【SpringCloud】配置:application.yml中都应该写些啥?
文章包含以下内容。
- 基本信息
- 容器配置
- 管理配置
- Endpoint
- Swagger配置
- Eureka配置
- Feign和Ribbon
- 调用链
- 通用配置
- 连接池配置
- Mybatis配置
#基本信息
基本信息用来展示项目的版本、开发者等。可用来开发统一的管理后台对项目进行控制。
info:
businessSide: 研发部
serviceName: ${artifactId}
version: @version@
jdk-version: @java.version@
spring-boot.version: @spring-boot.version@
spring-cloud.version: @spring-cloud.version@
author: 小姐姐
复制代码
一般,通过访问 /info ,即可得到解释后的JSON。
Tomcat配置
用来打印Server的Access日志和运行日志,同时比较重要的还有 contextPath 。良好的日志格式是必要的,用来进行后续的分析和统计。
注意某些版本的 basedir 改成了 file:. 语法,直接写 . 会报错的。
server:
port: 8888
context-path: /
tomcat:
basedir: .
accesslog:
enabled: true
directory: /export/logs/example/
pattern: "%{X-Forwarded-For}i %a %{X-B3-TraceId}i %t %m %U %s %b %D"
rename-on-rotate: true
suffix: .log
prefix: access
rotate: true
buffered: false
file-date-format: yyyy-MM-dd
uri-encoding: UTF-8
复制代码
Undertow 、 Jetty 的配置类似。
管理
线上要将 security开启。另外 contextPath 改成统一的更佳,我觉得 /ops 比较好,你也可以用。
management:
security:
enabled: false
context-path: /ops
复制代码
通过管理能够拿到哪些信息呢?我这里总结了一下,像Spring-admin这样的组件都是从中拿数据,你也可以轻易做一个后台哦。
| 路径 | 内容 |
|---|---|
| /ops/jolokia/list jolokia | 暴露的接口 |
| /ops/info | 输出项目基本信息 |
| ops/health | 输出健康信息 |
| /ops/autoconfig | 输出自动配置的信息 |
| /ops/configprops | 敏感信息,所以一定要关闭外网的访问 |
| /ops/beans Spring | 中都有哪些Bean,仅用于调试 |
| /ops/dump | JVM dump信息,比如线程汇总等 |
| /ops/env | 启动环境 |
| /ops/mappings | 所有URL映射 |
| /ops/metrics | 监控数据,报表使用 |
| /ops/trace | 最近的访问trace |
很多高危接口,开车注意安全。
Endpoint (如何描述,囧)
endpoints:
shutdown:
enabled: false
sensitive: false
jolokia:
enabled: true
复制代码
我们的jolokia就是在这里开放的,很简单的是不是?
shutdown接口非常有用,可以做一些类似 隔离 的功能。但我们更佳倾向于控制注册中心去干这些事,所以禁用。如果你开启了,注意不要暴露在外网。
Swagger
Swagger作为可视化的测试工具,也是项目沟通的桥梁,同时能作为文档使用,项目中都应该配备。
swagger:
title: ${artifactId}
version: @version@
contact:
name: 小姐姐
email: xjj@sayhiai.com
base-package: com.sayhiai.controller
base-path: /**
exclude-path: /error, /ops/**
复制代码
Eureka配置
服务可能作为提供者,也可能作为调用者。所以 client 和 instance 都应该配备。其中,参数是调了优的,你需要了解其中的含义。建议参考本公众号《SpringCloud服务的平滑上下线功能》。
eureka:
client:
register-with-eureka: true
fetch-registry: false
#eureka client获取服务注册状态
registry-fetch-interval-seconds: 5
healthcheck:
enabled: true
instance:
prefer-ip-address: true
instance-id: ${spring.cloud.client.ipAddress}:${server.port}
metadata-map:
management.context-path: ${server.context-path}
statusPageUrlPath: ${server.context-path}ops/info
health-check-url-path: ${server.context-path}ops/health
lease-expiration-duration-in-seconds: 15
lease-renewal-interval-in-seconds: 5
复制代码
Feign和Ribbon
Feign 和 Ribbon 作为底层,负责服务间通信。Ribbon的许多参数是公用的。为了支持平滑上下线功能,合理的超时配置也是必须的。
feign:
hystrix:
enabled: true
ribbon:
ReadTimeout: 8000
ConnectTimeout: 1000
OkToRetryOnAllOperations: true
MaxAutoRetriesNextServer: 2
MaxAutoRetries: 0
ServerListRefreshInterval: 3000
retryableStatusCodes: 404,500
复制代码
#调用链
调用链应该是分布式系统的必备功能了,否则会陷入问题的泥潭里不能自拔。我比较喜欢 jaeger , zipkin 的集成也是类似的, opentracing 都有通用的解决方案。
opentracing.jaeger.log-spans: true opentracing.jaeger.udp-sender.host: localhost opentracing.jaeger.udp-sender.port: 5775 复制代码
通用配置
两个比较重要的点提一下:
- aop一定要开启
proxyTargetClass,很多功能要用,比如各种starter。 - jmx一定开启,开启后就可以使用
jolokia等工具将jmx转成http,进而能够使用telegraf等进行数据收集做监控图。
spring:
application:
name: ${artifactId}
http:
encoding:
charset: UTF-8
force: true
enabled: true
profiles:
active: @profileActive@
aop:
proxyTargetClass: true
auto: true
jmx:
enabled: true
复制代码
数据库配置
一般 Druid 数据库连接池已经成为标配了。此数据库连接池配置项有点多,酌情开启。
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5
min-idle: 5
max-active: 200
max-wait: 10000
#test-while-idle: true
#validation-query: SELECT 1 FROM DUAL
test-on-borrow: false
test-on-return: false
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 15000
default-auto-commit: true
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 30000
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
#filters: stat,wall,slf4j
#有多个数据源时,配置公用监控数据
use-global-data-source-stat: true
filter:
stat:
enabled: false
db-type: mysql
log-slow-sql: true
slow-sql-millis: 2
slf4j:
data-source-log-enabled: true
data-source-logger-name: DRUID
statement-executable-sql-log-enable: true
statement-logger-name: DRUID
复制代码
MyBatis
什么?还在用ORM,那就MyBatis吧。或者,那么多选择,干么非要用SQL呢?
mybatis:
mapper-locations: classpath*:sqlmap/*Mapper.xml
type-aliases-package: ${package}.entity
configuration:
# 全局启用或禁用延迟加载。当禁用时,所有关联对象都会即时加载。
lazy-loading-enabled: false
# 使全局的映射器启用或禁用缓存
cache-enabled: true
# 当启用时,有延迟加载属性的对象在被调用时将会完全加载任意属性。否则,每种属性将会按需要加载。
aggressive-lazy-loading: false
# 是否允许单条sql 返回多个数据集 (取决于驱动的兼容性) default:true
multiple-result-sets-enabled: true
# 是否可以使用列的别名 (取决于驱动的兼容性) default:true
use-column-label: true
# 允许JDBC 生成主键。需要驱动器支持。如果设为了true,这个设置将强制使用被生成的主键,有一些驱动器不兼容不过仍然可以执行。 default:false
use-generated-keys: false
# 指定 MyBatis 如何自动映射 数据基表的列 NONE:不隐射 PARTIAL:部分 FULL:全部
auto-mapping-behavior: partial
# 这是默认的执行类型 (SIMPLE: 简单; REUSE: 执行器可能重复使用prepared statements语句;BATCH: 执行器可以重复执行语句和批量更新)
default-executor-type: simple
# 使用驼峰命名法转换字段。
map-underscore-to-camel-case: true
# 设置本地缓存范围 session:就会有数据的共享 statement:语句范围 (这样就不会有数据的共享 ) defalut:session
local-cache-scope: session
# 设置但JDBC类型为空时,某些驱动程序 要指定值,default:OTHER,插入空值时不需要指定类型
jdbc-type-for-null: 'null'
复制代码
最后,配上一张简图,当系统成长,通用的模块,都可以作为通用配置放在application.yml里。
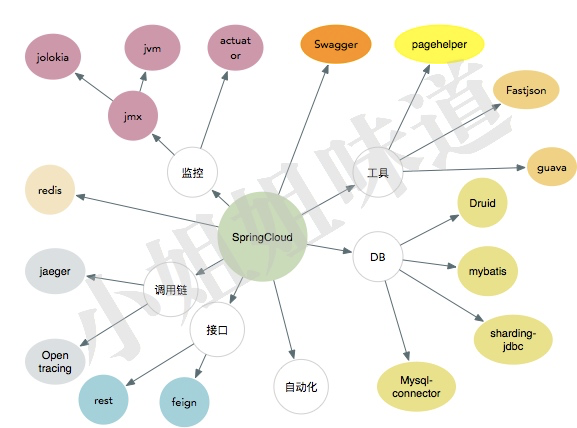

正文到此结束
- 本文标签: 时间 IO Feign db Eureka Proxy 数据库 src 调试 bean zipkin zip Select session ip 总结 sql http 代码 executor ribbon tab list Statement tar lib 开发者 Service java App 分布式 服务注册 tomcat 开发 druid 安全 统计 管理 cache springcloud classpath key JDBC client UI Security spring CTO id 注册中心 mail 参数 retry cat core IDE mapper Hystrix 测试 XML 连接池 js example 配置 文章 mysql UDP AOP bus jetty mybatis 缓存 线程 entity 数据 ORM 分布式系统 ssl json JVM https dataSource map ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

