让人抓头的Java并发(一) 轻松认识多线程
本篇文章作为Java并发系列的第一篇,并不会介绍相应的api,只是简单的提到多线程关键线程的通信和同步,后续文章会详细介绍其中的原理
线程简介
现代操作系统的最小执行单元,也称为轻量级线程。一个进程里可以创建多个线程,各个线程可以共享进程资源(内存地址、文件I/O等),又各自拥有独立的计数器、堆栈和局部变量等属性,JVM运行时数据区也如此。Java线程的实现
在HotSpot虚拟机中使用的是一对一线程模型,一个Java线程映射一个内核线程实现。内核线程(Kernel Level Thread)是直接由操作系统内核(Kernel)支持的线程,由内核完成切换,内核通过调度器(Scheduler)对线程调度并将线程的任务映射到各个处理器上。程序使用内核线程的高级接口--轻量级进程(Light Weight Process,通常讲的线程),不直接使用内核线程。因为Java线程采用这种一对一映射内核线程方式实现,所以Java线程调度无法通过设置优先级控制(线程调度采用抢占式)
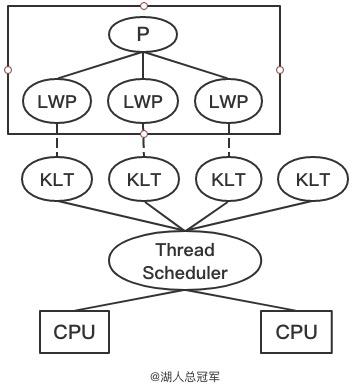
轻量级进程与内核线程之间1:1的关系
线程的状态:
Java定义了6种线程状态,在任意一个时间点,一个线程只能处于其中的一种状态。Java线程生命周期中的六种不同状态
| 状态 | 说明 |
|---|---|
| NEW | 初始状态,线程被构建还没有调用start()方法 |
| RUNNABLE | 运行状态,Java中运行和就绪统称运行中,可能正在执行,也可能在等待CPU时间片 |
| WAITING | 等待状态,这种状态的线程不会被分配CPU时间片,需要等待其他线程显式唤醒 |
| TIMED_WAITING | 超时等待状态,不同于等待状态的是在一定时间之后它们会由系统自动唤醒 |
| BLOCKED | 阻塞状态,表示线程在等待对象的monitor锁,试图通过synchronized去获取某个锁 |
| TERMINATED | 终止状态,表示当前线程已执行完毕 |
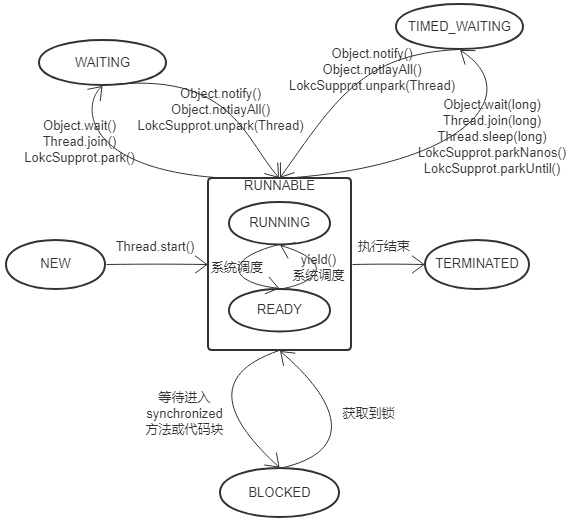
:bulb:小提示: 操作系统中的运行和就绪两个状态在Java中合并成运行状态,LockSupport类的park()方法会使当前线程进入等待状态,由于并发包中的ReentrantLock和condition等并发工具使用的是LockSupport的park(),所以阻塞于它们的线程不同于阻塞于synchronized的线程是处于阻塞状态,而是等待状态;关于这些状态的转换大家可以写个小demo试一试,利用jstack查看线程状态。
线程的创建
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
不推荐使用继承Thread方式实现,Runnable和Callable的区别在于实现后者可以获取执行的结果返回值(实现了Future接口的对象)和抛出异常。可以通过Future接口的get()获取返回值,get()会阻塞当前线程直到任务完成,Future接口的cancel(boolean)方法可以取消任务的执行(任务未启动,如果已启动boolean为true将以中断方式停止任务,false则不会产生影响)。实现有返回值的任务通常使用FutureTask配合线程池,该类实现了Runnable和Futrue接口
推荐使用线程池管理线程,线程池有以下好处
- 提高响应速度,任务到达不需要等待线程创建
- 降低资源消耗,重复利用已创建的线程降低线程创建和销毁的消耗
- 更好的管理线程,线程是稀缺资源,使用线程池可以进行统一分配监控
:bulb:小提示:尽量不要使用Executors来创建线程池,因为使用的无界队列会发生内存溢出,具体原因后续章节会介绍
线程间的通信
Java线程之间的通信由Java内存模型(JMM)控制,JMM决定了一个线程对共享变量的写入何时对其他线程可见。Java多线程同时访问一个对象或者变量时,由于每个线程拥有的只是这个变量的拷贝(为了加快程序的执行),所以在执行过程中,一个线程看到的变量并不一定是最新的。
:bulb:小提示:线程私有的本地内存是一个缓存、写缓冲等的抽象概念
Java内存模型
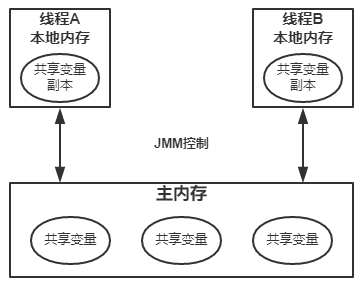
Java中的线程通信方式有以下几种:
- synchronized -- 一个线程释放锁之后会使同步队列中阻塞状态的线程重新尝试获取锁
- volatile -- 一个线程对变量的修改必须同步刷新回主存中,保证了其他线程对变量的可见性, 但并不保证原子性
- Object的wait()/notify()机制 -- 调用对象的notify()方法会使处于对象等待队列中的线程从对象的wait()方法返回,重新进入同步队列尝试获取锁
- 管道输入/输出流 -- 线程之间数据传输(单向),媒介为内存
线程间的通信方式:共享内存、消息队列;
//等待通知模式的经典范式:
synchronized (object) {
while (boolean) {
object.wait();
}
doSomeThing();
}
synchronized (object) {
change boolean;
object.notify();
}
复制代码
:bulb:小提示:等待处使用while而不是if是为了防止错误或者提前的通知
线程同步
将操作共享变量的代码行作为一个整体,同一时间只允许一个线程执行。目的是为了防止多个线程访问一个变量时出现不一致。
Java中实现线程同步的方式:
- synchronized
- Lock
- CountDownLatch
- CyclicBarrier
- Semaphore
- 阻塞队列
除了synchronized其它几种同步方式的实现都与AQS有关,后续文章中会详细介绍,下面给大家来个demo感受下本篇文章的内容。
/**
* @author XiaMu
*/
public class FutureTaskDemo {
private static volatile Integer count = 0;
private static CountDownLatch countDownLatch = new CountDownLatch(500);
private static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 不推荐,为了方便使用了
ExecutorService executorService = Executors.newFixedThreadPool(10);
List<FutureTask<Integer>> resultList = new ArrayList<>(500);
for (int i = 0; i < 500; i++) {
FutureTask<Integer> task = new FutureTask<>(() -> {
// lock.lock();(1)
int result = count++;
// lock.unlock();(1)
// countDownLatch.countDown();(2)
return result;
});
executorService.submit(task);
resultList.add(task);
}
// countDownLatch.await();(2)
System.out.println("第一处计算结果:" + count);
// 为了查看每个任务的执行结果
Map<Integer, Integer> resultMap = new HashMap<>(500);
for (FutureTask<Integer> result : resultList) { // (3)
Integer sum = result.get();
if (resultMap.containsKey(sum)) {
System.out.println(sum + "计算过了");
} else {
resultMap.put(sum, 1);
}
}
System.out.println("第二处计算结果:" + count);
executorService.shutdown();
}
}
复制代码
取两次执行结果:
第一处计算结果:0 第一处计算结果:270 135计算过了 492计算过了 163计算过了 16计算过了 454计算过了 437计算过了 458计算过了 445计算过了 463计算过了 第二处计算结果:496 470计算过了 317计算过了 319计算过了 第二处计算结果:492 复制代码
:bulb::毫无疑问,计算结果出现了错误,可以将(1)注释打开加锁保证计算正确。第一处计算结果不等于第二处是因为主线程执行到第一处时,子任务并没有执行完。如果没有(3)的for循环中获取结果的Future.get()阻塞主线程,那么第二处计算结果打印时子任务可能还没执行完。注释(2)打开可以解决两次打印不一致问题,因为CountDownLatch会将主线程阻塞直到第500个子任务执行完毕。
:bulb::使用集合时最好根据情况指定初始容量,否则在后续的操作中会发生频繁扩容影响效率【本篇文章只是讲了个大概,如果小伙伴们发现有问题或者疑惑的地方欢迎指出,一起学习进步!】
参考:
《Java并发编程的艺术》
《码出高效》
正文到此结束
- 本文标签: CyclicBarrier key ask tar executor JVM 内存模型 并发编程 tab 文章 java线程 UI 并发 消息队列 src Service ArrayList 多线程 Java内存模型 java jstack map 模型 缓存 注释 同步 js 处理器 HashMap API 操作系统 rmi 生命 进程 id CountDownLatch 时间 锁 https 线程池 线程通信 管理 Semaphore list http 线程 IO synchronized 代码 volatile mina 调度器 线程同步 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

