《Core Java Volume I》读书笔记——Lambda(上)
Java 8中引入了Lambda表达式,目的是支持函数式编程。为了说明问题假设我们有一个需求:使用List的 forEach 方法遍历输出一个List。
先说明两个点:
forEach forEach
旧方式:在没有Lambda之前,我们的代码类似下面这样:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
list.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
新方式1:有了Lambda之后,我们的代码可以简化成下面这样:
list.forEach(n -> System.out.println(n));
新方式2:甚至再简单一点:
list.forEach(System.out::println);
因为Java是纯OOP语言,没有函数这种概念,所以当需要传递一段功能性代码逻辑的时候,我们必须像上面老式方法中的那样,定义了一个匿名类,然后在类中实现接口,这样做比较麻烦,而且代码很冗余。有了Lambda之后,我们就无需定义一个类了,直接写功能性逻辑就行,代码非常精简,这也就是所谓的函数式编程,非常类似于其它语言里面的闭包、匿名函数等概念。宏观感受之后,接下来我们看下Lambda的一些细节。
函数式接口(Functional Interface)
我们先看函数式接口。看下上面例子中 forEach 方法的参数 Consumer<? super T> action :
// package java.util.function;
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
限于篇幅,我把代码中所有的注释都删掉了。对于这个参数我们需要关注下面两个点:
@FunctionalInterface accept()
没错, Consumer 就是一个函数式接口(Functional Interface),这个我们在前面介绍接口的文章里面已经介绍过了,这里看下 JSR-000335 Lambda Expressions for the JavaTM Programming Language 的 Part A: Functional Interfaces 中是如何定义的:
A functional interface is an interface that has just one abstract method (aside from the methods of Object), and thus represents a single function contract. (In some cases, this "single" method may take the form of multiple abstract methods with override-equivalent signatures inherited from superinterfaces; in this case, the inherited methods logically represent a single method.)
原文不是很长,有兴趣的可以看一下。简单概括 函数式接口就是只包含一个抽象方法的接口 。而且Java 8中增加了一个注解 @FunctionalInterface 来表名接口是函数式接口,但这个注解并非强制性的。 如果我们准备将一个接口定义为函数式接口,那最好加上这个注解,这样一旦接口不符合函数式接口的条件的时候,编译器就会报错 。如果不加这个注解,编译器是不知道的。
Lambda表达式就是为函数式接口而生的,但凡参数是函数式接口的方法,在调用的时候,都可以传递一个Lambda表达式作为参数。就像上面的 forEach 例子一样。
知道了什么时候(When)用Lambda表达式,我们再来看如何(How)用Lambda表达式。
Lambda表达式语法
一个Lambda表达式(Lambda Expression)由三部分组成:
->
一个例子(按照字符串长短排序):
String[] strArray = new String[]{"def", "cbad", "na", "a"};
Arrays.sort(strArray, (String a, String b) -> a.length() - b.length());
语法就不细介绍了,只列举一些注意点:
-
对于参数列表:
- 如果参数的类型可以推断出来的话,那可以省略参数的类型。比如上面新方式1中
forEach例子中的n,我们没有写类型,因为可以编译器可以根据list对象推断出来n的类型为Integer; - 如果只有一个参数,且类型可以推断出来,则可以省略掉圆括号;
- 如果一个参数也没有的话,也必须用一对空括号占位。
- 如果参数的类型可以推断出来的话,那可以省略参数的类型。比如上面新方式1中
-
对于表达式:
{}
方法引用(Method References)
上面 forEach 例子中的新方式2就是方法引用的例子。Lambda表达式中,我们自定义了代码逻辑,但如果我们想要实现的逻辑已经被某个方法实现了的话,我们可以直接引用,这就是所谓的方法引用。比如上面 forEach 例子中我们想要实现的就是打印元素,这个 System.out.println 方法已经实现了,所以我们可以直接引用,而无需自己去实现表达式。方法引用有三种格式:
- 对象::实例方法(object::instanceMethod)
- 类名::静态方法(Class::staticMethod)
- 类名::实例方法(Class::instanceMethod)
前两种其实只是Lambda表达式的简写,比如:
- 第一种
System.out::println等价于x->System.out.println(x), - 第二种
Math::pow等价于(x, y) -> Math.pow(x,y), - 第三种特殊一些,第一个参数会变为方法的目标(the target of the method),即方法的调用者,比如
String::compareToIgnoreCase等价于(x, y) -> x.compareToIgnoreCase(y).
我们还可以在方法引用中使用 this 关键字 。比如: this::equal 等价于 x -> this.equal(x) 。还可以使用 super 关键字用来调用方法所在类的父类实例方法,语法为: super::instanceMethod 。例如:
class Greeter {
public void greet() {
System.out.println("Hello, world!");
}
}
class TimedGreeter extends Greeter {
public void greet() {
Timer t = new Timer(1000, super::greet);
t.start();
}
}
构造器引用(Constructor References)
构造器引用和方法引用类似,只不过把方法名换成了 new 关键字。 因为引用构造器就是为了new对象,至于new的时候调用类的哪个构造器,则根据上下文推断。比如 int[]::new 等价于 x -> new int[x] .
这里我们举一个非常实用的例子做说明:在Java 8+中如何将一个Map根据Key或者Value排序?代码如下:
// 构造Map
final Map<String, Integer> unSortedMap = new HashMap<>();
unSortedMap.put("key1", 10);
unSortedMap.put("key2", 5);
unSortedMap.put("key3", 8);
unSortedMap.put("key4", 20);
// 按照Key,升序排
final Map<String, Integer> sortedByKeyAsc = unSortedMap.entrySet()
.stream()
.sorted(Map.Entry.comparingByKey())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
// 按照Key,降序排
final Map<String, Integer> sortedByKeyDesc = unSortedMap.entrySet()
.stream()
.sorted(Map.Entry.<String, Integer>comparingByKey().reversed())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
// 按照Value,升序排
final Map<String, Integer> sortedByValueAsc = unSortedMap.entrySet()
.stream()
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
// 按照Value,降序排
final Map<String, Integer> sortedByValueDesc = unSortedMap.entrySet()
.stream()
.sorted(Map.Entry.<String, Integer>comparingByValue().reversed())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
这种排序方式代码非常简洁,且可读性高。这里简单说明一下其中的 sorted 和 collect 。
sorted 用于指定比较规则,只有一个参数 Comparator<T> ,这个参数就是函数式接口,其定义的抽象方法为 int compare(T o1, T o2); ,代码中的 comparingByKey 和 comparingByValue 方法都实现了这个接口。当然我们自己也可以实现这个接口,这样就可以按照任意字段排序了。想一下,如果我们把上面的Map的Value由Integer换成一个 Map<String, Integer> 类型,即现在是一个Map的Map。现在我们需要根据里层Map的一个整数字段排序,如何实现?比如现在的Map长下面这样:
final Map<String, Map<String, Integer>> unSortedNestedMap = new HashMap<>();
final Map<String, Integer> innerMap1 = new HashMap<>();
innerMap1.put("count", 10);
innerMap1.put("size", 100);
final Map<String, Integer> innerMap2 = new HashMap<>();
innerMap2.put("count", 5);
innerMap2.put("size", 200);
final Map<String, Integer> innerMap3 = new HashMap<>();
innerMap3.put("count", 15);
innerMap3.put("size", 50);
unSortedNestedMap.put("innerMap1", innerMap1);
unSortedNestedMap.put("innerMap2", innerMap2);
unSortedNestedMap.put("innerMap3", innerMap3);
现在如何对根据里层Map的 count 的值对 unSortedNestedMap 进行排序?代码如下:
final Map<String, Map<String, Integer>> sortedNestedMapByInnerMapCount = unSortedNestedMap.entrySet()
.stream()
.sorted((e1, e2) -> e2.getValue().get("count").compareTo(e1.getValue().get("count")))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
其实代码也很简单,和上面的单层Map排序没有实质区别,只是我们自己实现了一下 sorted 那个函数接口参数而已。
另外一个就是 collect ,这个方法有一个参数 Collector<T, A, R> ,也是一个接口,但该接口并不是一个函数式接口,但其定义的几个抽象方法的返回值都是函数式接口类型的。我们使用 Collectors.toMap 方法可以产生一个 Collector<T, A, R> 类型的参数。 Collectors.toMap 方法有四个参数,而这四个参数均是函数式接口类型的:
public static <T,K,U,M extends Map<K,U>> Collector<T,?,M> toMap(Function<? super T,? extends K> keyMapper,
Function<? super T,? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier)
类型参数和参数含义说明如下:
Type Parameters:
- T - the type of the input elements
- K - the output type of the key mapping function
- U - the output type of the value mapping function
- M - the type of the resulting Map
Parameters:
- keyMapper - a mapping function to produce keys
- valueMapper - a mapping function to produce values
- mergeFunction - a merge function, used to resolve collisions between values associated with the same key, as supplied to Map.merge(Object, Object, BiFunction)
- mapSupplier - a function which returns a new, empty Map into which the results will be inserted
在给这个方法传参时我们把Lambda三种形式都使用到了:
LinkedHashMap
内置的函数式接口
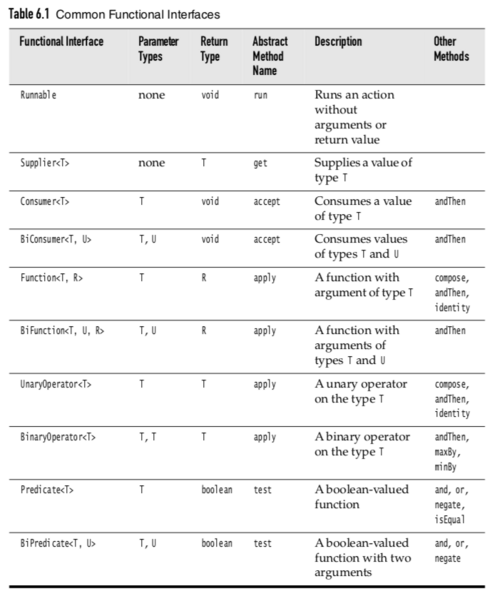
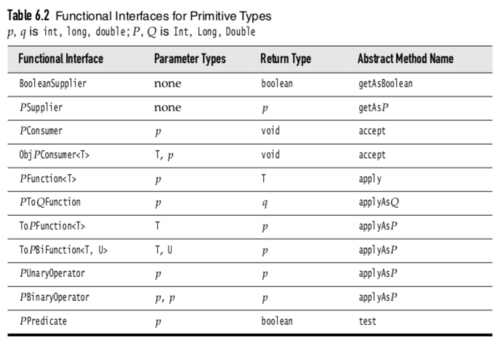
Java内置了一些标准的非常通用的函数式接口,一般我们如果需要使用函数式接口的话,应该优先从内置的里面选择;如果没有满足需求的,那就自己定义,但最好加上 @FunctionalInterface 注解。
内置的函数式接口主要分为两类:一类输入/输出是引用类型的,另一类是输入/输出是原始类型的。优先使用后者,因为可以避免自动装箱和拆箱。
注:以下图片截自《Core Java Volumn I - Fundamentals》。
引用类型:
原始类型:
因为篇幅原因,Lambda最后的一个重要点“变量作用域”下篇文章再总结。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

