玩转Java8Stream(三、Collectors收集器)
之前的文章中也提到了,Stream 的核心在于Collectors,即对处理后的数据进行收集。Collectors 提供了非常多且强大的API,可以将最终的数据收集成List、Set、Map,甚至是更复杂的结构(这三者的嵌套组合)。
Collectors 提供了很多API,有很多都是一些函数的重载,这里我个人将其分为三大类,如下:
- 数据收集:set、map、list
- 聚合归约:统计、求和、最值、平均、字符串拼接、规约
- 前后处理:分区、分组、自定义操作
API 使用
这里会讲到一些常用API 的用法,不会讲解所有API,因为真的是太多了,而且各种API的组合操作起来太可怕太复杂了。
数据收集
-
Collectors.toCollection() 将数据转成Collection,只要是Collection 的实现都可以,例如ArrayList、HashSet ,该方法接受一个Collection 的实现对象或者说Collection 工厂的入参。
示例:
//List Stream.of(1,2,3,4,5,6,8,9,0) .collect(Collectors.toCollection(ArrayList::new)); //Set Stream.of(1,2,3,4,5,6,8,9,0) .collect(Collectors.toCollection(HashSet::new));
-
Collectors.toList()和Collectors.toSet() 其实和Collectors.toCollection() 差不多,只是指定了容器的类型,默认使用ArrayList 和 HashSet。本来我以为这两个方法的内部会使用到Collectors.toCollection(),结果并不是,而是在内部new了一个CollectorImpl。
预期:
`javapublic static <T> Collector<T, ?, List<T>> toList() { return toCollection(ArrayList::new); }
public static <T>
Collector<T, ?, Set<T>> toSet() {
return new toCollection(HashSet::new);
}
实际:
```java
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
public static <T>
Collector<T, ?, Set<T>> toSet() {
return new CollectorImpl<>((Supplier<Set<T>>) HashSet::new, Set::add,
(left, right) -> { left.addAll(right); return left; },
CH_UNORDERED_ID);
}
刚开始真是不知道作者是怎么想的,后来发现CollectorImpl 是需要一个Set<Collector.Characteristics>(特征集合)的东西,由于Set 是无序的,在toSet()方法中的实现传入了CH_UNORDERED_ID,但是toCollection()方法默都是CH_ID,难道是说在使用toCollecion()方法时不建议传入Set类型?如果有人知道的话,麻烦你告诉我一下。
示例:
//List
Stream.of(1,2,3,4,5,6,8,9,0)
.collect(Collectors.toList());
//Set
Stream.of(1,2,3,4,5,6,8,9,0)
.collect(Collectors.toSet());
-
Collectors.toMap() 和Collectors.toConcurrentMap(),见名知义,收集成Map和ConcurrentMap,默认使用HashMap和ConcurrentHashMap。这里toConcurrentMap()是可以支持并行收集的,这两种类型都有三个重载方法,不管是Map 还是ConcurrentMap,他们和Collection的区别是Map 是 K-V 形式的,所以在收集成Map的时候必须指定收集的K(依据)。这里toMap()和toConcurrentMap() 最少参数是,key的获取,要存的value。
示例:这里以Student 这个结构为例,Student 包含 id、name。
public class Student{ //唯一 private String id; private String name; public Student() { } public Student(String id, String name) { this.id = id; this.name = name; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } }说明:这里制定k 为 id,value 既可以是对象本身,也可以指定对象的某个字段。可见,map的收集自定义性非常高。
`javaStudent studentA = new Student("20190001","小明"); Student studentB = new Student("20190002","小红"); Student studentC = new Student("20190003","小丁");
//Function.identity() 获取这个对象本身,那么结果就是Map<String,Student> 即 id->student
//串行收集
Stream.of(studentA,studentB,studentC)
.collect(Collectors.toMap(Student::getId,Function.identity()));
//并发收集
Stream.of(studentA,studentB,studentC)
.parallel()
.collect(Collectors.toConcurrentMap(Student::getId,Function.identity()));
//================================================================================
//Map<String,String> 即 id->name
//串行收集
Stream.of(studentA,studentB,studentC)
.collect(Collectors.toMap(Student::getId,Student::getName));
//并发收集
Stream.of(studentA,studentB,studentC)
.parallel()
.collect(Collectors.toConcurrentMap(Student::getId,Student::getName));
那么如果key重复的该怎么处理?这里我们假设有两个id相同Student,如果他们id相同,在转成Map的时候,取name大一个,小的将会被丢弃。
```java
//Map<String,Student>
Stream.of(studentA, studentB, studentC)
.collect(Collectors
.toMap(Student::getId,
Function.identity(),
BinaryOperator
.maxBy(Comparator.comparing(Student::getName))));
//可能上面比较复杂,这编写一个命令式
//Map<String,Student>
Stream.of(studentA, studentB, studentC)
.collect(Collectors
.toMap(Student::getId,
Function.identity(),
(s1, s2) -> {
//这里使用compareTo 方法 s1>s2 会返回1,s1==s2 返回0 ,否则返回-1
if (((Student) s1).name.compareTo(((Student) s2).name) < -1) {
return s2;
} else {
return s1;
}
}));
如果不想使用默认的HashMap 或者 ConcurrentHashMap , 第三个重载方法还可以使用自定义的Map对象(Map工厂)。
//自定义LinkedHashMap
//Map<String,Student>
Stream.of(studentA, studentB, studentC)
.collect(Collectors
.toMap(Student::getId,
Function.identity(),
BinaryOperator
.maxBy(Comparator.comparing(Student::getName)),
LinkedHashMap::new));
聚合归约
-
Collectors.joining(),拼接,有三个重载方法,底层实现是StringBuilder,通过append方法拼接到一起,并且可以自定义分隔符(这个感觉还是很有用的,很多时候需要把一个list转成一个String,指定分隔符就可以实现了,非常方便)、前缀、后缀。
示例:
Student studentA = new Student("20190001", "小明"); Student studentB = new Student("20190002", "小红"); Student studentC = new Student("20190003", "小丁"); //使用分隔符:201900012019000220190003 Stream.of(studentA, studentB, studentC) .map(Student::getId) .collect(Collectors.joining()); //使用^_^ 作为分隔符 //20190001^_^20190002^_^20190003 Stream.of(studentA, studentB, studentC) .map(Student::getId) .collect(Collectors.joining("^_^")); //使用^_^ 作为分隔符 //[]作为前后缀 //[20190001^_^20190002^_^20190003] Stream.of(studentA, studentB, studentC) .map(Student::getId) .collect(Collectors.joining("^_^", "[", "]"));
-
Collectors.counting() 统计元素个数,这个和Stream.count() 作用都是一样的,返回的类型一个是包装Long,另一个是基本long,但是他们的使用场景还是有区别的,这个后面再提。
示例:
// Long 8 Stream.of(1,0,-10,9,8,100,200,-80) .collect(Collectors.counting()); //如果仅仅只是为了统计,那就没必要使用Collectors了,那样更消耗资源 // long 8 Stream.of(1,0,-10,9,8,100,200,-80) .count(); -
Collectors.minBy()、Collectors.maxBy() 和Stream.min()、Stream.max() 作用也是一样的,只不过Collectors.minBy()、Collectors.maxBy()适用于高级场景。
示例:
// maxBy 200 Stream.of(1, 0, -10, 9, 8, 100, 200, -80) .collect(Collectors.maxBy(Integer::compareTo)).ifPresent(System.out::println); // max 200 Stream.of(1, 0, -10, 9, 8, 100, 200, -80) .max(Integer::compareTo).ifPresent(System.out::println); // minBy -80 Stream.of(1, 0, -10, 9, 8, 100, 200, -80) .collect(Collectors.minBy(Integer::compareTo)).ifPresent(System.out::println); // min -80 Stream.of(1, 0, -10, 9, 8, 100, 200, -80) .min(Integer::compareTo).ifPresent(System.out::println); -
Collectors.summingInt()、Collectors.summarizingLong()、Collectors.summarizingDouble() 这三个分别用于int、long、double类型数据一个求总操作,返回的是一个SummaryStatistics(求总),包含了数量统计count、求和sum、最小值min、平均值average、最大值max。虽然IntStream、DoubleStream、LongStream 都可以是求和sum 但是也仅仅只是求和,没有summing结果丰富。如果要一次性统计、求平均值什么的,summing还是非常方便的。
示例:
`java//IntSummaryStatistics{count=10, sum=55, min=1, average=5.500000, max=10} Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) .collect(Collectors.summarizingInt(Integer::valueOf)); //DoubleSummaryStatistics{count=10, sum=55.000000, min=1.000000, average=5.500000, max=10.000000} Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) .collect(Collectors.summarizingDouble(Double::valueOf)); //LongSummaryStatistics{count=10, sum=55, min=1, average=5.500000, max=10} Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) .collect(Collectors.summarizingLong(Long::valueOf));
// 55
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).mapToInt(Integer::valueOf)
.sum();
// 55.0
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).mapToDouble(Double::valueOf)
.sum();
// 55
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).mapToLong(Long::valueOf)
.sum();
5. Collectors.averagingInt()、Collectors.averagingDouble()、Collectors.averagingLong() 求平均值,适用于高级场景,这个后面再提。
示例:
```java
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.collect(Collectors.averagingInt(Integer::valueOf));
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.collect(Collectors.averagingDouble(Double::valueOf));
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.collect(Collectors.averagingLong(Long::valueOf));
-
Collectors.reducing() 好像也和Stream.reduce()差不多,也都是规约操作。其实Collectors.counting() 就是用reducing()实现的,如代码所示:
public static <T> Collector<T, ?, Long> counting() { return reducing(0L, e -> 1L, Long::sum); }那既然这样的话,我们就实现一个对所有学生名字长度求和规约操作。
示例:
`java//Optional[6] Stream.of(studentA, studentB, studentC) .map(student -> student.name.length()) .collect(Collectors.reducing(Integer::sum)); //6 //或者这样,指定初始值,这样可以防止没有元素的情况下正常执行 Stream.of(studentA, studentB, studentC) .map(student -> student.name.length()) .collect(Collectors.reducing(0, (i1, i2) -> i1 + i2));
//6
//更或者先不转换,规约的时候再转换
Stream.of(studentA, studentB, studentC)
.collect(Collectors.reducing(0, s -> ((Student) s).getName().length(), Integer::sum));
### 前后处理
1. Collectors.groupingBy()和Collectors.groupingByConcurrent(),这两者区别也仅是单线程和多线程的使用场景。为什么要groupingBy归类为前后处理呢?groupingBy 是在数据收集前分组的,再将分好组的数据传递给下游的收集器。
这是 groupingBy最长的参数的函数classifier 是分类器,mapFactory map的工厂,downstream下游的收集器,正是downstream 的存在,可以在数据传递个下游之前做很多的骚操作。
```java
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream)
示例:这里将一组数整型数分为正数、负数、零,groupingByConcurrent()的参数也是跟它一样的就不举例了。
//Map<String,List<Integer>>
Stream.of(-6, -7, -8, -9, 1, 2, 3, 4, 5, 6)
.collect(Collectors.groupingBy(integer -> {
if (integer < 0) {
return "小于";
} else if (integer == 0) {
return "等于";
} else {
return "大于";
}
}));
//Map<String,Set<Integer>>
//自定义下游收集器
Stream.of(-6, -7, -8, -9, 1, 2, 3, 4, 5, 6)
.collect(Collectors.groupingBy(integer -> {
if (integer < 0) {
return "小于";
} else if (integer == 0) {
return "等于";
} else {
return "大于";
}
},Collectors.toSet()));
//Map<String,Set<Integer>>
//自定义map容器 和 下游收集器
Stream.of(-6, -7, -8, -9, 1, 2, 3, 4, 5, 6)
.collect(Collectors.groupingBy(integer -> {
if (integer < 0) {
return "小于";
} else if (integer == 0) {
return "等于";
} else {
return "大于";
}
},LinkedHashMap::new,Collectors.toSet()));
-
Collectors.partitioningBy() 字面意思话就叫分区好了,但是partitioningBy最多只能将数据分为两部分,因为partitioningBy分区的依据Predicate,而Predicate只会有true 和false 两种结果,所有partitioningBy最多只能将数据分为两组。partitioningBy除了分类器与groupingBy 不一样外,其他的参数都相同。
示例:
//Map<Boolean,List<Integer>> Stream.of(0,1,0,1) .collect(Collectors.partitioningBy(integer -> integer==0)); //Map<Boolean,Set<Integer>> //自定义下游收集器 Stream.of(0,1,0,1) .collect(Collectors.partitioningBy(integer -> integer==0,Collectors.toSet())); -
Collectors.mapping() 可以自定义要收集的字段。
示例:
//List<String> Stream.of(studentA,studentB,studentC) .collect(Collectors.mapping(Student::getName,Collectors.toList())); -
Collectors.collectingAndThen()收集后操作,如果你要在收集数据后再做一些操作,那么这个就非常有用了。
示例:这里在收集后转成了listIterator,只是个简单的示例,具体的实现逻辑非常有待想象。
//listIterator Stream.of(studentA,studentB,studentC) .collect(Collectors.collectingAndThen(Collectors.toList(),List::listIterator));
总结
Collectors.作为Stream的核心,工能丰富强大,在我所写的业务代码中,几乎没有Collectors 完不成的,实在太难,只要多想想,多试试这些API的组合,相信还是可以用Collectors来完成的。
之前为了写个排序的id,我花了差不多6个小时去组合这些API,但还好写出来了。这是我写业务时某个复杂的操作

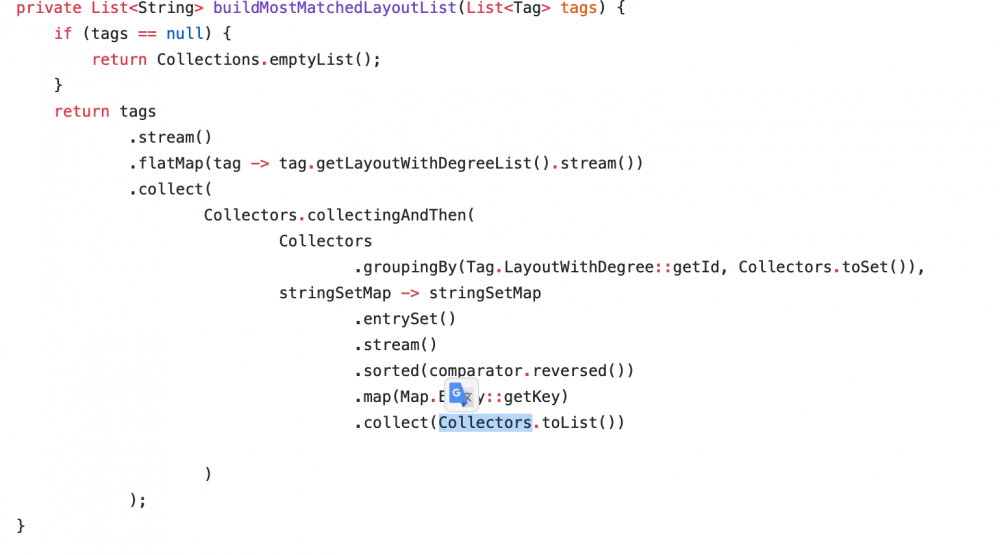
还有一点就是,像Stream操作符中与Collectors.中类似的收集器功能,如果能用Steam的操作符就去使用,这样可以降低系统开销。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

