微服务间的调用和应用内调用有什么区别
【编者的话】目前大部分的系统架构都是微服务架构,就算没有注册中心、服务管理,也肯定是多个服务,单体服务比较少了。
大家平时需要在应用内调用rpc接口也比较多,那么有没有思考过微服务之间的调用和应用内直接调用有什么区别呢?面试时是不是经常被被问到微服务呢,本篇文章针对微服务间的方法调用和应用内方法调用的有啥区别这个很小的点,谈谈我的经验。
微服务调用特点
先从单体应用说起。
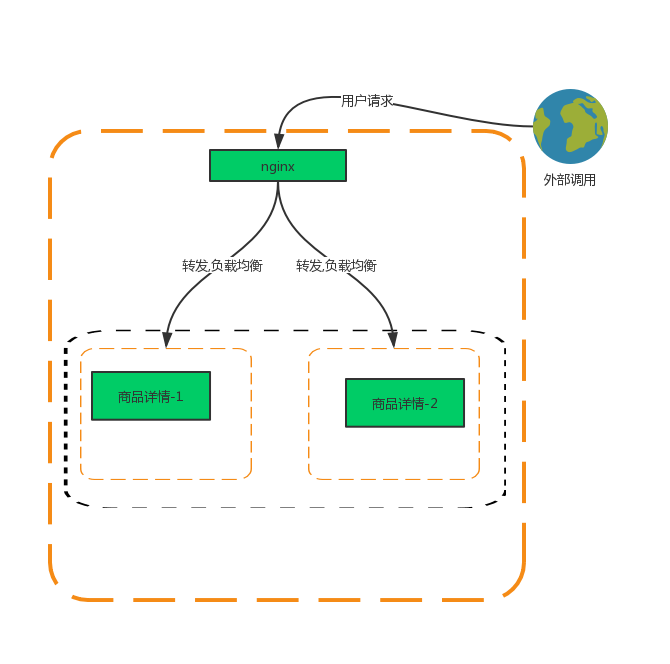
单体应用
单体引用通过一个服务节点直接组装好数据,返回给调用者。所有的方法调用都发生在应用内部。
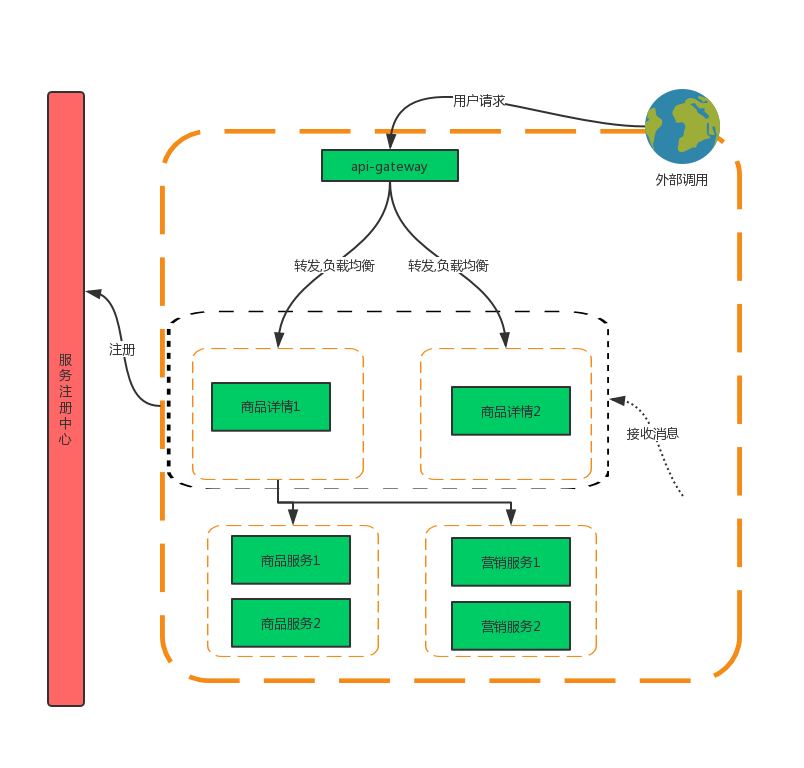
微服务应用
商品详情服务需要调用商品,营销等多个服务组装好商品详情页的数据。
微服务调用和应用内调用不同点在于它是跨进程的,甚至是跨节点的,这意味着什么呢?
使用Kubernetes编排微服务时,我们可以让不同的服务放在同一个节点的不同Docker container上,但是考虑到网络不可靠,和容灾,服务之间不可避免会放到不同的节点/机架上,所以下文都以跨节点来讨论。
意味着两点:
- 对外部有了依赖
- 如果是跨节点,就有了网络调用。我们知道网络都是不可靠的
关于网络有几个著名的错误推论:
- The network is reliable(网络是可靠的)
- Latency is zero.(延迟可以为0)
- Bandwidth is infinite(带宽是无限的)
- The network is secure(网络是安全的)
- Topology doesn’t change(网络拓扑结构不会变)
- Transport cost is zero(网络传输耗时为0)
- The network is homogeneous(网络是同类的)
我们需要做什么
存在上述两个问题后,那么我们需要在写微服务间方法调用时注意什么呢? 如果你想和更多微服务技术专家交流,可以加我微信liyingjiese,备注『加群』。群里每周都有全球各大公司的最佳实践以及行业最新动态 。
对外部有了依赖
微服务架构设计中有一条重要的原则叫严出宽进,严出意思就是说你提供给其他服务的东西要尽可能的进行严格的校验。宽进就是你调用别人的接口要宽容,兼容各种情况。比如说你需要考虑别人的节点down了/api超时/api不可用等等因素。
为了解决这个问题,我们必须要针对具体业务,分析依赖类型,是强依赖还是弱依赖,强依赖包装成自己的服务异常返回码/或者直接告诉前端调用不可用。弱依赖,catch所有异常,无论依赖方发生什么,不能影响我的接口返回。
此外,我依赖的服务某段时间内接口错误率很高,调用方还在不停的发送请求,那么就会一直得到错误的结果,这时候这些请求其实是无效的,所以这时候需要客户端熔断,不再去调用服务方,给服务方恢复的时间,等过段时间再去重试,发现服务方可用时,再去调用。
网络调用
网络调用是耗时的,所以我们需要利用池化技术,复用连接,比如在单体应用中我们需要与数据库连接,会利用到数据库连接池来提高数据操作效率。那么微服务调用也是这么个道理,我们与其他服务建议http/tcp连接,也需要建立连接池。另外一个服务可能会依赖多个微服务,不能因为和某个服务之间的连接出了问题,影响到与其他服务的连接,所以需要做连接池隔离。
服务间调用有可能失败,所以我们需要有重试机制,比如因为网络抖动引发的超时问题,我们可以通过重试提高API的可用性。
但是思考一下坏的情况,某段时间网络或者服务端真的有问题了。客户端超时时间设置的很大的话,客户端等待的时间就会很长,然后再加上重试机制,就会将客户端的连接占满,造成客户端相关API不可用。
几个案例
分享几个微服务调用的故障案例,帮助大家进行场景化思考
为啥要分享这些案例呢,因为TMD的这些案例都是血的教训,造成线上故障,不是我的错,却要我背锅。
案例1
新上线了一个产品功能,需要推广,放在另外一个流量比较大的产品模块中,展示一些我们产品功能的数据。
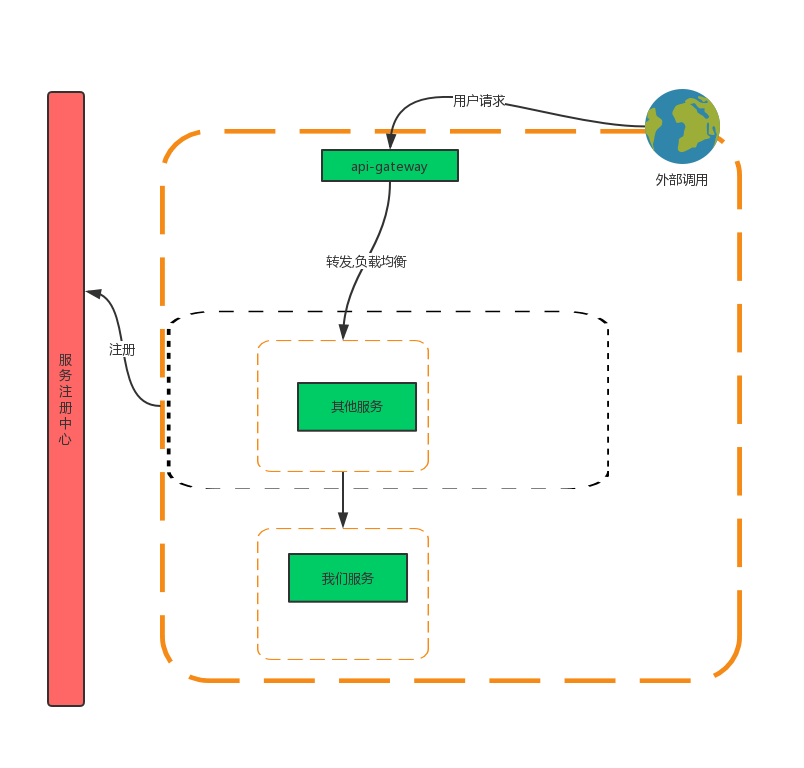
出于某种原因,我们的服务mock了rpc调用数据,返回null。结果其他服务整个前台页面挂了,挂了,挂了。
典型的强弱依赖问题,调用方没有处理好依赖类型,明明是一个弱依赖没有处理,变成了强依赖,造成功能挂了。
案例2
依赖的某个服务需要根据主键List<id>来批量查询,依赖服务内部做分库分表拆分,升级了sdk。在提供的sdk client中做分表路由,将批量id拆分成N个rpc调用。这么做的原因是防止批量查询把数据库连接池打爆。
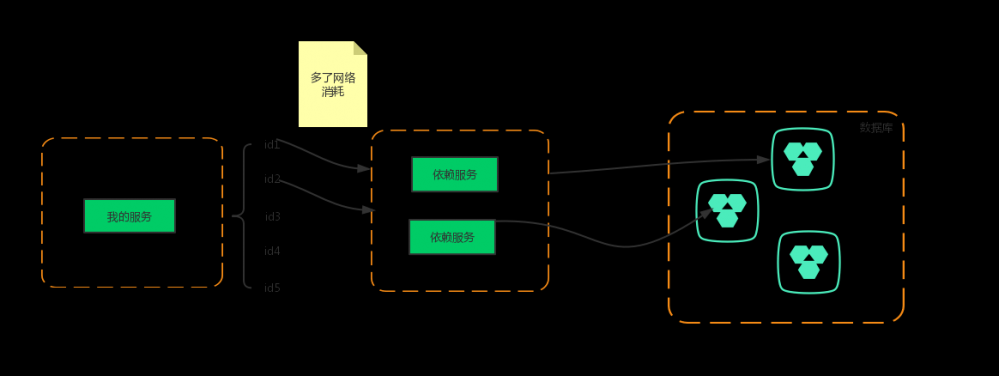
忽略了网络调用
案例3
别人调我们的服务的某个接口,这个接口RT(耗时时间)P95 < 30ms。但是客户端调用的超时时间设置成了500ms,在某次不知道是什么原因的情况下,调用方的连接大量block,造成线程阻塞,相关API不可用。看服务方监控,该接口返回时间正常,服务方没有任何异常。
没有正确的设置超时时间
总结
微服务调用和应用内调用有很大的区别,我们不能在进行服务间调用时无感知,需要知道它面临的问题:
- 对外部有了依赖,外部是不可靠的
- 有了网络调用
解法可以精炼为4条:
- 根据业务需要,判断依赖类型,做好对应的降级
- 设置合理的超时时间
- 调用方需要对不同的服务调用设置连接池隔离
- 调用方需要有熔断机制
这些问题看似都很简单,但是根据我的观察,真的有很多人写了无数的rpc调用,还没有意识到这些问题。
作者:方丈的寺院
原文: https://fangzhang.blog.csdn.ne ... 66398
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

