Java8函数式编程
最近使用lambda表达式,感觉使用起来非常舒服,箭头函数极大增强了代码的表达能力。于是决心花点时间深入地去研究一下java8的函数式。
一、lambda表达式
先po一个最经典的例子——线程
public static void main(String[] args) {
// Java7
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(i);
}
}
}).start();
// Java8
new Thread(() -> {
for (int i = 0; i < 100; i++) {
System.out.println(i);
}
}).start();
}
复制代码
第一次接触lambda表达式是在创建线程时,比较直观的感受就是lambda表达式相当于匿名类的语法糖,emm~,真甜。不过事实上,lambda表达式并不是匿名类的语法糖,而且经过一段时间的使用,感觉恰恰相反,在使用上匿名类更像是Java中lambda表达式的载体。
使用场景
下面的一些使用场景均为个人的一些体会,可能存在不当或遗漏之处。
1. 简化匿名类的编码
上面的创建线程就是一个很好简化编码的例子,此处就不再重复。
2. 减少不必要的方法创建
在Java中,我们经常会遇到这样一种场景,某个方法只会在某处使用且内部逻辑也很简单,在Java8之前我们通常都会创建一个方法,但是事实上我们经常会发现这样写着写着,一个类中的方法可能会变得非常庞杂,严重影响阅读体验,进而影响编码效率。但是如果使用lambda表达式,那么这个问题就可以很容易就解决掉了。
一个简单的例子,如果我们需要在一个函数中多次打印时间。(这个例子可能有些牵强,但是实际上还是挺常遇见的)
public class FunctionMain {
public static void main(String[] args) {
TimeDemo timeDemo = new TimeDemo();
timeDemo.createTime = System.currentTimeMillis();
timeDemo.updateTime = System.currentTimeMillis() + 10000;
outputTimeDemo(timeDemo);
}
private static void outputTimeDemo(TimeDemo timeDemo) {
Function timestampToDate = timestamp -> {
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return df.format(new Date(timestamp));
};
System.out.println(timestampToDate.apply(timeDemo.createTime));
System.out.println(timestampToDate.apply(timeDemo.updateTime));
}
interface Function {
String apply(long timestamp);
}
}
class TimeDemo {
long createTime;
long updateTime;
}
复制代码
在这段代码的outputTimeDemo中我们可以看到,对于时间戳转换的内容,我们并没有额外创建一个方法,而是类似于创建了一个变量来表达。不过,这个时候出现了另一个问题,虽然我们少创建了一个方法,但是我们却多创建了一个接口Function,总有种因小失大的感觉, 不过这个问题,我们在后面的部分可以找到答案。
3. 事件处理
一个比较常见的例子就是回调。
public static void main(String[] args) {
execute("hello world", () -> System.out.println("callback"));
}
private static void execute(String s, Callback callback) {
System.out.println(s);
callback.callback();
}
@FunctionalInterface
interface Callback {
void callback();
}
复制代码
在这里,可以发现一点小不同,就是Callback多了一个注解@FunctionalInterface,这个注解主要用于编译期检查,如果我们的接口不符合函数式接口的要求,那编译的时候就会报错。不加也是可以正常执行的。
4. stream中使用
这个在后面的中详解。
java.util.function包
在之前的例子中,我们发现使用lambda表达式的时候,经常需要定义一些接口用来辅助我们的编码,这样就会使得本应轻量级的lambda表达式又变得重量级。那是否存在解决方案呢?其实Java8本身已经为我们提供了一些常见的函数式接口,就在java.util.function包下面。
| 接口 | 描述 |
|---|---|
| Function<T,R> | 接受一个输入参数,返回一个结果 |
| Supplier<T> | 无参数,返回一个结果 |
| Consumer<T> | 接受一个输入参数,并且不返回任何结果 |
| BiFunction<T,U,R> | 接受两个输入参数的方法,并且返回一个结果 |
| BiConsumer<T,U> | 接受两个输入参数的操作,并且不返回任何结果 |
此处列出最基本的几个,其他的都是在这些的基础上做了一些简单的封装,例如IntFunction<R>就是对Function<T,R>的封装。上面的这些函数式接口已经可以帮助我们处理绝大多数场景了,如果有更复杂的情况,那就得我们自己定义接口了。不过遗憾的是在java.util.function下没找到无参数无返回结果的接口,目前我找到的方案就是自己定义一个接口或者直接使用Runnable接口。
使用示例
public static void main(String[] args) {
Function<Integer, Integer> f = x -> x + 1;
System.out.println(f.apply(1));
BiFunction<Integer, Integer, Integer> g = (x, y) -> x + y;
System.out.println(g.apply(1, 2));
}
复制代码
lambda表达式和匿名类的区别
lambda表达式虽然使用时和匿名类很相似,但是还是存在那么一些区别。
1. this指向不同
lambda表达式中使用this指向的是外部的类,而匿名类中使用this则指向的是匿名类本身。
public class FunctionMain {
private String test = "test-main";
public static void main(String[] args) {
new FunctionMain().output();
}
private void output() {
Function f = () -> {
System.out.println("1:-----------------");
System.out.println(this);
System.out.println(this.test);
};
f.outputThis();
new Function() {
@Override
public void outputThis() {
System.out.println("2:-----------------");
System.out.println(this);
System.out.println(this.test);
}
}.outputThis();
}
interface Function {
String test = "test-function";
void outputThis();
}
}
复制代码
如上面这段代码,输出结果如下

所以如果想使用lambda表达式的同时去访问原类中的变量、方法的是做不到的。
2. 底层实现不同
编译
从编译结果来看,两者的编译结果完全不同。
首先是匿名类的方式,代码如下:
import java.util.function.Function;
public class ClassMain {
public static void main(String[] args) {
Function<Integer, Integer> f = new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return integer + 1;
}
};
System.out.println(f.apply(1));
}
}
复制代码
编译后的结果如下:

可以看到ClassMain在编译后生成了两个class,其中ClassMain$1.class就是匿名类生成的class。
那么接下来,我们再来编译一下lambda版本的。代码和编译结果如下:
import java.util.function.Function;
public class FunctionMain {
public static void main(String[] args) {
Function<Integer, Integer> f = x -> x + 1;
System.out.println(f.apply(1));
}
}
复制代码

在这里我们可以看到FunctionMain并没有生成第二个class文件。
字节码
更进一步,我们打开他们的字节码来寻找更多的细节。首先依然是匿名类的方式
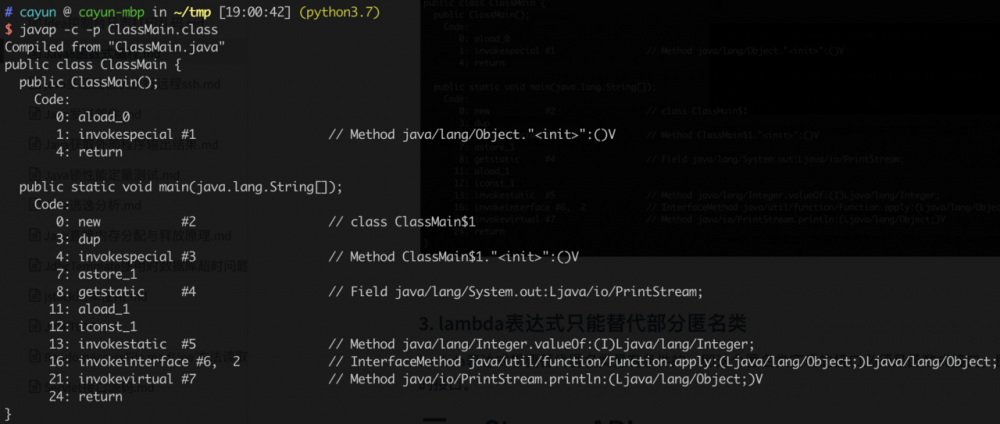
在Code-0这一行,我们可以看到匿名类的方式是通过new一个类来实现的。
接下来是lambda表达式生成的字节码,
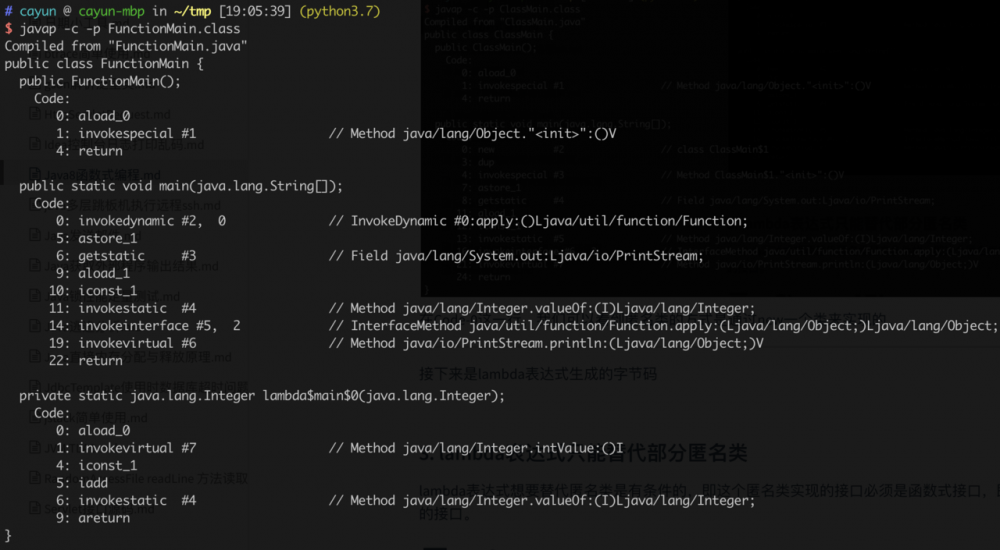
在lambda表达式的字节码中,我们可以看到我们的lambda表达式被编译成了一个叫做 lambda$main$0 的静态方法,接着通过invokedynamic的方式进行了调用。
3. lambda表达式只能替代部分匿名类
lambda表达式想要替代匿名类是有条件的,即这个匿名类实现的接口必须是函数式接口,即只能有一个抽象方法的接口。
性能
由于没有实际测试过lambda表达式的性能,且我使用lambda更多是基于编码简洁度的考虑,因此本文就不探讨性能相关问题。
关于lambda表达式和匿名类的性能对比可以参考官方ppt www.oracle.com/technetwork…
二、Stream API
Stream API是Java8对集合类的补充与增强。它主要用来对集合进行各种便利的聚合操作或者批量数据操作。
1. 创建流
在进行流操作的第一步是创建一个流,下面介绍几种常见的流的创建方式
从集合类创建流
如果已经我们已经有一个集合对象,那么我们可以直接通过调用其stream()方法得到对应的流。如下
List<String> list = Arrays.asList("hello", "world", "la");
list.stream();
复制代码
利用数组创建流
String[] strArray = new String[]{"hello", "world", "la"};
Stream.of(strArray);
复制代码
利用可变参数创建流
Stream.of("hello", "world", "la");
复制代码
根据范围创建数值流
IntStream.range(0, 100); // 不包含最后一个数 IntStream.rangeClosed(0, 99); // 包含最后一个数 复制代码
BufferReader.lines()
对于BufferReader而言,它的lines方法也同样可以创建一个流
File file = new File("/Users/cayun/.m2/settings.xml");
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
br.lines().forEach(System.out::println);
br.close();
复制代码
2. 流操作
在Stream API中,流的操作有两种:Intermediate和Terminal
Intermediate:一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。 Terminal :一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
除此以外,还有一种叫做short-circuiting的操作
对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream。 对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果。
常见的流操作可以如下归类:
Intermediatemap (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
TerminalforEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
Short-circuitinganyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
常见的流操作详解
1. forEach
forEach可以说是最常见的操作了,甚至对于List等实现了Collection接口的类可以不创建stream而直接使用forEach。简单地说,forEach就是遍历并执行某个操作。
Stream.of("hello", "world", "a", "b").forEach(System.out::println);
复制代码
2. map
map也同样是一个非常高频的流操作,用来将一个集合映射为另一个集合。下面代码展示了将[1,2,3,4]映射为[1,4,9,16]
IntStream.rangeClosed(1, 4).map(x -> x * x).forEach(System.out::println); 复制代码
除此之外,还有一个叫做flatMap的操作,这个操作在映射的基础上又做了一层扁平化处理。这个概念可能比较难理解,那举个例子,我们需要将["hello", "world"]转换成[h,e,l,l,o,w,o,r,l,d],可以尝试一下使用map,那你会惊讶地发现,可能结果不是你想象中的那样。如果不信可以执行下面这段代码,就会发现map与flatMap之间的区别了,
Stream.of("hello", "world").map(s -> s.split("")).forEach(System.out::println);
System.out.println("--------------");
Stream.of("hello", "world").flatMap(s -> Stream.of(s.split(""))).forEach(System.out::println);
复制代码
3. filter
filter则实现了过滤的功能,如果只需要[1,2,3,4,5]中的奇数,可以如下,
IntStream.rangeClosed(1, 5).filter(x -> x % 2 == 1).forEach(System.out::println); 复制代码
4. sorted和distinct
其中sorted表示排序,distinct表示去重,简单的示例如下:
Integer[] arr = new Integer[]{5, 1, 2, 1, 3, 1, 2, 4}; // 千万不要用int
Stream.of(arr).sorted().forEach(System.out::println);
Stream.of(arr).distinct().forEach(System.out::println);
Stream.of(arr).distinct().sorted().forEach(System.out::println);
复制代码
5. collect
在流操作中,我们往往需求是从一个List得到另一个List,而不是直接通过forEach来打印。那么这个时候就需要使用到collect了。依然是之前的例子,将[1,2,3,4]转换成[1,4,9,16]。
List<Integer> list1= Stream.of(1, 2, 3, 4).map(x -> x * x).collect(Collectors.toList());
// 对于IntStream生成的流需要使用mapToObj而不是map
List<Integer> list2 = IntStream.rangeClosed(1, 4).mapToObj(x -> x * x).collect(Collectors.toList());
复制代码
3. 补充
并行流
除了普通的stream之外还有parallelStream,区别比较直观,就是stream是单线程执行,parallelStream为多线程执行。parallelStream的创建及使用基本与stream类似,
List<Integer> list = Arrays.asList(1, 2, 3, 4); // 直接创建一个并行流 list.parallelStream().map(x -> x * x).forEach(System.out::println); // 或者将一个普通流转换成并行流 list.stream().parallel().map(x -> x * x).forEach(System.out::println); 复制代码
不过由于是并行执行,parallelStream并不保证结果顺序,同样由于这个特性,如果能使用findAny就尽量不要使用findFirst。
使用parallelStream时需要注意的一点是,多个parallelStream之间默认使用的是同一个线程池,所以IO操作尽量不要放进parallelStream中,否则会阻塞其他parallelStream。
三、Optional
Optional的引入是为了解决空指针异常的问题,事实上在Java8之前,Optional在很多地方已经较为广泛使用了,例如scala、谷歌的Guava库等。
在实际生产中我们经常会遇到如下这种情况,
public class FunctionMain {
public static void main(String[] args) {
Person person = new Person();
String result = null;
if (person != null) {
Address address = person.address;
if (address != null) {
Country country = address.country;
if (country != null) {
result = country.name;
}
}
}
System.out.println(result);
}
}
class Person {
Address address;
}
class Address {
Country country;
}
class Country {
String name;
}
复制代码
每每写到这样的代码,作为编码者一定都会头皮发麻,满心地不想写,但是却不得不写。这个问题如果使用Optional,或许你就能找到你想要的答案了。
Optional的基本操作
1. 创建Optional
Optional.empty(); // 创建一个空Optional Optional.of(T value); // 不接受null,会报NullPointerException异常 Optional.ofNullable(T value); // 可以接受null 复制代码
2. 获取结果
get(); // 返回里面的值,如果值为null,则抛异常 orElse(T other); // 有值则返回值,null则返回other orElseGet(Supplier other); // 有值则返回值,null则由提供的lambda表达式生成值 orElseThrow(Supplier exceptionSupplier); // 有值则返回值,null则抛出异常 复制代码
3. 判断是否为空
isPresent(); // 判断是否为空 复制代码
到这里,我们可能会开始考虑怎么用Optional解决引言中的问题了,于是思考半天,写出了这样一段代码,
public static void main(String[] args) {
Person person = new Person();
String result = null;
Optional<Person> per = Optional.ofNullable(person);
if (per.isPresent()) {
Optional<Address> address = Optional.ofNullable(per.get().address);
if (address.isPresent()) {
Optional<Country> country = Optional.ofNullable(address.get().country);
if (country.isPresent()) {
result = Optional.ofNullable(country.get().name).orElse(null);
}
}
}
System.out.println(result);
}
复制代码
啊嘞嘞,感觉不仅没有使得代码变得简单,反而变得更加复杂了。那么很显然这并不是Optional的正确使用方法。接下来的部分才是Optional的正确使用方式。
4. 链式方法
在Optional中也有类似于Stream API中的链式方法map、flatMap、filter、ifPresent。这些方法才是Optional的精髓。此处以最典型的map作为例子,可以看看map的源码
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
复制代码
源码很简单,可以看到对于null情况仍然返回null,否则返回处理结果。那么此再来思考一下引言的问题,那就可以很简单地改写成如下的写法,
public static void main(String[] args) {
Person person = new Person();
String result = Optional.ofNullable(person)
.map(per -> per.address)
.map(address -> address.country)
.map(country -> country.name).orElse(null);
System.out.println(result);
}
复制代码
哇哇哇,相比原先的null写法真真是舒服太多了。
map与flatMap的区别
这两者的区别,同样使用一个简单的例子来解释一下吧,
public class FunctionMain {
public static void main(String[] args) {
Person person = new Person();
String name = Optional.ofNullable(person).flatMap(p -> p.name).orElse(null);
System.out.println(name);
}
}
class Person {
Optional<String> name;
}
复制代码
在这里使用的不是map而是flatMap,稍微观察一下,可以发现Person中的name不再是String类型,而是Optional<String>类型了,如果使用map的话,那map的结果就是Optional<Optional<String>>了,很显然不是我们想要的,flatMap就是用来将最终的结果扁平化(简单地描述,就是消除嵌套)的。
至于filter和ifPresent用法类似,就不再叙述了。
四、其他一些函数式概念在Java中的实现
由于个人目前为止也只是初探函数式阶段,很多地方了解也不多,此处只列举两个。(注意:下面的部分应用函数与柯里化对应的是scala中的概念,其他语言中可能略有偏差)
部分应用函数(偏应用函数)
部分应用函数指的是对于一个有n个参数的函数f,但是我们只提供m个参数给它(m < n),那么我们就可以得到一个部分应用函数,简单地描述一下,如下
在这里 就是 的一个部分应用函数。
BiFunction<Integer, Integer, Integer> f = (x, y) -> x + y; Function<Integer, Integer> g = x -> f.apply(1, x); System.out.println(g.apply(2)); 复制代码
柯里化
柯里化就是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。换个描述,如下
Java中对柯里化的实现如下,
Function<Integer, Function<Integer, Integer>> f = x -> y -> x + y; System.out.println(f.apply(1).apply(2)); 复制代码
因为Java限制,我们不得不写成 f.apply(1).apply(2) 的形式,不过视觉上的体验与直接写成 f(1)(2) 相差就很大了。
柯里化与部分应用函数感觉很相像,不过因为个人几乎未使用过这两者,因此此处就不发表更多见解。
参考
[1] java.util.stream 库简介
[2] Java 8 中的 Streams API 详解
[3] 了解、接受和利用Java中的Optional(类)
[4]维基百科-柯里化
[5]维基百科-λ演算
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

