一些出的不错的Java面试题(二)
时序数据库是用于存放 时序数据 的数据库,而时序数据指基于时间的一系列数据,可以揭示数据的趋势性和规律性,对于大数据分析有重要的意义
时序数据库支持快速写入、持久化,以及多维度的聚合查询等,相比传统的数据库,时序数据库记录了所有的历史数据,在查询上也会带上时间作为过滤条件
mysql的各种加锁机制简单讲一下
- 共享锁和排它锁 :共享锁和排它锁相当于读锁和写锁
- 意向锁 :表级锁,表示稍后对表中的行需要使用的锁类型
- 记录锁 :索引记录上的锁
- 间隙锁 :锁定索引记录的间隙,该范围内的所有值都会被锁定
- 后键锁 :记录锁和间隙锁的组合,是索引记录锁加上该索引记录前一个间隙的间隙锁
- 插入意向锁 :一种特殊的间隙锁,可以避免插入到相同索引间隙中的不同位置的事务进行等待
- 自增锁 :插入具有自增属性的列使用的特殊表级锁
- 空间索引的谓词锁 :支持包含
SPATIAL索引的表的隔离级别
JDK8默认的垃圾收集器是什么
Parallel Scavenge + Serial Old
Redis的数据结构底层是如何实现的?
- string :定义了SDS数据结构用于实现字符串,重写了大量字符串处理的模板方法
- list :结合了 双向链表 和 ziplist压缩列表 ,在查询和修改的效率上达到了平衡
- hash :有zipmap和dict两种实现方式,zipmap基于列表,dict基于链表
- set :基于柔性数组实现,如果集合过大,会使用dict进行存储
- zset :有两种实现方式,一种是使用zipmap将数据按照值顺序存储,一种是基于跳跃表存储
Spring创建Bean有哪三种方式?
- 默认无参方式 :将类交给Spring的BeanFactory管理
- 静态工厂 :把创建实例的方法交给Spring管理。如果第三方依赖中没有暴露类的构造方法,只提供静态工厂的方法时,可以使用这种方式将类交给Spring管理
- 实例工厂方式 :把工厂类交给Spring管理
i++和++i在JVM层面的实现有什么区别?
i++ 的JVM汇编指令是 iload => iinc => istore ,执行顺序为:
- 把i加载到操作数栈
- i自增1
- 把栈顶的值存储到指定变量的位置
++i 的JVM汇编指令是 iinc => iload => istore ,执行顺序为:
- i自增1
- 把i加载到操作数栈
- 把栈顶的值存储到指定变量的位置
即 i++ 会先把i的值加载到操作数栈,所以语句中使用的是自增前的值,而 ++i 会先对i自增后在加载到栈顶,所以使用的是自增后的值
用过JPA吗,里面的@Version用过吗?
@Version注解是用于检测并发修改操作的,当发生这种情况时会抛出一个事务异常
@Version是基于乐观锁原理(版本号)保证字段的并发修改安全性,如果乐观锁更新失败会抛出 ObjectOptimisticLockingFailureException 异常
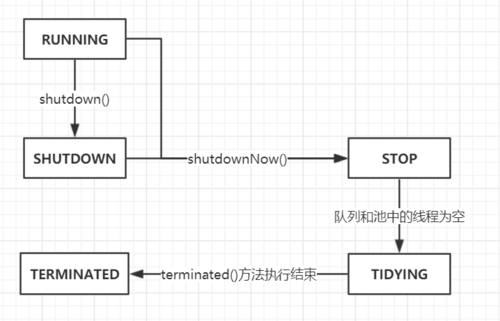
线程池的状态有哪几种?
在ThreadPoolExecutor中,其类变量 ctl 的高三位代表线程池状态:
- RUNNING :运行状态,正常工作
- SHUTDOWN :关闭状态,不接受新任务,但会处理在阻塞队列中排队的队伍
- STOP :停止状态,不接受新任务,也不处理排队的任务,同时会中断执行中的任务
- TIDYING :整理状态,所有任务终止,没有工作线程,即将运行
terminated方法来终结线程池 - TERMINATED :终结状态,
terminated方法结束后线程池终结
状态的转换通过以下方式:
Java原生的序列化是怎么实现的?
将一个对象的内容按以下格式存储为二进制文件:
- 序列化文件头 :声明序列化协议和版本等信息
- 类描述 :声明类名和域个数等信息, 序列化id 在此处声明
- 属性描述 :声明域类型和名称,注意,此处不声明属性的值
- 父类信息描述 :如果有,则和类描述部分一致
- 属性值 :保存属性的值
讲一下建造者模式
建造者模式是将多个简单的对象一步步构建成一个复杂的对象,将复杂对象的 构建 和 表示 相分离,使得同样的构建过程可以创建不同的表示
通过建造者模式,可以统一流程化的装配过程,相比于工厂模式,建造者模式更关注于零件装配的顺序
当需要创建复杂对象时,且内部变化不复杂时,可以使用建造者模式,更加精细地控制对象建造过程,同时将对象本身与对象的创建过程解耦,让客户端不需要知道内部组成的细节
JDK对synchronized关键字做了哪些优化?
锁膨胀
一般地,我们理解的synchronized属于重量级锁,在其下JDK提供了两种更轻量级的锁,分别是偏向锁和轻量级锁:
- 偏向锁 :不进行加锁,而是在对象头设置“01”标志位,表示偏向模式。持有偏向锁的线程再次进入与该锁相关的同步块时,只要检查设置的线程id是否与自身一致,如果一致则可以直接进入,省去了加锁操作。等待全局安全点时会撤销该锁
- 轻量级锁 :在运行到同步块时,JVM会在当前线程栈帧中建立一个
Lock Record的空间,用于存储锁对象的Mark Word的拷贝,然后尝试使用CAS操作将对象的Mark Word指向Lock Record,如果更新成功,则线程获取同步锁,并将锁标志位改为“00”
锁膨胀指的是,一开始使用偏向锁来进行同步,如果有其他线程进入同步块,则锁膨胀为轻量级锁,在轻量级锁的情况下,如果CAS更新失败,则锁膨胀为重量级锁
偏向锁保证了单线程的执行效率,轻量级锁保证了多线程但是几乎没有竞争的情况下的效率
锁粗化
将多次连接在一次的加锁和解锁操作合并为一次,扩展为一个更大的锁
锁消除
对于一些不可能存在共享数据竞争的锁进行消除
redis的各种数据结构各自有什么应用场景?
- string:计数器、存储图片(基于redis二进制存储安全性)
- hash:大量数据存储、存储对象的属性信息
- list:消息队列、分页查询(基于range命令)
- set:数据去重、集合运算
- zset:topN、范围查找
了解自适应哈希吗,简单讲一下
Innodb引擎会监控对表上索引的查找,如果观察到建立hash索引会带来性能的提升,就会建立hash索引,称为 自适应哈希
自适应哈希是通过 缓冲池的B+树 构造而来,所以建立的速度很快,而且不需要为整张表建立索引
通过 SHOW ENGINE INNODB STATUS 可以查看索引的使用情况
SQL注入有哪些方式?
~ and 0 <> (select count(*) from _table) ~ and [num] < (select count(*) from _table) ~ and 1=(select count(*) from _table where len(_name) > 0) ~ and 1=0 or [condition]
什么是覆盖索引
如果一个索引包含所有需要查询的字段的值,搜索时只需扫描索引,而无需全表扫描,则称为覆盖索引
在explain的extra列会显示 using index ,而不是 using where
正文到此结束
- 本文标签: explain java IO 数据库 管理 分页 JPA db map 构造方法 CTO 自适应 spring 图片 大数据 list Word tab sql JVM 空间 ThreadPoolExecutor rmi executor https redis 消息队列 http 协议 索引 安全 时间 同步 mysql bean ip 数据 并发 实例 src zip id 线程 多线程 锁 线程池 mina UI synchronized Select
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

