『互联网架构』软件架构-解密电商系统-交易分库分表(75)
订单相关表都已经是超大表,最大表的数据量已经是几十亿,数据库处理能力已经到了极限;单库包含多个超大表,占用的硬盘空间已经接近了服务器的硬盘极限,很快将无空间可用;过度解决:我们可以考虑到最直接的方式是增加大容量硬盘,或者对IO有更高要求,还可以考虑增加SSD硬盘来解决容量的问题。此方法无法解决单表数据量问题。可以对数据表历史数据进行归档,但也需要频繁进行归档操作,而且不能解决性能问题硬件上(大小)、单表容量(性能)。
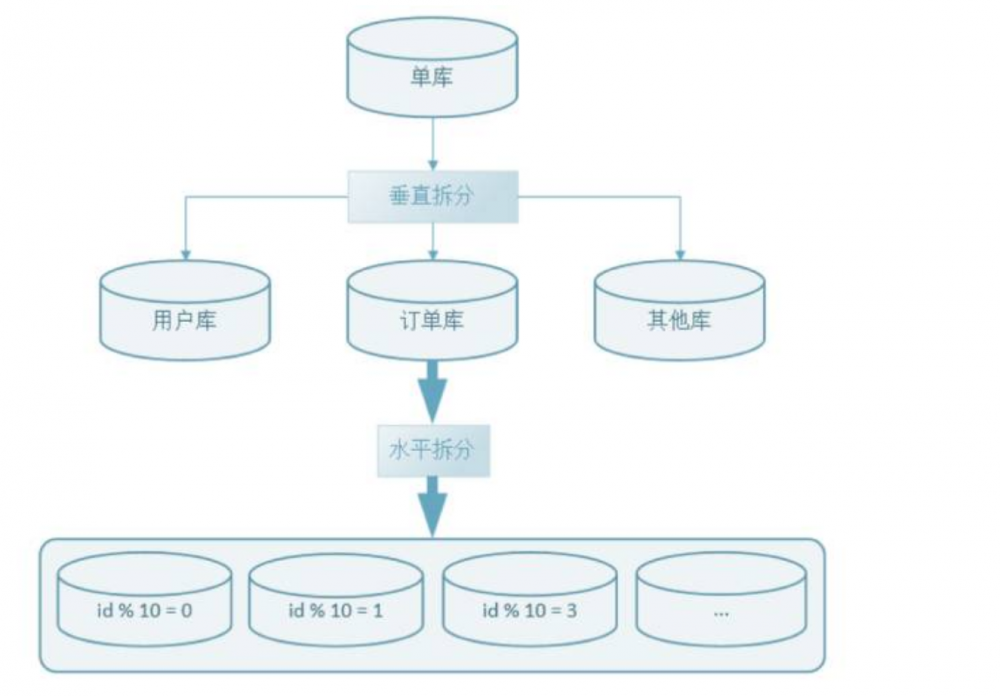
(一)如何优化?有什么方式
- 数据库的读写分离
数据库量还是很庞大,只是读和写数据的分离
- 换mysql》oracle
免费到收费谁能接受
- 分库分表
1、散列hash:hashmap可以很好的去解决数据热点的问题,但是扩容 短板
2、Range增量:他的库容很多好,但是他就是没法解决数据热点的问题。
(二)分库分表
shardingsphere的方式来完成分库分表,表中的一列确定分库键。
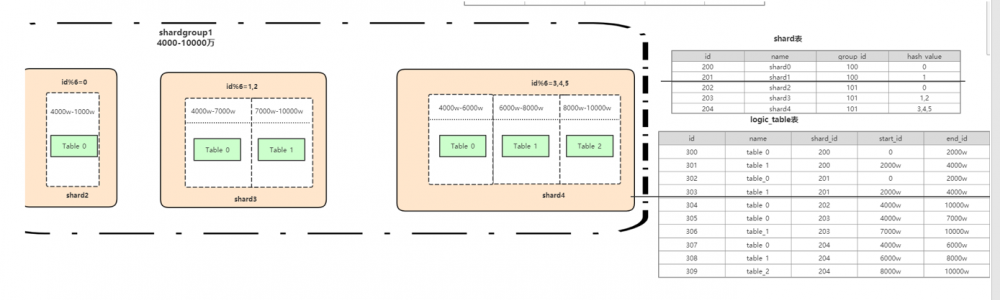
(三)分库分表难点
-
分库分表之分布式唯一ID解决方案
> Uuid
通用唯一识别码
组成部分:当前日期和时间+时钟序列+全局唯一网卡mac地址获取
执行任务数:10000
所有线程共耗时:91.292 s
并发执行完耗时:1.221 s
单任务平均耗时:9.1292 ms
单线程最小耗时:0.0 ms
单线程最大耗时:470.0 ms
优点:
代码实现简单、不占用宽带、数据迁移不影响。
缺点:
无序、无法保证趋势递增、字符存储、传输、查询慢。
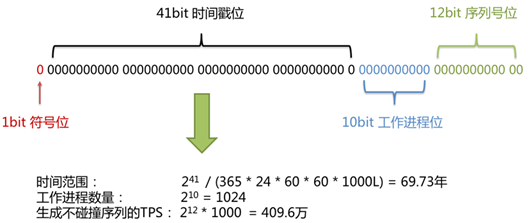
Snowflke
snowflake是Twitter开源的分布式ID生成算法。
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如MySQL的自增键,Oracle的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
io.shardingsphere.core.keygen.DefaultKeyGenerator
执行任务数:10000
所有线程共耗时:15.111 s
并发执行完耗时:217.0 ms
单任务平均耗时:1.5111 ms
单线程最小耗时:0.0 ms
单线程最大耗时:97.0 ms
优点:
不占用宽带、本地生成、高位是毫秒,低位递增。
缺点:
强依赖时钟,如果时间回拨,数据递增不安全。
Mysql
利用数据库的步长来做的。
CREATE TABLE bit_table (
id varchar(255) NOT NULL,//字符
PRIMARY KEY ( id )
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE bit_num (
id bigint(11) NOT NULL AUTO_INCREMENT,
KEY ( id ) USING BTREE
) ENGINE=InnoDB auto_increment=1 DEFAULT CHARSET=utf8;
SET global auto_increment_offset=1; –初始化
SET global auto_increment_increment=100; –初始步长
show global variables;
缺点:
受限数据库、单点故障、扩展麻烦。
优点:
性能可以、可读性强、数字排序。
Redis
redis原子性:对存储在指定key的数值执行原子的加1操作。如果指定的key不存在,那么在执行incr操作之前,会先将它的值设定为0
组成部分:年份+当天当年第多少天+天数+小时+redis 自增
执行任务数:10000
所有线程共耗时:746.767 s
并发执行完耗时:9.381 s
单任务平均耗时:74.6767 ms
单线程最小耗时:0.0 ms
单线程最大耗时:4.119 s
优点:
有序递增、可读性强、符合刚才我们那个扩容方案的id。
缺点:
占用宽带(网络)、依赖第三方、redis。
- 场景
| 名称 | 场景 | 适用指数 |
|---|---|---|
| Uuid | Token、图片id | ★★ |
| Snowflake | ELK、MQ、业务系统 | ★★★★ |
| 数据库 | 非大型电商系统 | ★★★ |
| Redis | 大型系统 | ★★★★★ |
PS:分库分表对于大型系统必须考虑,提前使用第三方工具来完成,如果使用shardsphere来完成比较好,也可以使用mycat。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

