记录线上RT规律性增长问题排查
背景
营销中心一个新工程上线,工程上线后,监控平台显示RT水位呈规律性上涨下降
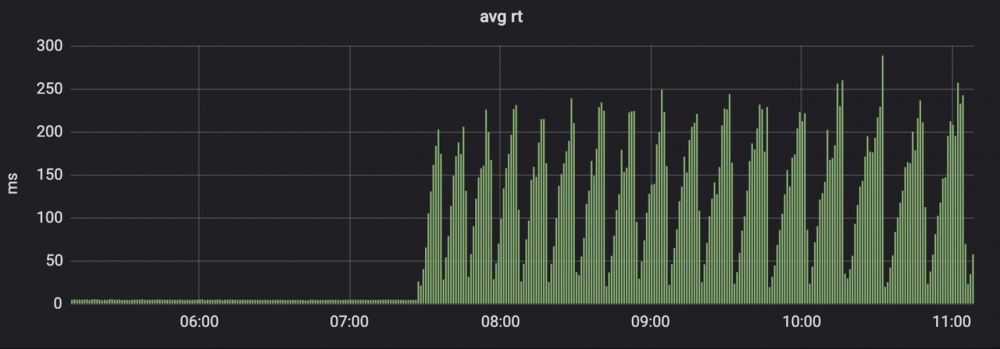
初次排查
初次看监控图,认为是redis key批量同时失效导致的,因为波峰的相隔时间正好是15分钟,redis的key失效时间也正好设置了这个时间。同时,当时公司运维反馈给我的,该表的sql请求量较大,15分钟调用了 36530次,占了该库性能的80%.
从链路监控中发现部分mysql的RT很高。
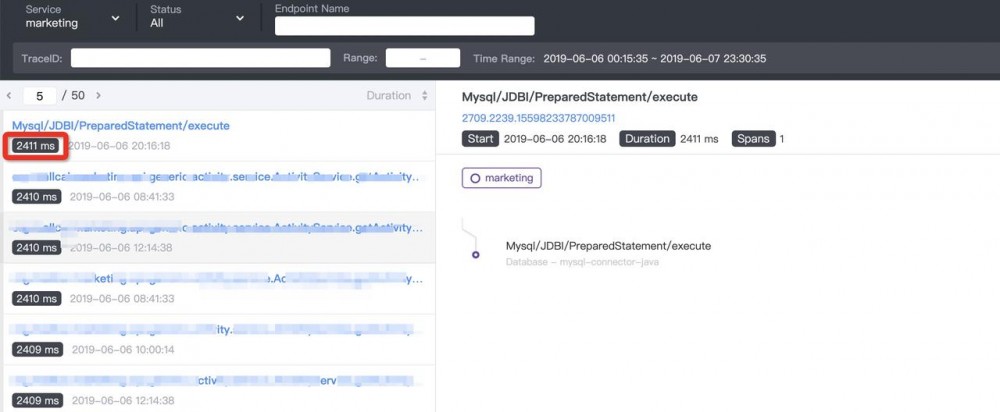
初次问题定位
结合db响应时间,初步定位问题为:缓存穿透后,大量的sql请求量导致RT上升。
但是其实无法解释规律性上涨问题。
于是乎,增加缓存击穿保护,发布上线,发现RT竟然下来了!认为问题已经解决。
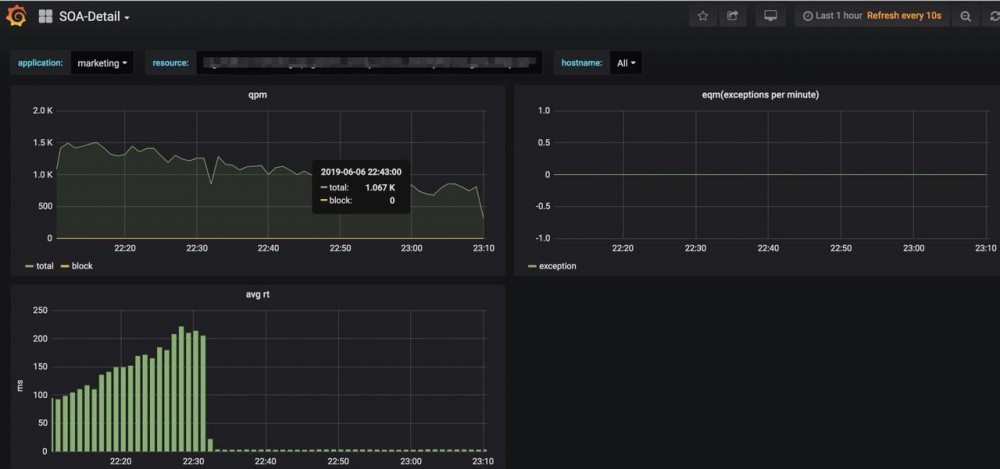
问题再次出现
过了个端午,今天再看RT情况,又恢复第一张图的情况
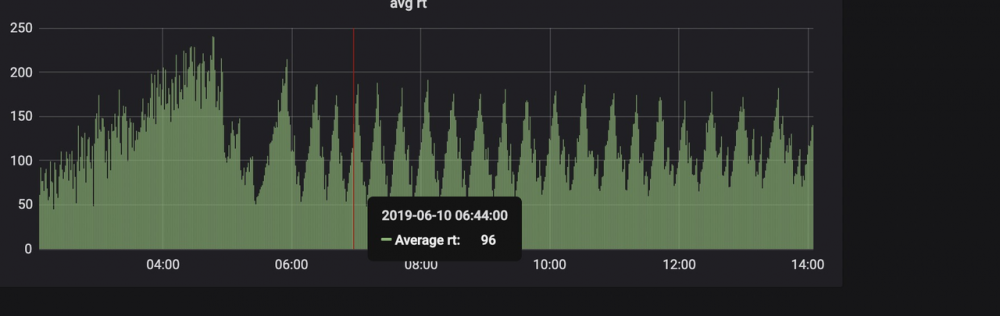
问题排查
感觉问题并非当初想象的那样。于是检查服务器情况,发现服务器CPU使用也非常奇葩。 
于是使用jstack 排查工程中多线程使用情况,发现无异常。
使用 top -Hp pid 查看CPU使用最频繁的线程
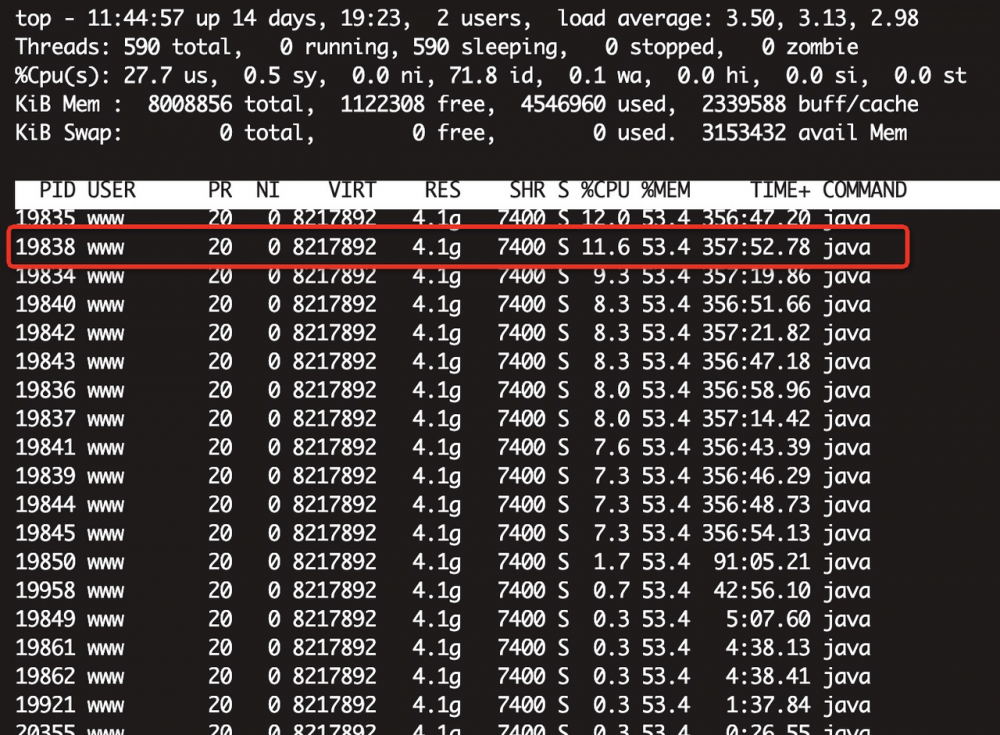
printf "%x/n" 19838 获取到十六进制值 4d7e
jstack 19832 | grep "4d7e" 查看线程情况
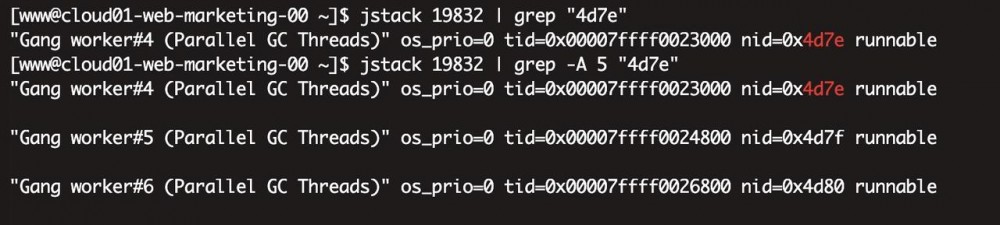
发现消耗CPU最多的竟然是gc线程
jstat -gc 19832 1000 查看GC情况
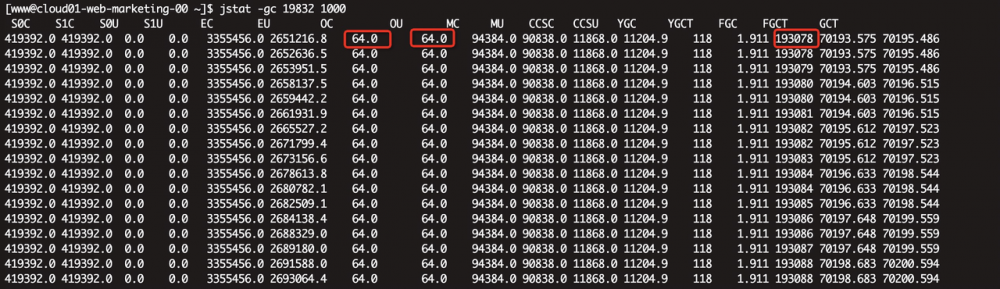
发现大bug了。老年代只配置了64M,线上一直在fullgc,端午三天已经fullgc了19万次多了。。好了,可以找运维小哥哥喝茶去了
结论
线上老年代配置的太小,导致系统一直在fullgc,fullgc的时候STW,阻塞用户线程,一般阻塞时间在100ms左右,导致RT飙升。fullgc后恢复正常,rt恢复,然后再次继续fullgc。
思考
1. 监控平台缺少对jvm监控
2. 对于请求量大的接口,评估缓存击穿风险
3. 问题排查要结合CPU,内存,IO,JVM多方面同时考虑
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

