入门架构——单机高性能

协作方式
在高并发场景中,必须要让服务器同时维护大量请求连接,可能是一个服务进程创建另一个进程,也可能是一个服务线程去创建另一个线程,但连接结束后进程或线程就销毁了,这是一个巨大的浪费
一个自然的想法就是通过创建一个进程/线程池从而达到资源复用,一个进程/线程可以处理多个连接
那么如何处理多个连接?
同步阻塞
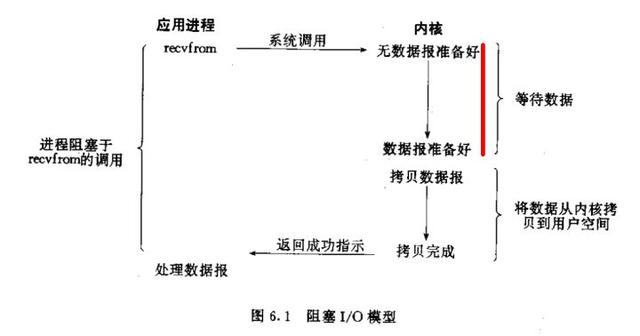
一个请求占用一个进程处理,先等待数据准备好,然后从内核向进程复制数据,最后处理完数据后返回
如果一个进程处理一个请求,再来请求再开进程,虽然会有CPU在等待IO时的浪费和进程数量限制,但还是可以做到一定的高性能。如果一个进程处理多个连接,那么其他连接会在第一个连接导致的IO操作时被阻塞,这样无法做到高性能,所以不会选择该模式实现高性能
同步非阻塞
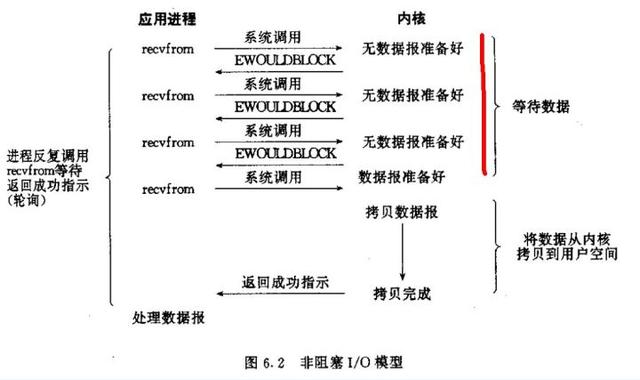
进程先将一个套接字在内核中设置成非阻塞再等待数据准备好,在这个过程中反复轮询内核数据是否准备好,准备好之后最后处理数据返回
一个进程处理一个请求不太实际,一个进程处理多个请求的性能上限会更高,所以简单的处理同步阻塞中的阻塞问题的方式就是一个进程轮询多个连接,但轮询是有CPU开销的,且如果一个进程有成千上万的连接时效率很低,也不会选择该模式实现高性能
I/O多路复用
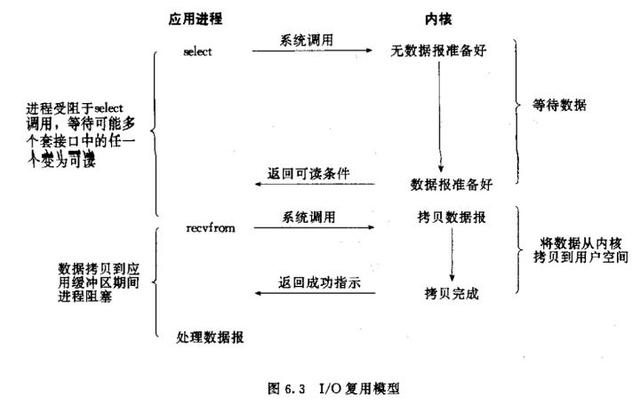
相当于对同步非阻塞的优化版本,区别在于I/O多路复用阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上。换句话说,轮询机制被优化成通知机制,多个连接公用一个阻塞对象,进程只需要在一个阻塞对象上等待,无需再轮询所有连接
当某条连接有新的数据可以处理时,操作系统会通知进程,进程从阻塞状态返回,开始处理业务,这是高性能的基础,但仍不算高效,因为让一个进程/线程进行select是不够的,还需要某种机制来分配进程/线程去负责监听、处理数据这个两个过程才能实现高性能
Reactor
I/O多路复用结合线程池就是Reactor
Reactor的核心包括Reactor(监听和分配事件)和处理资源池(负责处理事件),具体实现可以多变,体现在:
- Reactor的数量可以变化
- 处理资源池的数量可以变化,可以是单个进程/线程,也可以是多个进程/线程
单Reactor单进程/线程
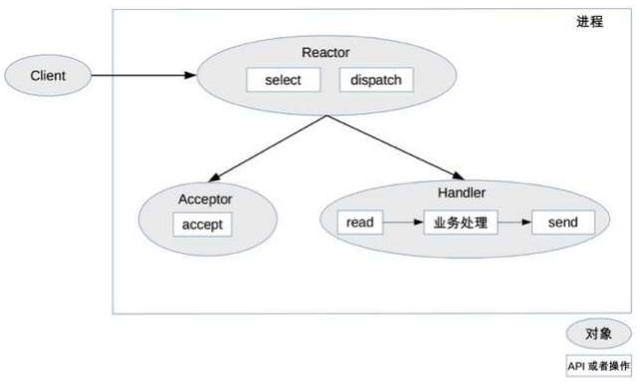
Reactor对象通过select监控连接事件,收到事件后通过dispatch分发
如果是建立连接,交给Acceptor处理,通过accept接收连接,创建一个Handler来处理连接后续的事件
如果是不是建立连接事件,交给之前建立连接阶段创建的对应的Handler处理
优点是简单,没有进程间通信、竞争,缺点是只有一个进程,无法发挥多核CPU性能,且Handler上处理某个连接的业务时,整个进程无法处理任何其他事件
所以适用场景不多,适合于业务处理非常快的场景,如Redis
单Reactor多线程
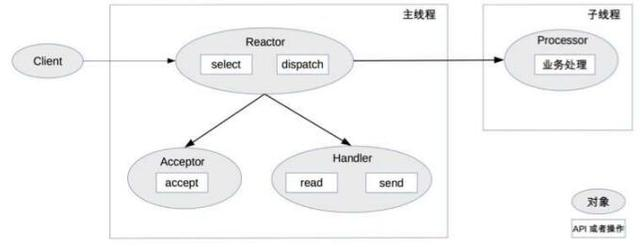
与单Reactor单进程/线程在于Handler只负责响应事件,业务处理交给Processor,且Processor会在独立的子线程中处理,然后将结果发给主进程的Handler处理
优点是充分发挥了多核CPU的能力,缺点是多线程数据共享复杂,且Reactor承担所有事件的监听和响应,高并发会成为瓶颈
多Reactor多进程/线程
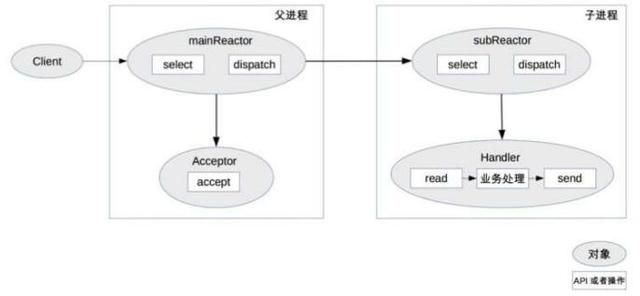
为了解决单Reactor多线程的问题,这个模式的区别:
父进程的select监听到连接建立事件后通过Acceptor将新的连接分配给子进程
子进程的Reactor将新的连接加入自己的连接队列进行监听,并创建一个Handler用于处理连接的事件
当有新的事件发生,子Reactor会调用连接的Handler
Handler完成read->业务处理->send的业务流程
看起来比单Reactor多线程更复杂,但实现更简单,因为:
父进程只负责接收并建立新连接,子进程只负责业务处理
父子进程之间的交互只有父进程把连接交给子进程,子进程不需要把结果返回给父进程
Nginx、Memcache、Netty使用的就是该模式
Proactor
Reactor是同步非阻塞的网络模型,因为真正的read和send这样的IO操作都需要用户进程同步操作,如果把IO操作改为异步就能进一步提升性能,这就是Proactor
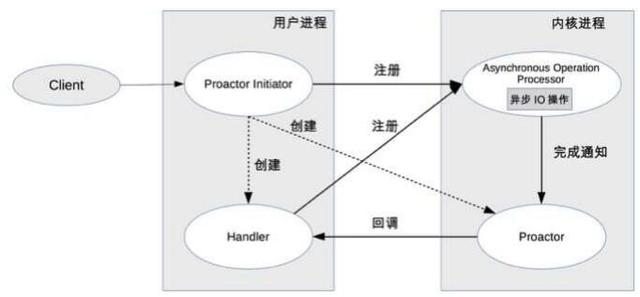
初始化器Initiator负责创建通知组件Proactor和处理器Handler,并且都注册到内核
内核负责处理注册请求,并完成IO操作
内核完成IO操作后通知Proactor
Proactor回调到Handler
Handler完成业务处理,Handler也可以注册新的Handler到内核
理论上Proactor的效率高于Reactor,让IO操作与计算重叠,但要实现真正的异步IO,需要操作系统支持,Windows支持而Linux不完善
实践方式
以上是操作系统或Nginx或高性能服务器软件已经帮我们解决了,我们在编码的时候除非达到了代码的性能极限,一般不需要担心这方面
所以下面谈到的是一些作为开发人员,为了提升单体服务的性能而需要注意的地方
高性能的代码
性能
选用高性能的框架。比如Java方面考虑用Netty,Go方面考虑用Gin
代码细节。这块是与我们最息息相关的了,如何写出高性能代码,每种语言都有自己的最佳实践,反而这里没办法讲到,需要日常学习积累。比如字符串拼接效率如何最高?哪个数据结构适合在某个业务场景使用?
IO细节。由于磁盘的读写速度远低于CPU、内存,所以对磁盘的读写往往会严重拖慢性能,比如写日志,不注意的话可能本地写了一份日志文件,控制台也在输出日志信息,另外一个文件上传流也在写入信息,那么log会成倍地拖慢速度,所以需要统一日志输出方式,比如只往日志收集流中写入到EFK系统中查看
单体服务器压测
写出了自认为高性能的代码?赶紧来压测试一遍,压测就一个目的:寻找瓶颈
在接近于生产环境下的机器做压测才是最真实的,还需要使用专门的压测机来避免环境的影响,最简单的方式是通过ab工具测试QPS是多少,同时检测CPU、内存、网络流量是否达到了瓶颈,然后再根据瓶颈,寻找解决方案,这就是大体压测以及优化的思路,单体应用的压测还挺简单,至于集群的压测就需要考虑更多,日后再说
最近我对一个服务进行了压测,QPS是1200,并且是跑在3台虚拟机上的,瓶颈在于CPU,所以很明显单体服务的性能太低或者是总路由出现了转发问题,这里不考虑后者,我们先分析这个服务的接口是拿来干什么的,这个接口仅仅做了一件事,从Redis获取数据,转发给前端,这里也不考虑Redis的性能问题,那么就可能是在处理数据的时候性能太低。所以同事将返回的json压缩了一下,从40kb压缩到了20kb,QPS直接提升到2500。这就是一个简单的压测后调优的例子,还可以参考这里。
合适的服务器
规格
如果你用过云服务,那么肯定会在启动实例的时候被强迫去选择一个规格的实例,如下
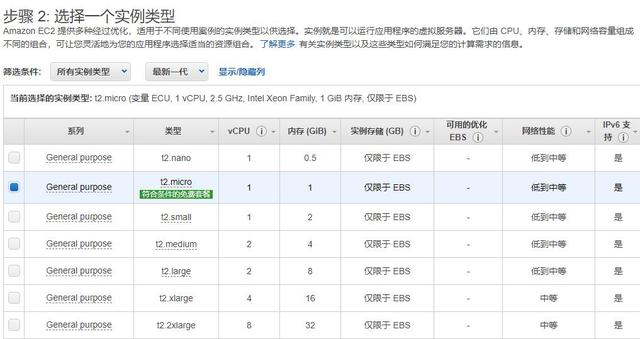
那么请根据你的服务是哪种性能需要,选择对应的服务器呢,当然还要考虑你滴钱包够不够
配置
在Linux平台上,在进行高并发TCP连接处理时,最高的并发数量都要受到系统对用户单一进程同时可打开文件数量的限制(这是因为系统为每个TCP连接都要创建一个socket句柄,每个socket句柄同时也是一个文件句柄)。可使用ulimit命令查看系统允许当前用户进程打开的文件数限制
类似的,对Linux系统配置也会影响到性能的参数需要格外注意,但也需要遵从一个方式:按需调整
感谢您耐心看完的文章
顺便给大家推荐一个Java技术交流群:710373545里面会分享一些资深架构师录制的视频资料:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多!
正文到此结束
- 本文标签: 处理器 JVM java Netty 文件上传 线程池 架构师 spring js redis json 性能问题 免费 性能优化 云 https 数据 实例 开发 文章 模型 linux windows UI Select 操作系统 http 高并发 并发 源码 配置 CTO 参数 进程数 分布式 微服务 测试 集群 TCP mybatis src IO QPS 服务器 进程 代码 快的 cache Reactor Nginx 线程 多线程 软件 同步
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

