RxJava浅析
RxJava 是 ReactiveX 推出的一个开源库,它是 Reactive Extensions 的Java VM实现,可以很方便的在Java中实现响应式编程。解决了Java中繁琐的异步切换、Callback hell等问题,使逻辑变得更加简洁。
1、操作符
RxJava 提供了 丰富&功能强大的操作符 ,可以说这些操作符就是 RxJava 的基础及核心,所以学习 RxJava 都是从这些操作符开始。但由于 RxJava 的操作符种类繁多且网络上已经出现了很多优秀的讲解 RxJava 操作符的文章,所以本文仅列举一些操作符讲解。
1.1、interval
Observable.interval(3000, TimeUnit.MILLISECONDS)//每隔3s发一个事件
.subscribeOn(Schedulers.io())
.subscribe(new Observer<Long>() {
@Override
public void onSubscribe(Disposable d) {
Log.i("tag", "start");
}
@Override
public void onNext(Long aLong) {
Log.i("tag", "onNext:" + aLong);
}
@Override
public void onError(Throwable e) {
Log.i("tag", "error:" + e.getMessage());
}
@Override
public void onComplete() {
Log.i("tag", "onComplete");
}
});
复制代码
interval 操作符主要就是实现轮询操作,通过该操作符来实现轮询效果会比 Handler 、 Timer 及 newScheduledThreadPool 更简洁,更优雅。但从原理上来看, interval 其实就是对 newScheduledThreadPool 的封装。当然,我们也可以自己对 Handler 、 Timer 来进行封装。
1.2、concatMap操作符
Observable.create(new ObservableOnSubscribe<File>() {
@Override
public void subscribe(ObservableEmitter<File> emitter) throws Exception {
File file = new File(path + File.separator + "blacklist");
emitter.onNext(file);
}
}).concatMap(new Function<File, ObservableSource<File>>() {
@Override
public ObservableSource<File> apply(File file) throws Exception {
if (!file.isDirectory()) {
return Observable.empty();
}
return Observable.fromArray(file.listFiles());
}
}).subscribe(new Consumer<File>() {
@Override
public void accept(File file) throws Exception {
LogUtils.i("getPackageNames", "删除文件夹中已存在的文件");
file.delete();
}
});
复制代码
concatMap 操作符主要是进行事件的拆分及合并。在上面示例中就实现了对文件夹的遍历及获得文件夹下的每个 File 对象。
1.3、map及filter操作符
Observable.fromIterable(data)
.map(new Function<PackageNameData, File>() {//类型转换
@Override
public File apply(PackageNameData pkg) throws Exception {
LogUtils.i("getPackageNames", "pkg:" + pkg.toString());
String path = FileUtil.getWeikePath() + File.separator + "blacklist";
File file = new File(path);
if (file.exists() && file.isFile()) {
file.delete();
}
boolean b = file.mkdirs();
if (b) {
LogUtils.i("getPackageNames", "创建文件夹" + file + "成功");
} else {
LogUtils.i("getPackageNames", "创建文件夹" + file + "失败");
}
path = path + File.separator + pkg.appPackageName.trim();
return new File(path);
}
})
.filter(new Predicate<File>() {//筛选
@Override
public boolean test(File file) throws Exception {
return !file.exists();
}
})
.subscribe(new Consumer<File>() {
@Override
public void accept(File file) throws Exception {
LogUtils.i("getPackageNames", "创建新的文件");
try {
boolean b = file.createNewFile();
if (!b) {
FileUtil.writeTxt(file.getAbsolutePath(), "");
}
} catch (IOException e) {
LogUtils.i("getPackageNames", "创建文件失败:" + e.getMessage());
FileUtil.writeTxt(file.getAbsolutePath(), "");
}
}
});
复制代码
filter 操作符主要是做筛选操作,如果返回false,则不会继续向下发送事件。所以如果想要在返回false的情况下也要继续发送事件的话,则不能使用该操作符。
map 操作符主要是对类型的转换,如上面示例中就是将 PackageNameData 类型转换成一个 File 类型并向下传递。
关于 RxJava 操作符的更多内容可以去阅读Carson_Ho的 RxJava 系列文章、扔物线的 给 Android 开发者的 RxJava 详解 等文章。
2、线程调度及同步机制
在Java中,一般讨论线程都会想到 Thread 类,但在RxJava中,我们会发现, RxJava 中的线程是可以做定时、轮询等操作。这到底是怎么实现的尼?或许会想到定时器类—— Timer ,但其实不是 Timer ,是通过一个可定时、轮询执行操作的线程池—— newScheduledThreadPool 来实现的。在 RxJava 中,由于该线程池有且仅有一个线程,因此可以将 该线程池理解为一种特殊线程,一种仅在 RxJava 中使用的特殊线程 。在后面内容中会将这种特殊的线程简称为线程。
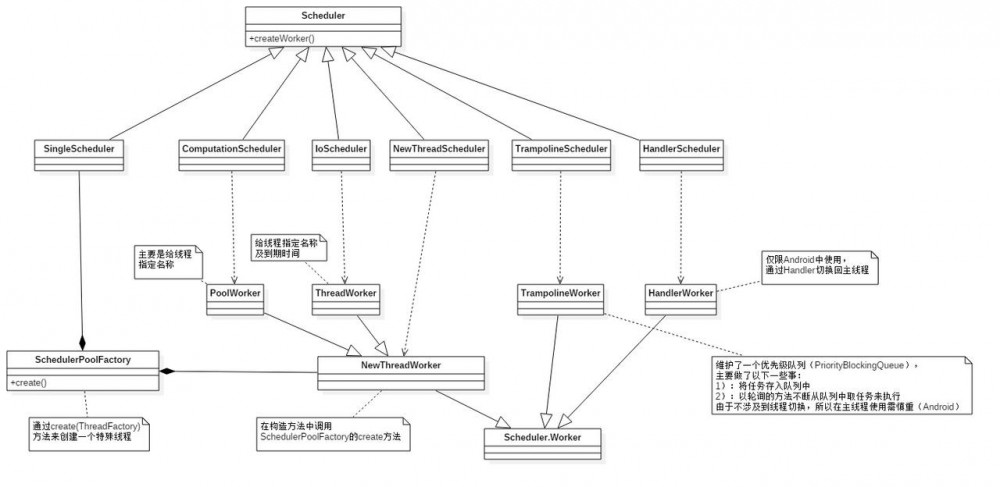
从图中可以看出,RxJava中线程都是在 SchedulerPoolFactory 类的 create 方法中创建的。
public static ScheduledExecutorService create(ThreadFactory factory) {
//创建线程为1的一个线程池,它相当于RxJava中的特殊线程
final ScheduledExecutorService exec = Executors.newScheduledThreadPool(1, factory);
tryPutIntoPool(PURGE_ENABLED, exec);
return exec;
}
复制代码
2.1、Schedulers.single()
在 RxJava 中可以使用 Schedulers.single() 来创建一个线程,该方法有且只会创建一个新的线程,类似于线程池中的 newSingleThreadExecutor 。所以该线程只会在当前任务执行完毕后才执行下一个任务—— 相当于串行执行 。下面来看一下源码里的实现。
public final class SingleScheduler extends Scheduler {
final ThreadFactory threadFactory;
final AtomicReference<ScheduledExecutorService> executor = new AtomicReference<ScheduledExecutorService>();
/** The name of the system property for setting the thread priority for this Scheduler. */
//相当于一个key,可以通过设置KEY_SINGLE_PRIORITY对应的值来设置线程优先级
private static final String KEY_SINGLE_PRIORITY = "rx2.single-priority";
//可以通过该参数来判断执行的线程名称
private static final String THREAD_NAME_PREFIX = "RxSingleScheduler";
...
public SingleScheduler() {
this(SINGLE_THREAD_FACTORY);
}
public SingleScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
//创建一个线程并使用原子变量类AtomicReference来管理该线程
//使用lazySet并不会让值立即对所有线程可见,而set则是立即对所有线程可见的
executor.lazySet(createExecutor(threadFactory));
}
//创建一个线程,SchedulerPoolFactory.create(threadFactory)该方法在上面前面已经讲述
static ScheduledExecutorService createExecutor(ThreadFactory threadFactory) {
return SchedulerPoolFactory.create(threadFactory);
}
//线程停止执行,关于如何停止可以去查看线程池的停止执行
@Override
public void shutdown() {...}
...
}
复制代码
可以看出,在 SingleScheduler 的构造方法中就通过 createExecutor 创建了一个线程,而 SingleScheduler 这个类仅会创建一次。所以当使用 Schedulers.single() 时仅会创建一个线程。
2.2、Schedulers.newThread()
在 RxJava 中可以使用 Schedulers.newThread() 来创建一个新线程,该线程不会被重用,线程数量会随着调用次数的增加而增加。
public final class NewThreadScheduler extends Scheduler {
final ThreadFactory threadFactory;
private static final String THREAD_NAME_PREFIX = "RxNewThreadScheduler";
private static final RxThreadFactory THREAD_FACTORY;
/** The name of the system property for setting the thread priority for this Scheduler. */
private static final String KEY_NEWTHREAD_PRIORITY = "rx2.newthread-priority";
static {
int priority = Math.max(Thread.MIN_PRIORITY, Math.min(Thread.MAX_PRIORITY,
Integer.getInteger(KEY_NEWTHREAD_PRIORITY, Thread.NORM_PRIORITY)));
THREAD_FACTORY = new RxThreadFactory(THREAD_NAME_PREFIX, priority);
}
public NewThreadScheduler() {
this(THREAD_FACTORY);
}
public NewThreadScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
}
//创建一个新的线程
@NonNull
@Override
public Worker createWorker() {
return new NewThreadWorker(threadFactory);
}
}
复制代码
上面的 NewThreadWorker 是一个非常重要类,后面的 Schedulers.computation() 及 Schedulers.io() 都是根据此类来创建线程的。

2.3、Schedulers.computation()
Schedulers.computation() 主要用来做一些计算密集型操作,会根据当前设备的CPU数量来创建一组线程。然后给不同任务分配不同的线程。下面来看源码的实现。
public final class ComputationScheduler extends Scheduler implements SchedulerMultiWorkerSupport {
...
static {
//最大线程数量,根据CPU数量计算出的
MAX_THREADS = cap(Runtime.getRuntime().availableProcessors(), Integer.getInteger(KEY_MAX_THREADS, 0));
...
}
static int cap(int cpuCount, int paramThreads) {
return paramThreads <= 0 || paramThreads > cpuCount ? cpuCount : paramThreads;
}
//我认为这里实现了一个简单的线程池
static final class FixedSchedulerPool implements SchedulerMultiWorkerSupport {
final int cores;
final PoolWorker[] eventLoops;
long n;
FixedSchedulerPool(int maxThreads, ThreadFactory threadFactory) {
// initialize event loops
//线程的数量
this.cores = maxThreads;
//创建一个数组,保存对应的线程
this.eventLoops = new PoolWorker[maxThreads];
//创建一组线程
for (int i = 0; i < maxThreads; i++) {
this.eventLoops[i] = new PoolWorker(threadFactory);
}
}
//根据索引来给不同任务分配不同的线程。
public PoolWorker getEventLoop() {
int c = cores;
if (c == 0) {
return SHUTDOWN_WORKER;
}
// simple round robin, improvements to come
return eventLoops[(int)(n++ % c)];
}
public void shutdown() {
for (PoolWorker w : eventLoops) {
w.dispose();
}
}
@Override
public void createWorkers(int number, WorkerCallback callback) {...}
}
public ComputationScheduler() {
this(THREAD_FACTORY);
}
//创建线程
public ComputationScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
this.pool = new AtomicReference<FixedSchedulerPool>(NONE);
start();
}
...
@NonNull
@Override
public Disposable scheduleDirect(@NonNull Runnable run, long delay, TimeUnit unit) {
//给任务分配一个线程
PoolWorker w = pool.get().getEventLoop();
return w.scheduleDirect(run, delay, unit);
}
@NonNull
@Override
public Disposable schedulePeriodicallyDirect(@NonNull Runnable run, long initialDelay, long period, TimeUnit unit) {
//给任务分配一个线程
PoolWorker w = pool.get().getEventLoop();
return w.schedulePeriodicallyDirect(run, initialDelay, period, unit);
}
//创建一组要使用的线程
@Override
public void start() {
FixedSchedulerPool update = new FixedSchedulerPool(MAX_THREADS, threadFactory);
if (!pool.compareAndSet(NONE, update)) {
update.shutdown();
}
}
//停止线程执行
@Override
public void shutdown() {...}
...
//在NewThreadWorker中创建了线程,这里之所以不直接使用NewThreadWorker是因为这里传递的threadFactory可以根据名称来区分线程
static final class PoolWorker extends NewThreadWorker {
PoolWorker(ThreadFactory threadFactory) {
super(threadFactory);
}
}
}
复制代码
原理还是比较简单的,用一个数组来保存一组线程,然后根据索引将任务分配给每个线程,由于每个线程实际上是一个线程池,而这个线程池会把多余的任务放在队列中等待执行,所以每个线程后面任务的执行需要等待前面的任务执行完毕。
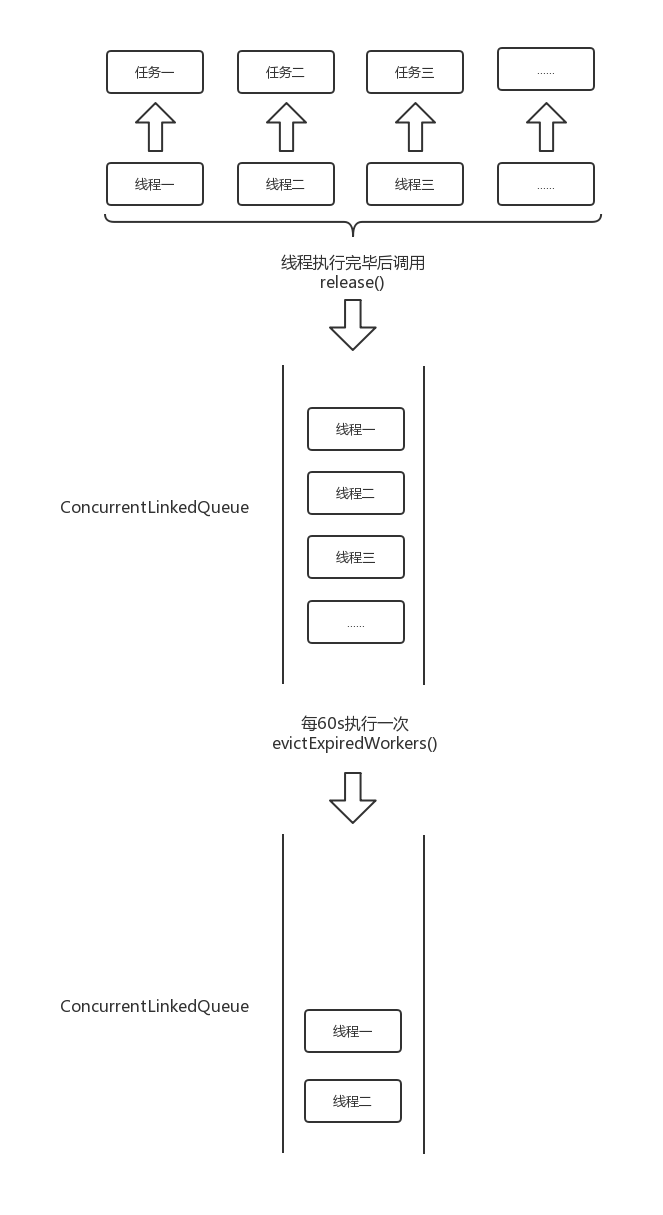
2.4、Schedulers.io()
Schedulers.io() 可以说是 RxJava 里实现最复杂的,它不仅会创建线程,也会清除线程。在 IoScheduler 中实现了一个缓存池,当线程执行完毕后会将线程放入缓存池中。下面来看一下源码实现。
public final class IoScheduler extends Scheduler {
...
//线程的存活时间
public static final long KEEP_ALIVE_TIME_DEFAULT = 60;
private static final long KEEP_ALIVE_TIME;
//线程的存活时间单位
private static final TimeUnit KEEP_ALIVE_UNIT = TimeUnit.SECONDS;
...
//缓存池
static final class CachedWorkerPool implements Runnable {
private final long keepAliveTime;
private final ConcurrentLinkedQueue<ThreadWorker> expiringWorkerQueue;
final CompositeDisposable allWorkers;
private final ScheduledExecutorService evictorService;
private final Future<?> evictorTask;
private final ThreadFactory threadFactory;
CachedWorkerPool(long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory) {
this.keepAliveTime = unit != null ? unit.toNanos(keepAliveTime) : 0L;
this.expiringWorkerQueue = new ConcurrentLinkedQueue<ThreadWorker>();
this.allWorkers = new CompositeDisposable();
this.threadFactory = threadFactory;
ScheduledExecutorService evictor = null;
Future<?> task = null;
if (unit != null) {
//创建一个线程,该线程默认会每60s执行一次,来清除已到期的线程
evictor = Executors.newScheduledThreadPool(1, EVICTOR_THREAD_FACTORY);
//设置定时任务
task = evictor.scheduleWithFixedDelay(this, this.keepAliveTime, this.keepAliveTime, TimeUnit.NANOSECONDS);
}
evictorService = evictor;
evictorTask = task;
}
@Override
public void run() {
//执行清除时间到期的线程操作
evictExpiredWorkers();
}
//每一个任务都从队列中获取线程,如果队列中有线程的话
ThreadWorker get() {
if (allWorkers.isDisposed()) {
return SHUTDOWN_THREAD_WORKER;
}
//如果缓存池不为空
while (!expiringWorkerQueue.isEmpty()) {
//从缓冲池中获得线程
ThreadWorker threadWorker = expiringWorkerQueue.poll();
if (threadWorker != null) {
return threadWorker;
}
}
// No cached worker found, so create a new one.
//缓存池为空,需要创建一个新的线程
ThreadWorker w = new ThreadWorker(threadFactory);
allWorkers.add(w);
return w;
}
//将执行完毕的线程放入缓存队列中
void release(ThreadWorker threadWorker) {
// Refresh expire time before putting worker back in pool
//刷新线程的到期时间
threadWorker.setExpirationTime(now() + keepAliveTime);
//将执行完毕的线程放入缓存池中
expiringWorkerQueue.offer(threadWorker);
}
//默认每60s执行一次,主要是清除队列中的已过期线程
void evictExpiredWorkers() {
if (!expiringWorkerQueue.isEmpty()) {
long currentTimestamp = now();
for (ThreadWorker threadWorker : expiringWorkerQueue) {
if (threadWorker.getExpirationTime() <= currentTimestamp) {
//如果线程threadWorker已到期就将其从缓存中移除
if (expiringWorkerQueue.remove(threadWorker)) {
allWorkers.remove(threadWorker);
}
} else {
// Queue is ordered with the worker that will expire first in the beginning, so when we
// find a non-expired worker we can stop evicting.
break;
}
}
}
}
...
}
public IoScheduler() {
this(WORKER_THREAD_FACTORY);
}
public IoScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
this.pool = new AtomicReference<CachedWorkerPool>(NONE);
start();
}
@Override
public void start() {
CachedWorkerPool update = new CachedWorkerPool(KEEP_ALIVE_TIME, KEEP_ALIVE_UNIT, threadFactory);
if (!pool.compareAndSet(NONE, update)) {
update.shutdown();
}
}
...
//创建一个新的线程
static final class ThreadWorker extends NewThreadWorker {
//到期时间,如果该线程到期后就会被清除
private long expirationTime;
ThreadWorker(ThreadFactory threadFactory) {
super(threadFactory);
this.expirationTime = 0L;
}
//获取线程的到期时间
public long getExpirationTime() {
return expirationTime;
}
//刷新到期时间
public void setExpirationTime(long expirationTime) {
this.expirationTime = expirationTime;
}
}
}
复制代码
CachedWorkerPool 是一个非常重要的类,它内部有一个队列及线程。该队列主要是 缓存已经使用完毕的线程 ,而 CachedWorkerPool 中的线程 evictor 主要就是做清除操作,默认是每60s就遍历一遍队列,如果线程过期就从队列中将该线程移除。这里的队列没有数量限制,所以理论上可以创建无限多的线程。
2.5、Schedulers.trampoline()
Schedulers.trampoline() 用的比较少,官方对于它的解释是:
在当前线程上执行,但不会立即执行。任务会被放入队列并在当前任务完成后执行。注意: 是在当前线程执行,也就意味着不会进行线程切换 。
通过查看源码可以发现,当 Schedulers.trampoline() 没有延迟任务时, Schedulers.trampoline() 使用与没有使用都没区别。但执行延时任务时,就会将当前任务添加进队列中,等待时间到了再执行。
public final class TrampolineScheduler extends Scheduler {
private static final TrampolineScheduler INSTANCE = new TrampolineScheduler();
public static TrampolineScheduler instance() {
return INSTANCE;
}
@NonNull
@Override
public Worker createWorker() {
return new TrampolineWorker();
}
/* package accessible for unit tests */TrampolineScheduler() {
}
//当不是延时任务时,直接执行该任务
@NonNull
@Override
public Disposable scheduleDirect(@NonNull Runnable run) {
RxJavaPlugins.onSchedule(run).run();
return EmptyDisposable.INSTANCE;
}
...
//执行延时任务,就会将该任务添加进优先级队列PriorityBlockingQueue中
static final class TrampolineWorker extends Scheduler.Worker implements Disposable {
final PriorityBlockingQueue<TimedRunnable> queue = new PriorityBlockingQueue<TimedRunnable>();
private final AtomicInteger wip = new AtomicInteger();
final AtomicInteger counter = new AtomicInteger();
volatile boolean disposed;
@NonNull
@Override
public Disposable schedule(@NonNull Runnable action) {
//将任务压入队列中
return enqueue(action, now(TimeUnit.MILLISECONDS));
}
@NonNull
@Override
public Disposable schedule(@NonNull Runnable action, long delayTime, @NonNull TimeUnit unit) {
long execTime = now(TimeUnit.MILLISECONDS) + unit.toMillis(delayTime);
//将任务压入队列中
return enqueue(new SleepingRunnable(action, this, execTime), execTime);
}
//将任务添加进队列中等待执行
Disposable enqueue(Runnable action, long execTime) {
if (disposed) {
return EmptyDisposable.INSTANCE;
}
final TimedRunnable timedRunnable = new TimedRunnable(action, execTime, counter.incrementAndGet());
queue.add(timedRunnable);
if (wip.getAndIncrement() == 0) {
int missed = 1;
for (;;) {
for (;;) {
if (disposed) {
queue.clear();
return EmptyDisposable.INSTANCE;
}
//获取一个要执行的任务
final TimedRunnable polled = queue.poll();
if (polled == null) {
break;
}
if (!polled.disposed) {
//执行任务
polled.run.run();
}
}
//重置wip的值
missed = wip.addAndGet(-missed);
if (missed == 0) {
break;
}
}
return EmptyDisposable.INSTANCE;
} else {
// queue wasn't empty, a parent is already processing so we just add to the end of the queue
return Disposables.fromRunnable(new AppendToQueueTask(timedRunnable));
}
}
...
}
...
}
复制代码
2.6、AndroidSchedulers.mainThread()
AndroidSchedulers.mainThread() 是 RxAndroid 中的的API。由于在android中需要在主线程更新UI,所以需要该API来切换回主线程。在Android中想要切换回主线程,就只有通过 Handler 来实现,而 AndroidSchedulers.mainThread() 也不例外。非常简单,就是通过 Handler 向主线程发送消息。
final class HandlerScheduler extends Scheduler {
//传递进来的Handler已经是主线程的Handler了,只要通过该Handler发送消息即可
private final Handler handler;
private final boolean async;
HandlerScheduler(Handler handler, boolean async) {
this.handler = handler;
this.async = async;
}
@Override
@SuppressLint("NewApi") // Async will only be true when the API is available to call.
public Disposable scheduleDirect(Runnable run, long delay, TimeUnit unit) {
...
//发送消息,切换回主线程
handler.sendMessageDelayed(message, unit.toMillis(delay));
return scheduled;
}
@Override
public Worker createWorker() {
return new HandlerWorker(handler, async);
}
private static final class HandlerWorker extends Worker {
private final Handler handler;
private final boolean async;
private volatile boolean disposed;
HandlerWorker(Handler handler, boolean async) {
this.handler = handler;
this.async = async;
}
@Override
@SuppressLint("NewApi") // Async will only be true when the API is available to call.
public Disposable schedule(Runnable run, long delay, TimeUnit unit) {
...
//发送消息,切换回主线程
handler.sendMessageDelayed(message, unit.toMillis(delay));
// Re-check disposed state for removing in case we were racing a call to dispose().
if (disposed) {
handler.removeCallbacks(scheduled);
return Disposables.disposed();
}
return scheduled;
}
...
}
...
}
复制代码

2.7、线程同步机制
在Android及一些开源库(如 OKHttp 、 Glide 等)中,多线程之间的数据同步问题一般都是采用 synchronized 来实现,因为它是使用最简单也最深入人心的一种实现方式,也是性能比较高的一种实现方法。但它却是一种悲观锁—— 不管是否有线来程竞争都会加锁 ,这就导致了在线程竞争比较低的情况下,它的性能不如乐观锁—— 一种通过CAS来实现的锁机制 。而 RxJava 中大量使用的 原子变量类 Atomicxxxxxx 就是一种乐观锁,也是 CAS 的一种实现。
CAS 全称为 Compare And Swap ,即 比较并替换 。它包含了3个操作数——需要读写的内存位置V、进行比较的值A和拟写入的新值B。当且仅当V的值等于A时, CAS 才会通过原子方式用新值B来更新V的值,否则不会执行任何操作。关于更多 CAS 可以参考笔者的Java之CAS无锁算法这篇文章。
在 RxJava 中都会使用装饰模式将 Observer 包裹成与操作符对应的类 xxxxxxObserver ,如 FlatMap 、 merge 等操作符对应的类—— MergeObserver 、 subscribeOn 操作符对应的类—— SubscribeOnObserver 、 observeOn 对应的类—— ObserveOnObserver 等。而 MergeObserver 、 SubscribeOnObserver 及 ObserveOnObserver 都分别继承自 AtomicInteger 、 AtomicReference 及 AtomicInteger 。也就是通过原子变量类来实现了线程之间的数据同步。
在 Flowable 中也是如此,只不过由 xxxxxxObserver 变为了 xxxxxSubscriber 而已。
3、生产者-消费者模型
生产者——消费者模式其实就是一种线程间协作的思想。在学习多线程时,实现的买票与卖票案例,就是该模型的实现。或许在开发中很少主动使用到该模型,但基本上都会被动使用该模型。如音视频的下载与解码、网络图片的下载与展示、RxJava事件的发送与接收等。到这里,我们会疑惑,该模型与RxJava有什么关联?是何种联系尼?其实RxJava的异步订阅就是该模型的一种实现,也因此会在上游发送事件的速度超出下游处理事件的速度时,抛 MissingBackpressureException 异常。
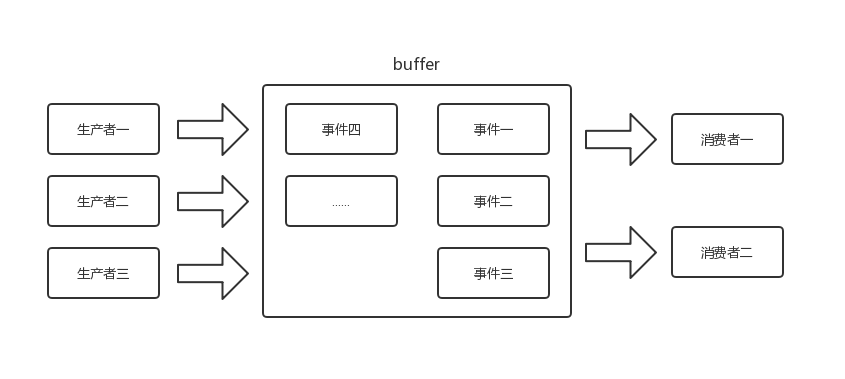
3.1、Backpressure
Backpressure 既是大家所说的背压,但是我认为这个翻译是有一点问题的,没有一目了然的表达 Backpressure ,笔者认为扔物线在 如何形象的描述反应式编程中的背压(Backpressure)机制? 中的回答就很好的阐述了 Backpressure 。 产生的原因——主要是 在异步场景下,上游发送事件的速度超过了下游处理事件的速度,使buffer溢出,从而抛出 MissingBackpressureException 异常 ,这里重点在于 buffer的溢出(RxJava 2.x中的默认buffer大小为128) 。在1.x的版本中,解决该问题的方案不是很彻底,但在2.x的版本中则分出一个新类 Flowable 来处理这个问题。它与 Observable 处理事件的流程刚好相反, Observable 的事件是由被观察者主动发送的,观察者无法控制速度,只能被动接受,而 Flowable 则是由观察者主动获取事件,从而解决了 MissingBackpressureException 异常。下面来看一个示例。
Flowable.create(new FlowableOnSubscribe<String>() {
@Override
public void subscribe(FlowableEmitter<String> emitter) throws Exception {
for (int i = 0; i < 200; i++) {
emitter.onNext("str" + i);
}
}
}, BackpressureStrategy.ERROR)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new FlowableSubscriber<String>() {
@Override
public void onSubscribe(Subscription s) {
Log.w("Flowable", "onSubscribe");
}
@Override
public void onNext(String s) {
Log.w("Flowable", "s:" + s);
}
@Override
public void onError(Throwable t) {
Log.w("Flowable", "error:" + t.toString());
}
@Override
public void onComplete() {
Log.w("Flowable", "onComplete");
}
});
复制代码
Flowable 的 create 方法的第二个参数是设置 Backpressure 的模式,它有如下几种模式:
-
BackpressureStrategy.MISSING:上游不做任何事件缓存及丢弃,全部交给下游处理,如果有溢出的话,上游不管,交给下游处理。 -
BackpressureStrategy.ERROR:当下游无法及时处理事件从而导致缓存队列已满时,会给出MissingBackpressureException异常提示,默认是该策略。 -
BackpressureStrategy.BUFFER:缓存队列无限大,所以不会抛出MissingBackpressureException异常。直到下游处理完毕所有事件为止,也意味着内存会随着事件的增多而增大。 -
BackpressureStrategy.DROP:如果下游无法及时处理事件从而当缓存队列已满时,会删除最近的事件。 -
BackpressureStrategy.LATEST:如果下游无法及时处理事件从而当缓存队列已满时,会保留最新的事件,其他的事件会被覆盖。
所以运行上面代码就会给出 MissingBackpressureException 异常提示,需要我们通过 request 方法来获取及消费事件及设置 Backpressure 策略来解决该问题。在使用其他操作符的时候,无法主动设置 Backpressure 策略,则会在缓存池满了以后给出 MissingBackpressureException 异常提示。
3.2、toFlowable
toFlowable 是 Observable 中的一个方法,通过该方法可以主动来设置 Backpressure 策略,从而低成本的解决在 Observable 中抛出的 MissingBackpressureException 异常。
Observable.interval(1000,TimeUnit.MILLISECONDS)
//设置`Backpressure`策略
.toFlowable(BackpressureStrategy.ERROR)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Subscriber<Long>() {
@Override
public void onSubscribe(Subscription s) {
}
@Override
public void onNext(Long aLong) {
}
@Override
public void onError(Throwable t) {
}
@Override
public void onComplete() {
}
});
复制代码
4、总结
相信阅读到这里,就已经对RxJava及源码都有了一定的了解。但是大家有没有想过以下几个问题,也是我在学习RxJava时一直思考的几个问题。
- RxJava的应用场景在哪?
- 学习RxJava的意义何在?
首先来看问题一, RxJava 的应用可以说非常广泛,比如轮询、网络出错重连、网络请求嵌套回调、联合判断、从缓存中获取数据等,但上面的一些场景也可以不用RxJava来实现,这也就导致了在使用时不会第一时间想到 RxJava 。所以笔者认为如果想要熟练的使用RxJava,则需要在思想上进行一次转变,因为RxJava是响应式编程的一种实现,它不会像 OkHttp 、 Glide 、 Dbflow 等开源库只会应用在某一领域。
关于学习RxJava的意义,我认为最好就是能够熟练使用并在可以使用 RxJava 的时候能够第一时间想到 RxJava ,当然由于 RxJava 学习门槛较高且需要思维的转变,所以在不能熟练使用时,就需要我们能够看懂别人写的 RxJava 代码了。当然 RxJava 的异步切换、Callback hell问题的解决也是很好的学习 RxJava 的理由。
那么大家怎么看 RxJava 尼???
【参考资料】
关于RxJava最友好的文章——背压(Backpressure)
如何形象的描述反应式编程中的背压(Backpressure)机制?
RxJava 沉思录(四):总结
我为什么不再推荐RxJava
关于 RxJava 背压
正文到此结束
- 本文标签: Android 锁 ask queue executor 构造方法 源码 find 管理 App volatile core message cache 索引 翻译 swap IDE CTO 开发 src 线程池 plugin 线程同步 ssl tar 数据 参数 同步 IOS ORM 回答 update 开发者 响应式 REST consumer 下载 Service 模型 java https UI 时间 list 开源 文章 Action id tag ip map 代码 key 总结 删除 Property IO 缓存 db cat 多线程 遍历 final http Atom 图片 synchronized tab 线程 API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

