大型高并发网站技术架构的九个演进过程

点击上方“ 搜云库技术团队 ”关注
选择“设为星标”
技术 / 架构 / 资料 / 职场 / 面试 / 内推在没有业务场景的时候就一味追逐架构,为技术而技术,或者一上来就想要设计出一个可以适用所有场景的解决方案,是不理智的。我们有的时候可能会陷入技术的怪圈而忘了考虑业务本身。我曾经看到的一句我很喜欢的话,在这边也与诸君分享: 好的架构都是进化来的,不是设计来的。
本文是阅读《大型网站技术架构核心原理与实践》一书的一些笔记,记录了原书的一些重要内容以及我的个人理解。其中很多内容网上都能找得到。
以下为演化过程:
一、初始阶段
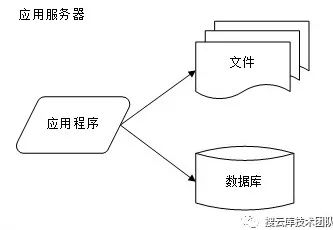
初始阶段考虑到使用量规范较小,且快速开发等原因,采用单服务器,将文件、数据库与应用程序一起部署即可。语言可以采用LAMP。如下图:
二、应用服务于数据服务分离
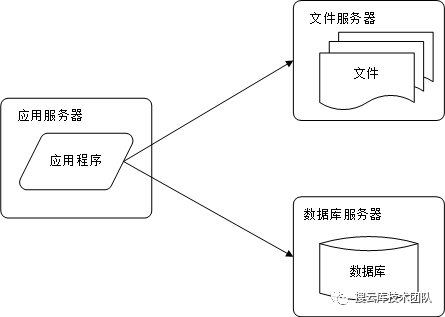
随着访问量的增多,导致存储空间不足,所以需要将应用与数据存储分离部署。文件和数据库存储需要分开。以避免由于大文件io而导致实时数据库服务的长响应延时。文件服务器需要更多的磁盘空间,数据库服务由于需要进行磁盘检索和数据缓存,所以需要较多的磁盘和内存。而应用服务器由于需要业务逻辑带来的频繁密集计算,所以需要较好的CPU。如下图。
三、使用缓存改善网站性能
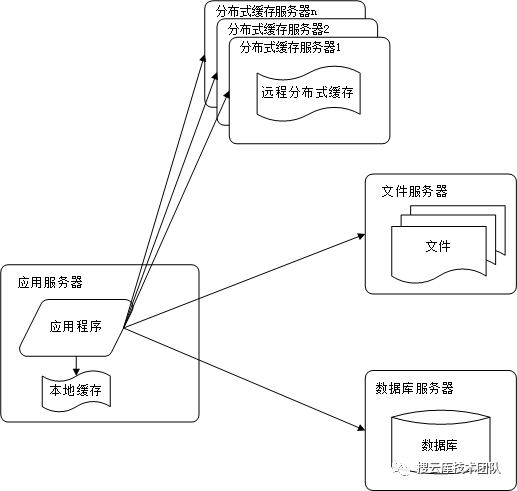
网站访问中,对访问频率比较高的数据进行本地缓存和分布式缓存,能够很好地提高网站性能。什么时候采用本地缓存,什么时候采用分布式缓存呢?一些公司会选择将热点数据存入本地缓存,同时异步写入分布式缓存。而更多时候,我们较少采用本地缓存,因为其会占用宝贵的应用程序的内存空间。采用本地缓存只有那种占用少量内存,且使用率非常高的数据。比如每次请求都需要判断用户是否在黑名单中。此时就可以把名单加载入本地缓存。分布式缓存我们常用的就是memcached和redis。二者的伸缩性都非常优秀。 整编:微信公众号,搜云库技术团队,ID:souyunku
四、应用服务集群化
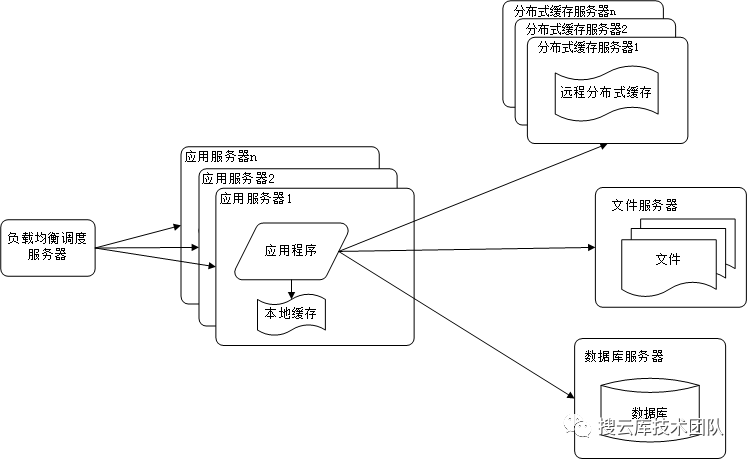
单一的服务器存在着并发处理能力不足,高峰期负载过高,单点等问题。此时可以用过简单的同构集群化部署来解决这一问题。
五、数据库读写分离
随着网站的发展,数据库的负载会变得越来越大。而且读、写数据库的操作本身就不是一个时间量级上的操作。如果都混在一起处理,则将很可能导致操作长时间阻塞等其他问题。大部分的主流数据库都自带主从热备的功能,所以部署起来还是比较简单的。而读写分离以及下面将提到的分库之后,我们常会采用一些中间件来对这个底层数据访问进行封装,从而对应用透明。比如mybatis有阿里巴巴的cobar client框架。读写分离后,我们的应用服务的设计中,就需要慎重考虑,读写同步的延时这一最终一致性的保证,对用户体验带来的影响是否可以接受。
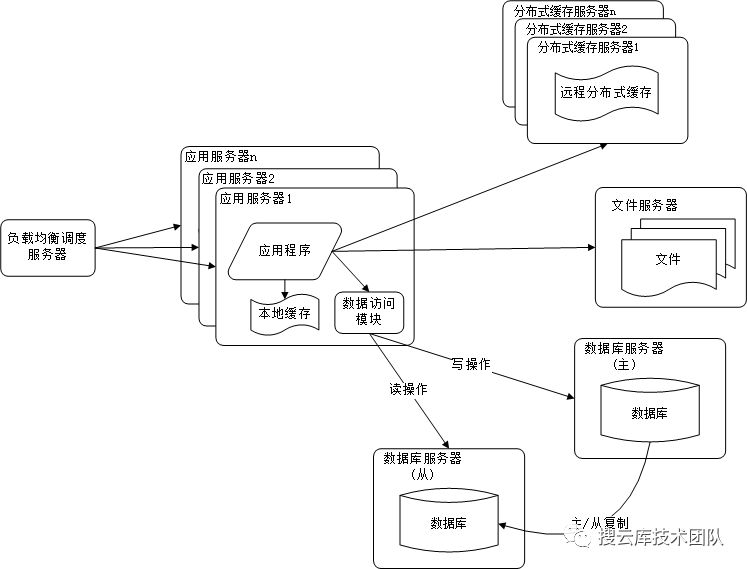
六、采用其他缓存代理技术
以上说的基本都是服务器端的优化,而用户访问网站时候,带宽、地域等其他因素会对访问体验带来不可忽视的影响。来改善这一体验,加快网站访问速度的办法主要有cdn加速和反向代理。可以认为cdn是一种特殊的反向代理,其也是基于反向代理的原理过来实现的缓存和加速。其主要缓存一些静态资源到离用户最近的网络提供商的机房。而此处的反向代理则是部署在网站服务端的机房。其既可以进行一些静态数据的高速缓存,也由于采用了SSL与内部服务器进行交互从而节省了大量开销。 整编:微信公众号,搜云库技术团队,ID:souyunku
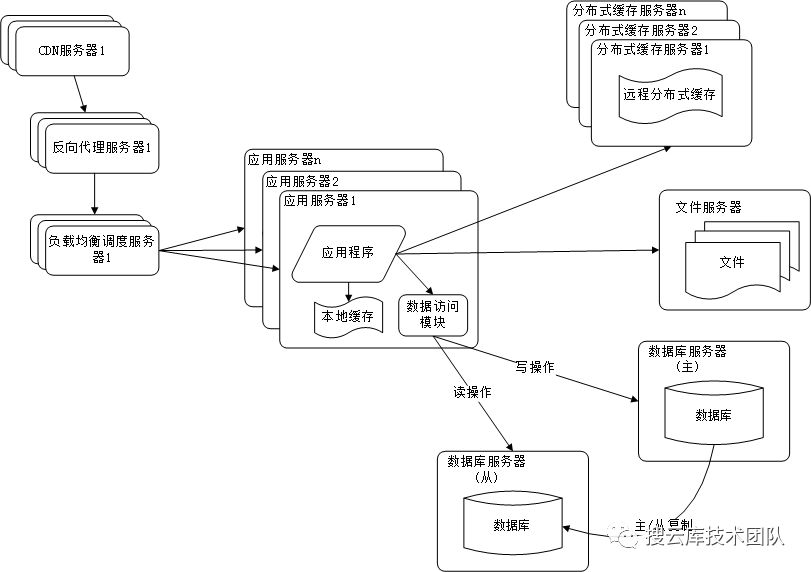
七、采用分布式数据库和分布式文件系统
随着网站规模的增大,单一的数据库和文件服务器已经无法很好迎合业务场景。所以同理地,也会将其集群化部署。
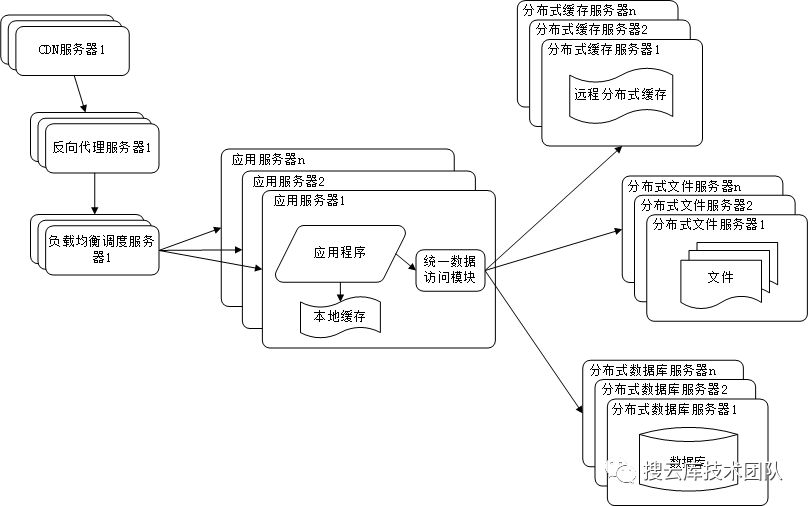
八、采用nosql和搜索引擎
随着数据需求越来越复杂,比如需要对log进行存储和分析以及检索。此时可以引入nosql数据库(如mongodb、hbase等)和搜索引擎技术(如lucense等)。同时,此时的数据源可能已经比较多,可以来自关系型数据库集群、非关系型数据库、缓存、文件系统甚至从消息队列订阅的数据等等。所以需要一个统一的数据访问模块(DAL)来统一对这一过程进行封装和管理。
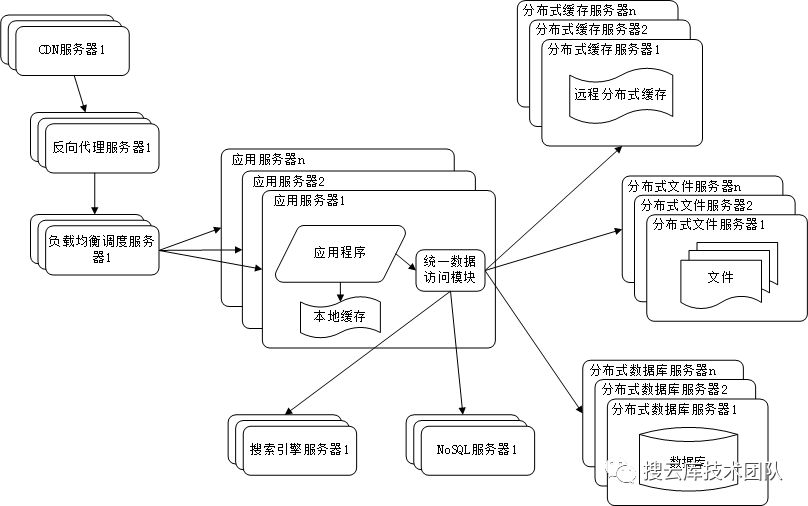
九、业务拆分与分布式化
前面我们提到,对业务服务进行同构部署来实现业务的并发处理。而我们知道这样简单的加机器在前期确实可以实现服务性能的线性增长,但是到了后期,并发量上来了之后,会发现这一处理将会很快达到瓶颈。而且于此同时,各个子业务的差异性带来的架构以及请求量方面的差异将日趋明显,如果还这样进行同构化的混部,其服务的性能将可能最终跟不上业务的发展,甚至可能导致雪崩。 所以最好的做法,就是对业务服务进行垂直拆分。同时对基础服务进行水平拆分。真正实现SOA。
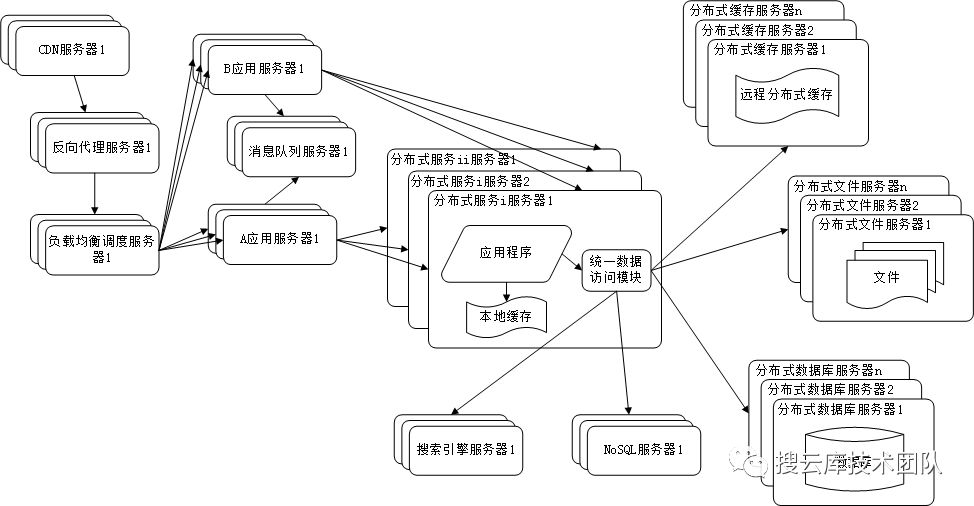
如此,便是一个网站架构演化的常见路径
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知我们,我们会立即删除并表示歉意。谢谢!
作者:吃橙子的狐狸 来源:cloud.tencent.com/developer/article/1396863 整编:搜云库技术团队,欢迎广大技术人员投稿 投稿邮箱:admin@souyunku.com
如果对本文的内容有疑问,请在文章留言区留言,谢谢。
》》》点击:永不失效的福利《《《
更多技术干货
推荐:最新200篇:技术文章整理

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

