一文摸清 Go 的并发调度模型
与其说并发调度,不如说,这就是一场“配对”游戏。
线程模型
在细说 Go 的调度模型之前,先来说说一般意义的线程模型。线程模型一般分三种,由用户级线程和 OS 线程的不同对应关系决定的。
N:1,即全部用户线程都映射到一个OS线程上,上下文切换成本最低,但无法利用多核资源;
1:1, 一个用户线程对应到一个 OS线程上, 能利用到多核资源,但是上下文切换成本较高,这也是 Java Hotspot VM 的默认实现;
M:N,权衡上面两者方案,既能利用多核资源也能尽可能减少上下文切换成本,但是调度算法的实现成本偏高。
为什么 Go Scheduler 需要实现 M:N 的方案?
线程创建开销大。 对于 OS 线程而言,其很多特性均是操作系统给予的,但对于 Go 程序而言,其中很多特性可能非必要的。这样一来,如果是 1:1 的方案,那么每次 go func(){...} 都需要创建一个 OS 线程,而在创建线程过程中,OS 线程里某些 Go 用不上的特性会转化为不必要的性能开销,不经济。
减少 Go 垃圾回收的复杂度。 依据1:1方案,Go 产生所用用户级线程均交由 OS 直接调度。 Go 的 垃圾回收器 要求在运行时需要停止所有线程,才能使得内存达到稳定一致的状态,而 OS 不可能清楚这些,垃圾回收器也不能控制 OS 去阻塞线程。
Go Scheduler 的 M:N 方案出现,就是为了解决上面的问题。
Go Scheduler
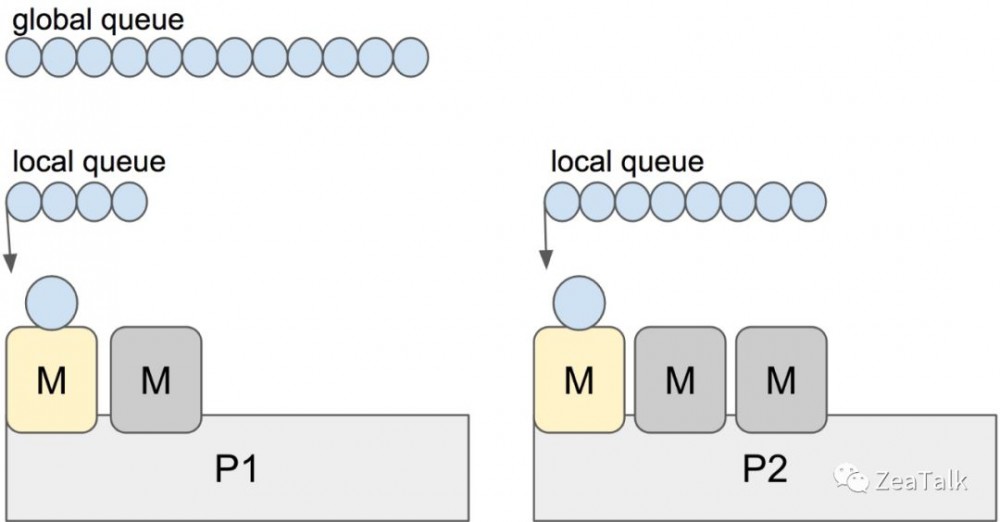
整个并发模型的讨论都离不开 Go Scheduler 的设计实现。
首先,需要了解的是,Go Scheduler 由哪些元素构成呢?
M:Machine,就是 OS 线程本身,数量可配置;
P:Processor, 调度器的核心处理器,通常表示执行上下文,用于匹配 M 和 G 。P 的数量不能超过 GOMAXPROCS 配置数量,这个参数的默认值为CPU核心数;通常一个 P 可以与多个 M 对应,但同一时刻,这个 P 只能和其中一个 M 发生绑定关系;M 被创建之后需要自行在 P 的 free list 中找到 P 进行绑定,没有绑定 P 的 M,会进入阻塞态。
注:GOMAXPROCS 参数很重要,其决定了 P 的最大数量,也决定了自旋 M 的最大数量。何为自旋,后面会提到。
G:Goroutine,Go 的用户级线程,常说的协程,真正携带代码执行逻辑的部分,由 go func(){...} 直接生成;
G0: 其本身也是 G ,也需要跟具体的 M 结合才能被执行,只不过他比较特殊,其本身就是一个 schedule 函数,这个函数包含如下逻辑:
/src/runtime/proc.go:
func schedule() {
// only 1/61 of the time, check the global runnable queue for a G. 仅 1/61 的机会, 检查全局运行队列里面的 G.
// if not found, check the local queue. 如果没找到, 检查本地队列.
// if not found, 还是没找到 ?
// try to steal from other Ps. 尝试从其他 P 偷.
// if not, check the global runnable queue. 还是没有, 检查全局运行队列.
// if not found, poll network. 还是没有, 轮询网络.
}
这里涉及到另外几个概念,本地队列、全局队列以及 “窃取”。
本地队列(local queue):本地是相对 P 而言的本地,每个 P 维护一个本地队列;与 P 绑定的 M 中如若生成新的 G,一般情况下会放到 P 的本地队列;当本地队列满了的时候,才会截取本地队列中 “一半” 的元素放入全局队列中;
全局队列(global queue):承载本地队列“溢出”的 G。为了保证调度公平性,schedule 过程中有 1/61 的几率优先检查全局队列,否则本地队列一直满载的情况下,全局队列中的 G 将永远无法被调度到;
窃取(stealing): 这似乎和 Java Fork-Join 中的 work-stealing 模型很相似,其目的也是一样,就是为了使得空闲(idle)的 M 有活干,不空等,提高计算资源的利用率。窃取也是有章法的,规则是随机从其他 P 的本地队列里窃取 “一半” 的 G。
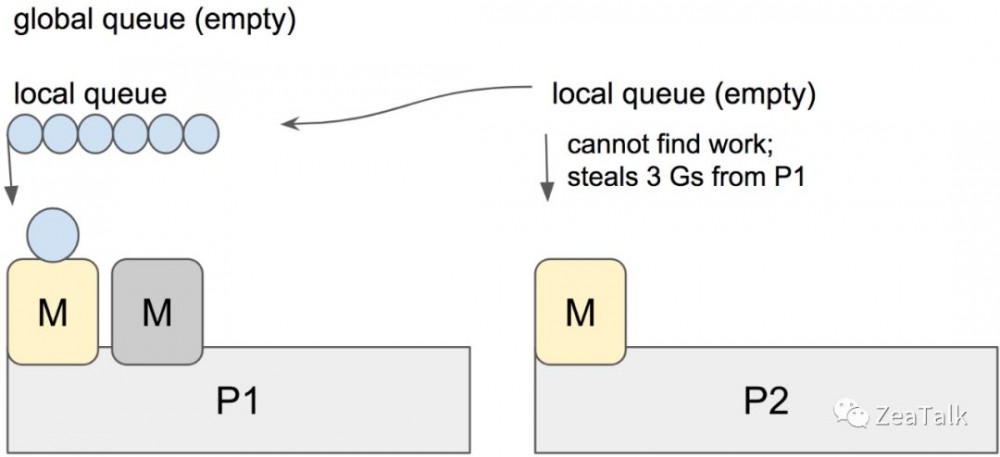
综上,整个调度流程就是:
-
1/61 的几率在全局队列中找 G,60/61 的几率在本地队列找 G;
-
如果全局队列找不到 G,从 P 的本地队列找 G;
-
如果找不到,从其他 P 的本地队列中窃取 G;
-
如果找不到,则从全局队列中拿取一部分 G 到本地队列。这里 拿取 的 “一部分” 满足一个公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
注:这里 GQ 表示全局队列。
-
如果找不到,从网络中 poll G。
只要找到了 G, 就会立马丢给 M 执行。当然上述任何执行逻辑如果没有 running 的 M 参与,都是无法真正被执行的,这包括调度逻辑本身。
一言蔽之,调度的本质就是 P 将 G 合理的分配给某个 M 的过程。
线程自旋(Spinning Threads)
线程自旋是相对于线程阻塞而言的 ,表象就是循环执行一个指定逻辑(就是上面提到的调度逻辑,目的是不停地寻找 G)。这样做的问题显而易见,如果 G 迟迟不来,CPU 会白白浪费在这无意义的计算上。但好处也很明显,降低了 M 的上下文切换成本,提高了性能。
具体来说,假设Scheduler 中全局和本地队列均为空,M 此时没有任何任务可以处理,那么你会选择让 M 进入阻塞状态还是选择让 CPU 空转等待 G 的驾临?
Go 的设计者倾向于高性能的并发表现,选择了后者。当然前面也提到过,为了避免过多浪费 CPU 资源,自旋的线程数不会超过 GOMAXPROCS ,这是因为一个 P 在同一个时刻只能绑定一个 M,P的数量不会超过 GOMAXPROCS ,自然被绑定的 M 的数量也不会超过。对于未被绑定的“游离态”的 M,会进入休眠阻塞态。
M 如果因为 G 发起了系统调用进入了阻塞态会怎样?
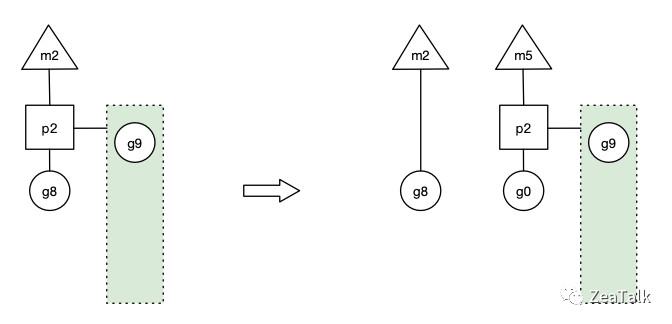
如图,如果 G8 发起了阻塞系统调用(例如阻塞 IO 操作),使得对应的 M2 进入了阻塞态。此时如果没有任何的处理,Go Scheduler 就会在这段阻塞的时间内,白白缺失了一个 OS 线程单元。
Go 设计者的解决方案是,一旦 G8 发起 Syscall 使得 M2 进入阻塞态,此时的 P2 会立即与 M2 解绑,保留 M2 与 G8 的关系,继而与新的 OS 线程 M5 绑定,继续下一轮的调度。那么虽然 M2 进入了阻塞态,但宏观来看,并没有缺失任何处理单元,P2 依然正常工作。
那 G8 的阻塞操作返回后怎么办?
G8 失去了 P2,意味着失去了执行机会,M2 被唤醒以后第一件事就是要窃取一个上下文(Processor),还给 G8 执行机会。然而现实是 M2 不一定能够找到 P 绑定,不过找不到也没关系,M2 会将 G8 丢到全局队列中,等待调度。
这样一来 G8 会被其他的 M 调度到,重新获得执行机会,继续执行阻塞返回之后的逻辑。
与 Java F-J Task 相比,Goroutine 是否有本质区别?
直觉告诉我,这两者并没有本质区别。
两个方案均为 M:N,两者定位都是“轻量级”的用户线程,而并非与 OS 线程一一对应。引入的本地队列使得在大多数场景下,线程争抢会更少。而从调度算法细分析来看,Go Scheduler 会比 F-J 更加复杂,对线程的控制更加精细,其适用的场景也更加全面。
总之,作为一个 Java 开发者,如果你是用 Hotspot VM,是默认不支持原生协程的,但不代表不能实现所谓的协程,F-J 可以理解为一个简易版实现。
然而 Go 并发调度的优势在哪呢?
原生支持;调度算法更加科学,更具备普适性;另外,简洁的语法掩盖了底层细节, 这让 开发者轻松实现高性能并发编程,成为可能。
以上关于 F-J 和Go Scheduler 的讨论,是我的个人理解,有不同想法的欢迎交流。端午安康!
完。
参考资料
https://rakyll.org/scheduler/
https://morsmachine.dk/go-scheduler
https://lingchao.xin/post/gos-work-stealing-scheduler.html
https://segmentfault.com/a/1190000018775901
https://segmentfault.com/a/1190000018777972#articleHeader6
https://github.com/golang/go/blob/master/src/runtime/proc.go
https://mp.weixin.qq.com/s/uu7J_9nsBu-K7E7Chw5ttw
写留言
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

