一致性hash算法及其java实现
随着业务系统越来越大,我们需要对API的访问进行更多的缓存,使用Redis是一个很好的解决方案.
但是单台Redis性能不足够且迟早要走向集群的,那么怎么才能良好的利用Redis集群来进行缓存呢?
当一个请求到来,我们如何决定将这个请求的内容缓存在那台Redis服务器上?我们一一道来.
分配方法
随机分配
假设我们有X台服务器,当一个请求来到的时候,我们获取一个 0-X 的随机数,然后将内容缓存在该服务器上.
这明显是不可选的,想要查询的时候我们自己也不知道在哪,只能逐个遍历服务器,知道拿到为止.
hash取模
还有一种常见的方式就是对 集群数量 进行hash取模.比如我们现在有3台服务器,那么对请求的key进行hash,之后拿到的 hashcode 对3进行取模,得到的数字就是该key应该存储的服务器.
这样虽然解决了上面的获取问题,但是扩展性极其差,设想一下现在我们需要新添加一台机器,也就是机器数量来到了 4 ,那么对4取模的结果和对 3 取模的结果基本上全部不一样,也就是说我们需要对所有的key进行一次重新的hash计算并重新存储.
一致性hash
这也是我们今天的重点,它于1997年由麻省理工学院提出.我们在下面单独讲解一下他.
一致性hash原理
其实本质上,一致性hash也是hash取模,只是是永远的对 2的32次方-1 取模.
一致性hash引入了一个叫做 一致性hash环 的概念,即将 (0-2^32-1) 中间的所有整数首尾相接连接成一个环.如下图:
然后将所有的节点映射到环上,假设我们有3个节点,N1,N2.N3.那么如下图:

.
之后我们将要存储的所有key也都映射到环上,假设我们有6个key.

这样之后,顺时针旋转key,将其存储在遇到的第一个服务器上,这样有什么好处呢?
那就是扩展性,当新插入一个节点时,只会影响到少部分key,需要重新计算的key很少,我们添加一个节点试试:
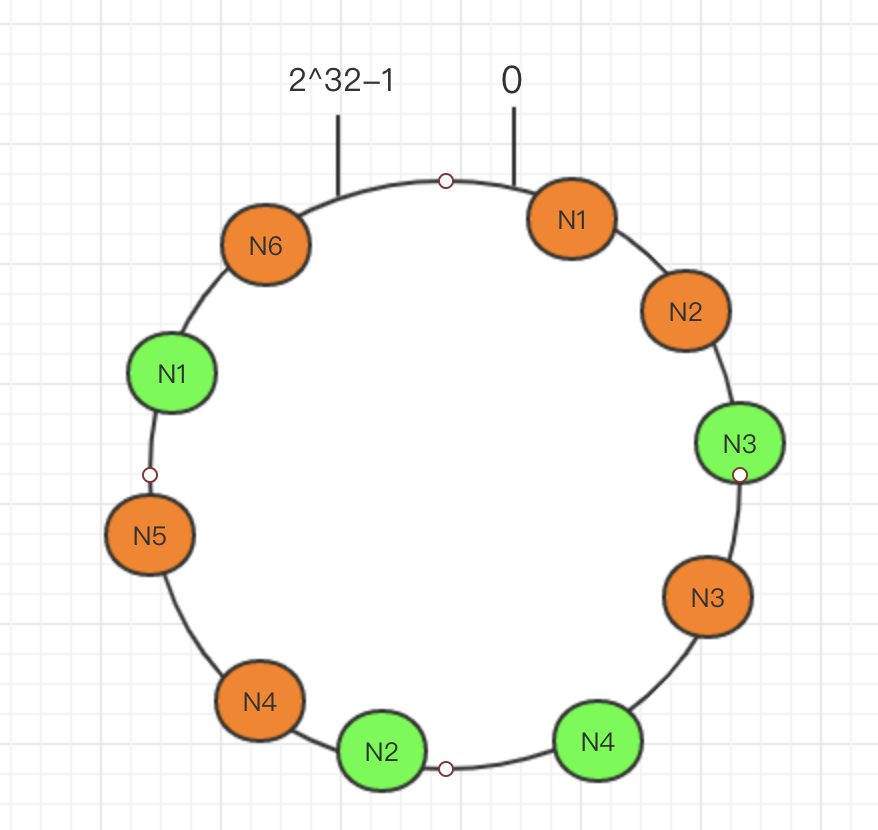
可以发现,只有N3数据需要从N2节点迁移到N4.
是不是看起来挺美滋滋的,啥好处都有,有啥缺点呢?
缺点当然有.
-
上面的图是一种理想状态,基本算是均匀的分布了,但是实际使用中,你用一个集群中的机器名(有很大的可能性很类似)去hash,拿到的结果可能很相近,也就是说,并不是像图中这样分散的,而是聚集在一起,而key是分散的,这样会导致,大量的key命中了其中一个或者多个服务器,而有一部分却空闲.总之,负载不均衡.
-
redis的key都是字符串,而字符串的
hashcode方法是可能会返回负值的,而一致性hash环是只有正值的,因此需要我们使用别的hash算法.(淡然你也可以粗暴的进行取绝对值).
使用虚拟节点解决hash不均匀的问题
hash不均匀主要出现在节点很少的时候,那么我们可以手动模拟一些节点出来,也就是所谓的虚拟节点,比如我们只有3个节点,但是我们定义一个规则,比如A-1,A-2,A-3,这三个节点都可以被映射到环上,但是在真正存储的时候我们都存储在A上.
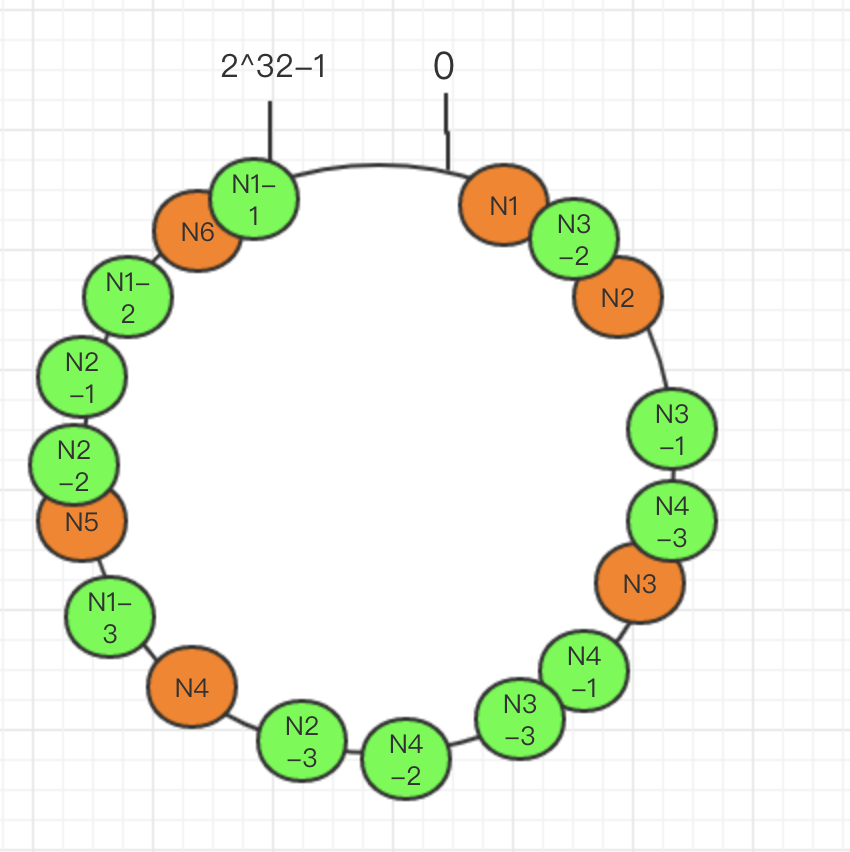
只要我们的虚拟节点足够多,我们就可以让其尽可能的均匀分布在环上.
总结
一致性hash算法是使用虚拟的环状数据结构,解决了简单hash算法中扩展性差的问题,在分布式缓存以及负载均衡中有许多的应用.
Java实现一致性hash算法缓存客户端
-
Java中提供了
ConcurrentSkipListMap类,可以很好的使用在这里,不仅可以轻松的模拟环状结构,并发安全且使用跳表结构的ConcurrentSkipListMap可以提供很好的并发性能. -
对于虚拟节点的多少,其实是可以大概估算出来的,因此在下面的代码中,我将其作为一个变量,在初始化的时候由当前节点的数量计算得到,当然我没有具体实现计算方法.这么设计是出于什么考虑呢,想让虚拟节点的数量尽量的刚刚好,万一节点很多,还是用固定的虚拟节点,对均匀性提升不会很大,反而会造成性能损耗等.
-
代码中主要提供了一下几个方法:
- 初始化,用一个redis配置的字符串
- 添加和删除节点,会将其虚拟节点一起操作.
- jedis的get和set操作,当然在实际情况下不会只有这两个方法,这里只做模拟,对更多的方法没有做一个实现.
好了,废话不多说了,都在注释里面了!
package util;
import redis.clients.jedis.Jedis;
import java.util.concurrent.ConcurrentNavigableMap;
import java.util.concurrent.ConcurrentSkipListMap;
/**
* Created by pfliu on 2019/05/19.
*/
public class ConsistentHashRedis {
// 用跳表模拟一致性hash环,即使在节点很多的情况下,也可以有不错的性能
private final ConcurrentSkipListMap<Integer, String> circle;
// 虚拟节点数量
private final int virtual_size;
public ConsistentHashRedis(String configs) {
this.circle = new ConcurrentSkipListMap<>();
String[] cs = configs.split(",");
this.virtual_size = getVirtualSize(cs.length);
for (String c : cs) {
this.add(c);
}
}
/**
* 将每个节点添加进环中,并且添加对应数量的虚拟节点
*/
private void add(String c) {
if (c == null) return;
for (int i = 0; i < virtual_size; ++i) {
String virtual = c + "-N" + i;
int hash = getHash(virtual);
circle.put(hash, virtual);
}
}
// 根据字符串获取hash值,这里使用简单粗暴的绝对值.
private int getHash(String s) {
return Math.abs(s.hashCode());
}
// 计算当前需要多少个虚拟节点,这里没有计算,直接使用了150.
private int getVirtualSize(int length) {
return 150;
}
/**
* 对外提供的set方法
*/
public void set(String key, String v) {
getJedisFromCircle(key).set(key, v);
}
public String get(String k) {
return getJedisFromCircle(k).get(k);
}
/**
* 从环中取到适合当前key的jedis.
*/
private Jedis getJedisFromCircle(String key) {
int keyHash = getHash(key);
ConcurrentNavigableMap<Integer, String> tailMap = circle.tailMap(keyHash);
String config = tailMap.isEmpty() ? circle.firstEntry().getValue() : tailMap.firstEntry().getValue();
// 注意,由于使用了虚拟节点,所以这里要做 虚拟节点 -> 真实节点的映射
String[] cs = config.split("-");
return new Jedis(cs[0]);
}
/**
* 对外暴露的添加节点接口
*/
public boolean addJedis(String cs) {
add(cs);
return true;
}
/**
* 对外暴露的删除节点节点
*/
public boolean deleteJedis(String cs) {
delete(cs);
return true;
}
/**
* 从环中删除一个节点极其虚拟节点
*/
private void delete(String cs) {
if (cs == null) return;
for (int i = 0; i < virtual_size; ++i) {
String virtual = cs + "-N" + i;
int hash = getHash(virtual);
circle.remove(hash, virtual);
}
}
}
复制代码
完。
ChangeLog
2019-05-19 完成
**以上皆为个人所思所得,如有错误欢迎评论区指正。**
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客------>呼延十
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

