpine镜像对JDK兼容性如何,听说有glibc的问题,那边怎么处理的?
A:alpine原生的镜像不能直接运行Oracle JDK的。我们是基于alpine+glib来制作JDK镜像的,目前运行未见异常。
Q:Harbor有没有做相关监控,比如发布了多少镜像,以及镜像同步时长之类的?
A:我们没有在Harbor上作扩展,只是在我们自己的Prism4k上,会统计各个项目的一些镜像发布数据。
Q:有没有用Helm来管理镜像包?后端存储是用的什么,原因是?
A:没有使用Helm。目前集群有存储需求时,使用的是NFS。正在考虑建基于Ceph的存储,因为现在接入项目越来越多,不同的需求会导致不同的存储。
Q:想了解下目前贵公司监控的纬度和监控的指标和告警这块。
A:监控方面,我公司也是大致大致划分为基础资源,中间件,业务指标三大块监控。方法论上也是努力在向业务提倡的RED原则靠拢。
Q:怎么不使用一下Rancher来管理呢?
A:Rancher有它擅长的特性,Kubernetes原生有Kubernetes原生的好处。不同的场景和规划,会使用不同的技术方案。公司其它部门也有使用Rancher来作Kubernetes集群管理的。
Q:想了解下,Yaml文件怎么管理的,可以自定义生成吗?
A:我们的Yaml文件,都统一纳到Prism4k平台管理,有一些资源是可以自定义的,且针对不同的项目,有不同的Yaml模板,然后,透过django的模块功能统一作解析。熟悉Yaml书写的研发同事可以自己定义自己项目的Yaml模板。
Q:Master高可用部署,采用域名方式相比于直接使用IP有什么好处与优势呢?
A:采用域名,我在分享中提及,是因为在公司现行的运行体制内设计出来的方案。如果能自己的团队可以全控公司网络和服务资源,我个人也会趋向于VIP的高可用。如果域名方案对于我们团队有优势,是因为这个方案,其它协同部门会同意。:)
Q:Pipeline会使用Jenkinfile来灵活code化Pipeline,把Pipeline的灵活性和创新性还给开发团队,这比一个模板化的统一Pipeline有哪些优势?
A:Pipeline的运行模式,采用单一Job和每个项目自定义Job,各有不同的应用场景。因为我们的Jenkins是隐于幕后的组件,研发主要基于Prism4k操作,可以相对减少研发的学习成本。相对来说,Jenkins的维护人力也会减少。对于研发各种权限比较高的公司,那统一的Job可能并不合适。
Q:想了解下贵公司使用什么网络方案?Pod的网络访问权限控制怎么实现的?
A:公司现在用的是Flannel网络CNI方案。同时,在不同的集群,也有作Calico网络方案的对比测试。Pod的网络权限,这块暂时没有,只是尝试Istio的可行性研究。
Q: 一个Job生成所有的Docker镜像,如果构建遇到问题,怎么去追踪这些记录?
A:在项目前期接入时,生成镜像的流程都作了宣传和推广。标准化的流程,会减少产生问题的机率。如果在构建中遇到问题,Prism4k的界面中,会直接有链接到本次建的次序号。点击链接,可直接定位到Console输出。
Q:遇到节点Node上出现100+ Pod,Node会卡住,贵公司Pod资源怎么做限制的?
A:我们的业务Pod资源,都作了limit和request限制。如果出现有卡住的情况,现行的方案是基于项目作拆分。Prism4k本身对多环境和多集群都是支持的。
Q:多环境下,集中化的配置管理方案,你们选用的是哪个,或是自研的?
A:我们现在正在研发的Prism4k,前提就是要支持多环境多集群的部署,本身的功能里,yaml文件的配置管理,都是其内置功能。
Q:etcd的--initial-cluster-state选项设置为new,重启etcd后会不会创建新的etcd集群?还是加入原有的etcd集群?
A:我们测试过轮流将服务器(3 Master)完全重启,ectd集群的功能均未受影响。但全部关机重启,还未测试过。所以不好意思,这个问题,我暂时没有考虑过。
Q:网络方案用的什么?在选型的时候有没有对比?
A:目前主要应用的还是Flannel方案,今年春节以来,还测试过Flannel、Caclico、kube-router方案。因为我们的集群有可能越机房,而涉及到BGP协议时,节点无法加入,所以一直选用了Flannel。
Q:部署的动态过程是在Jenkins的Web界面上看还是在自研的Prism4k上能看到,如果是Prism4k的话,整个可视化过程的展示这些等等也是自己开发的吗?Prism4k是用什么语言开发的,Python吗?
A:部署的动态过程,是在Prism4k上显示。可视化方案,也只是简单的使用ajax及websocket。Prism4k后端是基于Django 2.0以上开发,其中使用了RESTful framework、channels等库,前端使用了一些js插件。
以上内容根据2019年5月28日晚微信群分享内容整理。分享人 陈刚,平安证券运维研发工程师,负责经纪业务IT应用的持续交付平台的设计和开发 。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiese,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
正文到此结束
- 本文标签: Proxy ssh node DNS apr RESTful 实例 总结 推广 MQ Dashboard 目录 认证 js 集群 管理 解析 开发 统计 Haproxy 镜像同步 云 测试 https cat 数据 Kubernetes 参数 src IO 权限控制 协议 git 产品 UI 域名 REST lib plugin 工程师 2019 编译 ip Oracle 金融 需求 软件 企业 Job 高可用 部署 服务器 tomcat nfs 配置 代码 插件 Uber python Master tag Nginx 质量 科技 安装 Node.js 组织 Ajax http 测试环境 web jenkins 安全 API Docker 同步 ask 希望
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

