池水很深,不来了解下?
1、什么是线程池
-
线程池,顾名思义就是装线程的池子、线程集合。 在接收任务时,从池子取一个线程来执行。 执行完成之后不会被立即销毁,而是归还给这个池子。 这就是线程池的工作套路。
-
多线程和并发是Java开发中必不可少的一部分,来一个请求起一个线程去处理请求的时代早就过去了。 虽然这种方式实现起来简单,但是如果并发请求数量多,线程执行时间很短,很可能会出现每个请求创建新线程和销毁的时间比处理请求时间更长。 老板要的是吃草挤奶,你整出来吃奶挤草怕是要去财务结工资了。
-
在go中采用用户态线程即协程来追求高并发,协程与内核态线程一般是N:M的关系,N可以远大于M。 而Java中,一个JVM线程对应着一个内核线程,频繁的创建和销毁线程、用户态和内核态过度切换都会影响系统效率。 还好十月革命的一声炮响,给我们送来了线程池。 常用的Tomcat、C3P0、mysql等都有池化的设计思想。
2、为什么使用线程池
-
有人说你啰嗦这么多不就是想使用多线程吗? 那来个任务拿起键盘复制粘贴new Thread()开干不就行了,为什么要使用线程池呢? 你要真不用也没问题,但是当系统出了问题老板请你喝茶的时候,你再来了解怕是晚了。 线程池主要有以下3个作用:
-
Linux下线程是轻量级的进程,通过重复利用已经创建的线程降低线程的创建和销毁造成的开销。
-
提高响应速度。当任务到达后,任务可以不需要等待线程的创建就能立即执行。
-
提高线程可控性。使用线程池可以进行统一的分配,调优和监控。
3、Java中线程池简介
-
本文主要讨论java.util.concurrent包下的ThreadPoolExecutor,这是Java线程池中非常核心的一个类。
-
常用的Executors.newFixedThreadPool、Executors.newSingleThreadExecutor等方式,其内部实际上也是使用ThreadPoolExecutor。 ThreadPoolExecutor继承自AbstractExecutorService,也实现了ExecutorService接口,提供了4个构造器,但最终都是调用最后一个7参数的构造器完成初始化。
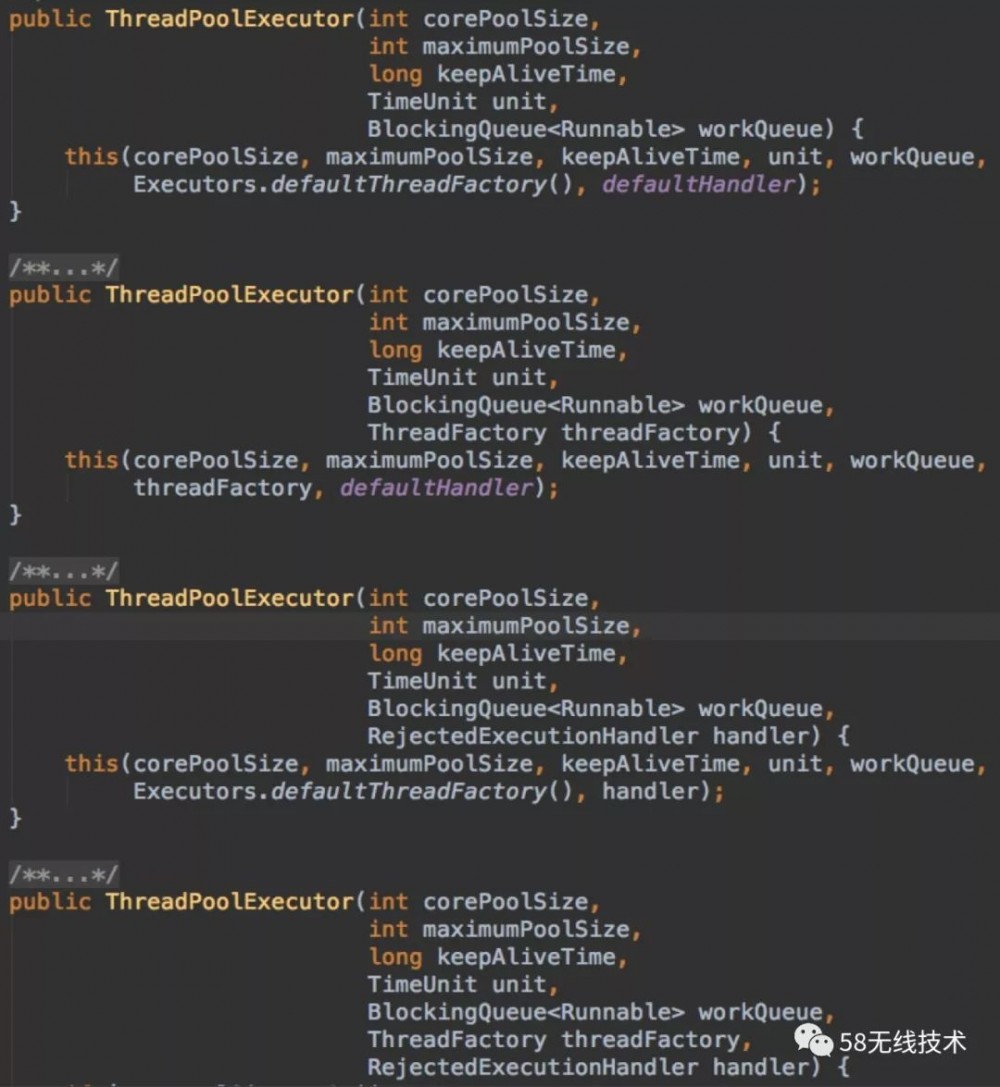
3.1 线程池构造参数
3.1.1 corePoolSize
-
核心线程数。 线程池创建完成后,默认没有任何线程,而是有任务来才创建,类似于懒加载(除非调用prestartAllCoreThreads()或prestartCoreThread()预先创建)。
3.1.2 maximumPoolSize
-
最大线程数。 线程多了浪费资源,少了又不能发挥线程池的性能。 创建线程有代价,不需要每次执行一个任务就创建一个线程。 也不能在任务很多时候,只有少量线程执行,这样来不及处理。 所以真正工作的线程数量随着任务的变化而变化。 因此其与corePoolSize协作来解决这个问题
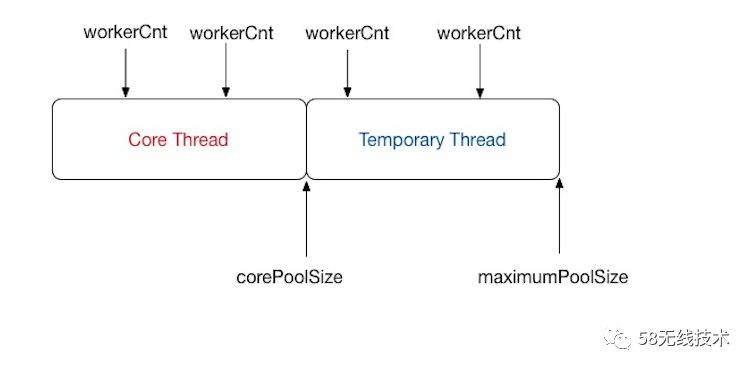
-
可以看出: 工作线程个数可能是从0到最大线程之间变化,与任务数量以及核心线程超时回收等有关系。
3.1.3 keepAliveTime
-
与下面的TimeUnit搭配使用,表示线程没有任务执行时最多保持多久会被回收。 默认下只有线程池中线程数大于corePoolSize时,keepAliveTime才起作用。 即当线程池中线程数大于corePoolSize且空闲时间达到keepAliveTime,那么线程会被回收直到数量不超过corePoolSize。
3.1.4 TimeUnit
-
时间单位,Enum实现。 有DAYS、HOURS、MINUTES、SECONDS、MILLISECONDS、MICROSECONDS、NANOSECONDS7个枚举成员可供使用。 如我们平时Thread.sleep(10000L),可以采用TimeUnit.SECONDS.sleep(10)可读性更高。
3.1.5 ThreadFactory
-
线程池当然少不了线程,线程如何来创建呢? 线程工厂ThreadFactory出场了。 默认使用Execotors.defaultThreadFactory,新创建的线程具相同的NORM_PRIORITY优先级且是非守护线程,同时也设置了线程名称。
//自定义的一个logFilter线程池工厂
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "logFilterThread");
}
};
3.1.6 workQueue
缓存任务的堵塞队列: ArrayBlockingQueue:基于数组结构的有堵塞队列,此队列按照FIFO对元素排序。 LinkedBlockingQueue:一个基于链表结构的阻塞队列,也是按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。 SynchronousQueue:是一个不存储元素的堵塞队列,同步移交。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于堵塞状态。 PriorityBlockingQueue:具有优先级的无限堵塞队列。
tips1:并不是先创建的线程就是核心线程,后创建的就是非核心线程。如果当前工作线程个数大于核心线程数,那么所有线程都可能是"非核心线程",都有被回收的可能。一个线程执行完毕后,会去堵塞队列里面取新任务,在取到任务之前它就是一个闲置的线程。 tips2:核心线程一般不会回收,但也不是绝对的。如果设置了允许核心线程超时回收,那么就没有核心线程这种说法了,所有线程都会通过pool(keepAlivaTime,timeUnit)来获取任务,一旦超时获取不到任务,就会被回收,实际中使用较少。
3.1.7 handler
-
workQueue一定程度上为线程池的执行提供了缓冲。 但如果是有界堵塞队列,就存在队列满的情况。 如果此时工作线程数量达到maximum,此时再有任务提交,线程池就会心有余而力不足,既没有空闲队列来存放,也无法创建新线程来执行任务,这时候我们就需要取舍。 这么复杂的东西,菜鸡们怎么处理的好? 没关系,jdk大牛们早就给我们这些CURD渣渣制定了4种策略:
ThreadPollExecutor.AbortPolicy:直接抛出一个运行时异常(默认的处理策略)。 ThreadPollExecutor.CallerRunsPolicy:使用调用者线程来执行该task(你行你上)。 ThreadPollExecutor.DiscardOldestPolicy:丢弃堵塞队列中最靠前的task,并执行当前task(老年卡的赶紧下车)。 ThreadPollExecutor.DiscardPolicy:直接丢弃task(能力有限,狗命要紧)。
3.2 线程池状态
-
不同状态下的线程池行为是不一样的。
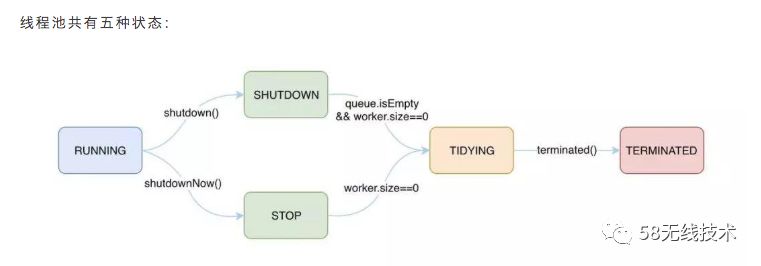
| 状态 | 含义 |
|---|---|
| RUNNING | 该状态下可以处理堵塞队列中任务,也可以接受新任务。 |
| SHUTDOWN | 待关闭状态,不再接受新任务但是可以继续处理堵塞队列中的任务。 |
| STOP | 停止状态,不接收新任务也不处理堵塞队列中任务,并尝试结束执行中任务。 |
| TIDYING | 工作线程数为0进入到此种状态,此时任务执行完毕,且没有工作线程。 |
| TERMINATED | 终止状态,此时线程池终止且释放所有资源。 |
3.3 线程池数量
-
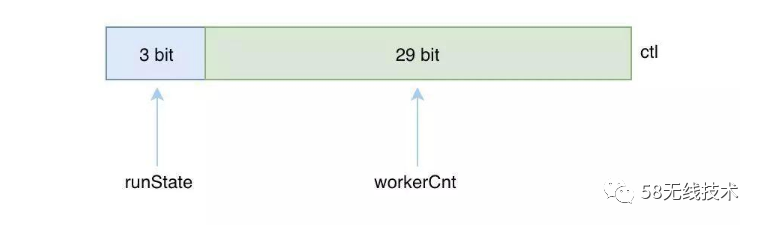
除了状态外,线程池另一个重点就是控制线程资源合理高效利用,所以必须控制工作线程的个数,因此需要保存当前线程池中工作线程的个数。
-
在ThreadPoolExecutor中只用了一个AtomicInteger型的变量就保存了这两个属性的值,那就是ctl。 ctl的高3位用来表示线程池的状态(runState),低29位用来表示工作线程的个数(workerCnt)。 线程池一共只有5种状态,至少需要3位才能表示得了5种状态。 一个变量就搞定了线程池中线程状态和线程数量这2大核心部分,设计可谓巧妙。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING,0)); //高3位表示线程池状态 private static final int COUNT_BITS = Integer.SIZE - 3; //低29位表示线程池容量 private static final int CAPACITY = (1 << COUNT_BITS) - 1;
3.4 execute()
借用一张图来表示当向线程池提交一个新任务时,线程池有3种处理情况: 创建一个工作线程来执行该任务、将任务加入到堵塞队列、拒绝该任务。
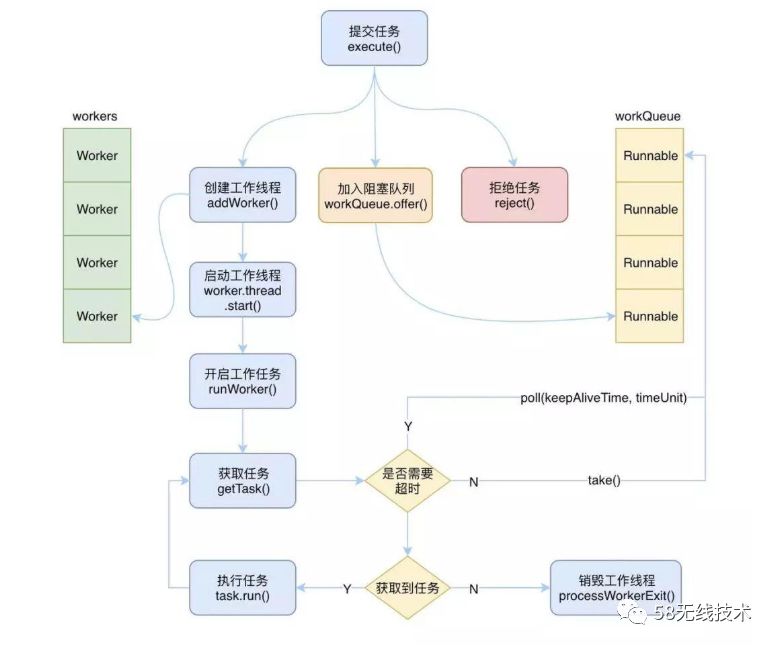
其中执行任务主要有创建线程、启动线程、执行任务三个阶段。 1、创建。 创建前需要做一系列判断,需要确保当前线程可以创建新的线程之后才能创建。如SHUTDOWN、STOP状态下则不能创建新线程。 采用CAS来自增工作线程的个数,自增成功则会创建新的工作线程,即Worker对象。 有一个加锁进行二次验证的过程,最后如果创建成功则会启动该工作线程。 2、启动。 工作线程创建成功之后也就是Worker对象已经创建好了,这时候需要启动工作线程,开始干活。 Worker对象关联着一个Thread所以需要启动的话则Worker.thread.start()。 Worker实现了Runnable接口,所以本质上Worker也是一个线程,一个Worker对象关联着一个Thread对象。 通过线程start开启之后就会调用Runnable的run(),在Worker对象的run()中,调用runWorker(this),也就是把当前对象传递给run()。 3、执行。 runWorker方法被调用之后就是执行具体任务。 首先拿到一个可以执行的任务,而Worker对象中默认绑定了一个任务,拿到该任务则直接执行。 执行完后会去堵塞队列中获取下一个任务执行,如此往复。
3.5 线程池的关闭
-
提供了shutdown()、 shutdownNow()2种关闭方式。 主要区别是shutdown()将线程池切换到SHUTDOWN状态,此时线程池不接受新的任务,但会等待已提交的任务执行完毕。 然后中断所有空闲的worker,最后调用tryTerminate尝试结束线程池。 而shutdownNow()将线程池置于STOP状态,除了线程池不接受新的任务,还会直接终止正在执行的任务,然后调用tryTerminate将线程池设置为TERMINATED状态。
4、一个单线程引发的血案
-
分享一个最近开发的模块,是从kafka的某个主题中消费日志,找出感兴趣的某些日志上报给广告商。每条日志是一个json串,调业务线parseLog()转换成对应entity。起初为了实现简单在一个线程中干了所有事,大致代码如下
private class StreamThread extends Thread{
private KafkaStream<byte[], byte[]> stream;
StreamThread(KafkaStream<byte[], byte[]> stream) {
this.stream = stream;
}
@Override
public void run() {
//kafka某分区stream
ConsumerIterator<byte[], byte[]> it = stream.iterator();
List<String> list = new ArrayList<>();
while (it.hasNext()) {
MessageAndMetadata<byte[], byte[]> message = it.next();
String msg = new String(message.message());
list.add(msg);
//50条一处理
if (list.size() == 50) {
//1.调用str2Entity方法
//2.判断是app点击日志
//3.判断是需要上报的表现类
//4.执行上报
list.clear();
}
}
}
}
-
上述代码是很有问题的,且日志流的接收与处理并没有分开。 一条日志少说几百个字符,解析字符串以及无字段标识ios还是android,只能大致通过refer头中匹配出platform=ios/android来区分客户端,这是个CPU密集型任务。 单线程中也无法发挥多核优势,上线后CPU一直80-90。 这其实是典型的生产-消费者模型,非最终版改造如下
//堵塞队列预设512,默认采用抛弃策略。
//上线后堵塞队列还达不到512,6个corePoolSize是够用的,任务不用添加到堵塞队列。此时maximumPoolSize不起作用。
private static ExecutorService detailFilterConsumerWorks = new ThreadPoolExecutor(
6, 8, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(512),
new ThreadPoolExecutor.DiscardPolicy()
);
//接收日志流信息同上
//消费改造成线程池
if (list.size() == 50) {
//提交到线程池中(解析字符串、过滤、上报等)
detailFilterConsumerWorks.submit(list);
//生产出的批量entity其实又是一个生产-消费者模型
//...
}
线程池参数的设置是需要结合实现情况,可能需要不断的尝试、验证,提升系统效率。 一个非官方不权威推荐是: 1.CPU密集型设为线程数=CPU数+1; 2.IO密集型=CPU数*2;
5、总结
-
本文分析了线程池的创建、任务的提交、状态转移及线程池的关闭;
-
execute()背后task的执行策略。
-
一个简单的生产者-消费者示例。
6、参考
《深入理解Java线程池: ThreadPoolExecutor》
https://juejin.im/entry/58fada5d570c350058d3aaad
《线程池是怎样工作的》
https://www.javazhiyin.com/35966.html

正文到此结束
- 本文标签: sql 线程池 HTML 高并发 java 锁 tar entity 可控性 Service ArrayList json tomcat 同步 cat IOS App id 并发 rmi 开发 src 多线程 Atom java线程 parse mina consumer 进程 http CTO IO stream mysql 参数 js C3P0 IDE queue 本质 解析 db 总结 线程 ask 时间 executor 缓存 linux REST https 工资 UI message Android 模型 tab final 广告 core 代码 ORM JVM list ip ThreadPoolExecutor
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

