微服务化后缓存怎么做
【编者的话】最近接手的代码中遇到几个缓存的问题,存在一些设计原则的问题,这里总结一下,希望可以对你有帮助。
问题
问题1: 店铺数据的获取,将用户关注的数据放在店铺信息一起返回。
对外提供的接口:
List<Shop> getPageShop(final Query query,final Boolean cache);
返回的店铺信息:
public class Shop {
public static final long DEFAULT_PRIORITY = 10L;
/**
* 唯一标识
*/
private Long id;
//省略了店铺其他信息
/**
* 用户关注
*/
private ShopAttention attention;
}
当调用方设置cache为true时,因为有缓存的存在,获取不到用户是否关注的数据。
问题2: 统计店铺的被关注数导致的慢SQL,导致数据库cpu飙高,影响到了整个应用。
SQL:
SELECT shop_id, count(user_Id) as attentionNumber
FROM shop_attention
WHERE shop_id IN
<foreach collection="shopIds" item="shopId" separator="," open="(" close=")">
#{shopId}
</foreach>
GROUP BY shopId
这两种代码的写法都是基于一个基准。
不同的地方的缓存策略不一样,比如我更新的地方,查找数据时不能缓存,页面展示的查找的地方需要缓存。 既然服务提供方不知道该不该缓存,那就不管了,交给调用方去管理。 如果你想和更多微服务技术专家交流,可以加我微信liyingjiese,备注『加群』。群里每周都有全球各大公司的最佳实践以及行业最新动态 。
这种假设本身没什么问题,但是忽略了另外一个原则,服务的内聚性。不应该被外部知道的就没必要暴露给外部。
无论是面向过程的C,还是面向对象的语言,都强调内聚性,也就是高内聚,低耦合。单体应用中应当遵循这个原则,微服务同样遵循这个原则。但是在实际过程中,我们发现做到高内聚并不简单。我们必须要时时刻刻审视方法/服务的边界,只有确定好职责边界,才能写出高内聚的代码。
问题分析
第一个问题,从缓存的角度来看,是忽略了数据的更新频繁性以及数据获取的不同场景。
对于店铺这样一个大的聚合根,本身包含的信息很多,有些数据可能会被频繁更改的,有些则会很少更新的。那么不同的修改频率,是否缓存/缓存策略自然不同,使用同一个参数Boolean cache来控制显然不妥
第二个问题,这种统计类的需求使用SQL统计是一种在数据量比较小的情况下的权宜之计,当数据规模增大后,必须要使用离线计算或者流式计算来解决。它本身是一个慢SQL,所以必须要控制号调用量,这种统计的数据量的时效性应该由服务方控制,不需要暴露给调用方。否则就会出现上述的问题,调用方并不清楚其中的逻辑,不走缓存的话就会使得调用次数增加,QPS的增加会导致慢SQL打垮数据库。
解法
缓存更新本身就是一个难解的问题,在微服务化后,多个服务就更加复杂了。涉及到跨服务的多级缓存一致性的问题。
所以对大部分的业务,我们可以遵循这样的原则来简单有效处理。
对数据的有效性比较敏感的调用都收敛到服务内部(领域内部应该更合适),不要暴露给调用方。
领域内部做数据的缓存失效控制。
缓存预计算(有些页面的地方不希望首次打开慢)的逻辑也应该放在领域内控制,不要暴露给调用方。
在领域内部控制在不同的地方使用不同的缓存策略,比如更新数据的地方需要获取及时的数据。比如商品的价格,和商品的所属类目更新频次不同,需要有不同的过期时间。
跨服务调用为了减少rpc调用,可以再进行一层缓存。因为这些调用可以接受过期的数据,再进行一层缓存没问题,expired time叠加也没多大影响(expire time在这边主要是影响缓存的命中数)
以上述店铺查询问题改造为例
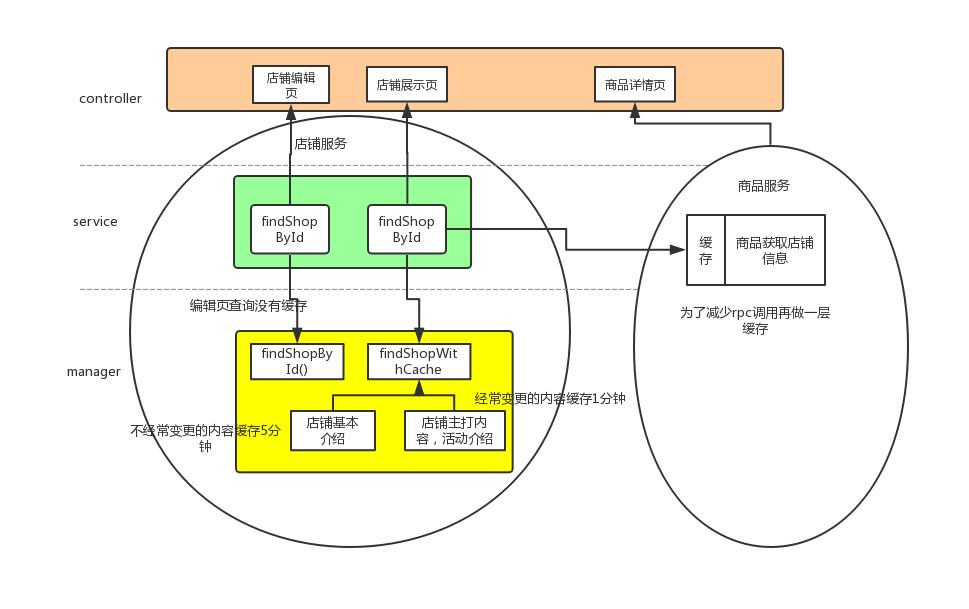
扩展:如果后续有case在跨服务的调用时,对数据的过期比较敏感,并且在调用方也做了缓存,那就是跨服务的多级缓存一致性的问题。那就需要服务方告知调用方缓存何时失效,使用消息队列or其他方式来实现。
作者:方丈的寺院
原文: https://fangzhang.blog.csdn.ne ... 92575
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

