一次线上生产问题的全面复盘 【定位->分析->解决】
点击上方 石杉的架构笔记 ,右上角选择“ 设为星标 ”
每日早8点半,技术文章准时送上
公众号后台回复“ 学习 ”,获取作者独家秘制精品资料
往期文章
BAT 面试官是如何360°无死角考察候选人的(上篇)
每秒上万并发下的Spring Cloud参数优化实战
分布式事务如何保障实际生产中99.99%高可用
记一位朋友斩获 BAT 技术专家Offer的面试经历
亿级流量架构系列之如何支撑百亿级数据的存储与计算
本文来源:crossoverJie
目录:
-
写在前面
-
生产现象
-
定位问题
-
解决办法
-
本地模拟
-
内存分析
-
总结
写在前面
之前或多或少分享过一些内存模型、对象创建之类的内容,其实大部分人看完都是懵懵懂懂,也不知道这些的实际意义。
直到有一天你会碰到线上奇奇怪怪的问题,如:
-
线程执行一个任务迟迟没有返回,应用假死。
-
接口响应缓慢,甚至请求超时。
-
CPU 高负载运行。
这类问题并不像一个空指针、数组越界这样明显好查,这时就需要刚才提到的内存模型、对象创建、线程等相关知识结合在一起来排查问题了。
正好这次借助之前的一次生产问题来聊聊如何排查和解决问题。
生产现象
首先看看问题的背景吧:我这其实是一个定时任务,在固定的时间会开启 N 个线程并发的从 Redis 中获取数据进行运算。
业务逻辑非常简单,但应用一般涉及到多线程之后再简单的事情都要小心对待。 果不其然这次就出问题了。
现象:原本只需要执行几分钟的任务执行了几个小时都没退出。翻遍了所有的日志都没找到异常。
于是便开始定位问题之路。
定位问题
既然没办法直接从日志中发现异常,那就只能看看应用到底在干嘛了。最常见的工具就是 JDK 自带的那一套。
这次我使用了 jstack 来查看线程的执行情况,它的作用其实就是 dump当前的线程堆栈。
当然在 dump 之前是需要知道我应用的 pid 的,可以使用 jps -v 这样的方式列出所有的 Java 进程。
当然如果知道关键字的话直接使用 ps aux|grep java 也是可以的。
拿到 pid=1523 了之后就可以利用 jstack 1523 > 1523.log 这样的方式将 dump 文件输出到日志文件中。
如果应用简单不复杂,线程这些也比较少其实可以直接打开查看。但复杂的应用导出来的日志文件也比较大还是建议用专业的分析工具。
我这里的日志比较少直接打开就可以了,因为我清楚知道应用中开启的线程名称,所以直接根据线程名就可以在日志中找到相关的堆栈:

所以通常建议大家线程名字给的有意义,在排查问题时很有必要。
其实其他几个线程都和这里的堆栈类似,很明显的看出都是在做 Redis 连接。
于是我登录Redis查看了当前的连接数,发现已经非常高了,这样Redis的响应自然也就变慢了。
接着利用 jps -v 列出了当前所以在跑的 Java 进程,果不其然有好几个应用都在查询 Redis,而且都是并发连接,问题自然就找到了。
解决办法
所以问题的主要原因是:大量的应用并发查询 Redis,导致 Redis 的性能降低。
既然找到了问题,那如何解决呢?
-
减少同时查询 Redis 的应用,分开时段降低 Redis 的压力。
-
将 Redis 复制几个集群,各个应用分开查询。但是这样会涉及到数据的同步等运维操作,或者由程序了进行同步也会增加复杂度。
目前我们选择的是第一个方案,效果很明显。
本地模拟
上文介绍的是线程相关问题,现在来分析下内存的问题。
以这个类为例:
https://github.com/crossoverJie/Java-Interview/blob/master/src/main/java/com/crossoverjie/oom/heap/HeapOOM.java
1public class HeapOOM {
2
3 public static void main(String[] args) {
4 Listlist = new ArrayList<>( 10) ;
5 while ( true){
6 list.add( "1") ;
7 }
8 }
9}
启动参数如下:
1-Xms20m
2-Xmx20m
3-XX:+HeapDumpOnOutOfMemoryError
4-XX:HeapDumpPath=/Users/xx/Documents
为了更快的突出内存问题将堆的最大内存固定在 20M,同时在 JVM 出现 OOM 的时候自动 dump 内存到 /Users/xx/Documents (不配路径则会生成在当前目录)。
执行之后果不其然出现了异常:
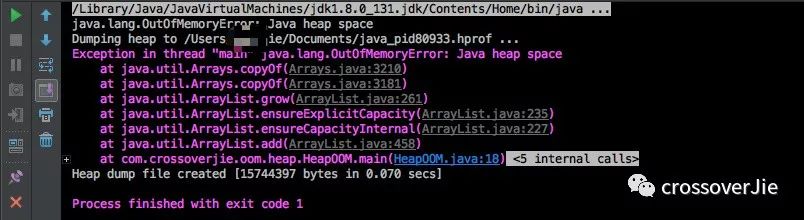
同时对应的内存 dump 文件也生成了。
内存分析
这时就需要相应的工具进行分析了,最常用的自然就是 MAT 了。
我试了一个在线工具也不错(文件大了就不适合了)
-
http://heaphero.io/index.jsp
上传刚才生成的内存文件之后:
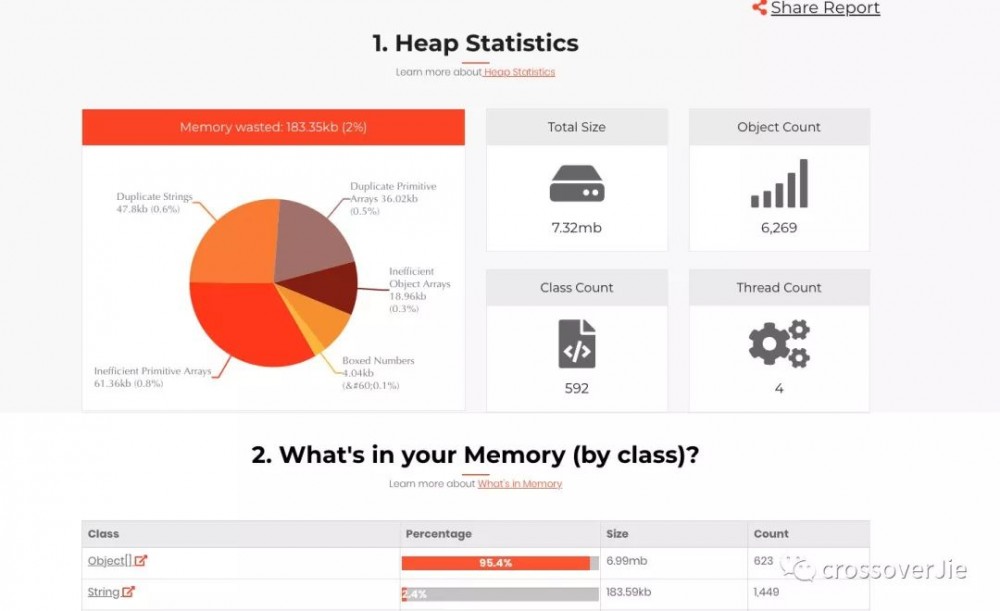
因为是内存溢出,所以主要观察下大对象:
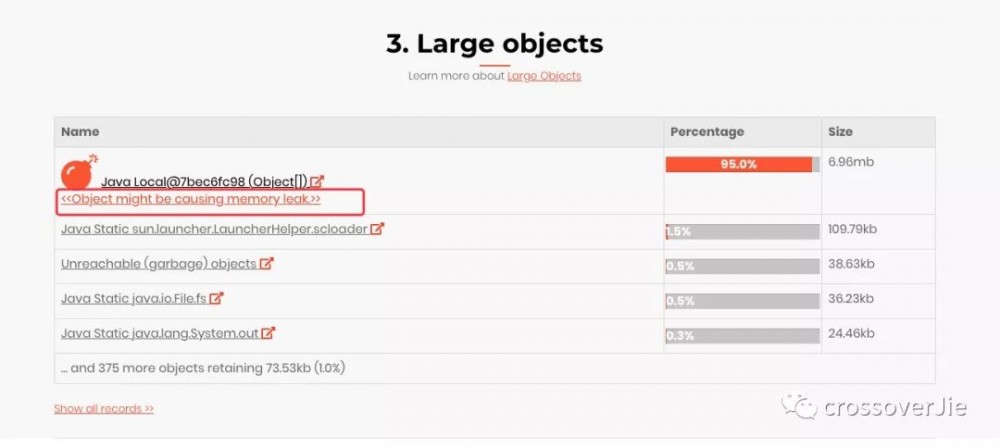
也有相应提示,这个很有可能就是内存溢出的对象,点进去之后:

看到这个堆栈其实就很明显了:在向 ArrayList 中不停的写入数据时,会导致频繁的扩容也就是数组复制这些过程,最终达到 20M 的上限导致内存溢出了。
更多建议
上文说过,一旦使用了多线程,那就要格外小心。
以下是一些日常建议:
-
尽量不要在线程中做大量耗时的网络操作,如查询数据库(可以的话在一开始就将数据从从 DB 中查出准备好)
-
尽可能的减少多线程竞争锁。可以将数据分段,各个线程分别读取
-
多利用
CAS+自旋的方式更新数据,减少锁的使用 -
应用中加上
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp参数,在内存溢出时至少可以拿到内存日志 -
线程池监控。如线程池大小、队列大小、最大线程数等数据,可提前做好预估
-
JVM 监控,可以看到堆内存的涨幅趋势,GC 曲线等数据,也可以提前做好准备
总结
线上问题定位需要综合技能,所以是需要一些基础技能。如线程、内存模型、Linux 等。
当然这些问题没有实操过都是纸上谈兵;如果第一次碰到线上问题,不要慌张,反而应该庆幸解决之后你又会习得一项技能。
END
划至底部,点击“ 在看 ”,是你来过的仪式感!
推荐阅读:
-
简历写了会Kafka,面试官90%会让你讲讲acks参数对消息持久化的影响!
-
面试最让你手足无措的一个问题:你的系统如何支撑高并发?
-
Java高阶必备:如何优化Spring Cloud微服务注册中心架构?
-
高并发场景下,如何保证生产者投递到消息中间件的消息不丢失?
-
从团队自研的百万并发中间件系统的内核设计看Java并发性能优化!
-
如果20万用户同时访问一个热点缓存,如何优化你的缓冲架构?
更多文章:
-
2018年原创汇总
-
2019年原创汇总(持续更新)
-
爆款推荐
-
面试专栏
欢迎长按下图关注公众号 石杉的架构笔记 ,后台回复“ 学习 ”,获取作者独家秘制精品资料

BAT架构经验倾囊相授

正文到此结束
- 本文标签: 分布式事务 http id 服务注册 js UI Document src Master 注册中心 2019 https 集群 同步 IO Spring cloud tk git 压力 时间 总结 线程池 性能优化 并发 db 进程 GitHub 锁 文章 模型 微服务 java 线程 内存模型 参数 Word 高可用 缓存 spring 数据库 多线程 快的 jstack 高并发 JVM 目录 grep redis list mmm 分布式 ArrayList linux 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

