『互联网架构』软件架构-Sharding-Sphere特性详解(67)
上次通过源码的方式演示了sharding-sphere,分库分表的实现,还有他的原理,不知道老铁拿到代码后跑一下看看。如果试过的老铁,麻烦在评论里面回复下。这次围绕上次分库分表,继续说下shardingShpere是如何做到的代码层面是如何实现的。分库分表写入的都是逻辑表,很多语句都是要进行改写的。
源码:https://github.com/limingios/netFuture/tree/master/源码/『互联网架构』软件架构-Sharding-Sphere特性详解(66)/shardingJdbc
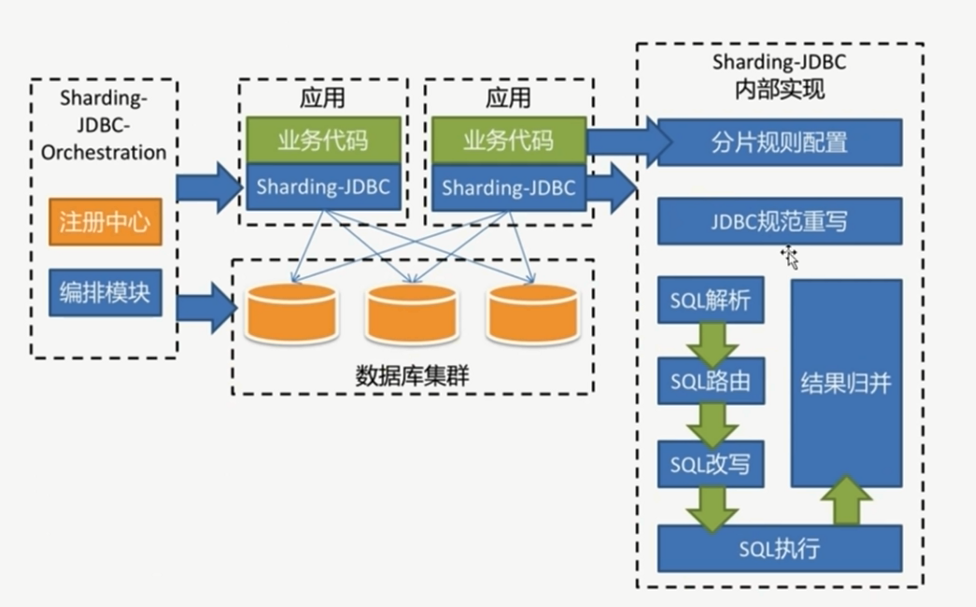
####JDBC规范重写
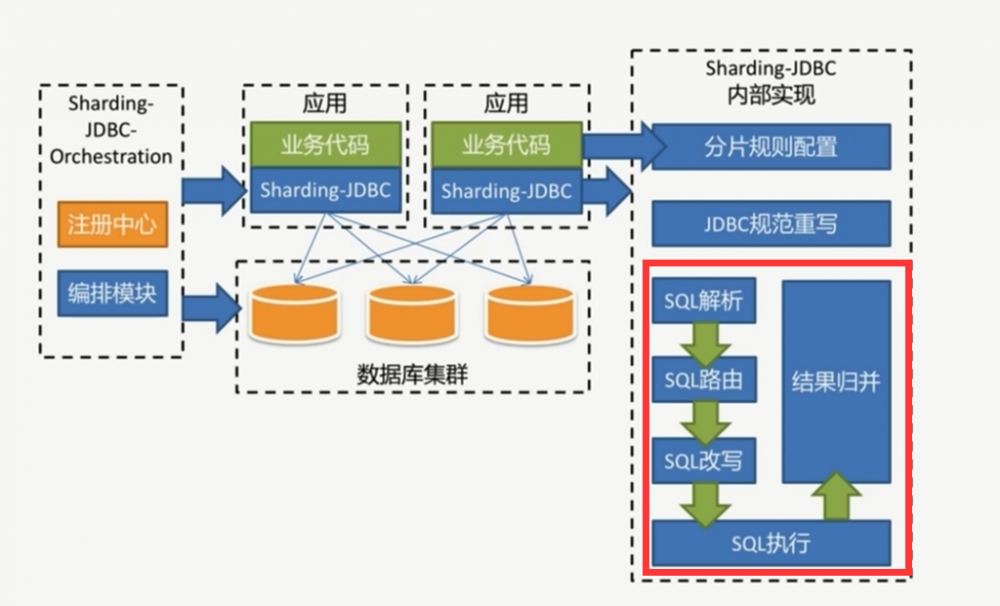
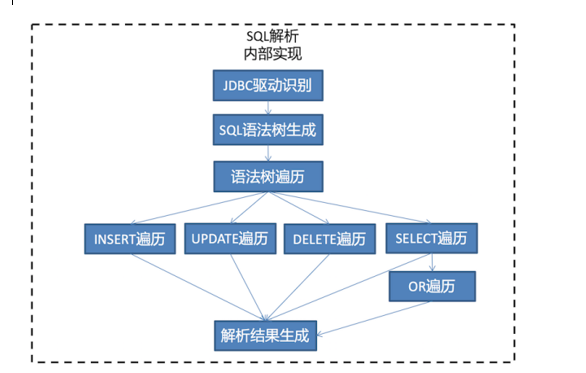
(一)SQL解析
1.数据库类型dbType;
2.分库分表规则shardingRule;
3.词法分析器引擎lexerEngine;
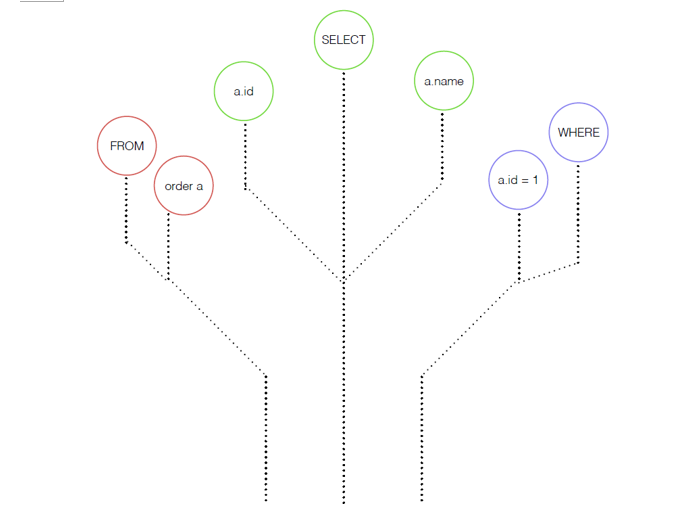
SQL语句
SELECT a.id a.name FROM order a WHERE a.id = 1
解析成
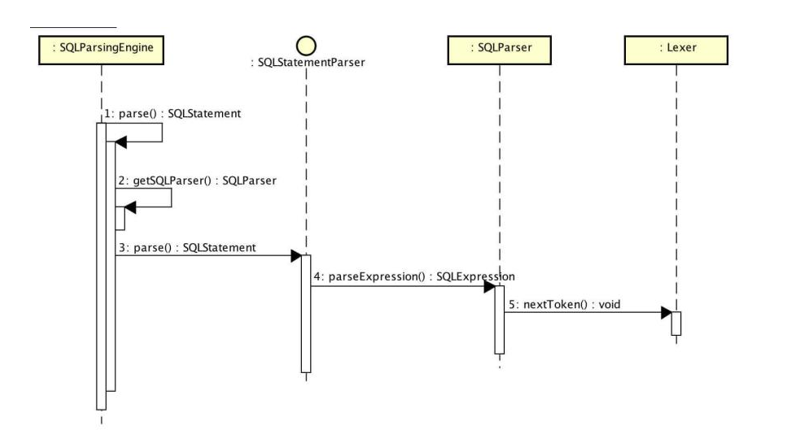
实例代码
@Test
public void assertParseWithoutParameter() throws SQLException {
ShardingRule shardingRule = createShardingRule();//创建分片规则
SQLParsingEngine statementParser = new SQLParsingEngine(DatabaseType.MySQL, "INSERT INTO `TABLE_XXX` (`field1`, `field2`) VALUES (10, 1)", shardingRule);//解析sql引擎
InsertStatement insertStatement = (InsertStatement) statementParser.parse();//解析sql开始
System.out.println("sql解析tables:"+insertStatement.getTables());
List<SQLToken> list=insertStatement.getSqlTokens();
for(SQLToken sqlToken:list){
System.out.println(sqlToken);
}
System.out.println("toString:"+insertStatement.toString());
}
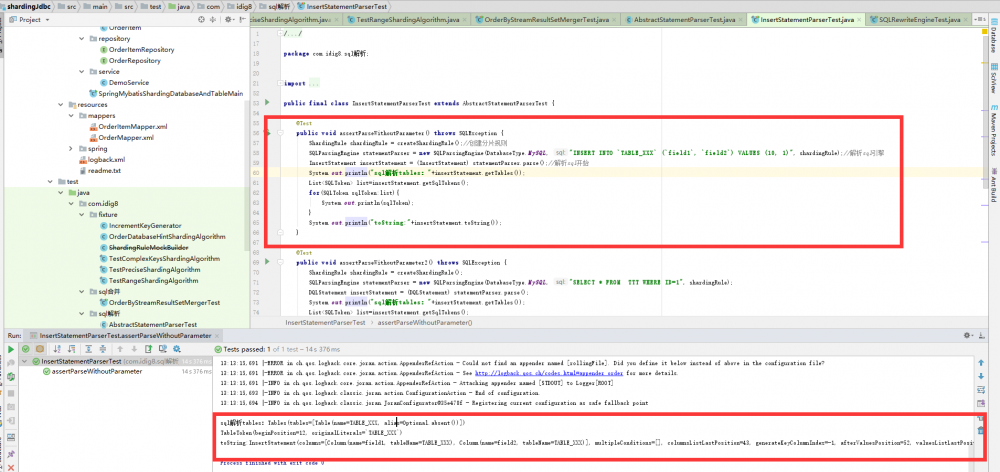
SQL语句拆解成TokenType的对象,
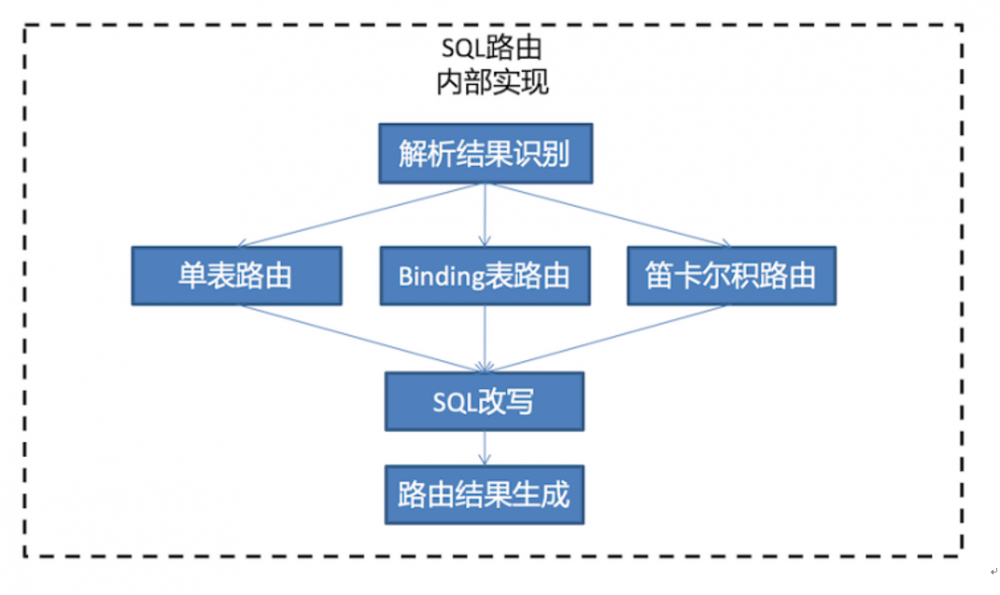
(二)SQL路由
路由方式分为:单表(single)、联表(binding) 混合(mix)
经过 SQL解析、SQL路由后,产生SQL路由结果,即 SQLRouteResult。根据路由结果,生成SQL,执行SQL。
io.shardingjdbc.core.routing.router.SQLRouter#parse 解析接口
io.shardingjdbc.core.routing.router.SQLRouter#route 路由接口
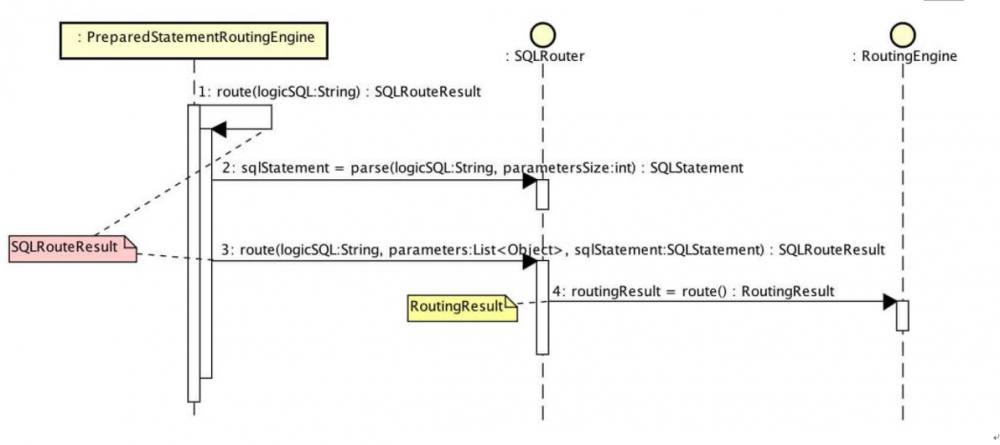
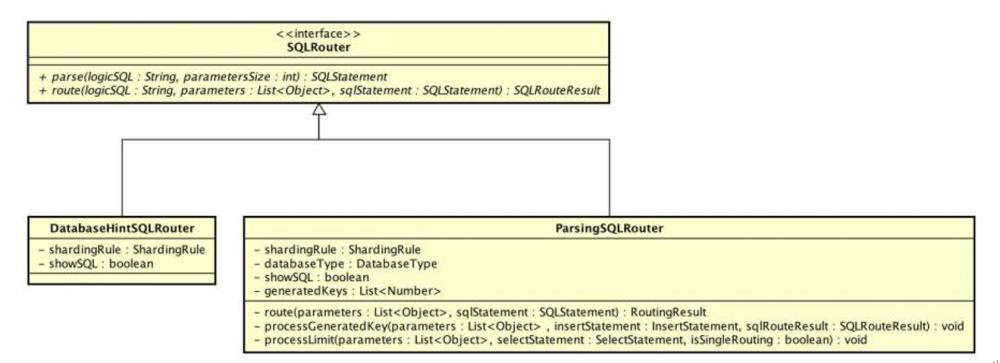
DatabaseHintSQLRouter,基于数据库提示的路由器
ParsingSQLRouter,需要解析的SQL路由器

<sharding:props>
<prop key="sql.show">true</prop>
</sharding:props>
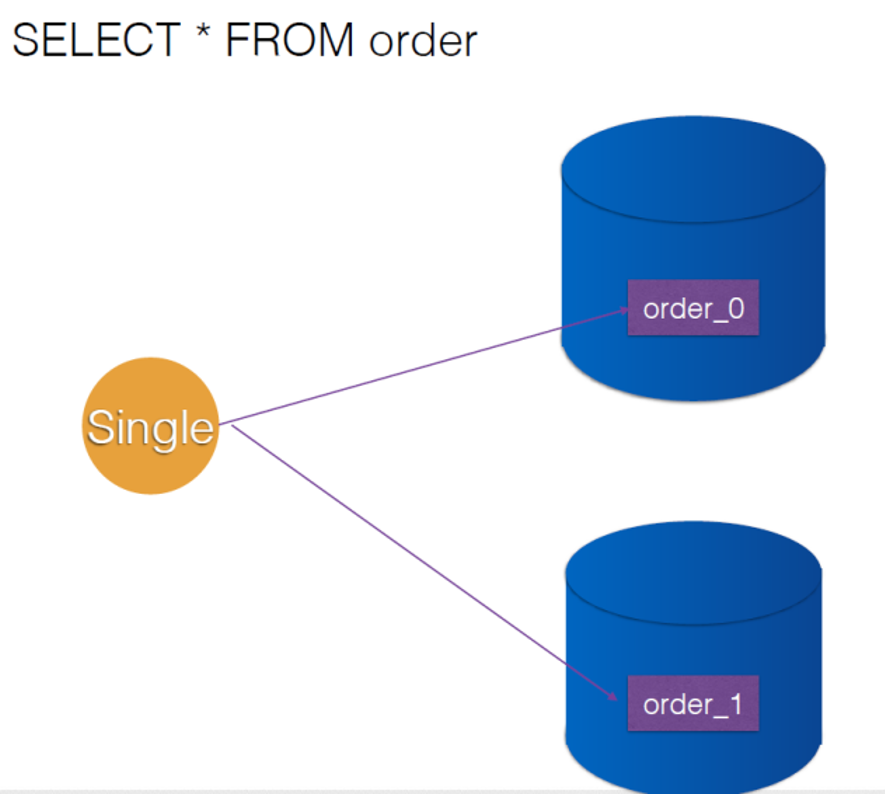
- 单表
全表查询
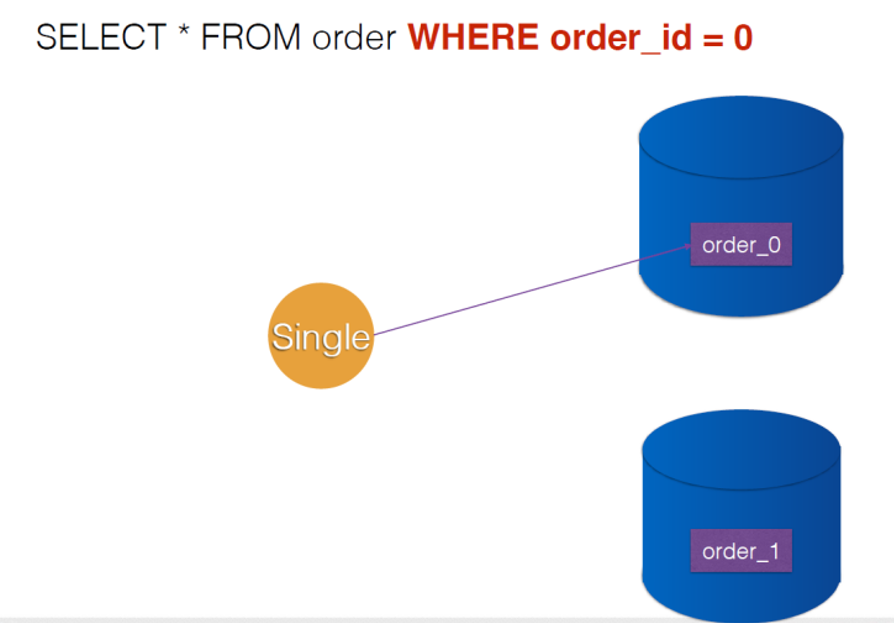
通过查询指定路由到表
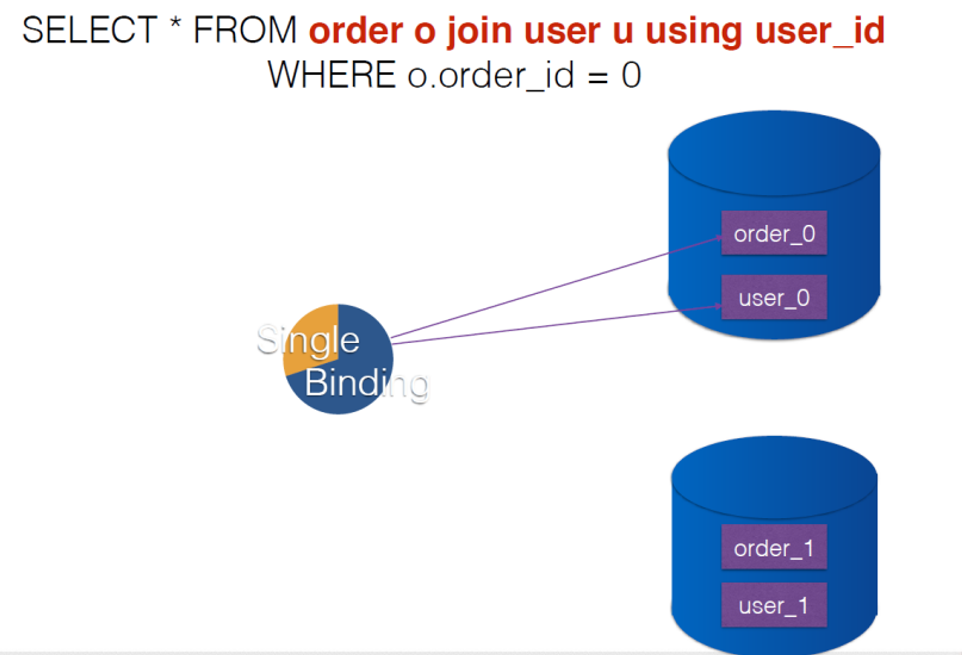
- 联表
联表-单库
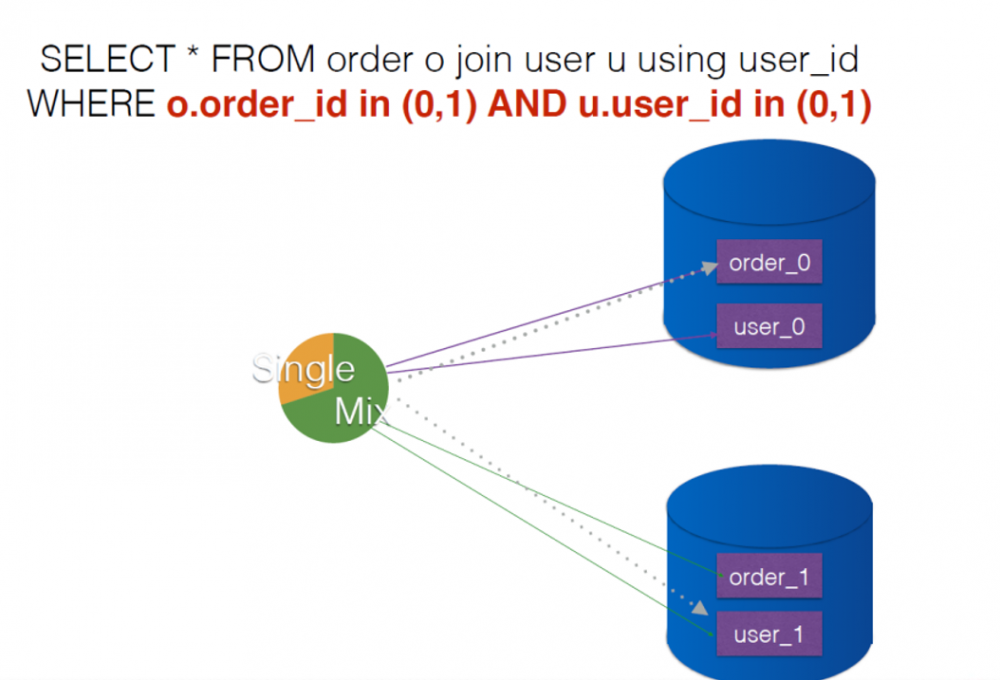
- 混合
(三)SQL改写
SQLRewriteEngine,SQL重写引擎,实现 SQL 改写、生成功能
(四)SQL执行
解析完成sql、路由也完成了,现在进行真正执行的时候了。
* ExecutorEngine> sql执行引擎
com.google.common.util.concurrent.ListeningExecutorService 线程池
- PreparedStatementExecutor>预编译sql执行器
> io.shardingjdbc.core.executor.ExecutorEngine#executePreparedStatement - EventBus>Sql执行事件
> io.shardingjdbc.core.executor.event.EventExecutionType 三种类型事件
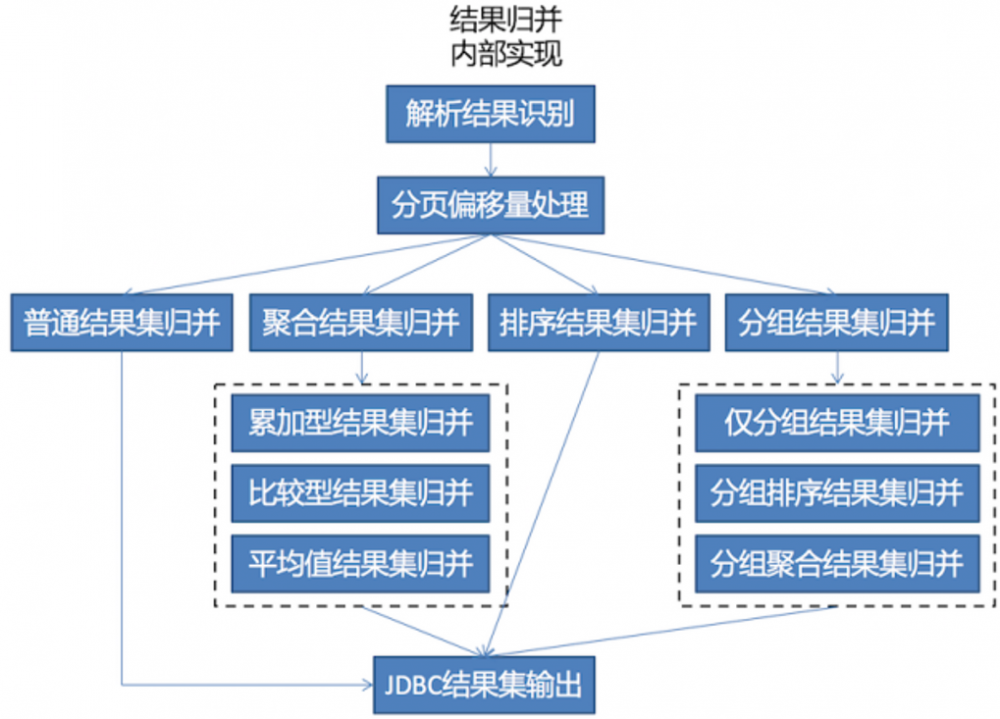
(五)结果归集
改写sql会变成多条,这个时候我们就需要把每个库查出来的结果合并。主要是:分页、分组、排序、聚合、迭代。
| 归并结果集接口 | SQL | 意义 |
|---|---|---|
| OrderByStreamResultSetMerger | SELECT * FROM t_order ORDER BY id | 排序 |
| GroupByStreamResultSetMerger | SELECT uid, AVG(id) FROM t_order GROUP BY uid | 分组 |
| GroupByMemoryResultSetMerger | SELECT uid FROM t_order GROUP BY id ORDER BY id DESC | 分组 排序 |
| IteratorStreamResultSetMerger | SELECT * FROM t_order | 迭代 |
| LimitDecoratorResultSetMerger | SELECT * FROM t_order ORDER BY id LIMIT 10 | 分页 |
PS:这篇写的比较琐碎,没说太多源码只是通过图片的方式说明流程:sql语句,sql路由,sql改写,sql执行这几种方式来针对sql进行分库分表,到实战的时候好好说下吧。目前的shardingjdbc里面有个proxy,nativecat可以直接访问proxy的形式来操作逻辑表的方式,来底层操作物理表。如果分库分表比较多的话,不通过proxy来完成的话,真是一场灾难。
百度未收录
>>原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
>>原文链接地址:上一篇:已是最新文章
正文到此结束
- 本文标签: db sql parse 百度 Service token tab cat 解析 分页 线程池 sharding 2019 源码 互联网 代码 软件 IOS id stream 编译 线程 IT人 list 文章 Master Proxy rewrite 数据库 GitHub value http IO ResultSet mysql Google key core 图片 Statement https 数据 实例 src executor JDBC git UI Select SQL执行 bus
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

